







最近秋招发放Offer已高一段落。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
喜欢本文记得收藏、关注、点赞。更多实战和面试交流,文末加入我们
技术交流

阿里巴巴Qwen团队开发的QVQ-72B,一个拥有720亿参数的视觉推理AI模型,让本地电脑部署高效多模态推理能力变得触手可及。

这款模型采用开放的Apache 2.0许可证,为AI爱好者、开发者以及注重数据隐私的企业提供了新的选择。
1 QVQ-72B
QVQ-72B模型专为处理需要同时理解文本和图像的任务而打造。
与传统语言模型相比,QVQ-72B具备强大的视觉处理功能,能够解读图像、生成与上下文相关的文本,并解决复杂的多模态问题。
其核心优势包括:
-
多模态融合:视觉与文本推理的无缝整合。
-
本地部署:可在本地硬件上灵活部署。
-
开源许可:基于Apache 2.0许可发布,支持个性化定制和商业应用。
-
隐私保护:本地安装,确保敏感数据安全存储于您的设备上。
2 QVQ-72B如何改变游戏规则
QVQ-72B以其独特的优势,正在重塑视觉推理领域的格局:
-
首次为本地使用:大多数视觉推理模型依赖于专有API或云基础设施,而QVQ-72B首次提供了本地使用的选项,让用户能够完全掌控自己的AI解决方案。
-
开放的Apache 2.0许可:这一宽松的许可证允许用户自由使用、修改和分发QVQ-72B,为创业者、研究者和开发者提供了灵活的起点。
-
卓越的性能:QVQ-72B拥有720亿参数,能够提供卓越的推理能力,其精准的多模态架构在以下任务中表现出色:
-
图像描述
-
视觉问题回答
-
场景理解
-
结合文本和视觉输入的复杂推理
-
数据隐私与安全:对于需要处理敏感数据的企业和个人,QVQ-72B的本地安装消除了云存储的隐私风险,确保数据的私密性和安全性。
3 本地部署QVQ-72B的简易指南
部署QVQ-72B到你的本地系统可能看起来是个技术挑战,但按照这个分步指南,一切都会简单明了。
步骤1:检查系统配置
在开始之前,请确保你的硬件满足以下最低要求,以保证QVQ-72B能够顺畅运行:
-
GPU:至少需要48 GB的内存,推荐使用NVIDIA A100或RTX 3090。
-
内存:至少128 GB的RAM。
-
存储空间:至少1 TB的空闲磁盘空间,用于存放模型权重和相关依赖。
-
操作系统:建议使用Linux系统,特别是Ubuntu 20.04或更新版本。
步骤2:获取QVQ-72B模型
-
访问QVQ-72B GitHub仓库下载模型:https://github.com/QwenTeam/QVQ-72B
-
克隆仓库:
git clone https://github.com/QwenTeam/QVQ-72B.git cd QVQ-72B
- 下载模型权重:
wget -O qvq72b_weights.tar.gz https://example.com/path-to-weights
tar -xvzf qvq72b_weights.tar.gz -C ./weights
步骤3:安装依赖项
在模型和权重文件准备就绪后,下一步是安装必要的Python库和系统包:
sudo apt update
sudo apt install python3-pip
pip install -r requirements.txt
步骤4:配置运行环境
为了确保QVQ-72B模型能够适应你的系统,需要进行一些环境配置:
-
调整配置文件:根据你的系统配置,编辑
config.yaml文件,确保所有设置都正确无误。 -
初始化模型:通过运行以下命令来初始化模型:
python initialize.py --config config.yaml
步骤5:运行模型
一切准备就绪后,可以启动QVQ-72B的交互界面:
python run.py
这样,你就可以开始使用QVQ-72B模型了。
4 QVQ-72B的应用
QVQ-72B的多模态能力,为各行各业的应用前景带来了无限的可能性:
- 研究和学术界:
使用QVQ-72B深入分析复杂数据集,开展实验,为医学、天文学和社会科学等领域的难题提供AI解决方案。
- 创意产业:
通过生成精准的图像描述、构建视觉叙事或辅助设计构思,QVQ-72B赋予内容创作者强大的力量。
- 商业智能:
将QVQ-72B集成至商业智能仪表板,提升决策支持能力,实现视觉数据的分析与洞察。
- 辅助工具:
开发辅助视觉障碍用户的应用,利用QVQ-72B的高级图像识别功能,帮助他们描述周围环境和事件。
- 游戏和娱乐:
将视觉推理技术融入游戏环境,创造沉浸式体验,使AI角色能够动态地理解和互动视觉元素。
QVQ-72B的应用潜力无限,为不同领域带来了创新的解决方案和丰富的应用场景。
5 性能基准测试表现
QVQ-72B在多项多模态性能基准测试中表现出色,超越了许多现有模型。主要成绩亮点如下:
-
视觉问题回答(VQA):在VQA v2数据集上,QVQ-72B达到了89.5%的准确率,显示出其在视觉问题回答任务中的高精确度。
-
图像描述:QVQ-72B生成的图像描述在BLEU-4评分中获得了76.3分,意味着其描述的流畅性和准确性都非常高。
-
场景理解:QVQ-72B在理解复杂场景方面展现出了强大的能力,甚至超越了如OpenAI的CLIP和Google的PaLM-E等知名模型。
这些基准测试结果充分证明了QVQ-72B在多模态AI领域的领先地位和强大的应用潜力。
6 与其他模型的比较
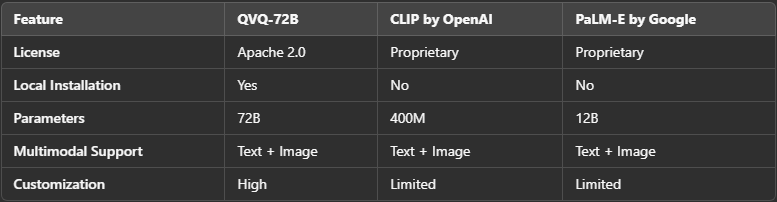
7 伦理考量
QVQ-72B的强大功能要求我们在使用时必须谨慎负责:
-
偏见控制:尽管QVQ-72B在多样化的数据集上进行了训练,我们仍需持续检查并减少其输出中可能存在的潜在偏见。
-
数据隐私保护:在处理敏感信息时,必须严格遵守相关的隐私法律和指导原则。
-
透明度:向用户清晰地说明模型的功能和局限,确保透明度。
我们应始终以负责任的态度使用QVQ-72B,保证技术的进步同时伴随着伦理的考量。
8 本地LLM的未来
QVQ-72B的发布标志着AI的新时代,一个个人和组织能够利用高级功能而不依赖于中心化云服务的新时代。随着硬件的普及和AI模型的不断进步,可以合理预见以下趋势:
-
本地AI解决方案的广泛采纳:更多的个人和组织将采用本地AI解决方案。
-
隐私与安全的加强:在AI应用中,隐私保护和数据安全将得到进一步的加强。
-
多模态推理等领域的创新加速:在多模态推理等关键领域,创新的步伐将加快。
QVQ-72B不只是视觉推理LLM,更是通往AI未来的重要门户。它以开源许可证、卓越的性能和本地部署能力,为开发者、研究人员和企业释放多模态智能的全部潜力。
不要错过这一开创性的技术革命。现在下载QVQ-72B,加入到视觉推理AI的新浪潮中来吧!

















 779
779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









