






- 一、层次分析法
- 流程:
- (1)选择指标,构建层次模型。
- 查阅资料或者自己去构建,不查阅文献就得发放调查问卷或者使用德尔菲法征求专家意见
- 指标按照一定的层级结构组织起来就构成了一个指标体系。
- (2)对目标层到准则层之间和准则层到方案层之间构建比较矩阵。
- 模型大致分为目标层、准则层和方案层
- 目标层是评价目标,准则层是评价指标体系,方案层是多个对比方案
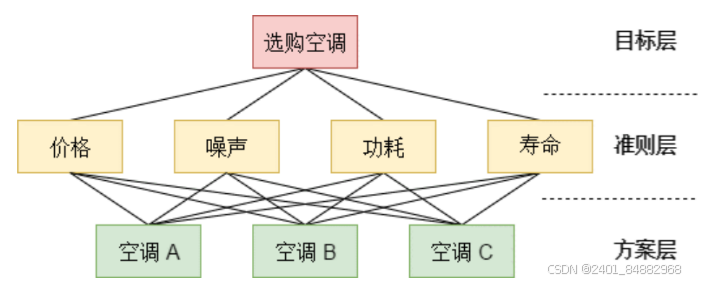
- 目标层是评价目标,准则层是评价指标体系,方案层是多个对比方案
- 模型大致分为目标层、准则层和方案层
- (1)选择指标,构建层次模型。
- 流程:
-
-
- (3)对每个比较矩阵计算CR值检验是否通过CR检验,如果没有通过检验需要调整比较矩阵。
- 两个相邻的层次之间需要构建成对比较矩阵,矩阵的每一项表示因素i和因素j的相对重要程度
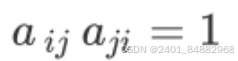
- (3)对每个比较矩阵计算CR值检验是否通过CR检验,如果没有通过检验需要调整比较矩阵。
-
-
-
-
- 通常来说,对重要性的取值都是取奇数
- RI值(随机一致性指标)
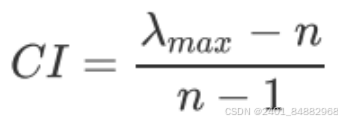
- 计算CI和RI的比值也就是CR,通常来说,当CR值超过0.1时,就可以认为这个矩阵是不合理的,需要被修改、被调整
-
-
-
-
- (4)求出每个矩阵最大的特征值对应的归一化权重向量。
- (4)求出每个矩阵最大的特征值对应的归一化权重向量。
-
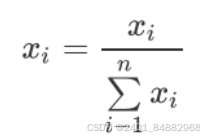
-
-
- (5)根据不同矩阵的归一化权向量计算出不同方案的得分进行比较。
- python进行矩阵分解的时候是在复数域内进行分解,所得到的向量也是复数向量,虚部为0的情况下想要单独分析实部,通过Q.real即可达成取实部的效果
-
- 二、熵权分析法
- 熵权法是一种客观赋权方法,基于信息论的理论基础,根据各指标的数据的分散程度,利用信息熵计算并修正得到各指标的熵权
- 第一步是指标正向化。它涉及将原本的负向指标转为正向指标,例如将死亡率转为生存率、故障率转为可靠度。通过正向化,目标或结果的达成情况更直观,提高指标的可解释性和可操作性。
- 对于极大型指标:指标越大越好,不需要正向化。只需要通过min-max规约或Z-score规约进行规约即可。
- 对于极小型指标:此类指标越小越好。它的正向化方式比较简单,可以取相反数;如果指标全部为正数,也可以取其倒数。
- 对于区间型指标:它的规约方法遵循下面的式子。
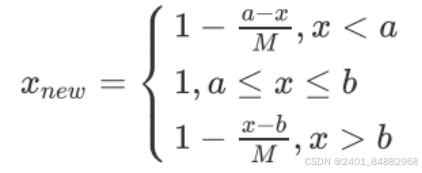
-
-
- 对于中值型指标:它的正向化操作为
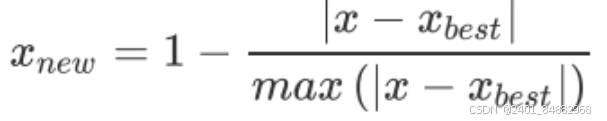
-
-
- 计算步骤
- (1)构建m个事物n个评价指标的判断矩阵
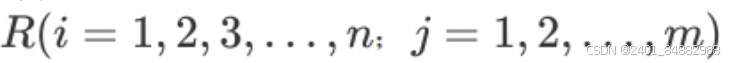
- 计算步骤
-
-
- (2)将判断矩阵进行归一化处理,得到新的归一化判断矩阵 。
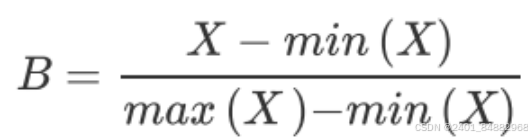
-
-
-
- (3)熵权法可利用信息熵计算出各指标的权重,从而为多指标评价提供依据。根据信息论中对熵的定义,熵值的计算如下。
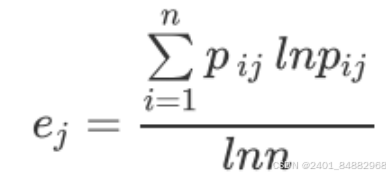
-
-
-
- 其中 p为离散属性中每个类取值的占比。通过熵值,可以评价不同指标的离散程度,一般情况下,信息熵越小,离散程度越大,因子对综合评价的权重就越大。
- (4)计算权重系数,代表对于某一个属性 ,第 类占样本的比例。 为属性 的取值数量。所以,权重系数定义为
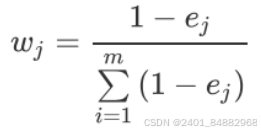
-
- 三、TOPSIS分析法
- 1、基本思想:对原始决策方案进行归一化,然后找出最优方案和最劣方案,对每一个决策计算其到最优方案和最劣方案的欧几里得距离,然后再计算相似度。若方案与最优方案相似度越高则越优先。
- 2、在TOPSIS分析法中,通过计算每个方案离理想解和负理想解的距离来判断优劣。理想解是最佳方案,各项指标最优;负理想解是最差方案,各项指标最差。
- 3、基本流程
- (1)对原始数据进行指标正向化和归一化操作得到矩阵Z
- (2)确定正理想解和负理想解
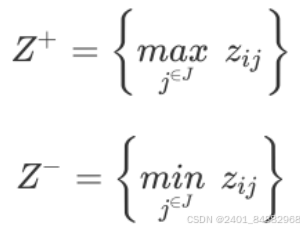
-
-
- (3)计算各评价对象到正理想解和负理想解的欧几里得距离:
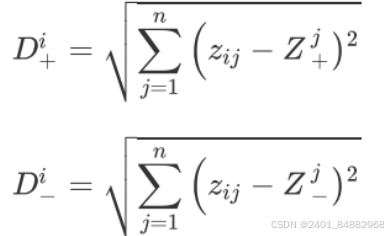
-
-
-
- (4)计算各评价对象的相似度
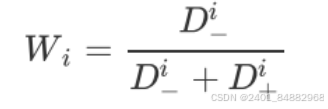
-
-
-
-
- 可以看到,相似度是与负理想解和两个理想解距离之和的比值,若占比越大,则说明离负理想解越远,越优先选择。
- (5)根据大小排序可得到结果。
-
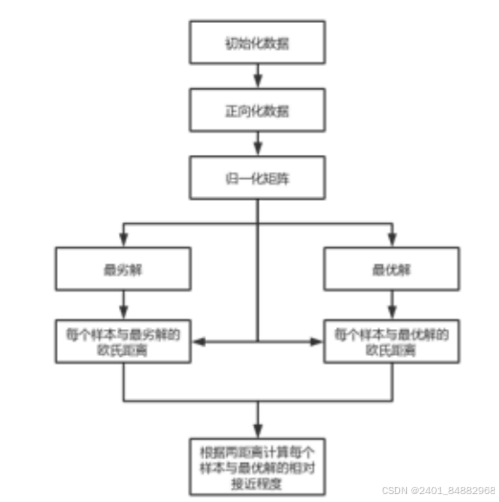
- 4、流程图
-
-
- 5、改进
- 考虑到不同指标在评价体系中的重要性可能存在差异,因此在计算距离时应对各个指标赋予相应的权重
- 权重的确定可以通过熵权法或层次分析法来实现
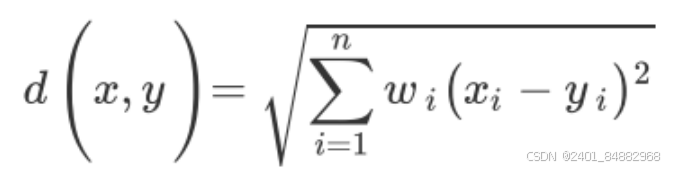
- 5、改进
- 四、CRITIC方法
- 1、波动性(对比强度):使用标准差进行表示,如果数据标准差越大说明波动越大,权重会越高
- 2、冲突性(相关性):使用相关系数进行表示,如果指标之间的相关系数值越大,说明冲突性越小,那么其权重也就越低
- 3、权重计算时,对比强度与冲突性指标相乘,并且进行归一化处理,即得到最终的权重
- 4、操作步骤
- (1)对指标进行无量纲化和正向化处理。第6章提到,min-max规约能够进行很好的无量纲化处理,如果这个指标是越大越好,那么规约方法形如:
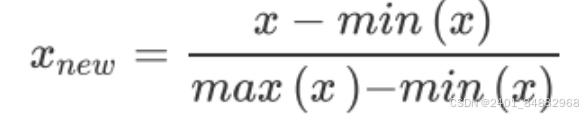
-
-
- 而如果指标是越小越好,那么规约方法形如:
-
-
-
- 对于区间型和中值型指标,则按照在TOPSIS分析中讲到的指标正向化处理。
- (2)计算指标变异性。本质上就是计算每个指标在所有样本中的标准差 。标准差表示指标在样本中的差异波动情况,若标准差越大,则它的区分度越明显,信息强度也越高,越应该给它分配更多权重。
- (3)计算指标冲突性,定义为:
-
-
-
- 其中rij表示指标r和指标j之间的相关系数。皮尔逊相关系数定义为:
-
-
-
- (4)获取信息量,其中信息量的定义方法为指标变异性和冲突性的乘积:
-
-
-
- (5)归一化得到指标权重,再用权重去乘归一化的数据矩阵可以得到每个对象的评分,并根据评分进行对象的评价、排序。归一化的过程形如:
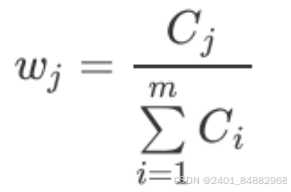
-
- 五、模糊综合评价法
- 1、用模糊数学对受到多种因素制约的事物或对象做出一个总体的评价
- 2、基本思想:用属于程度代替属于或不属于,从而刻画“中介状态”
- 3、首先确定被评价对象的因素(指标)集合评价(等级)集;再分别确定各个因素的权重及它们的隶属度矢量,获得模糊评判矩阵;最后把模糊评判矩阵与因素的权矢量进行模糊运算并进行归一化,得到模糊综合评价结果
- 注:文章内容来源于开源学习平台Datawhale的学习笔记

















 795
795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









