






无论你是AI爱好者还是技术专家,这篇文章将帮你梳理大语言模型的完整知识体系,从基础架构到实际应用,一文掌握当前最热门的AI技术!
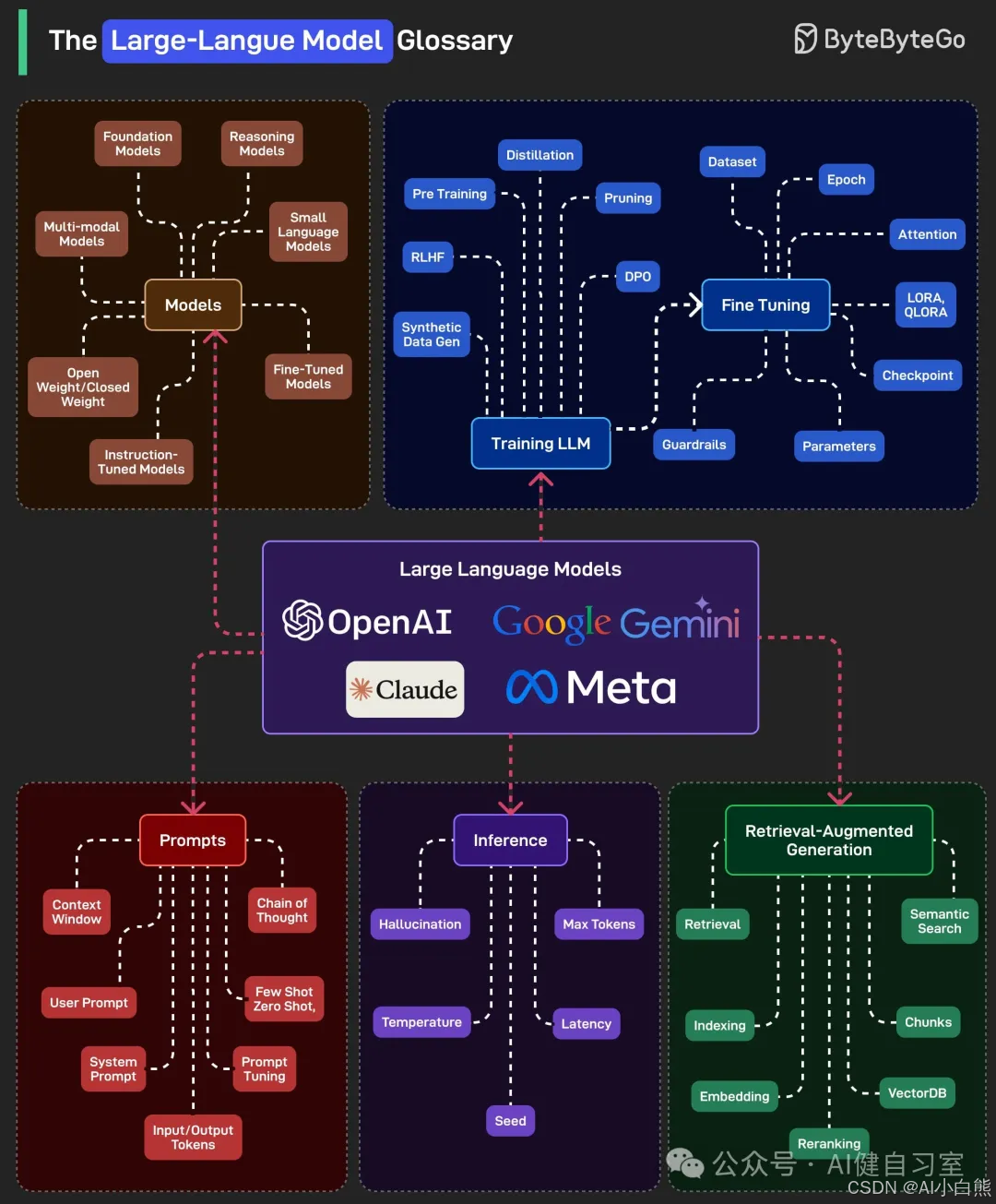
📚 大语言模型:AI界的"超级英雄"
你是否好奇ChatGPT、Claude和Gemini等AI助手背后的技术原理?它们都属于大语言模型(Large Language Models,简称LLMs)家族,这些模型正在重新定义人类与计算机的交互方式。
如今,OpenAI、Google、Amazon、Anthropic和Meta等科技巨头都在这一领域展开激烈竞争。但你知道吗?这些看似神奇的AI系统实际上由几个核心部分构成,理解了这些组成部分,你就能洞悉整个AI革命的本质!
🧩 大语言模型的"全家福":七大模型类型详解
大语言模型并非千篇一律,它们根据用途和结构可以分为多种类型:
📌 基础与专用模型
-
- 基础模型(Foundation Models):💪 作为其他模型的"地基",拥有海量参数和广泛知识
-
- 推理模型(Reasoning Models):🧠 特别强化了逻辑思维和推理能力
-
- 多模态模型(Multi-modal Models):👁️🗨️ 能同时理解文字、图像、音频等多种信息
-
- 小语言模型(Small Language Models):🚶♂️ 轻量级设计,适合资源受限场景
-
- 指令微调模型(Instruction-Tuned Models):📝 针对特定指令优化过的模型
-
- 开放/闭源权重模型(Open/Closed Weight):🔓/🔒 根据是否公开内部参数区分
-
- 微调模型(Fine-Tuned Models):🎯 在通用模型基础上针对特定任务进一步优化
💡 小贴士:不同类型的模型各有优势,选择时应根据实际需求考量。例如,资源有限时可选择小语言模型;需要处理图像时,多模态模型是更好的选择。
🔬 揭秘训练过程:大模型是如何"学习"的?
训练一个强大的大语言模型就像培养一个超级学霸,需要经过一系列精心设计的学习阶段:
📊 核心训练步骤
-
- 预训练(Pre Training):👶 模型的"童年",在海量文本上学习语言基础
-
- 蒸馏(Distillation):📚➡️📄 将"大部头"知识压缩成"精华版"
-
- 剪枝(Pruning):✂️ 移除"多余"神经元,保留精华
-
- RLHF(强化学习):👨🏫 通过人类反馈不断改进
-
- DPO(直接偏好优化):🎯 直接学习人类的喜好
-
- 合成数据生成:🧪 创造新的训练素材
-
- 微调(Fine Tuning):🔧 针对特定领域进行专门优化
⚙️ 关键技术参数
- • 参数(Parameters):模型的"大脑细胞"数量
- • 检查点(Checkpoint):训练过程的"存档点"
- • Epoch:完整数据集的一次学习周期
- • 注意力机制(Attention):模型的"集中力"系统
- • LoRA/QLoRA:高效微调的"小窍门"
- • Guardrails:确保模型输出安全的"护栏"
📌 重点提示:训练大语言模型不仅需要海量数据和计算资源,更需要精细的调优和安全措施。这也是为什么顶尖模型通常由资源雄厚的科技巨头开发。
🎯 提示工程:与AI对话的艺术与科学
想要让大语言模型按照你的意图工作,掌握提示工程(Prompt Engineering)技巧至关重要:
🔑 提示工程核心要素
| 提示元素 | 作用 | 使用技巧 |
|---|---|---|
| 上下文窗口 | 决定模型能"看到"多少历史信息 | 重要信息放在开头或结尾 |
| 用户提示 | 你的具体指令或问题 | 使用明确、具体的语言 |
| 系统提示 | 设定模型的"人格"和行为方式 | 定义角色和输出格式 |
| 思维链 | 引导模型逐步思考 | 添加"让我们一步步思考"等引导语 |
| 少样本/零样本 | 通过例子教会模型 | 提供1-3个高质量示例 |
💡 提示技巧速查表
- • 使用明确指令:说"列出5点关于…"比"告诉我…"更有效
- • 设定输出格式:预先指定"用表格回答"或"以markdown格式输出"
- • 使用角色设定:“作为一名经验丰富的数据科学家…”
- • 分解复杂问题:“首先分析…然后总结…”
- • 指定思考过程:“请先思考各种可能性,然后给出最佳方案”
🚀 进阶提示:优秀的提示不是一蹴而就的,而是需要不断迭代和改进。尝试不同的表述方式,观察哪种能带来最佳结果。
🧠 推理:模型如何思考与回答
当模型收到你的提示后,它会通过推理(Inference)过程生成回答:
⚖️ 关键推理参数
- • 幻觉(Hallucination):🤪 模型"编造"不实信息的现象
- • 最大标记数(Max Tokens):📏 限制回答的长度
- • 温度(Temperature):🌡️ 控制回答的创造性与随机性
- • 低温度(接近0):更确定、一致的回答
- • 高温度(接近1):更多样、创造性的回答
- • 延迟(Latency):⏱️ 从提问到回答的时间间隔
- • 种子(Seed):🌱 确保相同提示能得到一致回答的"魔法数字"
🔍 如何减少AI幻觉?
-
- 提供充分的上下文信息
-
- 要求模型在不确定时明确表示
-
- 使用低温度设置获取更可靠的回答
-
- 请求模型引用信息来源
-
- 使用检索增强生成(RAG)技术
# 设置推理参数的简单示例代码
response = model.generate(
prompt="请解释量子计算的基本原理",
max_tokens=500, # 限制回答长度
temperature=0.3, # 低温度,更确定的回答
seed=42 # 固定种子,确保结果可复现
)
📚 检索增强生成:让AI变得更"聪明"
检索增强生成(Retrieval-Augmented Generation,简称RAG)技术是提升AI回答质量和减少幻觉的利器:
🧰 RAG技术工具箱
-
- 检索(Retrieval):🔎 从外部数据源查找相关信息
-
- 语义搜索(Semantic Search):💭 基于含义而非关键词的搜索
-
- 索引(Indexing):📇 组织信息以便快速检索
-
- 嵌入(Embedding):🧩 将文本转换为数值向量
-
- 分块(Chunks):✂️ 将长文本分割成适合处理的片段
-
- 向量数据库(VectorDB):💾 存储和检索文本的数值表示
-
- 重新排序(Reranking):⭐ 优化检索结果的相关性
🌟 RAG的实际应用场景
- • 企业知识库:接入内部文档,回答员工问题
- • 个人助理:连接个人笔记和邮件,提供个性化回答
- • 教育辅助:结合教材内容,生成针对性的学习材料
- • 客户支持:整合产品手册和常见问题,提供准确支持
💡 实用建议:构建RAG系统时,合理的文档分块策略和高质量的向量嵌入是成功的关键。尝试使用不同的分块大小和重叠率,找到最适合你的数据特性的配置。
🚀 大语言模型的未来:技术趋势与应用前景
大语言模型技术正在快速发展,以下是几个值得关注的趋势:
-
- 多模态能力增强:👁️👂 更好地理解和生成图像、音频和视频
-
- 小型高效模型:💻 在保持性能的同时大幅减小模型体积
-
- 领域专精化:🔬 针对医疗、法律、金融等特定行业优化
-
- 多智能体协作:🤝 多个AI模型协同工作解决复杂问题
-
- 自主学习能力:📈 模型能够主动学习和改进自身能力
💼 企业应用建议
- • 从特定场景入手:选择一个明确的业务痛点,而非尝试解决所有问题
- • 数据隐私优先:确保敏感数据不会泄露到公共模型
- • 混合应用策略:结合通用模型和专用模型的优势
- • 持续评估与优化:定期检查模型表现并根据反馈调整
🔮 结语:AI新时代,与你同行
大语言模型技术正在重塑我们工作和生活的方式。理解这些技术不仅能帮助我们更好地利用AI工具,还能让我们在这场技术革命中把握先机。
无论你是技术爱好者、开发者还是企业决策者,希望这篇文章能为你打开大语言模型世界的大门,激发你探索和创新的热情!
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~


















 7733
7733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









