






前言
直接基于预训练的大语言模型(LLM)解决时间序列问题,是一个最近的重要研究点。之前的研究中,主要尝试用LLM进行zero-shot learning,或者基于LLM的参数进行finetune。随着研究的深入,研究者发现,单独的一个LLM模型,或者单独的用LLM在时序数据上finetune,并不能取得最优的效果。因此除了上述优化之外,另一些工作尝试同时引入LLM构建文本模型和时序模型,并对两种模态的信息进行对齐,提升时序预测效果。
今天就给大家总结几篇最近一段时间,使用语言模型+时序模型进行融合建模的最新工作。
1、基于Attention的文本时序融合
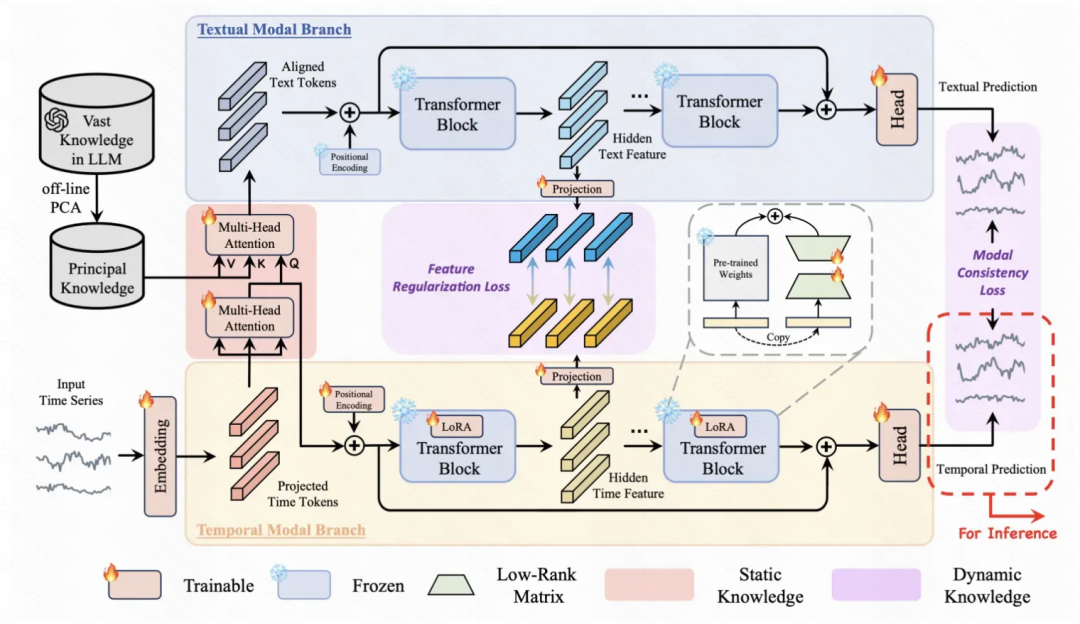
Taming Pre-trained LLMs for Generalised Time Series Forecasting via Cross-modal Knowledge Distillation 提出一种文本+时序模型双分支的结构,都从LLM进行参数初始化,并进行跨模态的表征对齐。整体模型包含两个分支,一个分支是文本模型,使用预训练的GPT2;另一个分支是时间序列模型,用来对时间序列数据进行编码,也使用预训练的GPT2。对于输入的多元时间序列数据,首先使用iTransformer中的方法,将每个变量的序列看成一个token,生成多元时间序列的表征。对于文本模型侧,首先使用PCA对word embedding做一个降维,生成cluster。为了实现时间序列和文本信息的对齐,使用一个multi-head attention,以时间序列表征作为Query,文本模型的cluster表征作为Key和Value计算融合表征。
文本模型和时间序列模型这两个分支都进行时间序列预测。为了对齐两个模态,文中引入了两个约束。第一个约束是,让文本模型和时间序列模型的隐层表征的距离最小;另一个约束是让两个模态的预测结果尽可能相同。在finetune阶段,文本模型侧不更新参数,时间序列模型测使用LoRA进行高效finetune。
2、Patch表征和Token表征隐空间对齐
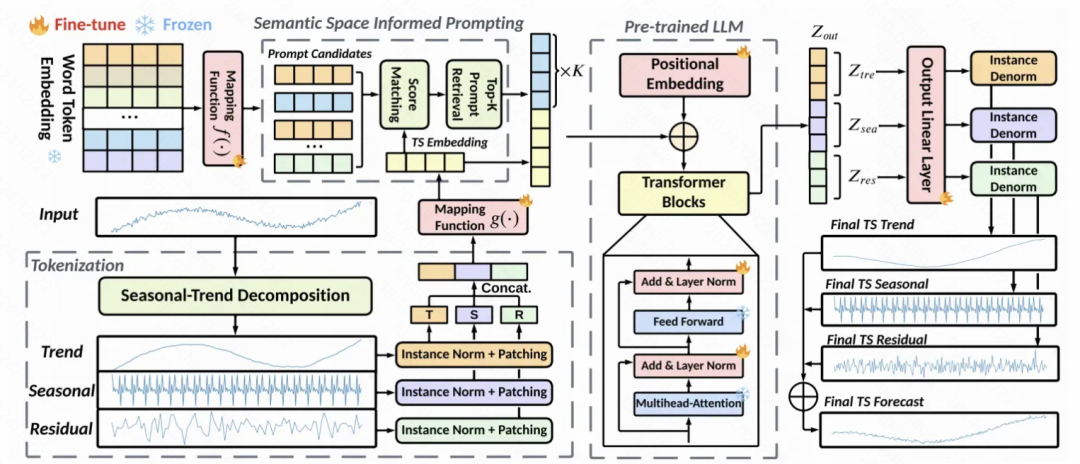
S2IP-LLM: Semantic Space Informed Prompt Learning with LLM for Time Series Forecasting 也是类似的建模方法,结合prompt对时序模型和文本模型进行对齐。本文提出,将时间序列的patch表征和大模型的word embedding在隐空间对齐,然后检索出topK的word embedding,作为隐式的prompt。具体做法为,使用上一步生成的patch embedding,和语言模型中的word embedding计算余弦相似度,选择topK的word embedding,再将这些word embedding作为prompt,拼接到时间序列patch embedding的前方。由于大模型word embedding大多,为了减少计算量,先对word embedding做了一步映射,映射到数量很少的聚类中心上。文中使用GPT2作为语言模型部分,除了position embedding和layer normalization部分的参数外,其余的都冻结住。优化目标除了MSE外,还引入patch embedding和检索出的topK cluster embedding的相似度作为约束,要求二者之间的距离越小越好。
3、原型Embedding对齐文本和时序
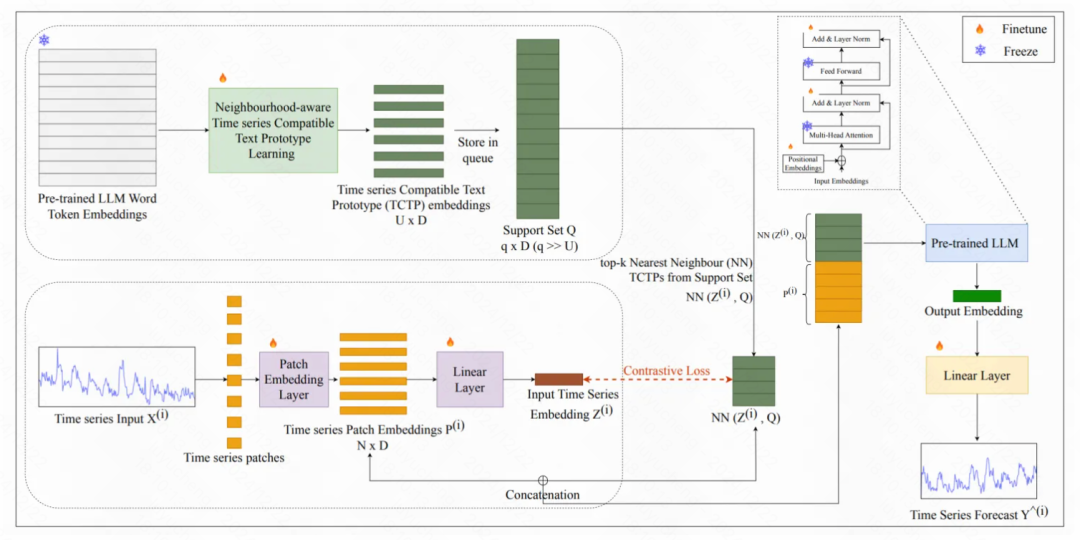
Rethinking Time Series Forecasting with LLMs via Nearest Neighbor Contrastive Learning 提出一种方法是训练几个文本原型向量,并让其对齐时间序列数据表征,最后将这些原型向量作为prompt加入到时间序列输入中。文中提出的文本原型向量名为TCTP。如下图所示,其核心是在LLM的token embedding表征空间中,学一些可学习的embedding,实现一种对原始token embedding聚类的目的。同时,通过对比学习的手段,拉近这些原型embedding和时间序列表征之间的距离,作为一个中间桥梁对齐token embedding和时间序列embedding。
具体的模型结构图如下。TCTP的优化目标有两个。一方面,要求每个token embedding和距离其最近的TCTP embedding尽可能小,实现将TCTP嵌入到token embedding的表征空间。另一方面,对于一个时间序列,使用patch+linear生成的时序表征,和各个TCTP计算距离,选择距离最小的K个TCTP,通过对比学习拉近时序表征和这K个TCTP的距离,实现时序表征到TCTP表征的对齐,进而对齐到预训练语言模型的token表征空间。
在得到TCTP表征后,将其作为soft prompt,拼接到时间序列输入的前面,整体输入到预训练的语言模型中。语言模型输出的表征接一个可学习的线性层,映射到最终的预测结果。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 3062
3062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









