







今天小编给大家介绍两篇联合文本和时序数据进行预训练的文章。
UniTime: A Language-Empowered Unified Model for Cross-Domain Time Series Forecasting
-
文献地址:https://arxiv.org/pdf/2310.09751.pdf
-
代码地址:https://github.com/liuxu77/UniTime

UniTime的目标是构建一个能够对语言和时序模进行跨模态建模的统一架构,并且能够灵活适应多领域具有不同特性的数据。文章提出要有效构建一个能够处理来自多样化领域数据的统一模型,面临以下三大挑战,1)变化的数据特性,不同变量(通道)数量、不同的历史长度和未来预测长度。2)领域混淆问题,不同领域的数据在时间模式或分布上具有显著差异,模型可能会在识别和适应这些差异上遇到困难。3)领域收敛速度不平衡。不同的时间序列领域因其独特的特性而展现出多样的收敛速率,模型可能在单个数据集上出现过拟合,而在其他数据集出现欠拟合。
基于上述问题UniTime使用领域指令和语言-时序变换器来提供识别领域信息并对齐两种模态。具体架构如下:
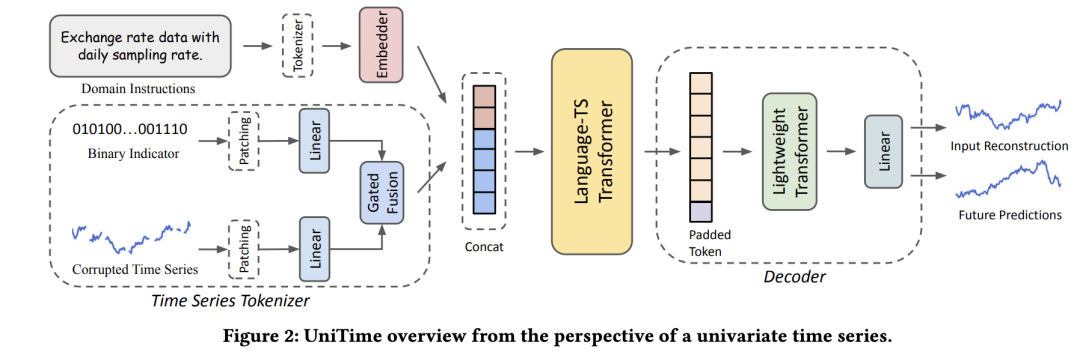
**通道独立:**UniTime采用PatchTST相同的通道独立方式,以灵活处理具有不同通道数的跨领域数据集,同时避免使用统一的嵌入层来处理具有显著不同语义的时间序列。
时序数据tokenizer: 首先将数据分成不同的patch。同时,为了克服不同的时间序列领域表现出不同的收敛速率,具有简单且规则模式的领域易出现过拟合的倾向的问题,文章引入了mask来提高模型的泛化能力。与常规方法中仅构造mask与原数据进行相乘不同,文章设计了一种可学习的的融合机制如下:
decoder-only LLM: 在利用跨时间序列领域训练模型时,尤其是当这些领域在时间模式或分布上表现出显著差异时,模型需要区分并泛化它们,遇到很大的挑战。文章使用领域提示来提供明确的领域识别信息给模型,帮助模型辨识每个时间序列的来源并相应地调整其预测策略。领域指令本质上是描述每个领域数据的句子。它们还由人类制定,以融入对数据的人类先验知识。此外,进一步使用Language-TS来从领域指令和时间序列中学习联合表示,并通过将时间序列与语言模型的共同潜在空间对齐,实现跨领域泛化。
文章将领域信息的表征放在时序表征之前,避免模型在处理时间序列时并未获取领域指令,削弱文本信息的实用性。
Language-TS Transfomrer 使用GPT-2的参数进行初始化。

考虑到文本的存在,Language-TS Transfomrer输出表征序列的长度可能不同,无法直接用简单的线性层融合后进行预测。因此,文章设置了最大输入长度,对于未达到最大长度的序列,在末尾填补一个重复的可学习的padding token。然后将填补后的序列送入一个轻量级的transformer层。同时文章设置了最大的预测长度,以统一模型训练过程。模型训练目标函数包含重构误差和预测误差。
注意,模型训练过程中作者使用了一个小技巧来避免多领域数据不稳定的问题。具体来说,文章通过从包含所有涉及时间序列领域的所有训练数据的池中随机选择实例来构建训练batch。每个batch只包含来自单一领域的数据,因为每个领域的通道数量和序列长度不同。此外,对于那些训练样本明显少于其他领域的领域,进行过采样,以平衡各领域数据集,我们确保模型充分接触到这些代表性不足的领域,防止它们被其他领域所掩盖。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 763
763

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









