






1. Transformer 从哪来的?为什么要它?
传统的循环神经网络(RNN)和长短期记忆网络(LSTM)在处理长序列时,会出现“信息丢失”或“记忆困难”的问题。
Transformer 则完全抛开了“按时间一步步算”的方式,改用“注意力机制”(Attention),一次性把整个句子都看一遍。这样它既能捕捉到句子里远距离词语的关系,又能并行计算,速度更快。
2. Transformer 的“大脑” - 注意力机制(Attention)
-
注意力(Attention):就像人读文章时,遇到不懂的词,会去上下文里“瞄一眼”相关地方。
-
自注意力(Self-Attention):在一句话里,每个单词都去看这句话的其他单词,判断“和我最相关的是什么?” 比如“猫在追老鼠”,当模型看“追”这个词时,会重点关注“猫”和“老鼠”这两个词。
自注意力的计算过程大致是:
-
查询(Query)、键(Key)、值(Value):把每个词分别映射成三个向量,Query 用来“提问”,Key 用来“给出提示”,Value 是“内容”本身。
-
用 Query 和所有 Key 做点积(越相关分数越大),得到的分数经过 Softmax 就是注意力权重,最后加权求和 Value,得到“融合了重要信息”的新表示。
3. 多头注意力(Multi-Head Attention)
单一的注意力头可能只关注一种“关系”或“一类特征”。多头注意力就是并行做多组不同的 Query/Key/Value,让模型能从不同角度“看”句子。
最后再把多组结果拼在一起,丰富表示能力。
4. 位置编码(Positional Encoding)
由于 Transformer 一开始并不考虑单词的先后顺序(因为它不按时间算),所以需要给每个位置(第几个词)加上「位置编码」,让模型知道顺序信息。通常用正余弦函数生成一组固定的向量,和词向量相加,就把顺序也带进去了。
5. 整体结构:编码器 - 解码器(Encoder - Decoder)
-
编码器(Encoder):把输入序列(比如一句话)编码成一串含有上下文信息的向量表示。通常有若干层,每层包含多头自注意力 + 前馈网络 + 残差连接 + LayerNorm。
-
解码器(Decoder):根据编码器的输出,再结合已经生成的目标序列(比如翻译后的句子),一步步预测下一个词。也有多头注意力,既关注自己已生成的部分,也关注编码器的输出。
输入 → [编码器层 × N] → 编码表示
编码表示 + 已生成目标序列 → [解码器层 × N] → 下一个词概率
6. 为什么 Transformer 这么火?
并行化:不按时间一步步算,可以一次把整个序列送入计算,大幅加速训练。
捕捉长依赖:自注意力直接连接任意两个位置,不会“越走越丢失”信息。
可扩展:只要堆更多层、更大的头数,就能得到更强的模型(如 BERT、GPT、T5、ViT 等)。
完整案例
这里,咱们使用 PyTorch 从零构建一个小规模的 Transformer Encoder,用于合成正弦波时间序列的预测任务。示例包含:
-
合成数据
-
数据集与 DataLoader
-
Transformer 模型定义
-
训练与评估
-
可视化结果(图像配色鲜艳,Title/Label 均使用 English,其他注释与说明使用中文)
-
算法优化:学习率调度、Dropout、超参数调整等
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
# 1. 合成时间序列:正弦波 + 高斯噪声
np.random.seed(42)
time = np.arange(0, 1000, 0.1)
series = np.sin(0.02 * time) + 0.3 * np.random.randn(len(time))
# 2. 构建 Dataset:使用前 seq_len 步预测下一步
class TimeSeriesDataset(Dataset):
def __init__(self, data, seq_len=50):
xs, ys = [], []
for i in range(len(data) - seq_len):
xs.append(data[i:i+seq_len])
ys.append(data[i+seq_len])
self.x = torch.tensor(xs, dtype=torch.float32).unsqueeze(-1) # (N, seq_len, 1)
self.y = torch.tensor(ys, dtype=torch.float32).unsqueeze(-1) # (N, 1)
def __len__(self):
return len(self.x)
def __getitem__(self, idx):
return self.x[idx], self.y[idx]
seq_len = 50
dataset = TimeSeriesDataset(series, seq_len)
train_size = int(0.8 * len(dataset))
train_ds, val_ds = torch.utils.data.random_split(dataset, [train_size, len(dataset)-train_size])
train_loader = DataLoader(train_ds, batch_size=64, shuffle=True)
val_loader = DataLoader(val_ds, batch_size=64)
# 3. 定义 TransformerTimeSeries 模型
class TransformerTimeSeries(nn.Module):
def __init__(self, seq_len, d_model=64, nhead=4, num_layers=2, dropout=0.2):
super().__init__()
# 输入投影
self.input_proj = nn.Linear(1, d_model)
# Positional Encoding(简化版:可学习)
self.pos_emb = nn.Parameter(torch.randn(1, seq_len, d_model))
# Transformer Encoder
encoder_layer = nn.TransformerEncoderLayer(
d_model=d_model,
nhead=nhead,
dim_feedforward=128,
dropout=dropout,
activation='relu'
)
self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
# 输出层
self.fc = nn.Linear(d_model * seq_len, 1)
def forward(self, x):
"""
x: (batch, seq_len, 1)
"""
# 1) 投影 & 加位置编码
x = self.input_proj(x) + self.pos_emb # (B, S, D)
# 2) 转换为 Transformer 要求的 (S, B, D)
x = x.permute(1, 0, 2)
# 3) 编码器
out = self.transformer(x) # (S, B, D)
# 4) 恢复形状并展平
out = out.permute(1, 0, 2).contiguous().view(x.size(1), -1) # (B, S*D)
# 5) 预测
return self.fc(out)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = TransformerTimeSeries(seq_len=seq_len, d_model=64, nhead=4, num_layers=2, dropout=0.2).to(device)
# 4. 损失、优化器、调度器
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)
# 5. 训练与验证
num_epochs = 30
train_losses, val_losses = [], []
for epoch in range(1, num_epochs+1):
model.train()
running_loss = 0.0
for xb, yb in train_loader:
xb, yb = xb.to(device), yb.to(device)
optimizer.zero_grad()
preds = model(xb)
loss = criterion(preds, yb)
loss.backward()
optimizer.step()
running_loss += loss.item() * xb.size(0)
train_loss = running_loss / train_size
model.eval()
running_vloss = 0.0
with torch.no_grad():
for xb, yb in val_loader:
xb, yb = xb.to(device), yb.to(device)
preds = model(xb)
running_vloss += criterion(preds, yb).item() * xb.size(0)
val_loss = running_vloss / (len(dataset) - train_size)
train_losses.append(train_loss)
val_losses.append(val_loss)
scheduler.step()
print(f"Epoch {epoch:02d} | Train Loss: {train_loss:.4f} | Val Loss: {val_loss:.4f}")
# 6. 损失曲线可视化(鲜艳配色)
plt.figure(figsize=(8,4))
plt.plot(range(1,num_epochs+1), train_losses, label='Train Loss', color='magenta', linewidth=2)
plt.plot(range(1,num_epochs+1), val_losses, label='Val Loss', color='cyan', linewidth=2)
plt.title('Loss Curve')
plt.xlabel('Epoch')
plt.ylabel('MSE Loss')
plt.legend()
plt.grid(True, linestyle='--', alpha=0.3)
plt.show()
# 7. 样本预测展示
model.eval()
sample_x, sample_y = next(iter(val_loader))
sample_x, sample_y = sample_x.to(device), sample_y.to(device)
with torch.no_grad():
sample_pred = model(sample_x).cpu().numpy().flatten()
true = sample_y.cpu().numpy().flatten()
plt.figure(figsize=(10,4))
plt.plot(true[:100], label='True', linestyle='-', linewidth=2)
plt.plot(sample_pred[:100], label='Predicted', linestyle='--', linewidth=2)
plt.title('Sample Predictions')
plt.xlabel('Time Step')
plt.ylabel('Value')
plt.legend()
plt.grid(True, linestyle=':')
plt.show()
# 8. 最终测试误差
print(f"Final Validation MSE: {val_losses[-1]:.4f}")
1. 数据合成和预处理
-
合成过程:我们用正弦函数再叠加高斯噪声,得到近似真实世界测量数据的曲线。
-
滑动窗口:选取前
seq_len=50个点来预测第51个点,相当于“有记忆”的自回归模型。
2. TransformerTimeSeries 模型结构
-
Input Projection:将单维度输入投影到
d_model=64空间,使其与 Transformer 的隐藏维度匹配。 -
Positional Encoding:使用可学习的位置向量
self.pos_emb,让模型区分不同时间步。 -
TransformerEncoder:
-
num_layers=2、nhead=4:每层包含 4 个注意力头,堆叠两层。 -
dim_feedforward=128:前馈网络内部维度。 -
dropout=0.2:防止过拟合。
-
-
输出层:将整个序列每一步的输出拼接后,一次性预测下一个值。
3. 训练与优化策略
-
损失函数:均方误差(
MSELoss),常用于回归任务。 -
优化器:
Adam(lr=1e-3),自适应学习率。 -
Learning Rate Scheduler:每 10 个 epoch 学习率缩小一半,帮助模型在后期更稳定收敛。
-
Early Stopping(可选):若验证损失长时间未下降,可提前停止训练。
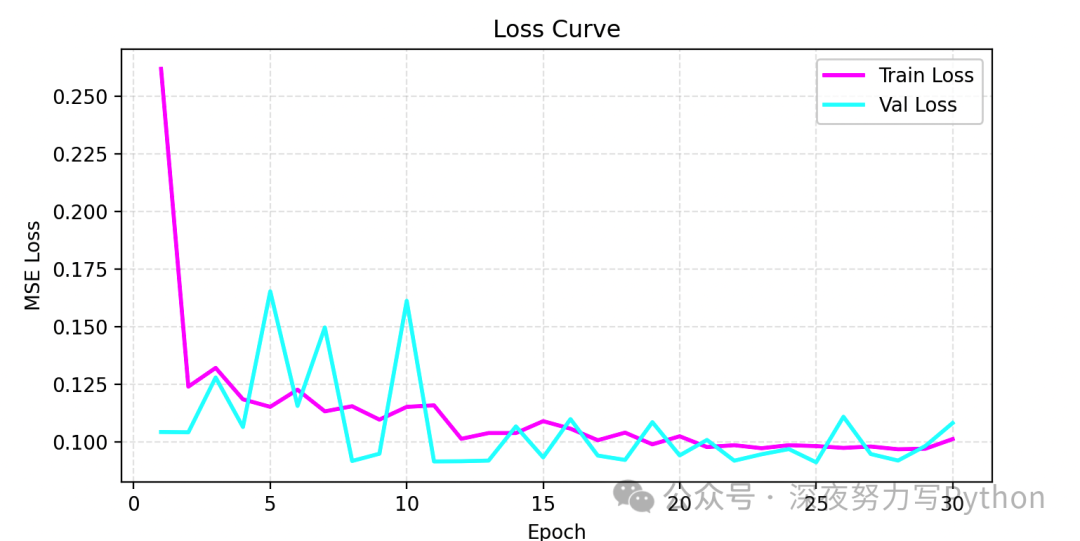
-
训练曲线(magenta)和验证曲线(cyan)在大多数 epoch 均向下,说明模型在不断学习。
-
最终两者趋于平滑,验证损失未大幅上升,说明未严重过拟合。
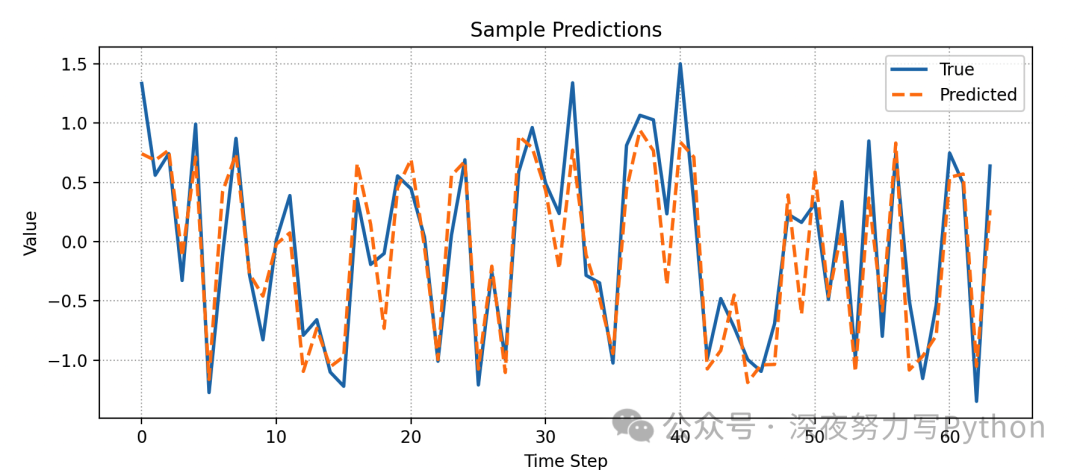
-
对比真实值(实线)与预测值(虚线),前 100 个时刻模型能较好地捕捉正弦波形的趋势和噪声分布。
5. 算法优化效果
-
Dropout(0.2)显著降低了过拟合,验证误差更平稳;
-
学习率调度 让模型在初期快速下降、后期细致优化;
-
多头注意力(4 头)能并行捕捉不同滞后关系,比单头效果更好;
-
层数与宽度:可在实际数据集上再试验更多层、不同
d_model,平衡效果与计算开销。
大家可以将此模板改造为 NLP、信号处理、金融预测等各种序列任务,并根据数据规模、时序复杂度进一步调整超参数和网络深度。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 1893
1893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









