






凡事预则立,不立则废,学习 AI 也不例外。过去,我已经分享了不少关于**RAG(检索增强生成)**的内容。
最近,越来越多新朋友加入,为了让大家快速上手,我特意整理了一份RAG关键知识总结,让你系统掌握信息检索、文本向量化以及 BGE-M3 embedding 的核心要点。
话不多说,干货开始!👇
本文整理一些文本向量化(embedding)和信息检索的知识,它们是如今大模型生成文本时常用的技术 —— “增强检索生成”(RAG)—— 的基础。
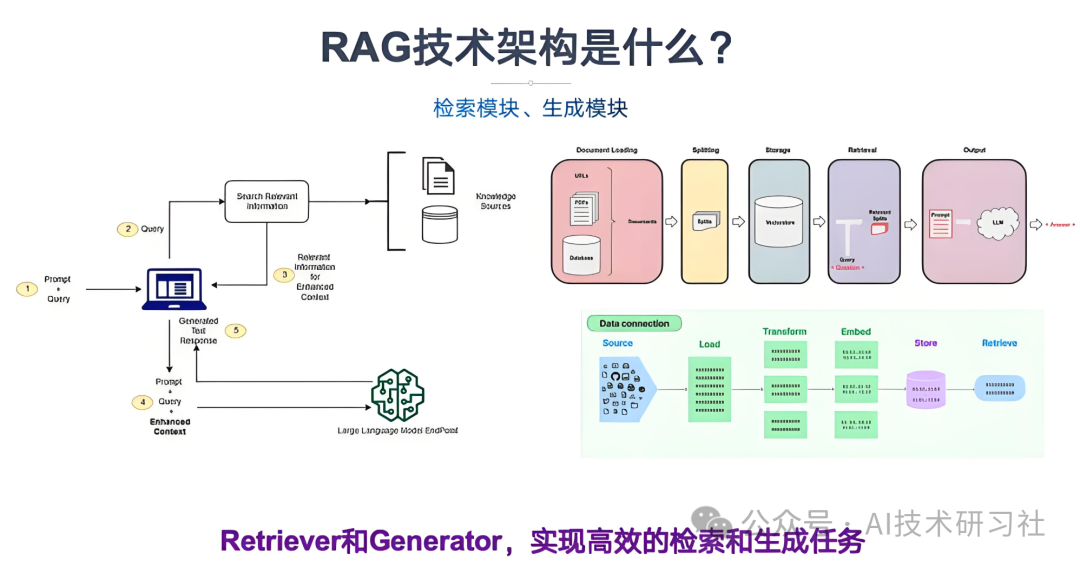
RAG (Retrieval-Augmented Generation,检索增强生成),是一种利用信息检索(Information Retrieval) 技术增强大模型生成效果(generation)的技术。RAG 在步骤上很简单。
- 搭建高质量文档数据库
- 对优质文档进行某种格式的转换(或称编码),例如基于 BERT 将文本段落转换成 数值格式的向量(这个过程称为
embedding),然后 - 将这些 embeddings 存储到合适的数据库(例如 ES 或向量数据库);
- 对优质文档进行某种格式的转换(或称编码),例如基于 BERT 将文本段落转换成 数值格式的向量(这个过程称为
- 针对用户输入进行数据库检索
- 对用户输入的 query 进行相同的转换(embedding),然后
- 利用最近邻等相似性算法,在文档库中寻找最相似的文本段落(与给定问题最相关的段落);
- 大模型生成返回给用户的内容
- 将找到文本段落送到大模型,辅助生成最终的输出文本,返回给用户。
本文主要关注以上 1 & 2 步骤中的 embedding & retrieval 阶段。
1 信息检索(information retrieval)技术三大发展阶段
信息检索的技术发展大致可分为三个阶段:
- 基于统计信息的关键字匹配(statistical keyword matching)
- 是一种
sparse embedding—— embedding 向量的大部分字段都是 0;
- 是一种
- 基于深度学习模型的上下文和语义理解,
- 属于
dense embedding—— embedding 向量的大部分字段都非零;
- 属于
- 所谓的“学习型”表示,组合上面两种的优点,称为
learned sparse embedding- 既有深度学习模型的上下文和语义理解能力;
- 又具备稀疏表示的可解释性(interpretability of sparse representations)和低计算复杂度。
下面分别来看。
1.1 基于统计信息和关键词匹配(1970s-2010s)
1.1.1 典型算法:TF-IDF、BM25
早期信息检索系统主要是基于统计信息 + 匹配关键词,算法包括,
-
TF-IDF
(term frequency - inverse document frequency), 1970s
-
BM25 (Best Matching), 1980s
- based on the
probabilistic retrieval frameworkdeveloped in the 1970s and 1980s. - BM25 is a
bag-of-wordsretrieval function that ranks a set of documents based on the query terms appearing in each document.
- based on the
1.1.2 原理
分析语料库的词频和分布(term frequency and distribution), 作为评估文档的相关性(document relevance)的基础。
1.1.3 优缺点
- 优点:方法简单,效果不错,所以使用很广泛。
- 缺点:单纯根据词频等统计和关键字检索做判断,不理解语义。
1.2 基于深度学习和上下文语义
1.2.1 Word2Vec (Google, 2013)
2013 年,谷歌提出了 Word2Vec,
- 首次尝试使用高维向量来表示单词,能分辨它们细微的语义差别;
- 标志着向机器学习驱动的信息检索的转变。
1.2.2 BERT (Google, 2019)
基于 transformer 的预训练(pretrain)语言模型 BERT 的出现,彻底颠覆了传统的信息检索范式。
核心设计和优点
- transformer 的核心是 self-attention,
- self-attention 能量化给定单词与句子中其他单词的关联性程度,
- 换句话说就是:能在上下文中分辨单词的含义;
- BERT 是双向(前向+后向)transformer,
- 可以理解为在预训练时,每个句子正向读一遍,反向再读一遍;
- 能更好地捕获句子的上下文语义(contextual semantics);
- 最终输出是一个 dense vector,本质上是对语义的压缩;
- 基于 dense vector 描述,用最近邻算法就能对给定的 query 进行检索,强大且语义准确。
局限性:领域外(Out-of-Domain)信息检索效果差
BERT 严重依赖预训练数据集的领域知识(domain-specific knowledge), 预训练过程使 BERT 偏向于预训练数据的特征, 因此在领域外(Out-Of-Domain),例如没有见过的文本片段,表现就不行了。
解决方式之一是**fine-tune**(精调/微调),但成本相对较高, 因为准备高质量数据集的成本是很高的。
另一方面,尽管传统 sparse embedding 在词汇不匹配问题时虽然也存在挑战, 但在领域外信息检索中,它们的表现却优于 BERT。 这是因为在这类算法中,未识别的术语不是靠“学习”,而是单纯靠“匹配”。
1.3 学习型:组合前两种的优点
1.3.1 原理:传统 sparse vector 与上下文化信息的融合
- 先通过 BERT 等深度学习模型生成 dense embedding;
- 再引入额外的步骤对以上 dense embedding 进行稀疏化,得到一个 sparse embedding;
代表算法:BGE-M3。
1.3.2 与传统 sparse embedding 的区别
根据以上描述,乍一看,这种 learned sparse embedding 与传统 sparse embedding 好像没太大区别, 但实际上二者有着本质不同,这种 embedding,
- 引入了 Token Importance Estimation;
- 既保留了关键词搜索能力,又利用上下文信息,丰富了 embedding 的稀疏表示;
- 能够辨别相邻或相关的 token 的重要性,即使这些 token 在文本中没有明确出现。
1.3.3 优点
- 将稀疏表示与学习上下文结合,同时具备精确匹配和语义理解两大能力,在领域外场景有很强的泛化能力;
- 与 dense embedding 相比更简洁,只保留了最核心的文本信息;
- 固有的稀疏性使向量相似性搜索所需的计算资源极少;
- 术语匹配特性还增强了可解释性,能够更精确地洞察底层的检索过程,提高了系统的透明度。
2 信息检索:三种 embedding 的对比
简单来说, vector embedding,或称向量表示,是一个单词或句子在高维向量空间中的数值表示。
- 高维空间:一个维度能代表一个特征或属性,高维意味着分辨率高,能区分细微的语义差异;
- 数值表示:一个 embedding 一般就是一个浮点数数组,所以方便计算。
对应上一节介绍的三个主要发展阶段,常见的有三种 embedding 类型:
- traditional sparse embedding
- dense embedding
- learned sparse embedding
2.1 Sparse embedding (lexical matching)
- 映射成一个高维(维度一般就是 vocabulary 空间大小)向量
- 向量的大部分元素都是 0,非零值表明 token 在特定文档中的相对重要性,只为那些输入文本中出现过的 token 计算权重
- 典型模型:BM25(对 TF-IDF 的改进)
非常适合关键词匹配任务(keyword-matching tasks)。
2.2 Dense embedding (e.g. BERT-based)
- 映射到一个(相对低维)向量,所有维度都非零
- 相比 sparse embedding 维度要低很多,例如基于 BERT 默认
1x768维度; - 典型模型:BGE-v1.5
所有维度都非零,包含语义理解,信息非常丰富,因此适用于 语义搜索任务(semantic search tasks)。
Multi-vector retrieval
- 用多个向量表示一段文本,可以看做是对 dense retrieval 的一种扩展
- 模型:ColBERT
2.3 Learned sparse embedding
结合了传统 sparse embedding 的精确度和 dense embedding 的语义丰富性,
- 可以通过深度学习模型“学习”相关 token 的重要性,即使是一些并未出现过的 token,
- 生成的“学习型”稀疏表示,能有效捕捉 query 和 doc 中的关键词。
3 Embedding & retrieval 工作原理详解
这里主要介绍 BGE-M3 模型的原理。BGE-M3 建立在 BERT 之上,因此需要先回顾 BERT 的基本原理。
3.1 BERT 是如何工作的
3.1.1 理论基础
- BERT 论文:BERT:预训练深度双向 Transformers 做语言理解(Google,2019)
- BERT 基于 transformer,后者的核心是 self-attention
- Transformer 是如何工作的:600 行 Python 代码实现 self-attention 和两类 Transformer(2019)
- 什么是 GPT?Transformer 工作原理的动画展示(2024)
3.1.2 BERT dense embedding 工作流
以输入 "Milvus is a vector database built for scalable similarity search" 为例,工作过程 [2]:
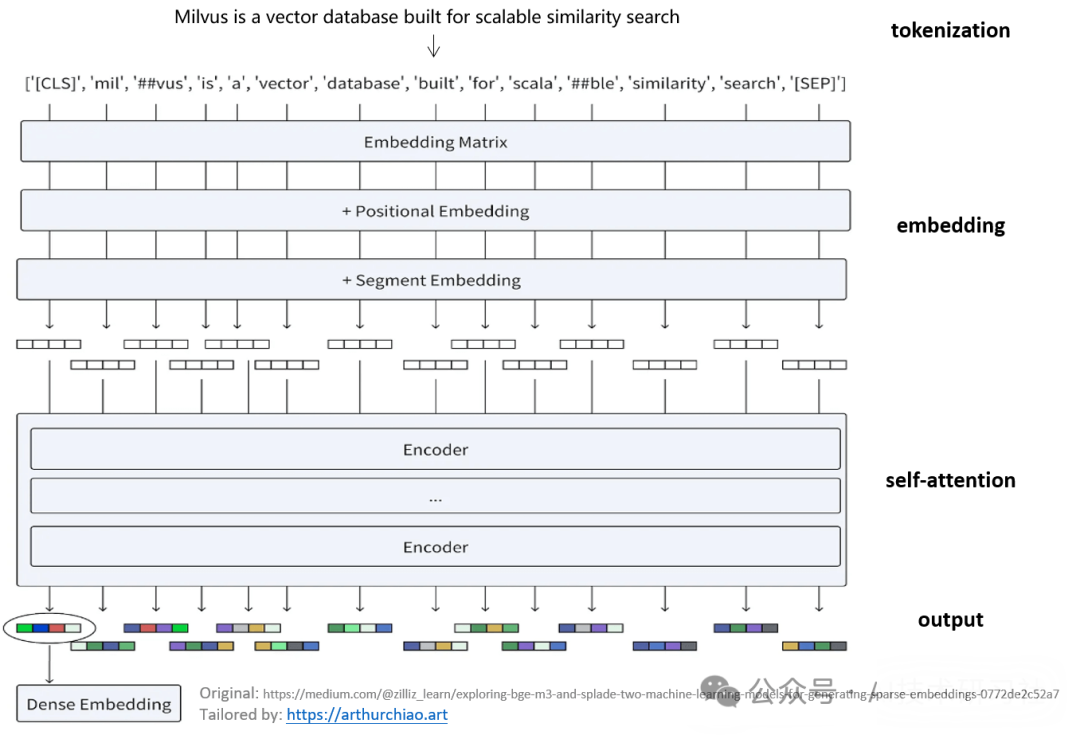
Fig. BERT dense embedding.

最终生成的 dense embedding 能够捕捉单个单词的含义及其在句子中的相互关系。
理解 BERT 是如何生成 dense embedding 之后,接下来看看基于 BERT dense embedding 的信息检索是如何工作的。
3.2 基于 BERT dense embedding 的文档检索是如何工作的
有了 dense embedding 之后,针对给定文本输入检索文档就很简单了,只需要再加一个最近邻之类的算法就行。
下面是两个句子的相似度判断,原理跟文档检索是一样的:
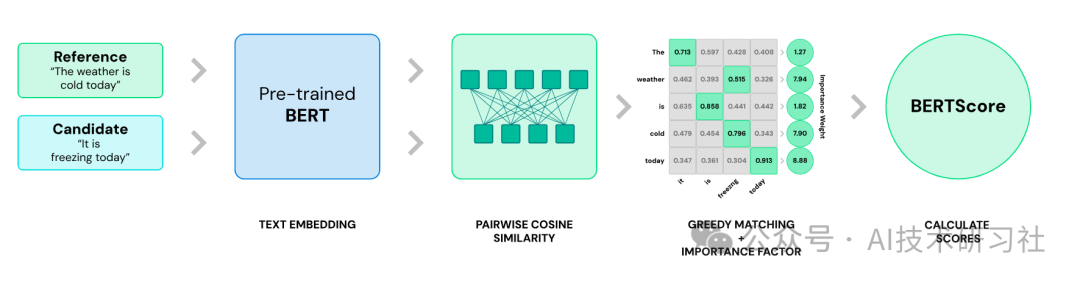
Fig. Similarity score based on BERT embedding. Image source
下面看个具体的 embedding & retrieval 模型:BGE-M3。
3.3 BGE-M3(BERT-based learned sparse embedding)是如何工作的?
BGE 是一系列 embedding 模型,扩展了 BERT 的能力。BGE-M3 是目前最新的一个,3 个 M 是强调的多个 multi- 能力:
- Multi-Functionality
- Multi-Linguisticity
- Multi-Granularity
3.3.1 设计 & 特点

3.3.2 BGE-M3 生成 learned sparse embedding 的过程
还是前面例子提到的输入,
- 先走 BERT dense embedding 的流程,
- 最后加一个 linear 层,得到 learned sparse embedding。

Fig. BGE-M3 learned sparse embedding. Image source
In M3-Embedding, the
[CLS]embedding is used for dense retrieval, while embeddings from other tokens are used for sparse retrieval and multi-vector retrieval [3].
4 BGE-M3 实战
4.1 相似度判断(检索)
$ pip install FlagEmbedding peft sentencepiece
来自官方的代码,稍作修改:
from FlagEmbeddingimportBGEM3FlagModel
model=BGEM3FlagModel('/root/bge-m3',use_fp16=True)
queries=["What is BGE M3?",
"Defination of BM25"]
docs=["BGE M3 is an embedding model supporting dense retrieval, lexical matching and multi-vector interaction.",
"BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document"]
query_embeddings=model.encode(queries,batch_size=12,max_length=8192,)['dense_vecs']
docs_embeddings=model.encode(docs)['dense_vecs']
similarity=query_embeddings@docs_embeddings.T
print(similarity)
这个例子是两个问题,分别去匹配两个答案,看彼此之间的相似度(四种组合),运行结果:
[[0.626 0.348 ]
[0.3499 0.678 ]]
- 问题 1 和答案 1 相似度是 0.6265
- 问题 2 和答案 2 相似度是 0.678
- 问题 1 和答案 2,以及问题 2 和答案 1,相似度只有 0.3x
符合预期。
4.2 精调(fine-tune)
精调的目的是让正样本和负样本的分数差变大。
4.2.1 官方文档
- fine-tune the dense embedding
- fine-tune all embedding function of m3 (dense, sparse and colbert)
4.2.2 训练数据格式及要求
- 文件为
jsonl格式,每行一个 sample;- 例子:toy_train_data/toy_train_data1.jsonl
- 每个 sample 的格式:
{"query": str, "pos": List[str], "neg":List[str]}- 空要写成
"neg": [""],写"neg": []会报错。 - 另外为空时试过删掉
"neg": []也不行,必须得留着这个字段。
- 空要写成
query:用户问题;
pos:正样本列表,简单说就是期望给到用户的回答;不能为空,也就是说必须得有正样本;neg:负样本列表,是避免给到用户的回答。
注意:
- 不是标准 json 格式,所以 python 直接导出一个 json 文件作为训练数据集是不行的。
- sample 不能分行,一个 sample 一行。
4.2.3 精调命令及参数配置
从 huggingface 或国内的 modelscope 下载 BGE-M3 模型,
$ git lfs install
$ git clone https://www.modelscope.cn/Xorbits/bge-m3.git
精调命令:
$ cat sft.sh
#!/bin/bash
num_gpus=1
output_dir=/root/bge-sft-output
model_path=/root/bge-m3
train_data=/data/share/bge-dataset
batch_size=2
query_max_len=128 # max 8192
passage_max_len=1024 # max 8192
torchrun --nproc_per_node$num_gpus\
-m FlagEmbedding.BGE_M3.run \
--output_dir$output_dir\
--model_name_or_path$model_path\
--train_data$train_data\
--learning_rate 1e-5 \
--fp16\
--num_train_epochs 5 \
--per_device_train_batch_size$batch_size\
--dataloader_drop_last True \
--normlized True \
--temperature 0.02 \
--query_max_len$query_max_len\
--passage_max_len$passage_max_len\
--train_group_size 2 \
--negatives_cross_device\
--logging_steps 10 \
--same_task_within_batch True \
--save_steps 10000 \
--unified_finetuning True \
--use_self_distill True
几个参数要特别注意下:
-
query & doc 最大长度BGE-M3 会分别针对 query 和 doc 初始化两个 tokenizer,以上两个参数其实对应

精调快慢取决于 GPU 算力、显存和参数配置,精调开始之后也会打印出预估的完成时间,还是比较准的。
4.2.4 测试精调之后的效果
还是用 4.1 的代码,稍微改一下,不要把 queries 和 docs 作为列表,而是针对每个 query 和 pos/neg 计算相似度得分。 然后针对测试集跑一下,看相似性分数是否有提升。
数据集质量可以的话,精调之后区分度肯定有提升。
4.3 CPU 运行速度优化:将模型转 onnx 格式
如果是在 CPU 上跑模型(不用 GPU), 根据之前实际的 BERT 工程经验,转成 onnx 之后能快几倍,尤其是在 Intel CPU 上 (Intel 公司做了很多优化合并到社区库了)。
但 BGE-M3 官方没有转 onnx 文档,根据第三方的库能成功(稍微改点代码,从本地加载模型),效果待验证。
5 rerank增强对 BGE-M3 的检索结果进行重排序
5.1 rerank/reranker 是什么?
rerank 的意思是“重新排序” —— 对 embedding model 检索得到的多个结果(对应多个分数), 重新计算它们的相似性分数,给出一个排名。这是一个可选模块, 用于对检索结果进行增强,把相似度最高的结果返回给用户。
5.1.1 另一种相似度模型
reranker 也是一类计算相似度的模型,例如这个列表 里的都是 rerank/reranker 模型,
- bge-reranker-v2-m3:与 bge-m3 配套的 reranker
- bge-reranker-v2-gemma:与 google gemma-2b 配套的 reranker
但它们的原理与 BGE-M3 这种 embedding model 有差异。
5.1.2 与 BGE-M3 等模型的差异:cross-encoder vs. bi-encoder
以两个句子的相似度检测为例,
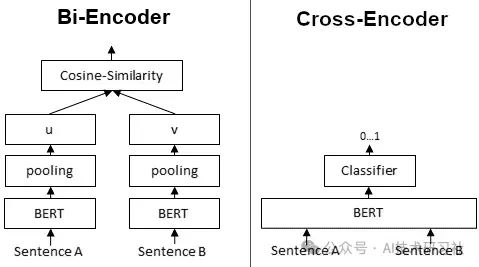
Fig. bi-encoder embedding model vs. cross-encoder model. Image source
- BGE-M3 属于左边那种,所谓的
bi-encoder embedding model, 简单说就是两个句子分别输入模型,得到各自的embedding, 然后根据 embedding vector 计算相似度; - reranker 属于右边那种,所谓的
cross-encoder model,直接得到结果; 如果对 BERT 的工作原理比较熟悉(见 BERT paper),就会明白这其实就是 BERT 判别两个句子 (next sentense prediction, NSP)任务的延伸。
5.2 embedding 和 reranker 工作流
- 用户输入
query和 doc 列表doc1/doc2/doc3/..., - BGE-M3 计算相似分,返回 topN,例如
[{doc1, score1}, {doc2, score2}, {doc3, score3}],其中score1 >= score2 >= score3, - reranker 接受
query和 BGE-M3 的结果,用自己的模型重新计算query和doc1/doc2/doc3的相似度分数。
5.3 BGE-M3 得到相似分之后,为什么要通过 reranker 再计算一遍?
这里可能有个疑问:step 2 不是已经检索出最相关的 N 个 doc 了吗? 为什么又要进入 step3,用另外一个完全不同的模型(reranker)再计算一种相似分呢?
简单来说,embdding 和 rerank 都是 NLP 中理解给定的两个句子(或文本片段)的关系的编码技术。 再参考刚才的图,
Fig. bi-encoder embedding model vs. cross-encoder model. Image source
-
bi-encoder
- 分别对两个句子进行编码,得到两个独立的 embedding,再计算相似度。
- 速度快,准确性相对低。
-
cross-encoder
-
同时对两个句子编码,输出一个相似度分数;也可以换句话说,把两个句子合成一个句子编码,所以两个句子是彼此依赖的;
-
速度慢,准确性高
。
-
总结起来:embedding model 计算的相似度是粗粒度的,只能算粗排; reranker 对 embedding model 得到的若干结果再进行细排; 要体会和理解这种差异,还是要看基础 paper BERT:预训练深度双向 Transformers 做语言理解(Google,2019)。
零基础如何学习AI大模型
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
大模型就业发展前景
根据脉脉发布的《2024年度人才迁徙报告》显示,AI相关岗位的需求在2024年就已经十分强劲,TOP20热招岗位中,有5个与AI相关。
 字节、阿里等多个头部公司AI人才紧缺,包括算法工程师、人工智能工程师、推荐算法、大模型算法以及自然语言处理等。
字节、阿里等多个头部公司AI人才紧缺,包括算法工程师、人工智能工程师、推荐算法、大模型算法以及自然语言处理等。

除了上述技术岗外,AI也催生除了一系列高薪非技术类岗位,如AI产品经理、产品主管等,平均月薪也达到了5-6万左右。
AI正在改变各行各业,行动力强的人,早已吃到了第一波红利。
最后
大模型很多技术干货,都可以共享给你们,如果你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~


















 1779
1779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









