






科技圈又炸了!首个通用具身智能基座大模型 GO1 横空出世,这消息一放出来,整个技术圈和行业直接沸腾,堪称 “王炸” 级别的大事件!
智元发布首个通用具身基座模型一-智元启元大模型(Genie Operator-1),它开创性地提出了Vision-Language-Latent-Action (ViLLA) 架构。
-
该架构由VLM(多模态大模型) + MoE(混合专家)组成,其中VLM借助海量互联网图文数据获得通用场景感知和语言理解能力。
-
MoE中的Latent Planner(隐式规划器借助大量跨本体和人类操作视频数据获得通用的动作理解能力。
-
MoE中的Action Expert(动作专家)借助百万真机数据获得精细的动作执行能力,三者环环相扣,实现了可以利用人类视频学习,完成小样本快速泛化,降低了具身智能门槛,并成功部署到智元多款机器人本体,持续进化,将具身智能推上了一个新台阶。
一、GO1 大模型技术细节剖析
1. 独特的数据吸纳体系
GO1 大模型的构建,宛如搭建一座宏伟的数字金字塔,而其数据来源恰似这座金字塔坚实的基石,极为丰富且多元。
金字塔底层,依托着互联网海量的纯文本与图文数据。这些数据犹如一座知识的宝库,机器人通过对其深入学习,能够理解世间万物的通用知识,洞悉各类场景的特点与规律,为后续更为复杂、深入的学习活动筑牢根基。
例如,通过阅读大量关于家居环境的图文资料,机器人能够了解家具的种类、布局以及常见的生活场景,这为它日后在家居场景中执行任务提供了基础认知。
往上一层,大规模人类操作及跨本体视频数据成为关键的知识源泉。这一数据来源对于机器人而言,无异于一位经验丰富的导师,为其提供了生动且直观的动作操作范例。机器人借助这些视频数据,能够仔细观察人类或其他本体在执行各种任务时的动作模式,从简单的抓取物品到复杂的器械操作,都能一一学习并模仿。
以工业生产场景为例,机器人通过观看工人操作机床的视频,能够学习到精准的操作手法、工具的使用技巧以及工艺流程,从而为自身在工业生产线上的应用积累宝贵经验。
再上一层的仿真数据,则为机器人的能力提升带来了质的飞跃。仿真数据模拟了各种真实世界中可能出现的复杂场景与变化因素,机器人在对这些数据进行学习和训练后,其泛化能力得到极大增强。这意味着机器人不再局限于在特定、单一的场景中执行任务,而是能够灵活应对各种未曾经历过的复杂环境与突发状况。

比如,在救援场景中,仿真数据可以模拟地震后的废墟、火灾现场的浓烟等极端环境,机器人通过学习这些数据,能够在实际救援中迅速适应并展开行动。
金字塔的顶层,是高质量的真机示教数据。这一数据来源专门用于训练机器人精准的动作执行能力。在真机示教过程中,专业人员通过实际操作机器人,为其示范如何以最精准、高效的方式完成各类任务。
例如,在医疗手术辅助场景中,医生通过真机示教,让机器人学习如何在狭小的手术空间内精准操作医疗器械,确保手术的安全与成功。此前,常规的 VLA(视觉语言动作)架构在处理大规模人类及跨本体操作视频数据时,常常面临诸多难题,难以充分挖掘这些数据的价值。
而 GO1 大模型凭借其强大的技术创新能力,成功突破了这一技术瓶颈。智元在去年底推出的 AgiBot World 真机数据集,为 GO1 大模型提供了强大的数据支撑。
该数据集堪称行业内的 “数据宝库”,包含超过 100 万条轨迹、涵盖 217 个任务、涉及五大场景,在长程数据规模、场景范围覆盖面以及数据质量上均远超同类。从简单的抓取、放置等基础操作,到搅拌、折叠等精细长程、双臂协同复杂交互任务,一应俱全。这使得 GO1 大模型在学习过程中能够接触到丰富多样的任务实例,从而不断优化自身的算法和执行能力。
2. 创新的 ViLLA 架构
为了将这些丰富的数据资源充分利用起来,智元团队精心研发了全新的 ViLLA(视觉语言隐式动作)架构。
这一架构堪称 GO1 大模型的 “智慧大脑”,其创新性和先进性在人工智能领域中独树一帜。与传统的 VLA 架构相比,ViLLA 架构具有显著的优势。
传统 VLA 架构在图像 — 文本输入与机器人执行动作之间,往往存在着难以逾越的鸿沟,导致机器人在理解和执行任务时出现偏差或效率低下的问题。
而 ViLLA 架构则巧妙地通过预测 Latent Action Tokens(隐式动作标记),成功地弥合了这一关键鸿沟。
在实际应用中,当机器人接收到图像和文本指令后,ViLLA 架构能够迅速对指令进行解析,并通过预测隐式动作标记,精准地规划出机器人应执行的动作序列。
这种强大的能力极大地增强了机器人的泛化能力,使其能够在不同的场景和任务中快速适应并高效执行。通过在五种不同复杂度任务上的严格测试,结果令人惊叹:相较于已有的最优模型,GO1 的平均成功率大幅提高了 32%。在倒水、清理桌面、补充饮料等日常生活场景中的任务中,GO1 的表现尤为突出。
它能够准确地识别目标物体、判断环境状况,并以流畅、精准的动作完成任务,远远超过最先进的开源具身基座模型。这一卓越的性能表现,充分彰显了 ViLLA 架构在真实世界中实现灵巧操作和长时任务执行的强大能力。
3. 回顾过去
2024年底,智元推出了AgiBot World,包含超过100万条轨迹、涵盖217个任务、涉及五大场景的大规模高质量真机数据集。
基于AgiBot World,智元今天正式发布智元通用具身基座大模型 Genie Operator-1(G0-1) 。
GO-1: VLA进化到ViLLA
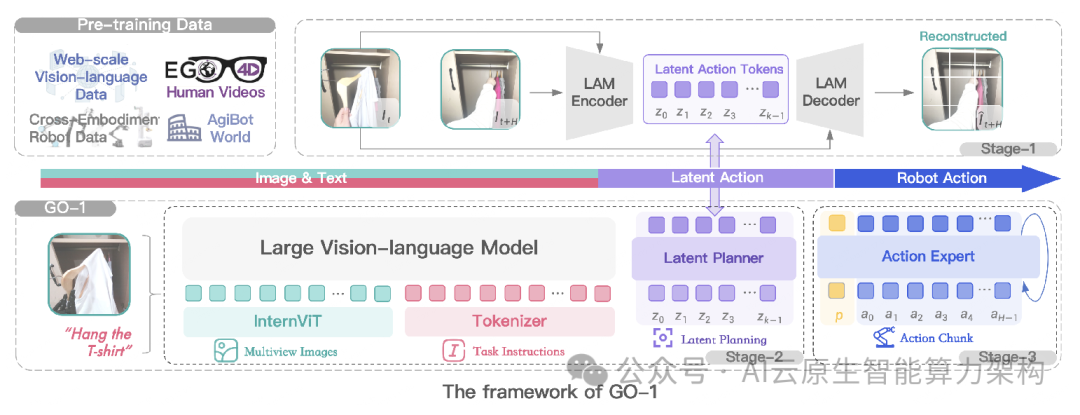
为了有效利用高质量的AgiBot World数据集以及互联网大规模异构视频数据,增强策略的泛化能力,智元提出了 Vision-Language-Latent-Action (ViLLA) 这一创新性架构。
GO-1作为首个通用具身基座大模型,基于ViLLA构建。与Vision-Language-Action (VLA)架构相比,ViLLA 通过预测Latent Action Tokens(隐式动作标记),弥合图像-文本输入与机器人执行动作之间的鸿沟。
在真实世界的灵巧操作和长时任务方面表现卓越,远远超过了已有的开源SOTA模型ViLLA架构是由VLM(多模态大模型)+MoE(混合专家)组成,其中VLM借助海量互联网图文数据获得通用场景感知和语言理解能力,MoE中的Latent Planner(隐式规划器)借助大量跨本体和人类操作数据获得通用的动作理解能力,MoE中的Action Expert(动作专家)借助百万真机数据获得精细的动作执行能力。
在推理时,VLM、Latent Planner和Action Expert三者协同工作:
-
VLM 采用internVL-2B,接收多视角视觉图片、力觉信号、语言输入等多模态信息,进行通用的场景感知和指令理解;
-
Latent Planner是MoE中的一组专家,基于VLM的中间层输出预测Latent Action Tokens作为CoP(Chain ofPlanning,规划链),进行通用的动作理解和规划;
-
Action Expert是MoE中的另外一组专家,基于VLM的中间层输出以及LatentAction Tokens,生成最终的精细动作序列;
3.1 下面展开介绍下MoE里2个关键的组成Latent Planner和Action Expert:
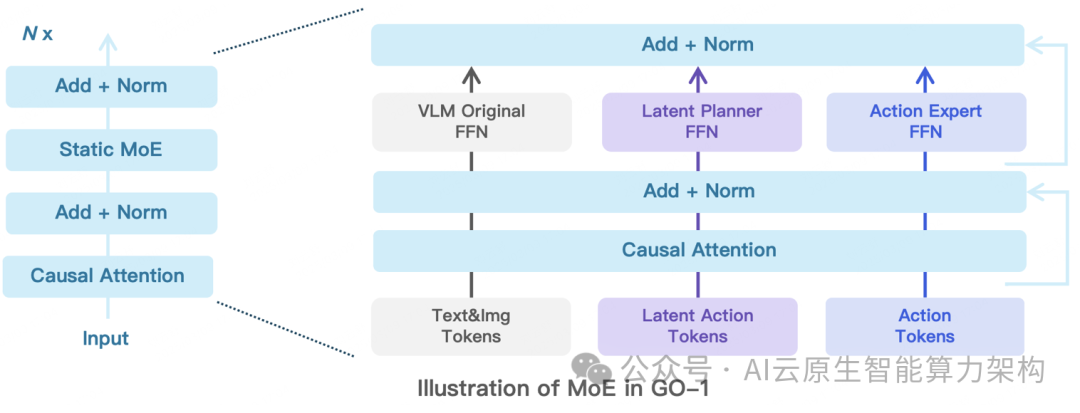
混合专家一: Latent Planner (隐式规划器)
尽管AgiBot World 数据集已经是全球最大的机器人真机示教数据集,但这样高质量带动作标签的真机数据量仍然有限,远少于互联网规模的数据集。
为此,我们采用Latent Actions(隐式动作)来建模当前帧和历史帧之间的隐式变化,然后通过Latent Planner预测这些Latent Actions,从而将异构数据源中真实世界的动作知识转移到通用操作任务中。
Latent Action Model (LAM,隐式动作模型) 主要用于获取当前帧和历史帧之间LatentActions的Groundtruth (真值) ,它由编码器和解码器组成。
其中:编码器采用Spatial-temporalTransformer,并使用Causal Temporal Masks(时序因果掩码)解码器采用SpatialTransformer,以初始帧和离散化的Latent Action Tokens作为输入。
Latent Action Tokens通过VQ-VAE的方式进行量化处理Latent Planner负责预测这些离散的Latent Action Tokens,它与VLM 主干网络共享相同的Transformer 结构,但使用了两套独立的FFN(前馈神经网络)和O/K//O(查询、键、值、输出)投影矩阵。
Latent Planner这组专家会逐层结合 VLM 输出的中间信息,通过Cross EntropyLoss (交叉熵损失) 进行监督训练。
混合专家二: Action Expert (动作专家)
为了实现 High-frequency(高频率) 且 Dexterous(灵活)的操控,我们引入Action Expert, 其采用Diffusion Model作为目标函数来建模低层级动作的连续分布Action Expert结构设计上与Latent Planner类似,也是与 VLM 主干网络共享相同的Transformer 结构,但使用两套独立的FFN和Q/KN/0投影矩阵,它通过DenoisingProcess (去噪过程) 逐步回归动作序列。
Action Expert与VLM、Latent Planner分层结合,确保信息流的一致性与协同优化。
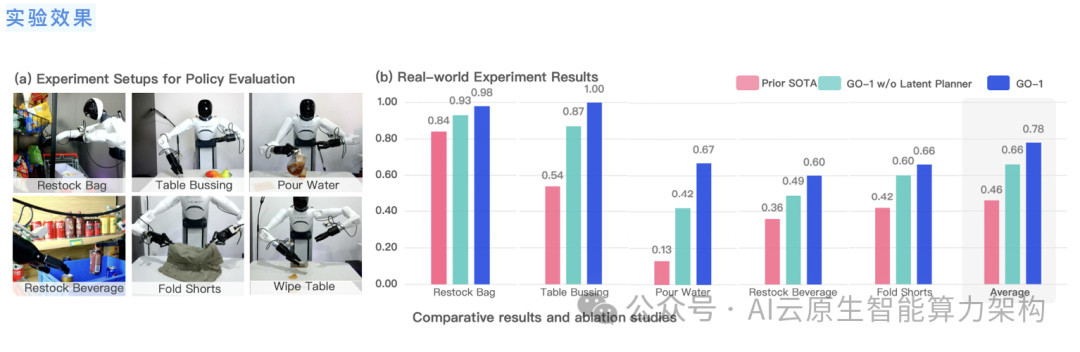
通过Vision-Language-Latent-Action (ViLLA) 创新性架构,我们在五种不同复杂度任务上测试 GO-1.相比已有的最优模型,G0-1成功率大幅领先,平均成功率提高了32%(46%->78%)。
其中“Pour Water”(倒水)、“Table Bussing”(清理桌面) 和“Restock Beverage”(补充饮料) 任务表现尤为突出。
此外我们还单独验证了ViLLA 架构中Latent Planner的作用,可以看到增加Latent Planner可以提升12%的成功率(66%->78%)。
3.2、GO-1具身智能的全面创新
GO-1大模型借助人类和多种机器人数据,让机器人获得了革命性的学习能力,可泛化应用到各类的环境和物品中,快速适应新任务、学习新技能。同时,它还支持部署到不同的机器人本体,高效地完成落地,并在实际的使用中持续不断地快速进化。
这一系列的特点可以归纳为4个方面:
-
人类视频学习: GO-1大模型可以结合互联网视频和真实人类示范进行学习,增强模型对人类行为的理解,更好地为人类服务。
-
小样本快速泛化: GO-1大模型具有强大的泛化能力,能够在极少数据甚至零样本下泛化到新场景、新任务,降低了具身模型的使用门槛,使得后训练成本非常低
-
脑多形: GO-1大模型是通用机器人策略模型,能够在不同机器人形态之间迁移,快速适配到不同本体,群体升智,
-
持续进化: GO-1大模型搭配智元一整套数据回流系统,可以从实际执行遇到的问题数据中持续进化学习,越用越聪明。
智元通用具身基座大模型GO-1的推出,标志着具身智能向通用化、开放化、智能化方向快速迈进。
-
从单一任务到多种任务: 机器人能够在不同场景中执行多种任务,而不需要针对每个新任务重新训练。
-
从封闭环境到开放世界: 机器人不再局限于实验室,而是可以话应多变的真实世界环境从预设程序到指令泛化: 机器人能够理解自然语言指令,并根据语义进行组合推理,而不再局限于预设程序。
4. GO1 大模型对行业的深远影响
4.1 推动具身智能应用的普及
GO1 大模型的诞生,宛如一场及时雨,为具身智能领域带来了蓬勃的发展生机,推动着具身智能应用从实验室走向现实生活的各个角落。
在过去,机器人往往局限于执行特定、单一的任务,功能较为有限,难以满足复杂多变的实际需求。
而 GO1 大模型的出现,彻底改变了这一局面。它赋予了机器人从依赖特定任务的工具,向着具备通用智能的自主体转变的能力。GO1 大模型可泛化应用到各类复杂多样的环境和物品中,能够快速适应全新的任务需求,高效学习新的技能。
无论是在充满挑战的工业生产车间,还是在温馨的家庭生活场景;无论是面对形状各异的工业零部件,还是日常使用的家居用品,GO1 大模型驱动下的机器人都能展现出出色的适应能力和执行能力。
在商业领域,物流仓储行业首当其冲地受益于 GO1 大模型。以往,物流仓储中的货物搬运和分类工作主要依赖人工,效率低下且容易出错。如今,搭载 GO1 大模型的机器人能够快速识别不同货物的形状、大小和重量,根据仓库的布局和存储规则,合理规划搬运路径,高效地完成货物的搬运和分类任务。这不仅大大提高了仓储运作的效率,降低了人力成本,还减少了货物损坏和错放的风险。
在工业领域,生产线上的任务需求常常随着市场变化和产品更新而频繁调整。传统机器人在面对这种变化时,往往需要进行复杂的重新编程和调试,耗时费力。而基于 GO1 大模型的机器人则能够通过对新任务的快速学习和适应,迅速调整自身的动作和操作流程,轻松应对生产线的变化。它们可以精准地完成复杂的装配工作,提高产品质量和生产效率,为工业企业的转型升级提供强大助力。
在家庭场景中,GO1 大模型的应用更是让智能生活变得触手可及。家庭服务机器人能够承担起更多样化的家务任务,如打扫房间、整理物品、照顾老人小孩等。它们可以根据家庭成员的生活习惯和需求,灵活调整任务执行的时间和方式,为人们创造更加舒适、便捷的生活环境。

5. 重塑行业竞争格局
随着 GO1 大模型的震撼发布,整个具身智能行业的竞争格局宛如被一只无形的大手重新洗牌,发生了翻天覆地的变化。
在这场激烈的科技竞赛中,那些具备强大研发实力和深厚数据积累的企业,犹如插上了腾飞的翅膀,借助 GO1 大模型的先进技术,迅速提升自身产品的竞争力,在市场中抢占先机,扩大市场份额。
它们能够将 GO1 大模型与自身的业务优势相结合,开发出更具创新性和实用性的产品与解决方案,满足客户日益多样化的需求。例如,一些大型科技企业可以利用 GO1 大模型,研发出更加智能、高效的工业机器人,为制造业提供全方位的智能化升级服务,从而在工业机器人市场中脱颖而出。
然而,对于一些原本在技术研发上相对滞后的企业而言,GO1 大模型的出现无疑带来了巨大的竞争压力。它们面临着严峻的挑战,如果不能及时跟上技术发展的步伐,加大在具身智能领域的研发投入,提升自身的技术实力,就有可能在市场竞争中逐渐被边缘化,甚至被淘汰出局。
这种竞争压力如同达摩克利斯之剑,高悬在这些企业的头顶,促使它们不得不积极寻求变革和突破。与此同时,GO1 大模型的发布也在行业内引发了一场 “鲶鱼效应”。
它激发了行业内其他企业的创新活力和竞争意识,促使整个行业加大在具身智能领域的研发投入。企业们纷纷加大研发资源的投入,组建专业的研发团队,积极开展技术创新和产品研发工作。
这种良性的竞争环境将推动整个具身智能行业的技术快速发展,不断涌现出更多创新的产品和解决方案,为行业的繁荣发展注入源源不断的动力。
6. 与近期开源大模型的对比分析
6.1 与 DeepSeek 开源大模型
DeepSeek 在大模型开源领域一直以来都表现得极为活跃,犹如一颗耀眼的明星,吸引着全球众多开发者和企业的目光。
其推出的一系列开源模型,如 DeepSeek - R1 等,在全球范围内受到了广泛的关注和应用。
DeepSeek 的优势主要体现在其在模型推理系统等方面的卓越优化。
在模型推理过程中,DeepSeek 通过跨节点批量扩展技术,充分利用分布式计算资源,将推理任务高效地分配到多个计算节点上并行处理,大大提高了推理速度。
同时,计算与通信重叠技术的应用,使得计算过程和数据通信过程能够同时进行,避免了因数据传输等待而造成的时间浪费,进一步提升了系统的整体性能。
相比之下,GO1 大模型则专注于具身智能领域,在机器人动作学习、任务执行等方面展现出独特的技术优势。GO1 大模型通过其独特的数据吸纳体系和创新的 ViLLA 架构,能够让机器人更加深入地理解人类指令,精准地执行各种复杂任务,在适应复杂多变的现实环境方面具有显著优势。
例如,在家庭服务场景中,GO1 大模型驱动的机器人能够更好地理解家庭成员的日常需求,如根据不同时间段的需求准备餐饮、打扫房间等,而 DeepSeek - R1 等模型在这方面的针对性应用则相对较弱。
尽管两者的应用领域有所侧重,但它们都为推动人工智能技术的发展贡献了不可或缺的重要力量。
DeepSeek 在模型推理性能优化方面的成果,为大规模数据处理和实时应用提供了有力支持;而 GO1 大模型在具身智能领域的突破,则为机器人在现实世界中的广泛应用开辟了新的道路。
6.2 与阿里开源大模型
阿里作为科技行业的巨头之一,在开源大模型领域也取得了令人瞩目的成绩。其开源的万相大模型一经推出,便在开源社区引发了强烈反响,迅速成为关注的焦点。
开源仅 6 天,万相大模型就凭借其卓越的性能和广泛的应用潜力,登上了全球开源榜首的宝座,展现出强大的竞争力。
万相大模型在图像、文本等多模态处理方面展现出了惊人的能力。
在图像识别任务中,它能够准确识别各种复杂场景下的物体、人物和事件,识别准确率高达 95% 以上;在文本处理方面,无论是自然语言生成、文本分类还是机器翻译,万相大模型都表现出色。
例如,在机器翻译任务中,它能够将中文准确地翻译成多种外语,翻译质量流畅自然,符合目标语言的表达习惯。相比之下,GO1 大模型专注于具身智能领域,致力于为机器人赋予更强大的行动能力和任务执行能力。
虽然与万相大模型的应用方向有所不同,但两者都反映了企业在人工智能不同细分领域的积极探索和创新精神。
阿里通过万相大模型,在互联网内容创作、智能客服、智能广告等领域取得了显著的应用成果;而智元则借助 GO1 大模型,在机器人领域开启了全新的发展篇章,为机器人在工业、物流、家庭服务等多个行业的应用提供了强大的技术支持。
6.3 与腾讯开源大模型
腾讯同样在积极推进大模型的开源工作,其开源模型在自然语言处理、智能交互等领域展现出了独特的优势。在自然语言处理方面,腾讯的开源模型能够深入理解文本的语义和语境,实现高效的文本分类、情感分析和信息抽取等任务。
例如,在社交媒体舆情监测中,该模型能够快速准确地分析大量用户评论的情感倾向,为企业和政府提供有价值的决策参考。在智能交互领域,腾讯的开源模型支持智能语音助手、聊天机器人等多种应用场景,能够与用户进行自然流畅的对话,提供个性化的服务和解决方案。
与 GO1 大模型相比,腾讯的开源模型更侧重于语言理解和生成等领域,通过对语言数据的深度挖掘和学习,提升机器与人类之间的沟通效率和质量。
而 GO1 大模型则聚焦于让机器人在现实世界中能够更好地感知、理解和行动,实现物理世界与人工智能的深度融合。
在实际应用中,腾讯的开源模型在互联网内容服务、智能办公等领域发挥着重要作用;而 GO1 大模型则为机器人在工业制造、物流配送、家庭服务等需要实际操作和行动的场景中提供了核心技术支撑。
首个通用具身智能基座大模型 GO1 的发布,无疑为人工智能领域注入了一股强大的创新动力。它在技术上的卓越创新以及对行业产生的深远影响,都值得我们给予持续且高度的关注。
随着各大企业在开源大模型领域的不断发力,未来人工智能技术必将迎来更加蓬勃、迅猛的发展,为我们的生活和社会带来翻天覆地的改变。
让我们满怀期待,共同见证科技进步的伟大奇迹,迎接一个充满无限可能的智能新时代。

AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 737
737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









