






对于 LLM,加速推理并降低显存,是两个至关重要的问题。本文将从 Key-Value Cache 出发,介绍两种相关的模型结构改进。分别是 ChatGLM 系列使用的 Multi-Query Attention(MQA) 和 LLama 系列使用的 Grouped-Query Attention(GQA)。希望读完之后,能够明白“为何要做”和“如何去做”。
LLM 普遍采用 decoder-only 的结构,自回归地逐个 token 进行生成。在最基础的设置下,我们传给模型的输入顺序为(假设只生成 5 个词):
prompt -> x0 -> x1 -> x2 -> x3 -> x4 -> x5
用 transformers 库的 pytorh 代码表示为:
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits = model(input_ids)["logits"][:, -1:]
# 取最大概率token为当前时间步输出.
next_token_id = torch.argmax(next_logits,dim=-1)
# 将prompt和历史输出拼接在一起,作为下一步的输入.
input_ids = torch.cat([input_ids, next_token_id], dim=-1)
print("shape of input_ids", input_ids.shape)
每一次推理,都使用完整的历史序列作为 model 的输入,因此 input_ids 不断增长:
shape of input_ids torch.Size([1, 21])
shape of input_ids torch.Size([1, 22])
shape of input_ids torch.Size([1, 23])
shape of input_ids torch.Size([1, 24])
shape of input_ids torch.Size([1, 25])
1. Key-Value Cache
实际上,上述的计算流程在古早 transformer 模型时代就已经被废弃了,因为重复计算实在是太多。
在 Bert 这种的 encoder 结构中,所有的序列位置是并行计算的,Query 、Key 和 Value 都是 [seq_length, hidden_size] 的矩阵。但是到了 LLM 这样的 decoder 结构中,逐个时间步进行生成,Query 退化为 [1, hidden_size] 的向量,Key 和 Value 仍然是 [seq_length, hidden_size] 的矩阵。
以 x=[robot, must, obey, orders] 为例,self-attention 的权重矩阵是一个下三角,每个 token 的后序位置会全部被 mask 住。

self-attention 权重计算

transformers 库支持对 Key-Value Cache 的使用,只要传入一个参数 use_cache=True 即可。
past_key_values = None # 即 key-value cache, 列表结构为 [num_layers, 0 for k, 1 for v, batch_size, length, hidden_dim]
generated_tokens = [] # 记录生成结果.
next_token_id = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
# 只传入当前 token 作为输入.
next_logits, past_key_values = model(next_token_id, past_key_values=past_key_values, use_cache=True).to_tuple()
next_logits = next_logits[:, -1:]
# 取最大概率token为当前时间步输出.
next_token_id = torch.argmax(next_logits, dim=-1)
print("shape of input_ids", next_token_id.shape)
print("length of key-value cache", len(past_key_values[0][0]))
# 只记录, 不参与后续生成.
generated_tokens.append(next_token_id.item())
在这种模式下,每次迭代只输入 next_token_id,而不是完整历史序列 input_ids。因此,model 的输入 next_token_id 在每一次迭代中保持不变,而 past_key_values 不断增长。
shape of input_ids torch.Size([1, 1])
length of key-value cache 20
shape of input_ids torch.Size([1, 1])
length of key-value cache 21
shape of input_ids torch.Size([1, 1])
length of key-value cache 22
shape of input_ids torch.Size([1, 1])
length of key-value cache 23
shape of input_ids torch.Size([1, 1])
length of key-value cache 24
关于具体解释可以看我的另一个回答:Transformer推理性能优化技术很重要的一个就是K V cache,能否通俗分析,可以结合代码?
Key-Value Cache 是一种不影响预测结果的性能优化方法,它有两个主要优势:
-
比起全量计算 QK^T 退化为 qK^T 后大幅削减了FLOPs(FLoating-point OPerations),显著提升推理速度;
-
最大内存消耗随序列变长的增长曲线,从二次方变为线性,得到有效控制;
2. 多轮会话的存储开销
对于 LLM 应用,多轮会话的场景天然地适配 Key-Value Cache 策略。
User:礼拜天之后是星期几?
Assistant:是星期一。
User:那再往后呢?
Assistant:是星期二。
如果不做缓存,就不得不在每一次 user 提问之后,把历史会话内容进行重新编码。用 model.generate() 入口做一个示例:
# 第一轮会话.
prompt = system_prompt + "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"
model_inputs = tokenizer(prompt, return_tensors='pt')
# 无生成历史.
generation_output = model.generate(**model_inputs, max_new_tokens=60, return_dict_in_generate=True)
decoded_output = tokenizer.batch_decode(generation_output.sequences)[0]
# 第二轮会话.
prompt = decoded_output + "\nQuestion: How can I modify the function above to return Mega bytes instead?\n\nAnswer: Here"
model_inputs = tokenizer(prompt, return_tensors='pt')
# 传入 past_key_values.
generation_output = model.generate(
**model_inputs,
past_key_values=generation_output.past_key_values,
max_new_tokens=60,
return_dict_in_generate=True
)
但是,由于 Key-Value Cache 将全部层、全部 attention 头、全部时间步的 K 和 V 都缓存起来,对于一个支持 超长上下文的 LLM 来说,整体的存储开销是非常惊人的。以 Chinese-LLaMA-2-7B-16K 为例:
2 * config.max_position_embeddings * config.num_hidden_layers * config.hidden_size
= 2 * 16384 * 32 * 4096
= 4,294,967,296
将近 43 亿个浮点数!如果用半精度 float16,相当于 8G;即使是最狠的 4-bit 量化,也得占 2G 的显存。这还只是一个轻量化的 LLaMA-7B。
因此,有必要设置针对性的优化方案,削减 K 和 V 对应的存储空间以降低缓存容量。这就是 Multi-Query Attention(MQA) 和 Grouped-Query Attention(GQA)的出发点。
3. Multi-Query Attention(MQA)
MQA:《Fast Transformer Decoding: One Write-Head is All You Need》
“Multi-Query”即只有 Query 进行分头,Key 和 Value 变换为单头维度,在各个注意力头之间共享同一组 KV 映射。即削减了 FLOPs,也降低了 Cache,并且压缩了频繁矩阵拼接的 I/O 耗时。
# query 正常分头.
self.head_dim = self.embed_dim // self.num_heads
# key 和 value 使用单头.
self.kv_heads = 1 if self.multi_query else self.num_heads
# key 和 value 降维.
self.kv_dim = self.kv_heads * self.head_dim
# K,Q,V 映射矩阵,embed_dim(Q) + kv_dim(K) + kv_dim(V)
self.c_attn = nn.Linear(self.embed_dim, self.embed_dim + 2 * self.kv_dim)
# 从 hidden_states 映射为 query \ key \ value.
query, key_value = self.c_attn(hidden_states).split((self.embed_dim, 2 * self.kv_dim), dim=2)
key, value = key_value.split((self.head_dim, self.head_dim), dim=-1)
MQA 在 2019 年就已经发表,目前用在 Falcon、PaLM、MPT、BLOOM 等 LLM 上。
4. Grouped-Query Attention(GQA)
GQA:《GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints》
GQA 是 Google 在 2023 年提出的,作者认为 MQA 砍得太狠了,影响了模型效果。于是改用一种温和策略,对Key 和 Value 先分头,再分组(2或4或8),同一组内共享 KV 矩阵。
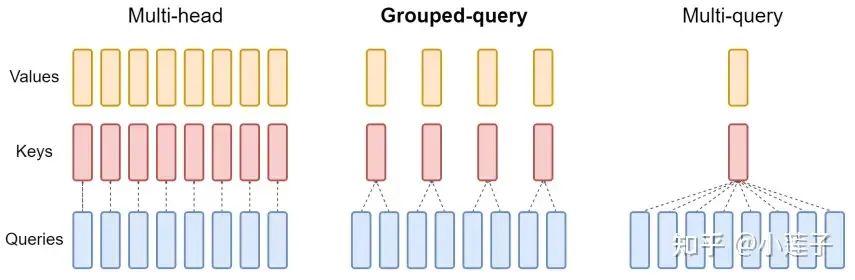
GQA(中间)与 MQA(右边)
论文的对比实验用的是 “Uptraining” 的方法。即,把原始的多头 Key 和 Value 做平均池化,模拟“单头”(MQA)和“多组”(GQA),然后再继续预训练 a=0.05 的原预训练步数。

MQA与GQA效果对比
原版 MHA 的指标是 47.2,MQA 有所衰减为 46.4,GQA-8 回升到 47.1,接近无损了。并且,推理速度上 GQA 并没有明确落后于 MQA。
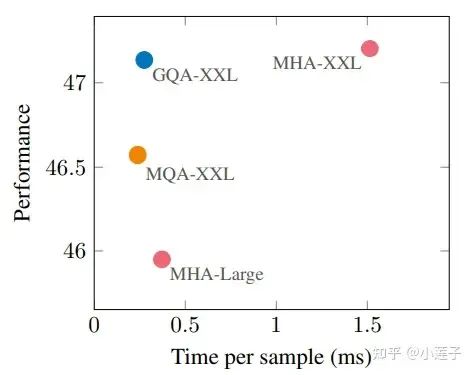
推理速度对比

在大模型时代,我们如何有效的去学习大模型?
现如今大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也_想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把都打包整理好,希望能够真正帮助到大家_。
一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,下面是我整理好的一套完整的学习路线,希望能够帮助到你们学习AI大模型。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF书籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型各大场景实战案例

结语
【一一AGI大模型学习 所有资源获取处(无偿领取)一一】
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈
















 7134
7134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}