






对于 LLM,加速推理并降低显存,是两个至关重要的问题。本文将从 Key-Value Cache 出发,介绍两种相关的模型结构改进。分别是 ChatGLM 系列使用的 Multi-Query Attention(MQA) 和 LLama 系列使用的 Grouped-Query Attention(GQA)。希望读完之后,能够明白“为何要做”和“如何去做”。
LLM 普遍采用 decoder-only 的结构,自回归地逐个 token 进行生成。在最基础的设置下,我们传给模型的输入顺序为(假设只生成 5 个词):
prompt -> x0 -> x1 -> x2 -> x3 -> x4 -> x5
用 transformers 库的 pytorh 代码表示为:
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits = model(input_ids)["logits"][:, -1:]
# 取最大概率token为当前时间步输出.
next_token_id = torch.argmax(next_logits,dim=-1)
# 将prompt和历史输出拼接在一起,作为下一步的输入.
input_ids = torch.cat([input_ids, next_token_id], dim=-1)
print("shape of input_ids", input_ids.shape)
每一次推理,都使用完整的历史序列作为 model 的输入,因此 input_ids 不断增长:
shape of input_ids torch.Size([1, 21])
shape of input_ids torch.Size([1, 22])
shape of input_ids torch.Size([1, 23])
shape of input_ids torch.Size([1, 24])
shape of input_ids torch.Size([1, 25])
1. Key-Value Cache
实际上,上述的计算流程在古早 transformer 模型时代就已经被废弃了,因为重复计算实在是太多。
在 Bert 这种的 encoder 结构中,所有的序列位置是并行计算的,Query 、Key 和 Value 都是 [seq_length, hidden_size] 的矩阵。但是到了 LLM 这样的 decoder 结构中,逐个时间步进行生成,Query 退化为 [1, hidden_size] 的向量,Key 和 Value 仍然是 [seq_length, hidden_size] 的矩阵。
以 x=[robot, must, obey, orders] 为例,self-attention 的权重矩阵是一个下三角,每个 token 的后序位置会全部被 mask 住。


transformers 库支持对 Key-Value Cache 的使用,只要传入一个参数 use_cache=True 即可。
past_key_values = None # 即 key-value cache, 列表结构为 [num_layers, 0 for k, 1 for v, batch_size, length, hidden_dim]
generated_tokens = [] # 记录生成结果.
next_token_id = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
# 只传入当前 token 作为输入.
next_logits, past_key_values = model(next_token_id, past_key_values=past_key_values, use_cache=True).to_tuple()
next_logits = next_logits[:, -1:]
# 取最大概率token为当前时间步输出.
next_token_id = torch.argmax(next_logits, dim=-1)
print("shape of input_ids", next_token_id.shape)
print("length of key-value cache", len(past_key_values[0][0]))
# 只记录, 不参与后续生成.
generated_tokens.append(next_token_id.item())
在这种模式下,每次迭代只输入 next_token_id,而不是完整历史序列 input_ids。因此,model 的输入 next_token_id 在每一次迭代中保持不变,而 past_key_values 不断增长。
shape of input_ids torch.Size([1, 1])
length of key-value cache 20
shape of input_ids torch.Size([1, 1])
length of key-value cache 21
shape of input_ids torch.Size([1, 1])
length of key-value cache 22
shape of input_ids torch.Size([1, 1])
length of key-value cache 23
shape of input_ids torch.Size([1, 1])
length of key-value cache 24
关于具体解释可以看我的另一个回答:Transformer推理性能优化技术很重要的一个就是K V cache,能否通俗分析,可以结合代码?
Key-Value Cache 是一种不影响预测结果的性能优化方法,它有两个主要优势:
-
比起全量计算 QK^T 退化为 qK^T 后大幅削减了FLOPs(FLoating-point OPerations),显著提升推理速度;
-
最大内存消耗随序列变长的增长曲线,从二次方变为线性,得到有效控制;
2. 多轮会话的存储开销
对于 LLM 应用,多轮会话的场景天然地适配 Key-Value Cache 策略。
User:礼拜天之后是星期几?
Assistant:是星期一。
User:那再往后呢?
Assistant:是星期二。
如果不做缓存,就不得不在每一次 user 提问之后,把历史会话内容进行重新编码。用 model.generate() 入口做一个示例:
# 第一轮会话.
prompt = system_prompt + "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"
model_inputs = tokenizer(prompt, return_tensors='pt')
# 无生成历史.
generation_output = model.generate(**model_inputs, max_new_tokens=60, return_dict_in_generate=True)
decoded_output = tokenizer.batch_decode(generation_output.sequences)[0]
# 第二轮会话.
prompt = decoded_output + "\nQuestion: How can I modify the function above to return Mega bytes instead?\n\nAnswer: Here"
model_inputs = tokenizer(prompt, return_tensors='pt')
# 传入 past_key_values.
generation_output = model.generate(
**model_inputs,
past_key_values=generation_output.past_key_values,
max_new_tokens=60,
return_dict_in_generate=True
)
但是,由于 Key-Value Cache 将全部层、全部 attention 头、全部时间步的 K 和 V 都缓存起来,对于一个支持 超长上下文的 LLM 来说,整体的存储开销是非常惊人的。以 Chinese-LLaMA-2-7B-16K 为例:
2 * config.max_position_embeddings * config.num_hidden_layers * config.hidden_size
= 2 * 16384 * 32 * 4096
= 4,294,967,296
将近 43 亿个浮点数!如果用半精度 float16,相当于 8G;即使是最狠的 4-bit 量化,也得占 2G 的显存。这还只是一个轻量化的 LLaMA-7B。
因此,有必要设置针对性的优化方案,削减 K 和 V 对应的存储空间以降低缓存容量。这就是 Multi-Query Attention(MQA) 和 Grouped-Query Attention(GQA)的出发点。
3. Multi-Query Attention(MQA)
MQA:《Fast Transformer Decoding: One Write-Head is All You Need》
“Multi-Query”即只有 Query 进行分头,Key 和 Value 变换为单头维度,在各个注意力头之间共享同一组 KV 映射。即削减了 FLOPs,也降低了 Cache,并且压缩了频繁矩阵拼接的 I/O 耗时。
# query 正常分头.
self.head_dim = self.embed_dim // self.num_heads
# key 和 value 使用单头.
self.kv_heads = 1 if self.multi_query else self.num_heads
# key 和 value 降维.
self.kv_dim = self.kv_heads * self.head_dim
# K,Q,V 映射矩阵,embed_dim(Q) + kv_dim(K) + kv_dim(V)
self.c_attn = nn.Linear(self.embed_dim, self.embed_dim + 2 * self.kv_dim)
# 从 hidden_states 映射为 query \ key \ value.
query, key_value = self.c_attn(hidden_states).split((self.embed_dim, 2 * self.kv_dim), dim=2)
key, value = key_value.split((self.head_dim, self.head_dim), dim=-1)
MQA 在 2019 年就已经发表,目前用在 Falcon、PaLM、MPT、BLOOM 等 LLM 上。
4. Grouped-Query Attention(GQA)
GQA:《GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints》
GQA 是 Google 在 2023 年提出的,作者认为 MQA 砍得太狠了,影响了模型效果。于是改用一种温和策略,对Key 和 Value 先分头,再分组(2或4或8),同一组内共享 KV 矩阵。
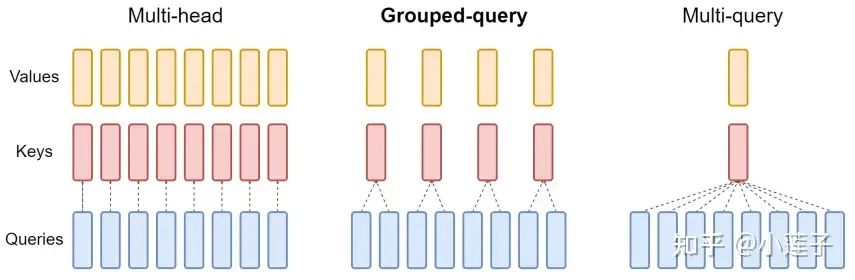
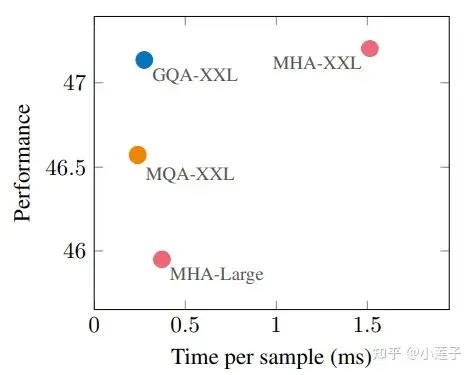
论文的对比实验用的是 “Uptraining” 的方法。即,把原始的多头 Key 和 Value 做平均池化,模拟“单头”(MQA)和“多组”(GQA),然后再继续预训练 a=0.05 的原预训练步数。

原版 MHA 的指标是 47.2,MQA 有所衰减为 46.4,GQA-8 回升到 47.1,接近无损了。并且,推理速度上 GQA 并没有明确落后于 MQA。
最后分享
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

5. 大模型面试题
面试,不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】

如有侵权,请联系删除。















 7133
7133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









