






今天给大家推荐一个创新Max,且不卷的idea:基于Mamba做异常检测!
以往的异常检测方法,以基于CNN、Transformer为主。但CNN在处理长距离依赖性方面存在困难,Transformer虽然表现出色,但由于其自注意力机制,计算复杂度较高。而Mamba,则完美弥补了这两者的缺陷,在有效处理长距离依赖性同时,具有线性复杂度,计算资源需求少!在提高模型检测精度和速度方面,一骑绝尘!比如模型ALMRR便在准确率高达99.1%的同时,参数量和计算复杂度大幅降低!
更为重要的是,传统的方法早已卷成红海,Mamba作为近来的新贵,尚在发展期,可挖掘的空间还很广!
为让大家能够紧跟领域前沿,找到更多idea启发,我给大家梳理了多种创新思路,且提供了源码!
论文原文+开源代码需要的同学看文末
论文:MambaAD:Exploring StateSpace Models for Multi-class Unsupervised Anomaly Detection
内容
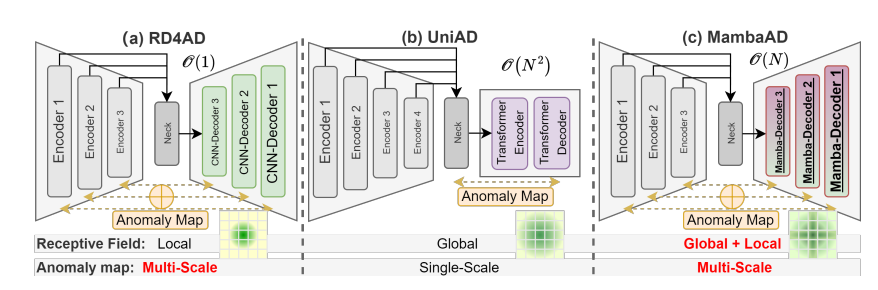
该论文介绍了MambaAD,这是一个基于Mamba框架的多类别无监督异常检测方法。MambaAD结合了预训练编码器和Mamba解码器,并在多尺度上使用局部增强状态空间(LSS)模块,有效地捕获长程和局部信息,在六个不同的异常检测数据集上达到了最先进的性能,同时保持了较低的模型参数和计算复杂度。
论文:ALMRR: Anomaly Localization Mamba on Industrial Textured Surface with Feature Reconstruction and Refinement
内容
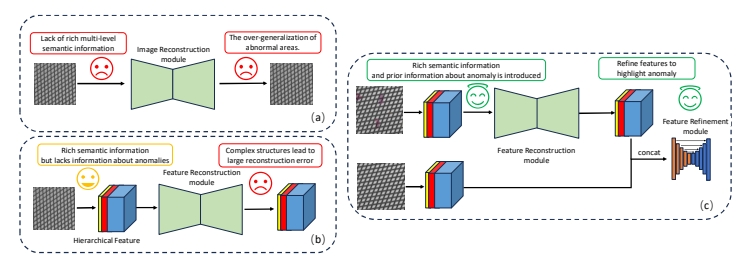
该论文提出了一种名为ALMRR的新型无监督异常检测方法,该方法通过特征重建和细化来定位工业纹理图像中的异常。ALMRR利用Mamba框架进行特征重建,并通过特征细化模块提高异常定位的精确度。在训练阶段,模型通过添加人工模拟的异常来增强对异常的先验知识。
论文:Joint Selective State Space Model and Detrending for Robust Time Series Anomaly Detection
内容
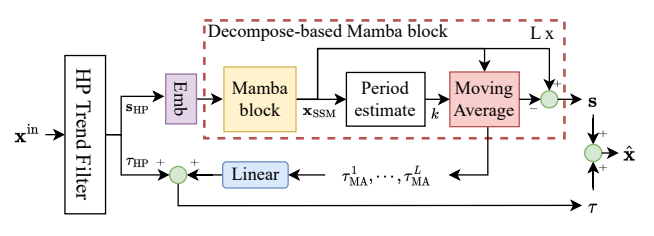
该论文提出了一种基于选择性状态空间模型(S6)和多阶段去趋势机制的时间序列异常检测方法,旨在解决长期依赖建模和非平稳数据泛化问题,以其在捕捉长期依赖关系方面的能力而闻名,而去趋势机制则用于减轻非平稳数据中的显著趋势成分,以提高模型的泛化能力。
论文:End-to-End Learning-Based Study on the Mamba-ECANet Model for Data Security Intrusion Detection
内容
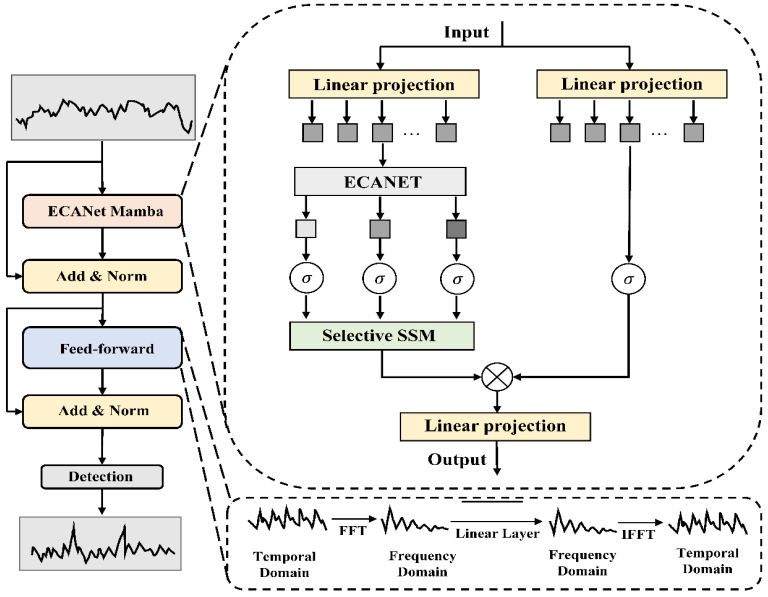
该论文提出了一种基于深度学习的端到端数据安全入侵检测系统,该系统整合了Mamba模型和ECANet模型,并通过端到端学习进行训练和优化。Mamba模型用于初步数据特征提取,而ECANet模型通过注意力机制进一步优化特征选择,增强了模型对重要特征的关注。
关注下方《人工智能学起来》
回复“MMAD”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏

















 1639
1639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









