








论文链接:https://arxiv.org/pdf/2405.03485
代码&数据集链接:https://github.com/L-Sun/LGTM
在本文中,介绍了LGTM,一种新颖的用于文本到动作生成的局部到全局pipeline。LGTM基于扩散的架构,旨在解决将文本描述准确转换为计算机动画中语义连贯的人体动作的挑战。具体而言,传统方法通常难以处理语义差异,特别是在将特定动作与正确的身体部位对齐方面存在困难。 为解决这个问题,本文提出了一个两阶段pipeline来克服这个挑战:首先利用大语言模型(LLMs)将全局动作描述分解为部分特定的描述,然后由独立的身体部位动作编码器处理,以确保精确的局部语义对齐。最后,基于注意力的全身优化器对动作生成结果进行优化,并确保整体一致性。本文的实验表明,LGTM在生成局部准确、语义对齐的人体动作方面取得了显著改进,标志着文本到动作应用的显着进步。
介绍
在本文中解决了文本到动作的问题,即,给定一个角色动作的文本描述,本文旨在自动生成合理且逼真的3D人体动作。 成功自动化此过程对于各种下游应用具有重要潜力,包括为增强和虚拟现实环境创建内容,推动机器人技术的进步,以及改进人机交互。
作为自然语言处理、机器学习和计算机图形学交汇处的长期挑战,文本到动作生成近年来受到了广泛关注。扩散模型的出现,正如各种研究所强调的,推动了这一领域的显着进步。尽管取得了这些进展,从文本描述生成既在局部语义上准确又在全局上连贯的动作仍然是一个巨大的障碍。当前方法通常难以有效捕捉嵌入在动作描述中的微妙的局部语义,并且难以生成与这些语义线索准确对齐的动作。
特别是,在文本到动作合成中,现有方法经常遇到诸如局部语义泄露和缺失元素等问题。例如,当输入描述为“一个男人用他的左腿踢东西”时,这些方法可能错误地生成与“右踢”相对应的动作。类似地,涉及需要多个身体部位协调的复杂动作的prompt经常会导致某些部分的动作被省略。本文的观察揭示了这些方法中的两个主要缺点。
首先,大多数现有技术都使用单个全局文本描述符来描述所有局部身体动作。这种方法要求网络从统一的全局文本来源中学习局部动作语义与相应身体部位之间的关联。这个过程在文本内容在不同身体部位之间相似的情况下尤为困难,导致难以区分每个部分的具体动作。其次,这些方法中使用的文本编码器在编码与动作相关的文本方面的效果有限。这一限制在最近的研究中详细说明了不同动作文本之间的高特征相似性。编码文本特征的同质性进一步加剧了网络在区分和准确表示局部文本语义中微妙变化方面的困难。
为此,本文提出了一种新颖的基于扩散的文本到动作生成架构,称为LGTM,它擅长生成既符合文本描述又在局部语义准确性方面精确的动作。LGTM通过一种从局部到全局的方法进行操作,结构上分为两个主要阶段。第一阶段实施了一种有效的策略来解决局部语义准确性问题。在这里,本文引入了一个分区模块,利用大语言模型(LLMs)将全局动作描述分解为针对每个身体部位具体的描述。随后,专用的身体部分动作编码器独立处理这些特定于各部位的描述。这种专注的方法通过减少冗余信息和防止语义泄漏有效地避免了局部语义不准确性,从而保持对相关局部语义的清晰关注。
然而,由于每个身体部分动作编码器都是独立工作的,没有意识到其他部分的运动,因此必须同步这些单独的动作,以避免整体协调问题。为了解决这个问题,LGTM的第二阶段引入了基于注意力的全身优化器。该组件专门设计用于促进不同身体部位之间的信息整合,确保整体动作不仅在局部上精确,而且在全局上连贯流畅。
为评估LGTM的有效性,本文进一步进行了文本驱动的动作生成实验,并提供了定量和定性结果。本文的实验表明,本文提出的LGTM可以生成更符合输入文本的忠实动作,无论在局部还是全局上,并且优于现有技术方法。
总结一下,本文的贡献如下:
-
本文提出了LGTM,一种新颖的基于扩散的架构,可以将文本描述转化为准确和连贯的人体动作,相比之前的文本到动作方法有了显著的改进。
-
LGTM引入了一个独特的分区模块,利用LLMs将复杂的动作描述分解为特定于每个部位的描述。这显著提高了动作生成中的局部语义准确性。
-
本文的实验证明了独立的身体部位运动编码器与基于注意力的全身优化器的有效集成,确保了生成动作的局部精度和全局一致性,为文本到动作生成提供了有希望的改进。
相关工作
运动序列的生成是计算机图形领域长期以来的挑战,其目标是根据条件控制信号生成一系列运动帧。鉴于本文的方法是以基于身体分区的文本到动作合成为中心,本文探索了两个主要方面的相关文献:身体分区建模和文本到动作生成。
基于部分的运动建模。将人体分割为不同的部分有助于在更细粒度的水平上控制运动合成,从而实现局部调整。
一些研究探讨了将各个身体部分的运动组合起来合成新的运动的概念。[Hecker等人,2008] 提出了一种重新定位算法,将运动组合到单个身体部位的水平上,以生成多样化的角色动画。[Jang等人,2008] 将运动分为上半身和下半身两个部分,通过算法将它们合并,以扩充其运动数据库。[Soga等人,2016] 通过关注身体分区来从现有数据集中合成舞蹈动作。[Jang等人,2022] 在部分水平进行风格转移,利用图卷积网络将不同身体部位的运动组合成新的、连贯的序列,保持局部风格的同时将其转移到特定的身体部位,而不影响其他部位或整个身体的完整性。然而,这些方法依赖于预先存在的运动数据,因此更准确地描述为合成而不是生成。
为了实现更详细的局部控制,[Starke等人,2020] 提出了一种基于身体分区的局部相位模型,用于生成篮球运动员的动作,相比于全局相位方法[Starke等人,2019;Zhang等人,2018],实现了更高的局部保真度。[Starke等人,2021] 引入了一种神经动画分层技术,将由控制模块产生的不同身体部位的轨迹结合起来,为动画师提供了更细粒度的控制,实现了高质量的运动生成。[Lee等人,2022] 开发了一种用于重新组装基于物理的部分运动的算法,允许将具有不同骨骼结构的角色的部分运动组合在一起。通过在物理模拟的虚拟环境中操作,他们采用部分时间弯曲和基于优化的组装,以确保改善空间和时间上的对齐。[Bae等人,2023] 利用部分运动鉴别器增强运动的多样性,并利用全局控制策略来保持运动的物理真实性。
文本提供了一个用户友好的界面,用于指导动作生成,因为它易于使用并具有编辑能力。然而,通过文本精确控制生成动作的结果是一个重要挑战。在这一小节中,本文将研究文本到动作生成技术,并确定它们的局限性。
某些文本到动作的方法基于编码器-解码器架构,重点是在统一的潜在空间内对齐模态。[Ahuja 和 Morency 2019]通过在编码动作和文本之间交替训练他们的网络,然后将它们解码回动作,从而隐式地对齐这两种模态。[Ghosh 等 2021;Petrovich 等 2022]同时对文本和动作进行编码,并将它们解码为动作,利用额外的损失函数将模态在潜在空间内更加接近。这些方法在从长文本描述中生成动作时遇到困难。[Athanasiou 等 2022]通过自回归方式生成短动作剪辑来解决长动作生成的问题,但这需要将长文本描述手动分割成较短的段落并指定动作的持续时间。
为了利用视觉先验,[Tevet 等 2022a]使用了一个冻结的 CLIP [Radford 等 2021] 文本编码器来编码动作描述,并将动作的潜在空间与 CLIP 的潜在空间对齐。然而,用于对齐的图像来自于随机的动作帧,当帧不具代表性时,网络可能会产生困惑。此外,[Petrovich 等 2023]观察到,动作描述在 CLIP 的潜在空间中往往聚集得很密集,因为与用于训练 CLIP 的更广泛的文本数据集相比,动作相关文本的分布更窄。
最近发展的神经扩散模型在图像生成方面启发了利用这些模型实现更高质量的文本到动作方法。[Tevet 等 2022b;Zhang 等 2022]利用Transformer对文本条件下的动作进行去噪处理。[Chen 等 2023b]引入了基于 U-Net 的 DDIM 生成模型来对潜在空间中的动作进行去噪处理,从而加速了生成过程。然而,这些方法缺乏通过masking来控制局部动作生成的能力。此外,它们在学习正确的局部语义映射方面存在困难,因为所有身体部位共享相同的文本信息,这可能导致语义不匹配的部分运动。
将动作处理为离散空间中的token预测是动作生成的另一种方法。但是,这些方法的局限性在于codebook的表达能力可能会限制生成动作的多样性,从而可能导致文本输入被映射到不符合预期的动作。
控制局部动作语义的挑战源于:
-
在所有身体部位之间共享文本信息,
-
网络难以区分由CLIP编码的文本潜在代码。
这些因素导致了在动作生成中实现精确的局部语义控制的困难,从而引发了语义泄漏等问题。
受先前研究中的技术进展和挑战的启发,本文提出了一种新颖的框架,将身体部位分割与独立的局部动作语义注入以及全局语义联合优化策略相结合。该框架旨在增强文本到动作合成的逼真度和可控性,满足对更加细致和准确的动作生成的需求。
方法
在本节中,本文深入探讨了 LGTM 的具体细节,如下图 2 所示。LGTM 结构化为一个从局部到全局的生成框架,首先创建局部的、部位级别的动作,然后通过全局融合和优化过程生成最终的全身动作。在其核心,LGTM 通过将全身文本和动作空间细分为部位特定的子空间来操作。这种细分由一个专用的分区模块巧妙处理。
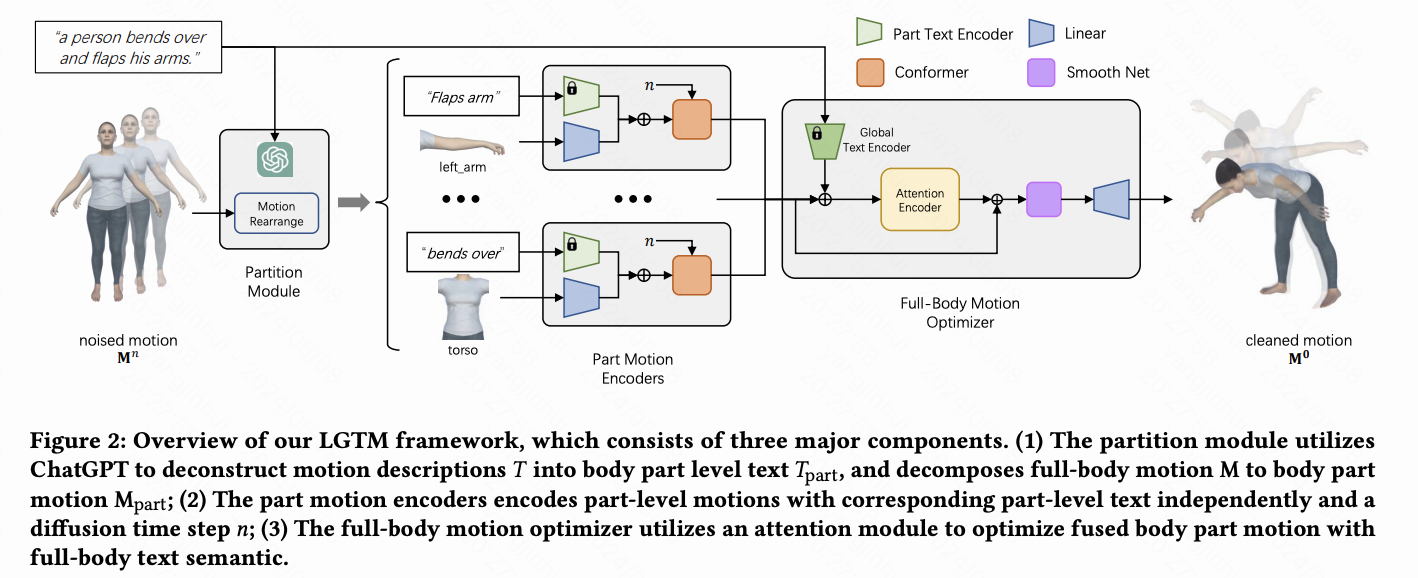
对于每个子空间,本文开发了专门的部位动作编码器。这些编码器被训练成独立学习部位级别动作和部位级别文本之间的一系列映射关系。这种策略有效地缓解了以前方法中出现的局部语义映射不正确的问题。在进行局部编码之后,LGTM 引入了一个全身动作优化器,建立各个子空间之间的关联,确保最终全身动作的一致性和连贯性。下面,本文详细解释了 LGTM 中每个模块的功能和细节。
初步:人体运动扩散模型
输入表示。 将本文方法的输入对定义为 (M, T),其中 M 表示全身动作数据,T 表示原始的全身文本描述。具体来说,本文使用 [Guo et al. 2022a] 提出的 HumanML3D 表示作为本文的动作数据表示,该表示是从 SMPL 动作数据计算得到的,包括了有助于网络训练的冗余动作特征。一个全身动作数据 M 包含 F 帧和 J = 22 个关节。具体来说,本文表示 ,其中 和 分别表示根关节绕 y 轴的角速度、在 x-z 平面上的线性速度和高度, 和 分别表示除根关节之外所有关节的局部位置和 6D 旋转, 表示所有关节的局部速度, 表示脚的接触信号。
扩散模型。 本文的方法建立在一个文本条件的扩散模型之上。在训练阶段,该模型根据马尔可夫过程向干净的动作 M 添加噪声,并训练一个网络来预测添加的噪声,使用 L2 损失。在采样阶段,该模型逐渐从纯粹被加噪声的动作 中减少噪声,并使用 DDIM作为本文的扩散模型来加速采样过程。更多细节请参阅补充材料。
划分模块
划分模块旨在为每个身体部位的部分运动编码器注入局部语义。在实践中,输入对 (M, T) 被划分为六个部分,包括头部、左臂、右臂、躯干、左腿和右腿。
运动 M 被分解如下:

下标表示特征来自何处。例如, 包括右腿所有关节的局部位置。
对于动作描述 𝑇,本文利用LLM的知识推理能力将其分解为六个部分:,使用精心设计的prompt。 prompt包括三个部分:任务定义、输出要求和一些输出示例。任务定义指示LLM提取每个动作部分的主要描述。输出要求告诉LLM本文需要结构化输出,如JSON格式、身体部位命名等。然后,本文采用了少量样本的方法来指导LLM生成所需的输出。有关本文prompt的更多详细信息,请参阅原文补充材料。 分解的描述示例如下表1所示。

部分动作编码器
部分动作编码器 旨在独立地从部分级别的输入对 中学习局部语义映射。由于每个编码器仅从其对应的部分级别输入对获取信息,并且无法访问其他身体部位的信息,因此语义泄漏的问题得到了有效缓解。本文将部分级别的编码过程表示如下:
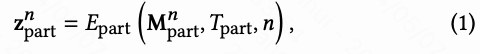
每个部分动作编码器,,由三个组件组成:一个线性层、一个文本编码器和一个Conformer。线性层的目标是将潜在维度的大小与文本编码器的大小对齐。本文使用了六个不同的冻结的部分级别TMR文本编码器,每个对应于六个身体部位中的一个,它们分别在部分级别的动作-文本对Mpart,𝑇part上进行了预训练。由于TMR模型仅在动作描述和动作数据上进行训练,而不是在大型视觉数据集上进行训练,因此由TMR编码的与动作相关的文本embedding更容易被网络区分,而不是由CLIP编码的文本。投影的动作和文本 embedding然后被Conformer融合并处理。Conformer将卷积块结合到Transformer架构中,以更好地捕获时间局部特征。此外,先前的工作 [Alexanderson et al. 2023] 在音乐到舞蹈任务上显示了Conformer的成功。
全身运动优化
由于每个部分的动作和文本都是独立编码为,因此网络将忽略不同身体部位之间的相关性。因此,本文提出全身动作优化器𝐺通过根据全身文本信息调整每个身体部位的运动来建立相关性。
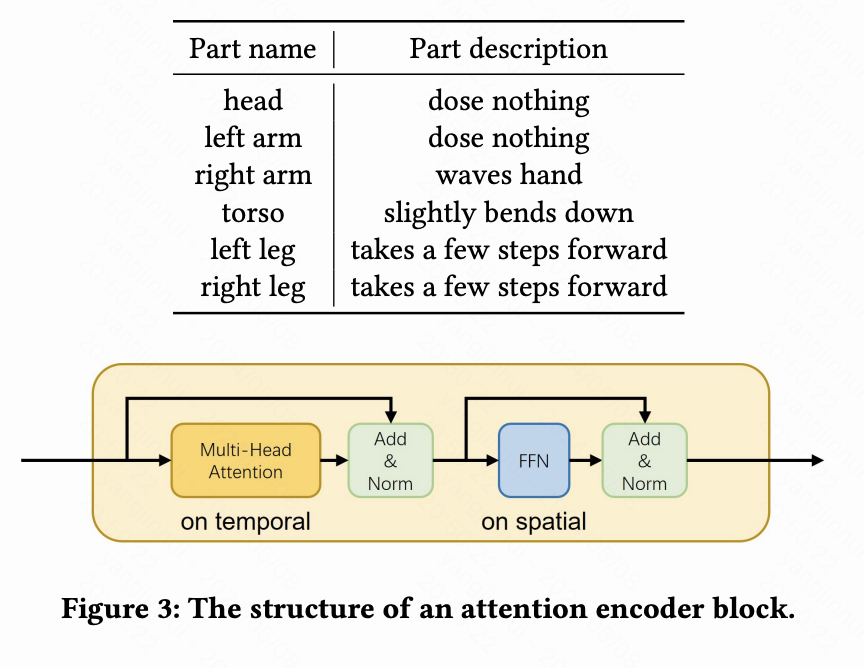
具体来说,本文首先将所有身体部分的潜在编码连接成一个全身潜在编码 ,其形状为 (𝐹, 𝑆) = (𝐹, 6 × 128),然后与通过冻结全身级别的 TMR 文本编码器编码的全局文本embedding进行融合。接下来,本文使用一个注意力编码器来计算一个增量,用于调整潜在编码 中的每个部分。注意力编码器是实际进行时空信息交换的地方。它由多个注意力编码器块组成,每个块包含一个多头注意力块和一个前馈层,如下图3所示。由于潜在编码 在时间维度 𝐹 上由多头注意力块处理,而前馈层 (FFN) 在空间维度 𝑆 上运行,因此每个身体部分的潜在编码可以持续交换时空信息。接下来,本文使用 SmoothNet来减少抖动,其中包含一个具有残差连接的堆叠 MLP,并在时间维度上运行,作为潜在空间中的低通滤波器。
最后,本文将潜在代码投影到原始特征维度,并得到干净的动作 。全身动作优化器可以表述为:
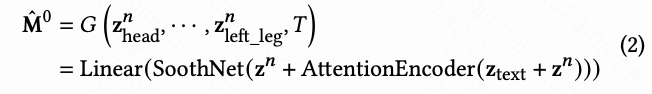
结果
在本节中,展示了由本文的方法生成的动作,并与其他文本驱动的动作生成方法进行了比较分析。此外,本文进行了几项消融研究,以突显本文框架中各个组件的贡献。
实施细节
part-level的动作描述是由ChatGPT生成的(gpt3.5-turbo-1106)模型。本文的模型使用AdamW优化器进行训练,采用快速温和余弦衰减的学习率衰减策略。初始学习率为,batch size为64。扩散步数为1K。本文的模型在HumanML3D数据集上的训练时间约为在3个NVIDIA RTX 4090 GPU上进行8小时。
定性结果
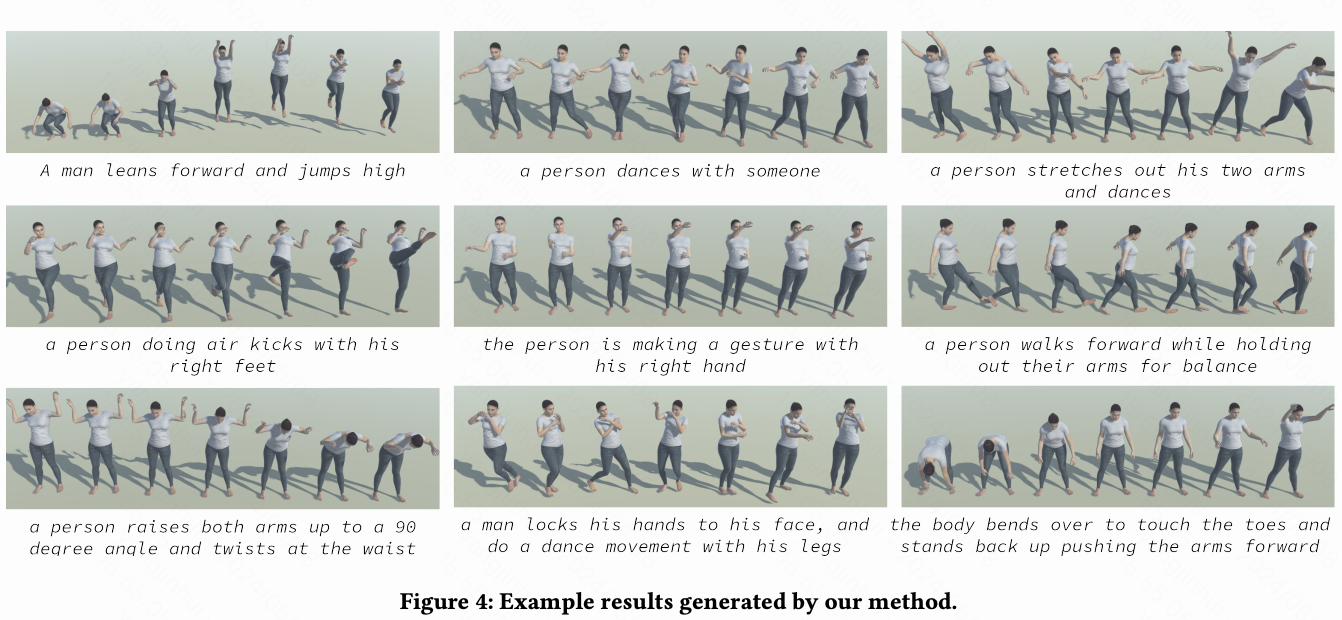
下图4显示了本文方法生成的几个示例结果。本文可以看到,本文的方法能够生成具有精确局部语义的动作,例如身体部位语义对应和动作时间顺序,因为本文的方法独立地将局部语义信息注入到相应的部位中,而整体动作优化器在空间和时间域中构建了正确的身体部位之间的关系。例如,“一个人向前倾身然后跳得很高”的结果显示了角色确实按正确的顺序倾身然后跳跃。而“一个人用手锁住他的脸,然后做一些舞蹈动作,但没有用腿” 的结果表明角色在跳舞时保持了正确的手和脸之间的空间关系。而“一个人用右脚做空中踢腿”的结果显示角色确实用正确的身体部位进行踢腿。
本文还提供了与两种基准方法(包括MDM和 MLD)的视觉比较。下图5显示了本文的方法能够生成更具语义匹配的动作。在第一行中,角色在本文的结果中可以用两只手拿东西,而在MDM中只能用左手。在第二行中,角色在本文的结果中只用左脚正确跳跃,而在MDM中双脚跳跃,而在MLD中不跳跃。在第三行中,MDM的结果包含奇怪的姿势,而MLD不包含“拍手”,但本文的结果更正确。最后一行显示,对于更复杂的文本输入,本文的方法能够生成比这两种基线方法更语义准确的结果。

定量评价
评估指标。 为了定量评估本文的方法,本文使用了[Guo等人,2022a]提出的指标,包括:
-
(1)Fréchet Inception Distance(FID),评估生成的动作质量与真实动作分布之间的差异;
-
(2)多样性(DIV),计算生成动作的方差;
-
(3)R Precision,计算生成动作与相应文本描述之间的前n匹配精度;
-
(4)多模态距离(MM Dist),计算配对的动作和文本之间的距离;
-
(5)部分级别多模态相似度(PMM Sim),计算部分级别配对的动作和文本之间的归一化余弦相似度。
这些指标是在潜在空间中使用T2M的文本编码器和动作编码器计算的,就像之前的工作一样。由于本文的方法提供了对生成动作的详细控制,本文还使用部分级别多模态相似度(PMM Sim)将本文的方法与基线方法进行了比较,通过训练部分级别文本编码器和动作编码器进行对比学习,这与TMR相似,本文认为这样做可以使潜在空间中的动作样本更加分散,使得不同的动作更容易被区分。具体来说,本文在TMR潜在空间中计算PMM Sim如下:
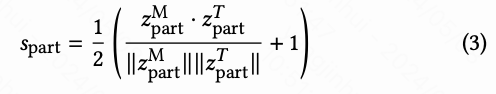
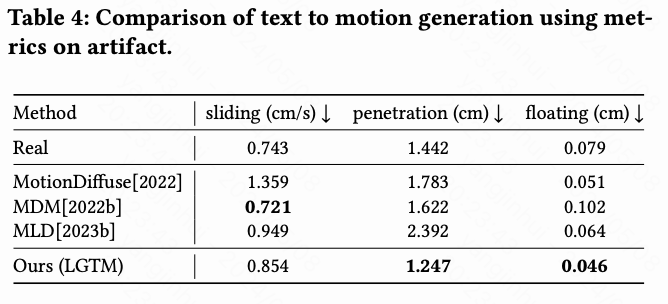
在这里, 和 分别通过TMR编码器对部分级别的动作和文本进行编码获得。虽然本文主要关注语义可控生成,但本文也评估了文本到动作合成中的常见伪影。本文使用[Yuan等人,2022]介绍的三个具体指标对生成的动作进行评估:滑动、穿透和浮动。
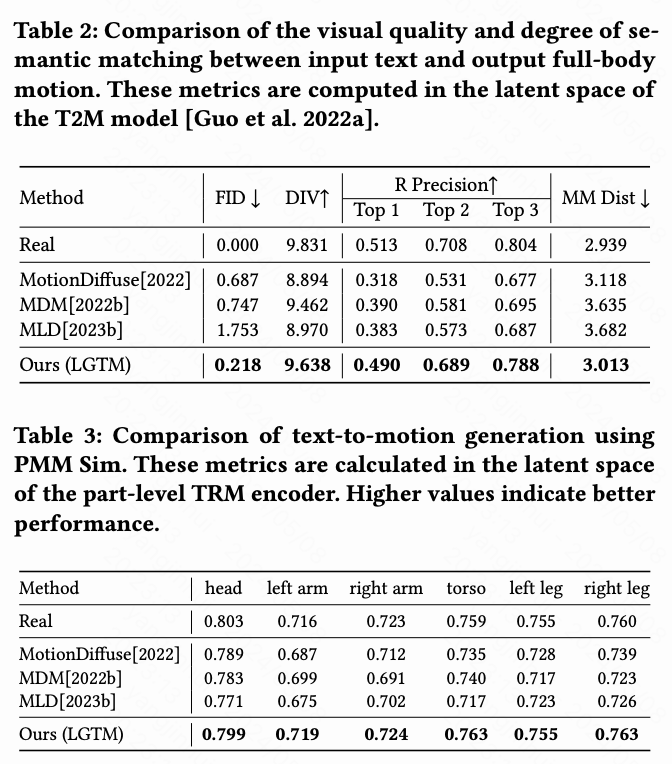
比较结果。 全身动作的比较结果显示在下表2中,部分级别动作的比较结果显示在下表3中。下表2中的FID和DIV指标表明本文的方法生成了更加真实和多样化的动作。R Precision 和 MM Dist 表明本文的方法能够生成更好的全局语义匹配的动作。下表3还表明本文的方法实现了最佳的局部语义匹配,性能非常接近真实数据。本文的局部到全局设计独立地将局部语义信息注入到身体部位,并与全局语义一起进行细化,这为网络提供了更准确和结构化的语义信息,有助于生成,并因此实现更高的质量。对于伪影评估,如下表4所示,本文可以看到每种方法在毫米尺度上表现非常接近真实数据(Real行)。伪影可以归因于数据集固有的质量差异。
消融实验
本文设计了两个主要实验来评估本文方法的不同组成部分的影响。第一个实验研究了不同文本编码器对动作质量的影响。第二个实验评估了全身动作优化器对本文方法生成的动作质量的影响。
文本编码器的重要性。 本文通过用CLIP替换本文预训练的文本编码器进行测试,展示了本文使用的TMR文本编码器可以捕捉更详细的语义。此外,本文还呈现了使用CLIP或TMR文本编码器获得的MDM的结果,以进行比较。
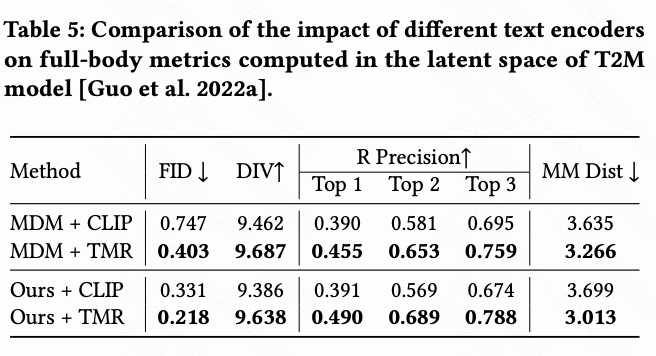
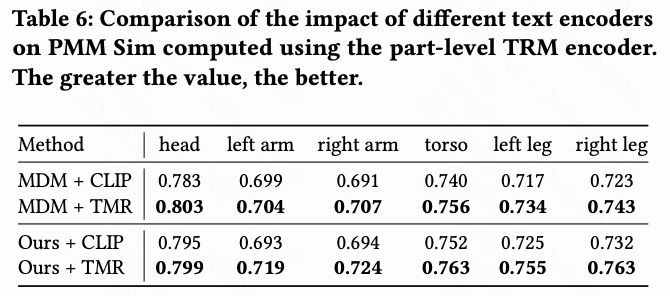
下表5和下表6分别评估了全身和部分级别的动作质量。总体而言,本文观察到使用TMR文本编码器通常会产生比使用CLIP更好的结果,无论是对于本文的方法还是MDM,以及无论是对于局部还是全局质量。当将本文的方法与使用相同文本编码器的MDM进行比较时,本文的方法通常表现更好,进一步证明了本文局部到全局设计的优越性。
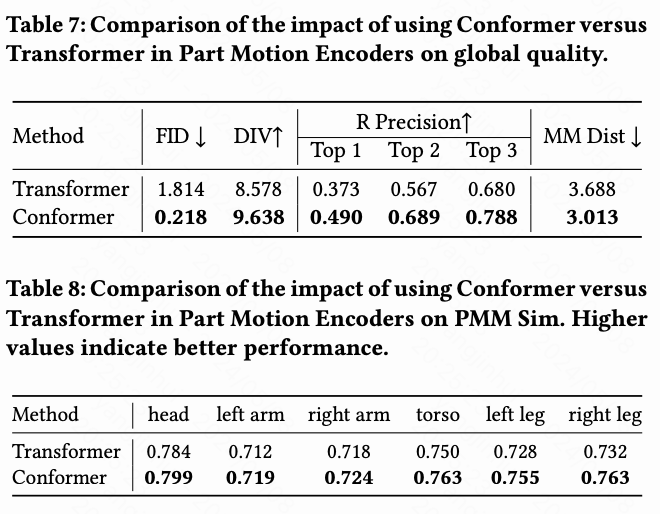
Conformer的影响。 将Transformer替换为Conformer是为了提高部分动作编码器的动作质量。为了验证改进,本文比较了两种配置的全局质量指标。从下表7和下表8中,本文观察到使用Conformer的LGTM可以获得比使用Transformer更好的质量和语义匹配性能。这种改进可以归因于Conformer的卷积模块,它比自注意力更好地捕捉了局部特征。
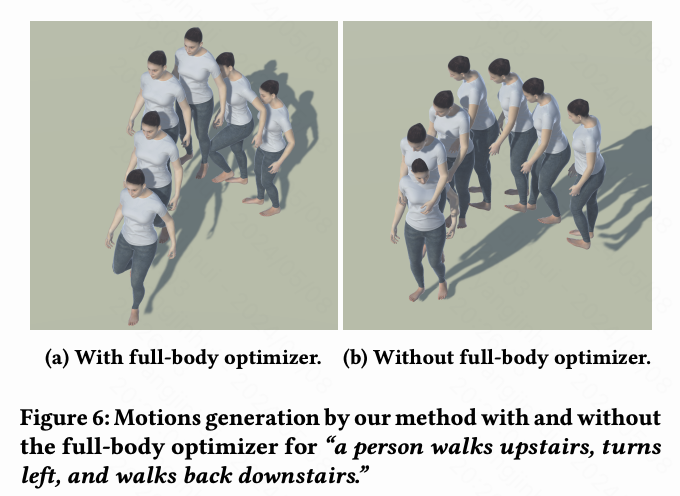
全身动作优化器的重要性。 本文的全身动作优化器的目标是建立不同身体部位运动之间的相关性,并改善全身运动的协调性。为了验证其效果,本文将其与“w/o opt”设置进行比较,其中本文去除了本文全身优化器的关键组件,即注意力编码器。从下表9和下表10中可以看出,没有优化器,局部动作质量下降,全身动作质量也明显较差;参见下图6中的一个示例结果。没有全身动作优化器,角色的两只脚在运动过程中无法很好地协调步伐交替,因为缺乏信息交换。

结论
本文提出了LGTM用于文本到动作的生成,这显著提高了从文本描述中衍生的3D人体动作的准确性和连贯性。通过将大语言模型与局部到全局的生成框架结合起来,本文的方法有效地解决了语义映射和动作连贯性的关键挑战。
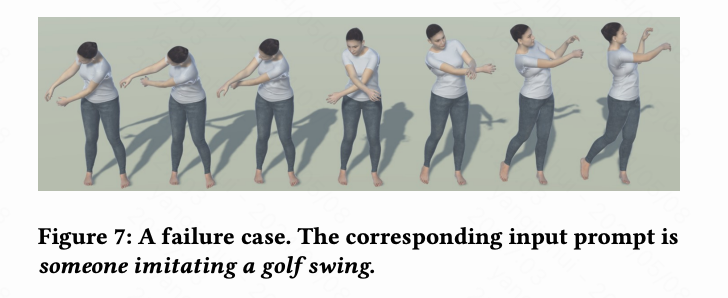
限制和未来工作。 由于本文使用ChatGPT进行动作描述分解,因此局部语义映射取决于ChatGPT的推理能力。不正确的分解或映射可能导致不令人满意的动作生成结果。例如,在生成“高尔夫挥杆”动作时,这需要高水平和全身协调,LGTM会遇到困难,因为ChatGPT识别到右手挥动高尔夫球杆,但未能将这种推理分解为每个身体部位的一系列低级动作。结果是网络生成了一个不可信的动作,如下图7所示。此外,在数据集中的含糊不清的文本可能会在训练过程中使网络混淆。例如,短语“一个人执行动作A和动作B”可能暗示这些动作同时发生或顺序发生,导致输出可能与用户期望不一致。通过提供更详细的时间描述,可以缓解这个问题。此外,由于数据集中样本长度有限,本文当前的框架无法始终生成高质量的长期动作。对于未来的工作,一个有前途的方向是将本文的局部到全局的思想与那些基于VQ-VAE的方法(如TM2T和MotionGPT)结合起来,通过构建部分级别的动作片段作为动作token,进行更详细的动作生成,以获得不同部分级别的动作组合。
参考文献
[1] LGTM: Local-to-Global Text-Driven Human Motion Diffusion Model
更多精彩内容,请关注公众号:AI生成未来

欢迎加群交流AIGC技术,添加小助手


















 569
569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









