








文摘要概述
论文Datasets for Large Language Models: A Comprehensive Survey(arXiv:2402.18041)从五个方面对LLM数据集的基本方面进行了整合和分类:(1)预训练语料库;(2)指令微调数据集;(3)偏好数据集;(4)评价数据集;(5)传统自然语言处理(NLP)数据集。
该论文提供了对现有可用数据集资源的全面回顾,包括来自444个数据集的统计数据,涵盖8个语言类别,跨越32个领域,整合了来自20个维度的统计信息。调查的总数据量超过了774.5TB的预训练语料库和7亿个其他数据集实例。
*这里重点对该论文的前半部分,即预训练语料库和指令微调数据集进行分析讨论。
论文局限
这篇论文只综述了纯文本的数据集,不包括多模态数据集。
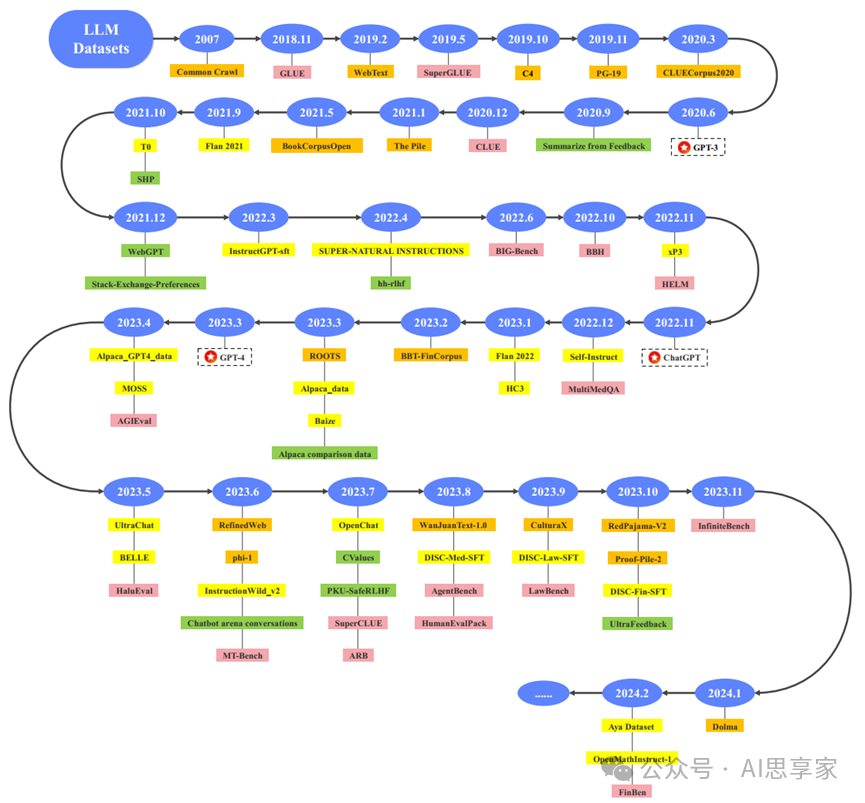
图1. 代表性大型语言模型数据集的时间线
橙色代表预训练语料库,黄色代表指令微调数据集,绿色代表偏好数据集,粉色代表评估数据集。
Part.A 预训练语料
在预训练阶段,LLM从大量未标记的文本数据中学习广泛的知识,然后将其存储在模型参数中。作为LLM的基石,预训练语料库影响着预训练的方向以及模型未来的潜力,预训练语料在提供通用性、增强泛化能力、提升性能水平、支持多语言处理等方面发挥重要作用。
01 预训练语料分类
预训练语料库可以包含各种类型的文本数据,如网页、学术材料、书籍,同时也可以容纳来自不同领域的相关文本,如法律文件、年度财务报告、医学教科书和其他特定领域的数据。
各种预训练语料库各有特色,亦存在不足之处。网页是预训练语料库中最普遍和最广泛的数据类型,但它通常包含大量的噪音,无关信息和敏感内容,使其不适合直接使用。社交媒体数据中可能存在有害信息,如偏见、歧视和暴力,但它对于LLM的预训练仍然是至关重要的。因为社交媒体数据有利于模型学习对话交流中的表达能力,以及捕捉社会趋势、用户行为模式等。书籍资料拥有更连贯的文本结构和更高的数据质量,但通常情况下,它们的更新速度较慢,可能无法及时反映当下的语言使用习惯和社会变迁。此外,书籍的覆盖领域和语言风格可能较为有限,这可能会限制模型在多样化和现实世界场景中的应用能力。因此,在选择预训练语料库时,需要综合考虑数据的多源性、覆盖面、时效性以及可能存在的偏差和风险,以确保预训练出的模型既具有广泛的适用性,又能在特定领域内表现出色。
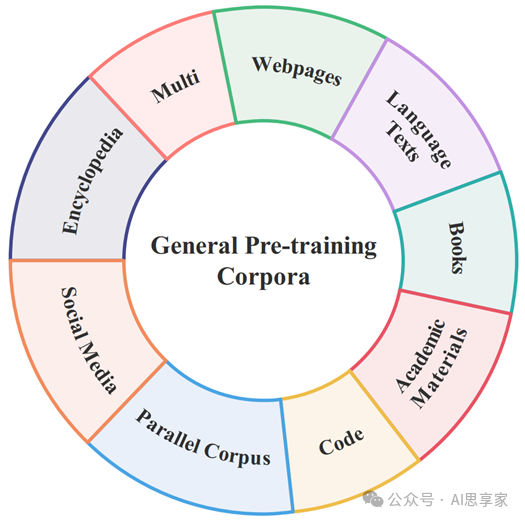
图2. 通用预训练语料库的数据类别
02 网页预训练语料库的构建方法
网页语料库的构建通常有两种主要方法。
第一种方法是建立在Common Crawl的基础上。许多后续的预训练语料库是通过从Common Crawl中重新选择和清洗数据而得到的。例如,RefinedWeb、C4、mC4、CC100、OSCAR 22.01、RedPajamaV2、CC-Stories、RealNews、CLUECorpus2020、CulturaX等。
第二种方法是独立抓取各种原始网页,然后采用一系列清洗过程来获得最终的语料库。例如,WuDaoCorpora-Text、MNBVC、WanJuanText-1.0、TigerBot pretrain zh corpus等。
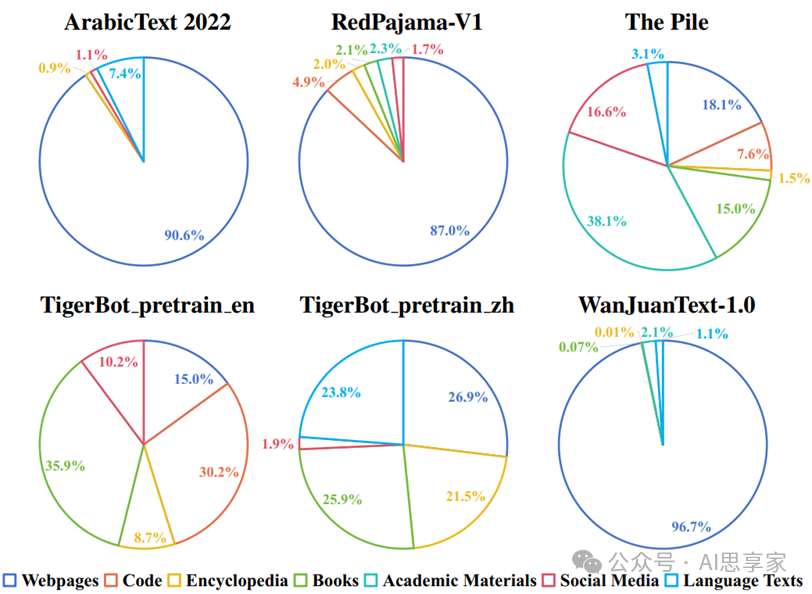
图3. 饼图展示了选定多类别预训练语料库的数据类型分布
相应的预训练语料库名称位于每个饼图的上方。不同的颜色代表不同的数据类型。
财经领域
财经领域大模型语料来源:财经新闻、财务报表、公司年报、金融研究报告、金融文献、市场数据。
财经大模型语料库:BBT-FinCorpus(大规模中文金融领域语料库)、FinCorpus(轩辕的训练语料)、FinGLM、TigerBot-research、TigerBot-earning。
医疗领域
医疗领域大模型语料来源:医学文献、医疗诊断记录、病例报告、医学新闻、医学教科书和其他相关资料。
医疗大模型语料库:Medical-pt(开源的医学百科全书和医学教科书数据集)、PubMed Central(医学文献)
法律领域
法律领域大模型语料来源:法律文书、法律书籍、法律条款、法院判决和案件、法律新闻和其他法律资料。
法律大模型语料库:TigerBot-law(包含11类中国法律法规)
交通领域
交通领域大模型语料来源:交通文献,交通技术项目,交通统计,工程建设信息,管理决策信息,交通术语。
交通领域大模型语料库:TransGPT(国内首个开源大型交通模型)
数学领域
数学领域大模型语料来源:数学相关代码、数学网络数据和数学论文。
数学领域大模型语料库:Llemma
特别提示:
在使用任何预训练语料库之前,建议查看适用许可证的具体条款和条件,以确保符合相关规定。Apache-2.0、ODC-BY、CC0和Common Crawl Terms of Use许可证通常用于预训练语料库,为商业用途提供了相对宽松的限制。
03 预训练语料库的处理流程
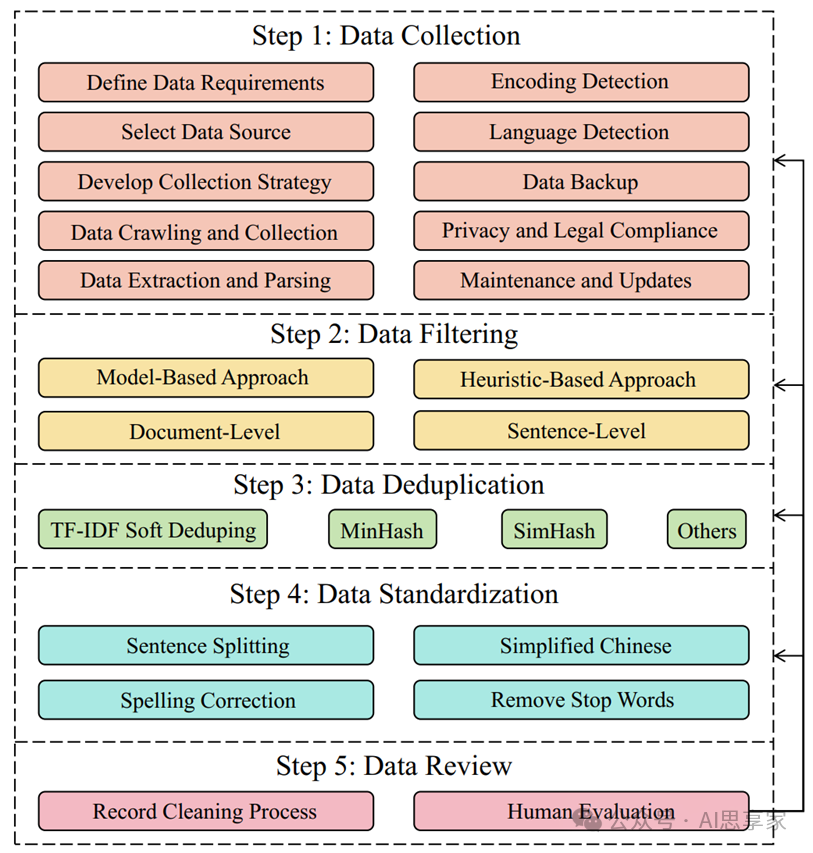
图4. 预训练语料库的处理流程
1. 数据采集(Data Collection)
(1)明确数据需求:数据类型、语言、领域、来源、质量标准
(2)选择数据源:可以采用黑名单和专门的过滤器提前排除低质量的网站
(3)制定采集策略:包括数据收集的时间跨度、规模、频率和方法,便于获取多样化和实时的数据
(4)数据抓取和收集:利用web爬虫、API或其他数据检索工具,根据预定义的收集策略从选定的数据源收集文本数据。在抓取过程中,确保遵守法律法规和网站的相关协议和政策。
(5)数据提取和解析:从原始数据中提取文本组件,实现对文本的准确解析和分离。可能涉及HTML解析、PDF文本提取等。
(6)编码检测:使用编码检测工具来识别文本编码,确保文本以正确的编码格式存储。
(7)语言检测:利用语言检测工具识别文本的语言,根据不同的语言将数据分割成子集,只选择需要的语言文本。WanJuanText-1.0使用pyclid2实现语言分类。
(8)数据备份
(9)隐私和法律遵从
(10)维护和升级
2. 数据过滤(Data Filtering)
数据过滤有基于模型的方法或基于启发式的方法。
基于模型的方法通过训练筛选模型过滤低质量数据,可以使用高质量的预训练语料库作为正样本,将待过滤的污染文本作为负样本,训练分类器进行过滤。
基于启发式的方法,过滤可以在文档层面和句子层面进行。前者在文档层面操作,采用启发式规则删除语料库中不符合要求的整个文档。后者在单个文本句子层面操作,使用启发式规则删除文档中不符合标准的特定句子。
在句子层面,设置相应的启发式规则,选择性地删除语料库中不需要保留的句子。常用的启发式规则包括:
-
基于语义和标点,通过过滤不完整的句子来评估句子的完整性;
-
删除涉及个人隐私的内容或用其他文本代替隐私信息;
-
删除与暴力、色情等相关的有害内容;
-
去除异常符号;
-
删除标识符,如HTML、CSS、JavaScript等;
-
删除包含大括号的句子;
-
删除过短的句子;
-
删除多余的内容,如按钮、导航栏和其他不相关的元素;
-
删除包含特定单词的文本。
3. 数据去重(Data Deduplication)
重复数据删除涉及删除语料库中重复或高度相似的文本。
几种典型的重复数据删除方法如下:
(1)TF-IDF(词频-逆文档频率)软删除操作
这种方法涉及计算文本中每个单词的TF-IDF权重,以比较文本之间的相似性。相似度超过阈值的文本将被删除。TF-IDF权重是单词在文本中的频率(TF)乘以整个语料库中的逆文档频率(IDF)。较高的权重表明一个单词在特定文本中频繁出现,但在整个语料库中却不常见,这使得它成为文本的关键特征。
(2)MinHash
这种方法估计两个集合之间的相似性。文本通过随机哈希处理,以获得一组最小哈希值。然后通过比较这些最小哈希值来估计相似性。如果两个文本的最小哈希值集合有很多相似之处,那么这两个文本就被认为是相似的。这种方法在执行计算时需要的计算资源较少,同时占用的存储空间也较小。
(3)SimHash
这种方法用于计算文本相似度。文本特征向量被哈希化以生成固定长度的哈希码。通过比较文本哈希码之间的汉明距离来估计相似度,距离越小表示相似度越高。
小科普:
汉明距离:这是一种用于度量两个等长字符串在对应位置上不同字符的数量。在文本相似度的计算中,汉明距离用于衡量两个文本哈希码之间的差异程度。
(4)其他方法
CulturaX采用了基于URL的去重方法,移除语料库中共享相同URL的重复文档。WanJuanText-1.0使用MinHashLSH和n-grams来评估相似性,删除相似度大于0.8的内容。
4. 数据标准化(Data Standardization)
数据标准化涉及文本数据的规范化和转换,使其在模型训练过程中更易于管理和理解。它主要包括四个步骤:
(1)句子切分
MultiUN可对提取的文本进行句子切分。中文文本使用简单的正则表达式进行切分,而其他文本则使用NLTK工具包26的句子分词模块。
CLUECorpus2020利用PyLTP(Python语言技术平台)将文本分割成完整的句子,每行一个句子。
(2)简体中文转化
WuDaoCorpora-Text将所有繁体中文字符转换为简体中文。
(3)拼写校正
可采用现成的训练模型来对文本进行拼写校正。
(4)移除停用词
通常可以移除那些高频但缺乏实质性信息价值的词汇。此外,中文文本中的空格没有实际意义,也可以删除。
5. 数据审查(Data Review)
数据审查阶段开始于细致地记录之前的预处理步骤和方法,以供未来参考和审查。随后,进行人工审查,抽样检查数据处理是否达到预期标准。在此审查过程中发现的问题将被作为反馈提供给第1步至第4步。这个阶段可以在上述每个步骤结束时同时建立。
04 预训练语料库面临的挑战
(1)数据选择方面存在数据类型不够全面、分类不够细的局限,古文及民族文化等小众领域的开源语料库较少,合成数据的训练效果有待验证。
(2)大多数预训练语料库的时效性较差,难以实时更新。
(3)目前尚未建立预训练语料库的系统性质量评估方法,大多数研究只关注语料库的某些方面,而对于如何定义高质量语料库、如何比较语料库质量以及全面质量评估的标准等问题仍未有明确答案。
(4)预训练语料库的数据预处理缺乏统一标准和流程,有效性和最佳数据清洗程度尚不明确。过滤有害内容会减少模型生成的有害信息,但可能削弱其辨别能力,过度清洗则可能降低数据多样性。未来研究需探讨更干净语料库的必要性以及有害和低质量数据的影响。
(5)构建预训练语料库数据系统:数据预处理缺乏标准,对数据没有系统的评价方案,相关数据的发布没有建立标准,目前对数据没有统一的管理和维护。
Part.B 指令微调数据集
指令微调数据集由一系列文本对组成,包括“指令输入”和“答案输出”。“指令输入”表示人类对模型提出的请求,包括各种类型,如分类、摘要、释义等。“答案输出”是模型按照指令生成的响应,与人类的期望保持一致。
指令微调数据集用于进一步微调预训练的语言模型(LLMs),使模型能够更好地理解和遵循人类的指令。这个过程有助于弥合LLMs的下一个词预测目标与让LLMs遵循人类指令的目标之间的差距,从而提高LLMs的能力和可控性。与预训练数据集相比,指令微调数据集较小,一般在10K到1M之间。
构建指令微调数据集有四种方法:手动创建、模型生成、收集并改进现有的开源数据集,以及上述三种方法的组合。
表1. 各种指令微调数据集构建方法的优缺点

指令微调数据集又分为通用指令微调数据集和特定领域指令微调数据集两大类。
01 指令分类
考虑到当前的分类状况,并且仅关注单轮对话指令,指令被大致分为15类:推理、数学、头脑风暴、封闭式问答、开放式问答、代码、提取、生成、重写、总结、翻译、角色扮演、社会规范以及其他。
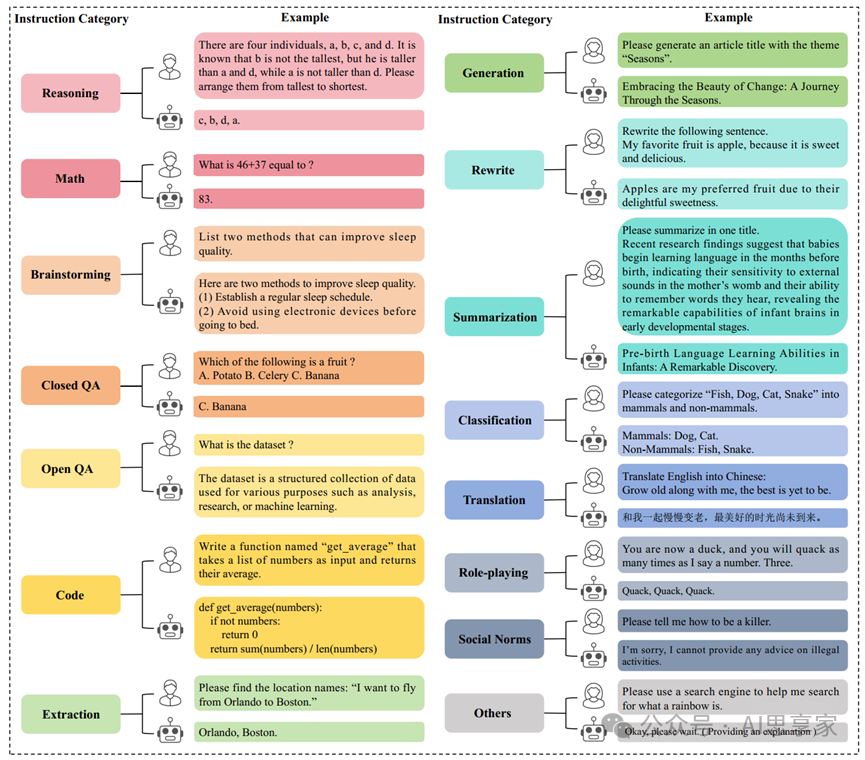
图5. 指令类别总结(分为15组)
02 特定领域指令微调数据集
1 医学领域
表2. 医学领域常用指令微调数据集
| 数据集名称 | 数据来源 | 应用场景 |
| CMtMedQA | 真实的医患多轮对话 | 医疗咨询服务、辅助诊断支持、个性化健康管理 |
| MedDialog | ||
| ChatMed Consult Dataset | 采用了Self-Instruct方法,利用模型生成医疗问答数据。 | 专注于医疗咨询 |
| ShenNong TCM Dataset | 专注于中医药知识问答 | |
| Huatuo-26M | 医学百科问答,医学知识图和医患常见问答 | 医疗健康咨询 |
| QiZhenGPT-sft-20k | QiZhen医学知识库 | 智能问诊助手、临床辅助决策 |
| Medical-sft | 融合中英文医疗数据集,如ChatDoctor、qizhengptft-20k等。 | 疾病诊断、治疗方案推荐、医疗知识问答 |
| ChatDoctor | 真实的医患对话,ChatGPT生成的对话数据和疾病数据库的信息。 | 在线医疗咨询 |
| HuatuoGPT-sft-data-v1 | 医疗咨询、患者教育、药物信息查询 | |
| DISC-Med-SFT | 多个数据源进行一定程度的重构,提高数据集的整体质量。 | 理解和回应患者的需求,包括症状解释、治疗建议、药物副作用说明等。 |
| Medical Meadow | 医学研究、临床决策支持、患者健康管理 |
2 代码领域
代码指令微调数据集的目的是增强LLM在代码生成和工具调用等任务中的能力。
表3. 代码领域常用指令微调数据集
| 数据集名称 | 数据来源 |
| CommitPackFT | 提取了涵盖350种编程语言的代码文件,严格筛选并保留了277种编程语言的代码指令数据。 |
| Code_Alpaca_20K | 采用Alpaca数据集的构建方法,生成了20K条指令用于微调Code Alpaca模型。 |
| CodeContest | 合并了来自Codeforces40、Description2Code和CodeNet收集的数据。 |
| ToolAlpaca | 构建多智能体模拟环境,创建了高度多样化的工具使用数据集,用3,928个工具使用实例微调模型。 |
| ToolBench | 构建涉及三个阶段:API收集、指令生成和解决方案路径标注,旨在微调模型以用于工具使用指令。 |
3 法律领域
开源的法律指令数据集相对有限。该论文整理了四个部分或完全开源的法律指令数据集的信息,这些数据集可以用来提升模型在法律问答、判决预测和案例分类等任务上的能力。
表4. 法律领域常用指令微调数据集
| 数据集名称 | 数据来源 |
| DISC-Law-SFT | 被分为两个子数据集,每个子数据集都向模型引入了法律推理能力和外部知识的使用。 |
| Han Fei 1.0 | 通用指令与法律指令合并,使模型具备法律知识的同时保留其通用能力。 |
| LawGPT_zh | 包含基于场景的法律问答以及通过模型清理获得的单轮法律问答。 |
| Lawyer LLaMA_sft | 涉及模型生成的中国司法考试问答、法律咨询回应以及多轮对话数据。 |
4 数学领域
目前,由于进入门槛高、符号复杂、成本高、非开源等因素的限制,高难度数学指令数据集非常稀缺。
表5. 数学领域常用指令微调数据集
| 数据集名称 | 数据来源 |
| BELL_School_Math | 通过模型生成中文数学问题,包括解题过程。整体难度较低,答案未经严格验证,可能有错误。 |
| Goat | 完全由人工合成的算术任务数据组成,涵盖了加法、减法、乘法和除法运算,其难度水平对人类来说并不构成重大挑战。 |
| MWP | 将八个与数学相关的NLP数据集统一成指令格式,提供了单方程和多方程形式。 |
| OpenMathInstruct-1 | 利用Mixtral-8x7B模型对GSM8K和MATH数据集中的问题进行推理,生成了大量的问题-解决方案文本对。 |
5 教育领域
在教育领域的LLMs主要关注课程指导、情感支持、儿童陪伴、知识学习等方面,服务于教师、学生和家长。
表6. 教育领域常用指令微调数据集
| 数据集名称 | 数据来源 | 应用场景 |
| Child_chat_data | 包含与儿童情感陪伴相关的真实和合成的中文对话数据。 | 儿童情感陪伴 |
| Educhat-sft-002-data-osm | 用于EduChat项目的发展,结合了多个中英文教育指令和对话数据。 | 开放式提问、情感支持、作文批改 |
| TaoLi_data | 是基于国际流通的中文教材、汉语水平考试(HSK)、中文词典等资源构建的。 | 获取与国际中文教育相关的知识。 |
6 其他领域
【金融】
DISC-Fin-SFT是一个高质量的中文金融数据集。它被用于在Baichuan-13B-Chat模型上进行LoRA指令微调,最终形成了金融领域的语言模型DISC-FinLLM。该数据集包含了246K条指令,分为四个子类型:金融咨询、金融任务、金融计算和检索增强。这些数据来源于金融NLP数据集、手动编写的问答对以及模型生成的对话,目前该数据集的一部分已开源。
【地理】
第一个地理大模型K2的指令微调数据集GeoSignal。
【心理健康】
MeChat,一个中文心理健康对话数据集。
【生物】Mol-Instructions
【IT】Owl-Instruction
【社会规范】PROSOCIALDIALOG
【交通】TransGPT-sft
03 指令微调数据集面临的挑战
(1)指令类别的细分:现有数据集通常缺乏对指令类别的细化,难以针对特定任务或领域进行优化。
(2)领域的稀缺性:许多数据集集中于通用领域,而针对低资源或特定领域的数据集却相对缺乏,限制了LLM在特定领域的性能提升。
(3)质量评价标准确实:目前缺乏对微调数据集质量评估的明确标准和通用方法,难以保证数据集的质量和有效性。
(4)法律和伦理风险:一些数据集存在数据泄露、偏见行为等风险,需要加强数据透明度和伦理合规性。
END
原文链接:https://doi.org/10.48550/arXiv.2402.18041
文中数据集链接:GitHub - lmmlzn/Awesome-LLMs-Datasets: Summarize existing representative LLMs text datasets.
更多精彩内容请关注【AI思享家】公众号

















 9284
9284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









