




论文题目:GRAMIAN MULTIMODAL REPRESENTATION LEARNING AND ALIGNMENT
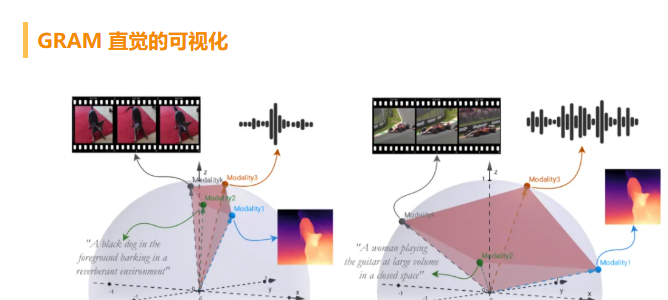
在多模态数据处理领域,传统基于余弦相似度的成对对齐方法始终存在扩展性瓶颈。与之不同,Gramian Representation Alignment Measure(GRAM)另辟蹊径,创新性地通过计算k 维平行六面体体积,精准度量模态间的对齐程度。该方法直接作用于模态嵌入的高维空间,支持n 个模态同时对齐,彻底打破了传统方法仅适用于两两对齐的局限,为多模态融合提供了更高效的解决方案。
为进一步优化高维嵌入空间的对齐效果,研究团队提出基于 GRAM 的对比损失函数。该函数以 GRAM 体积计算为核心,引导多模态模型构建高度统一的嵌入空间。通过最小化模态向量张成的平行六面体体积,模型在下游任务中实现了性能突破,刷新了多项基准测试的最优结果。
GRAM 的价值不仅限于对齐度量,更可作为量化多模态模型性能的关键指标。实验数据显示,GRAM 度量值与下游任务性能呈现显著相关性(Pearson 相关系数达 0.923),即平行六面体体积越小,模型性能越优,这一发现为多模态模型的评估与优化提供了全新视角。
核心方法解析
GRAM 通过计算模态向量张成的 k 维平行六面体体积,直接在高维空间中对齐 n 个模态。其核心逻辑在于:通过最小化 Gramian 体积,实现模态间的几何对齐 —— 当多模态数据语义高度一致时,嵌入向量形成的平行六面体体积趋近于零;反之,模态错位会导致体积显著增大。这种量化方式为多模态对齐提供了直观且可计算的衡量标准。
模型架构创新
GRAM 模型架构深度融合体积度量与多模
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1824
1824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









