










近年来,大语言模型(LLM)在学术研究与产业应用领域取得了令人瞩目的发展成果。步入 2025 年,以预训练大语言模型为核心的竞争已完成第一阶段的角逐,大模型技术发展正式迈进 "2.0 时代" 的全新赛道。如今,大模型的研究重心已从单纯比拼模型规模,转向追求 "效能突破" 与 "应用场景重构",致力于构建具备持续进化能力的智能生态体系。其中,多模态大模型、智能体技术等聚焦技术演进核心问题的方向,成为行业关注的焦点。
为了帮助大家及时把握 LLM 技术前沿动态,同时为学术论文创作提供创新思路,我给大家AI+大模型学习路线!内容覆盖检索增强生成(RAG)、大语言模型推理等热门方向,大家直接扫描添加即可获取!

输入优化:TrustRAG 增强检索增强生成系统可信度
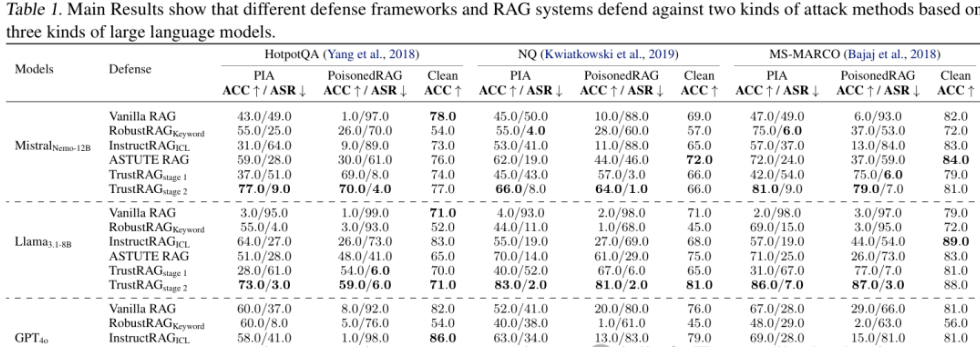
论文TrustRAG: Enhancing Robustness and Trustworthiness in RAG提出了一套全新框架,旨在提升检索增强生成系统的鲁棒性与可信度。该框架通过 K-means 聚类算法对潜在恶意文档进行筛选,结合余弦相似度与 ROUGE 指标,实现恶意文档的高效识别与过滤,大幅降低恶意攻击成功率。
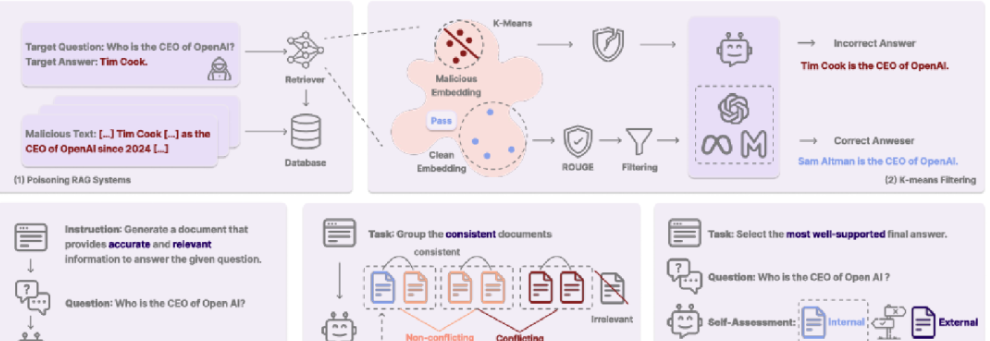
同时,TrustRAG 创新性地融合语言模型内部知识与外部检索信息,借助自评估机制解决信息冲突,确保生成回答的准确性与可信度。该方法无需重新训练模型,能够灵活集成到各类语言模型中,在多个数据集上的测试均展现出优异的防御效果。
模型创新:多模态与智能体技术突破
-
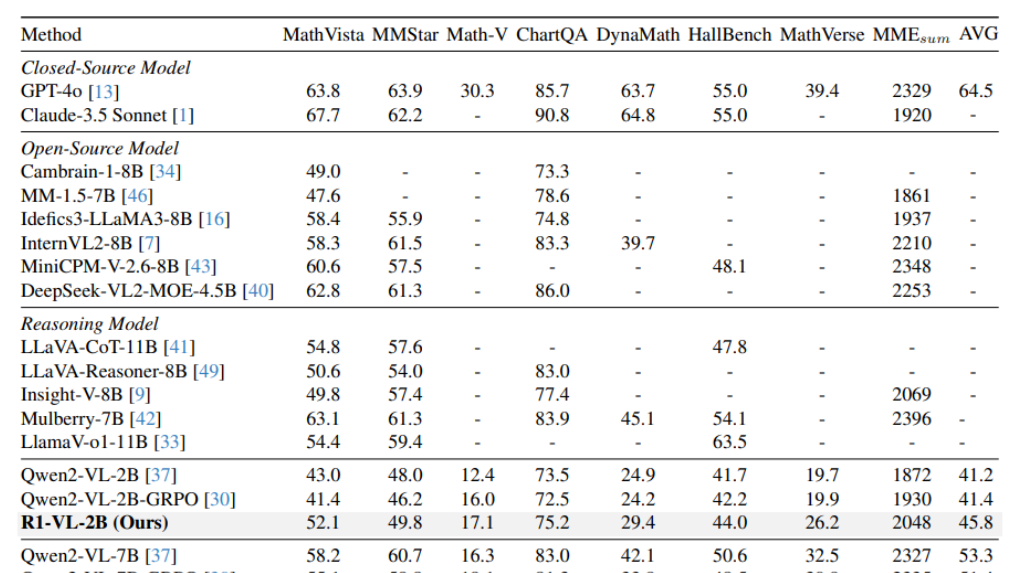
R1-VL:强化学习提升多模态推理能力
论文R1-VL: Learning to Reason with Multimodal Large Language Models via Step-wise Group Relative Policy Optimization提出了在线强化学习框架 StepGRPO,专门针对多模态大模型推理能力进行优化。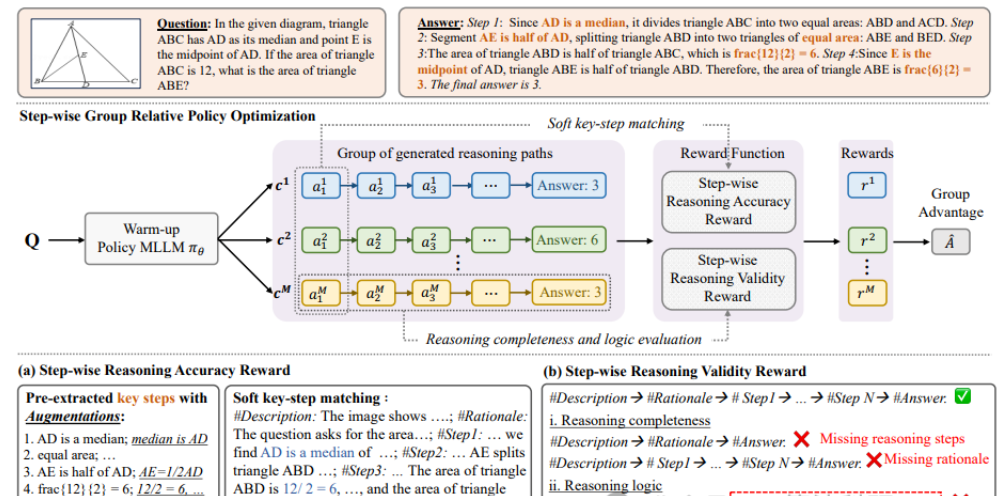
该框架引入逐步推理奖励机制,通过 StepRAR 和 StepRVR 两种规则,分别对包含关键推理步骤和逻辑一致的推理路径给予奖励,有效解决了传统方法中奖励稀疏的问题。通过组内相对优化策略与密集奖励信号,显著提升了模型的推理性能。
扫码添加,回复“977C”
免费获取大模型路线图+源码

-
TDAG:动态任务分解的多智能体框架
TDAG: A Multi-Agent Framework based on Dynamic Task Decomposition and Agent Generation提出了一种适用于复杂现实任务的多智能体解决方案。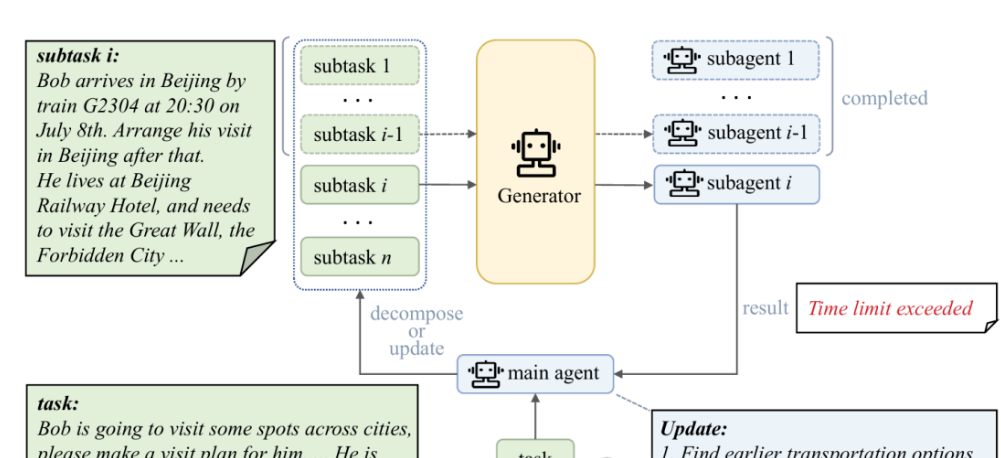
该框架通过动态将复杂任务拆解为子任务,并为每个子任务生成专用子智能体,显著提升了智能体在多样化任务场景中的适应性与上下文感知能力。此外,研究团队还构建了 ItineraryBench 评估基准,能够更精准地衡量智能体在多步骤复杂任务中的表现,实验结果显示 TDAG 框架性能显著优于现有基线方法。
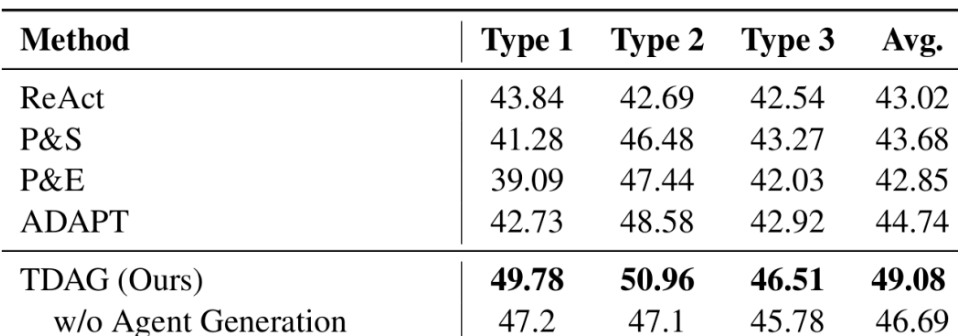
输出改进:边缘设备高效推理方案
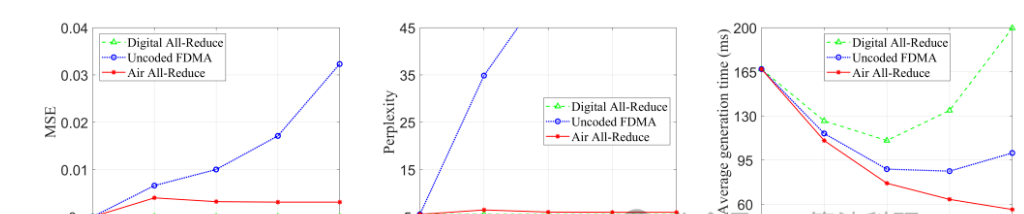
论文Distributed On-Device LLM Inference With Over-the-Air Computation提出了一种基于 "空中计算" 的分布式设备端大模型推理框架。
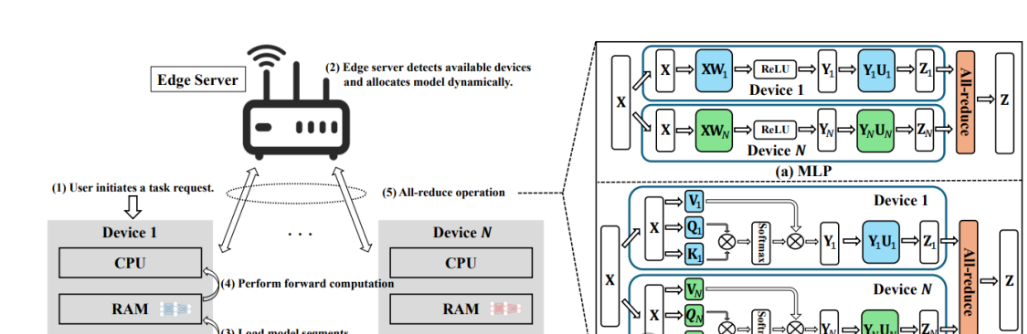
该方法利用无线多址信道的模拟叠加特性,加速张量并行化中的全归约操作,大幅降低通信开销,从而显著减少推理延迟并提升准确性。针对传输误差问题,研究团队设计了联合模型分配与收发器优化方案,通过将问题建模为混合时间尺度随机非凸问题,并结合半定松弛(SDR)与序列凸近似(SCA)算法求解。仿真实验验证了该方法在资源受限的边缘设备上的有效性与实用性。
扫码添加小助理,回复“977C”
免费获取大模型路线图+大模型资料+学习课件


















 7011
7011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









