






点击下方“ReadingPapers”卡片,每天获取顶刊论文解读
论文信息
题目:Eye-gaze Guided Multi-modal Alignment for Medical Representation Learning
眼动引导的多模态对齐用于医学表示学习
作者:Chong Ma, Hanqi Jiang, Wenting Chen, Yiwei Li, Zihao Wu, Xiaowei Yu, Zhengliang Liu, Lei Guo, Dajiang Zhu, Tuo Zhang, Dinggang Shen, Tianming Liu
论文创新点
眼动数据整合:作者首次将眼动数据引入到视觉-语言预训练中,提出了眼动引导的多模态对齐框架(EGMA),利用放射科医生在诊断过程中的眼动数据来辅助医学图像和文本特征的对齐。
细粒度对齐优化:通过将眼动数据转化为标记级别的关联矩阵,作者优化了图像块和文本标记之间的细粒度对齐,显著提升了模型在多模态特征对齐中的表现。
跨模态映射增强:作者引入了眼动引导的跨模态映射,利用眼动数据双向引导图像和文本之间的特征映射,进一步增强了模型处理多模态数据的能力,特别是在图像分类和图像-文本检索任务中表现出色。
摘要
在医学多模态框架中,跨模态特征的对齐是一个显著的挑战。然而,现有工作从数据中隐式学习了对齐特征,而没有考虑医学背景中的显式关系。这种对数据的依赖可能导致学习到的对齐关系泛化能力较低。在这项工作中,作者提出了眼动引导的多模态对齐(EGMA)框架,利用眼动数据来更好地对齐医学视觉和文本特征。作者探索了放射科医生眼动数据在自然辅助对齐医学图像和文本中的作用,并引入了一种新颖的方法,通过在诊断评估期间同步收集的眼动数据。作者在四个医学数据集上进行了图像分类和图像-文本检索的下游任务,EGMA在这些任务中达到了最先进的性能,并在不同数据集上表现出更强的泛化能力。此外,作者还探讨了不同数量的眼动数据对模型性能的影响,突出了将这种辅助数据整合到多模态对齐框架中的可行性和实用性。
关键词
医学多模态对齐,眼动,放射学
III. 方法
如图2所示,作者提出的方法框架由四个主要部分组成。首先,在部分A中,作者从图像和文本中提取特征,以获得精炼的实例级别相似度矩阵。其次,在部分B中,作者整合了从放射科医生的音频、图像和眼动数据中提取的文本转录,以可视化和映射放射科医生在诊断期间对图像特定区域的关注。这一过程建立了文本和图像之间的对齐,促进了模型训练。详细的眼动数据处理方法在第III-A节中描述。由于眼动数据紧密连接了文本和局部视觉信息,在从部分B获取辅助信息后,作者引入了眼动引导的精炼对齐训练策略,如图2的C和D部分所示。具体而言,作者在第III-B节中介绍了眼动引导的细粒度文本-图像相似度矩阵的优化算法。最后,在第III-C节中,作者提出了眼动引导的跨模态映射算法。
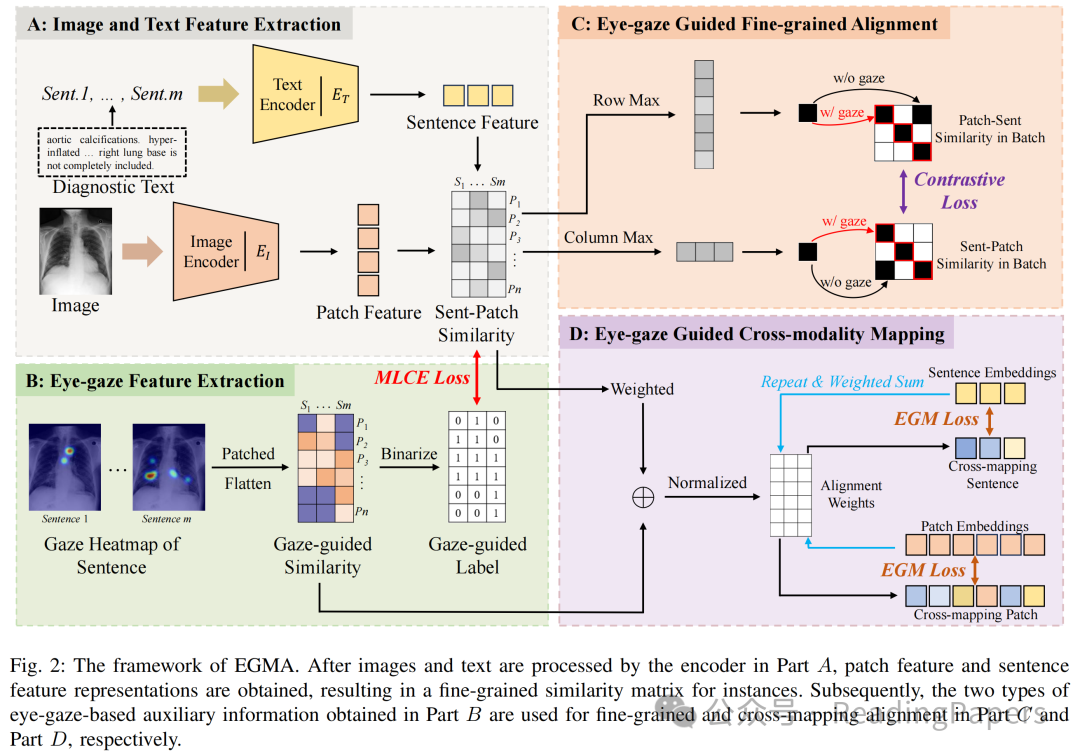
A. 多模态数据处理
随着眼动追踪和语音识别等数据收集技术的发展,现在可以收集和处理放射科医生在诊断过程中的多模态交互数据。在这项工作中,作者利用MIMIC-EYE数据集作为训练集,该数据集包含从MIMIC数据集中提取的3689张图像。每个样本都附有相应的眼动追踪数据和转录文本。这些眼动追踪数据由PhysioNet上公开可用的EYE GAZE和REFLACX数据集提供。由于每种模态都是同步的,音频数据与眼动数据在时间上对齐。通过根据每个单词发音前后的时间分割音频,作者可以将转录与音频对齐,从而将句子级别的文本与眼动数据对齐。随后,作者根据眼动数据和图像生成注意力热图,表示放射科医生关注的图像区域。通过上述数据处理步骤,作者实现了句子级别文本和图像区域之间的精确对齐。眼动和音频转录的详细处理方法可在补充材料中找到。
B. 眼动引导的细粒度对齐
对比学习的核心思想是将相关样本的特征拉近,同时将不相关样本的特征推远。在CLIP模型的训练过程中,假设批次大小为,输入数据为(),表示图像-文本对,通过图像编码器和文本编码器获取全局特征和。随后,计算两种模态之间的余弦相似度和,公式如下:
其中,是图像到文本的相似度,是文本到图像的相似度,是另一种模态的索引号。然后,图像到文本的对比损失和文本到图像的对比损失可以表示为:
其中,是一个可学习的温度参数。值得注意的是,在上述损失的计算中,图像和文本都使用了全局级别的特征,而眼动数据生成的辅助信息强调了模态之间的局部级别特征。因此,基于FILIP,作者将实例特征和替换为和,其中是的第个图像块特征,是的第个句子特征,分别是图像块的数量和报告的句子数量。然后,作者计算句子到图像块和图像块到句子在一个实例中的相似度:
对于每个与句子对应的热图,作者首先将其划分为个图像块。随后,作者将个句子的热图连接起来,得到输入的眼动引导相似度矩阵(如图2.B所示)。在该矩阵中,非零元素表示相应句子与图像块之间的语义相关性。因此,作者将二值化,将非零区域设置为1,得到眼动引导标签矩阵。在此步骤之后,作者计算和的多标签交叉熵(MLCE)损失,完成正样本对之间的细粒度对齐优化,如下所示:
其中,是多标签交叉熵损失。随后,作者计算细粒度特征和。然后,作者将替换为更新后的,并在公式1中计算细粒度图像到文本损失和文本到图像损失。作者的眼动引导细粒度(EGF)对齐损失公式如下:
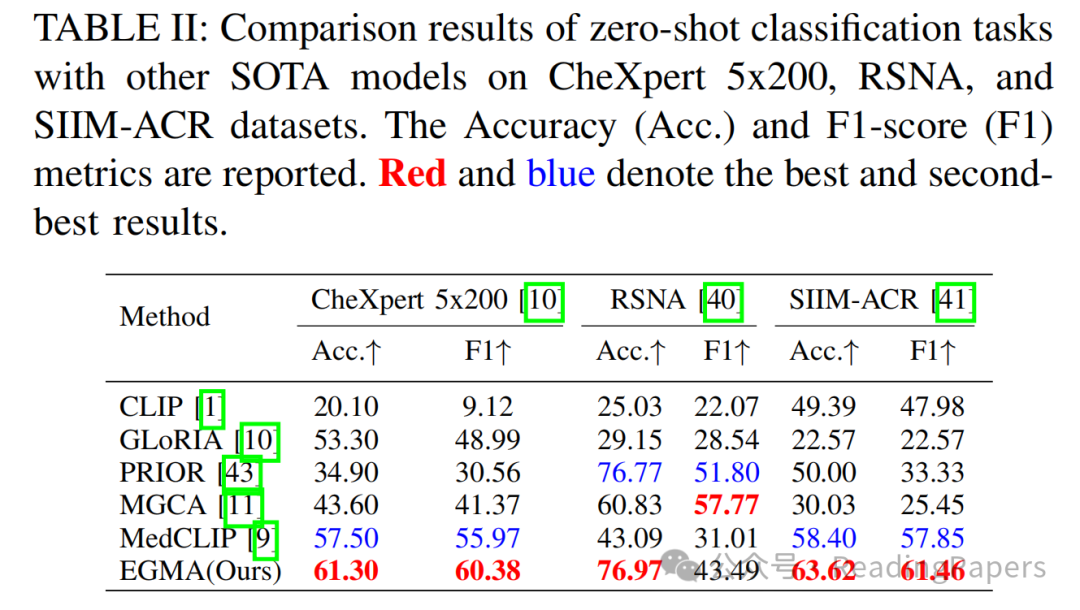
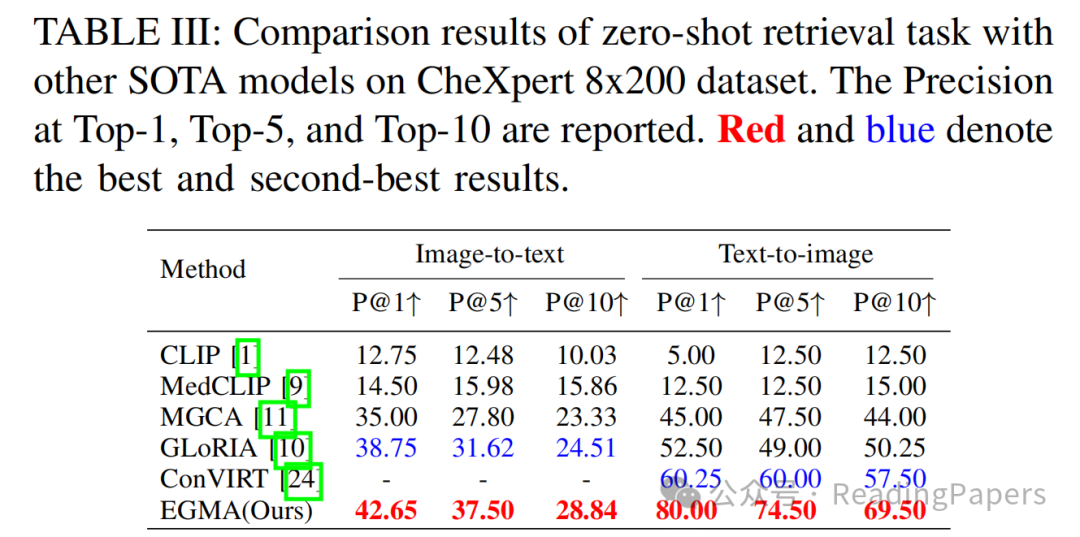
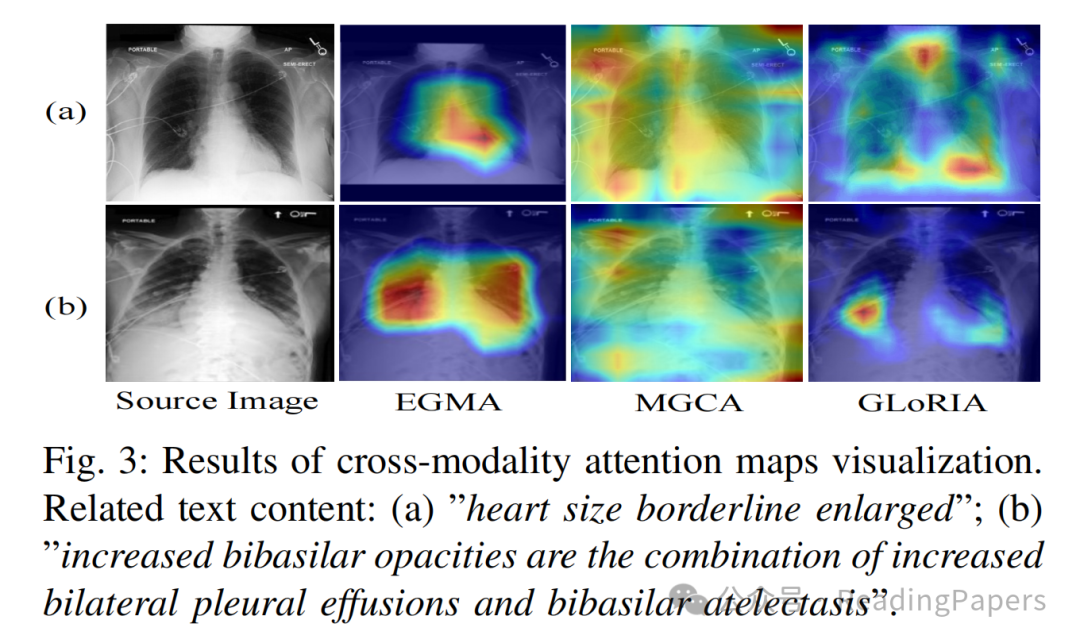
IV. 实验
声明
本文内容为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。本文信息旨在传播和学术交流,其内容由作者负责,不代表本号观点。文中作品文字、图片等如涉及内容、版权和其他问题,请及时与我们联系,我们将在第一时间回复并处理。


















 40
40

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









