







2024年10月08日更新
C3K2(YOLO11)
C3K2 模块 是 YOLO11 模型中的一种重要特征提取组件,是基于传统 C3 模块的改进设计。它通过结合可变卷积核(例如 3x3、5x5 等)和通道分离策略,提供了更强大的特征提取能力,尤其适用于更复杂的场景和深层次的特征提取任务。
C3K2 模块结构特点
-
可变卷积核设计:相比于标准 C3 模块,C3K2 引入了多尺度的卷积核C3K,其中K为可调整的卷积核大小,如 3x3、5x5 等。这种设计可以扩展感受野,使模型能够捕捉更广泛的上下文信息,尤其适合大物体检测或背景复杂的场景。
-
特征分割和拼接:C3K2 模块通常将输入特征分为两部分,一部分通过普通的卷积操作直接传递,另一部分则通过多个C3K(当c3k参数设置为True时)或 Bottleneck 结构进行深度特征提取。最终两部分特征进行拼接,并通过 1x1 卷积进行融合。此结构既能保持轻量化,又能有效提取深层次特征。
-
增强的特征提取能力:由于使用了不同大小的卷积核,C3K2 在处理复杂场景时能显著提高特征提取的精度,特别是在物体边界和复杂背景中的检测能力方面。
C3K2 模块实现代码
class C3k2(C2f):
"""
C3k2 模块是带有 2 个卷积操作的加速版 CSP Bottleneck 模块,并且可以选择性地使用 C3k 块。
"""
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
"""
初始化 C3k2 模块。
参数:
- c1: 输入通道数
- c2: 输出通道数
- n: Bottleneck 模块的重复次数
- c3k: 是否使用 C3k 模块
- e: 扩展因子,决定隐藏通道数
- g: 分组卷积参数
- shortcut: 是否使用残差连接
"""
super(C3k2, self).__init__()
self.c = int(c2 * e) # 计算隐藏通道数
# 定义 1x1 卷积层,用于将输入调整到 2 倍的隐藏通道数
self.cv1 = nn.Conv2d(c1, 2 * self.c, kernel_size=1, stride=1, bias=False)
self.cv2 = nn.Conv2d(2 * self.c, c2, kernel_size=1, stride=1, bias=False)
# 定义模块列表,使用 C3k 或 Bottleneck 模块
self.m = nn.ModuleList(
C3k(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck(self.c, self.c, shortcut, g) for _ in range(n)
)
def forward(self, x):
"""
前向传播函数,处理输入张量。
参数:
- x: 输入张量
返回:
- 经过 C3k2 模块处理后的输出张量
"""
# 将 cv1 的输出分成两部分
y = list(self.cv1(x).chunk(2, dim=1)) # 使用 chunk 操作将通道维度分成两部分
# 对每个模块列表中的模块进行处理,并将结果添加到 y 中
y.extend(m(y[-1]) for m in self.m)
# 将所有部分拼接并通过 cv2 恢复通道数
return self.cv2(torch.cat(y, dim=1))
C3K2 模块结构图

C3K(YOLO11)
C3K 模块 是 YOLO11 模型中的一个关键模块,它在传统 C3 模块的基础上进行了增强,旨在提高特征提取能力,特别是适应更复杂的任务和多尺度检测需求。相比于传统的 C3 模块,C3K 引入了更多灵活性,尤其是在卷积核设计方面。
C3K 模块的特点
-
可变卷积核大小:C3K 模块允许使用不同的卷积核大小,如 3x3、5x5,甚至更大的卷积核。这使得模型能够在不同尺度上提取特征,扩展了感受野,尤其有助于捕捉更复杂的空间特征。
-
瓶颈结构增强:类似于 C3 模块,C3K 也使用了瓶颈结构(Bottleneck),但它结合了更大的卷积核,使得特征提取能力更强,尤其是在大物体检测或复杂背景的场景中表现出色。
-
轻量化和高效性:尽管 C3K 增加了卷积核大小,但它仍然保持了较为轻量化的设计。通过分支结构和特征拼接,C3K 模块在保持高效计算的同时,提升了模型的检测精度。
C3K 模块实现代码
class C3k(C3):
"""
C3k 模块,提供自定义卷积核大小的 CSP Bottleneck 模块。
"""
def __init__(self, c1, c2, n=1, shortcut=True, g=1, k=3):
"""
初始化 C3k 模块。
参数:
- c1: 输入通道数
- c2: 输出通道数
- n: Bottleneck 模块的重复次数
- shortcut: 是否使用残差连接
- g: 分组卷积参数
- k: 卷积核大小
"""
super(C3k, self).__init__()
hidden_channels = int(c2 * 0.5) # 默认扩展因子为 0.5
# 定义卷积层
self.cv1 = nn.Conv2d(c1, hidden_channels, kernel_size=1, stride=1)
self.cv2 = nn.Conv2d(c1, hidden_channels, kernel_size=1, stride=1)
self.cv3 = nn.Conv2d(2 * hidden_channels, c2, kernel_size=1, stride=1)
# 定义 Bottleneck 模块序列,使用自定义卷积核大小
self.m = nn.Sequential(
*[Bottleneck(hidden_channels, hidden_channels, shortcut, g=g, k=(k, k), e=1.0) for _ in range(n)]
)
def forward(self, x):
"""
前向传播函数,处理输入张量。
参数:
- x: 输入张量
返回:
- 经过 C3k 模块处理后的输出张量
"""
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
C3K 模块结构图

Bottleneck(ResNet)
Bottleneck 模块 是神经网络中常用的一种结构,特别是在目标检测、图像分类和分割任务中具有广泛的应用。它最初在 ResNet(残差网络) 中被引入,旨在提高网络的深度和表现能力,同时减少计算量。
Bottleneck 模块结构特点
-
通道压缩和扩展:
- 输入降维:Bottleneck 模块首先通过 1x1 卷积将输入特征图的通道数进行压缩,减少计算量。这一过程也称为 "降维"。
- 中间卷积:随后使用 3x3 或更大的卷积核进行特征提取,这是模块中的核心计算部分。此时,特征图的空间维度保持不变。
- 输出扩展:最后通过另一个 1x1 卷积将通道数扩展回原始的大小。
-
残差连接:Bottleneck 模块与残差连接(Residual Connection)结合,形成了跳跃连接(Skip Connection),使输入特征能够直接与输出进行相加。这一结构使得网络在深层次的情况下仍能有效训练,缓解了梯度消失问题。
Bottleneck 模块实现代码
class Bottleneck(nn.Module):
"""
Bottleneck 模块,用于特征提取,包含 1x1 和 3x3 卷积层,并带有残差连接。
"""
def __init__(self, in_channels, out_channels, shortcut=True, g=1, e=0.5):
"""
初始化 Bottleneck 模块。
参数:
- in_channels: 输入通道数
- out_channels: 输出通道数
- shortcut: 是否使用残差连接
- g: 分组卷积参数
- e: 扩展因子,控制 Bottleneck 中的隐藏通道数
"""
super(Bottleneck, self).__init__()
hidden_channels = int(out_channels * e)
# 1x1 卷积用于降维
self.conv1 = nn.Conv2d(in_channels, hidden_channels, kernel_size=1, stride=1, bias=False)
self.bn1 = nn.BatchNorm2d(hidden_channels)
# 3x3 卷积用于提取特征,使用自定义卷积核大小
self.conv2 = nn.Conv2d(hidden_channels, out_channels, kernel_size=3, stride=1, padding=1, groups=g, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
# 判断是否需要残差连接
self.shortcut = nn.Identity() if in_channels == out_channels and shortcut else None
def forward(self, x):
"""
前向传播函数,处理输入张量。
参数:
- x: 输入张量
返回:
- 经过 Bottleneck 模块处理后的输出张量
"""
residual = x
x = self.conv1(x)
x = self.bn1(x)
x = torch.relu(x)
x = self.conv2(x)
x = self.bn2(x)
if self.shortcut is not None:
x += residual
return torch.relu(x)
Bottleneck 模块结构图

C2PSA (YOLO11)
C2PSA 模块是 YOLO11 中用于增强特征提取的一个高级模块,结合了 CSP (Cross Stage Partial) 结构和 PSA (Pyramid Squeeze Attention) 注意力机制,从而提升了多尺度特征提取能力。它主要用于复杂场景下的目标检测,特别是在处理多尺度物体时表现出色。
模块结构特点
- CSP 结构:C2PSA 模块继承了 CSP 的分段特征处理思想,特征经过一次 1x1 卷积后被分成两部分,一部分直接传递,另一部分经过 PSA 注意力模块处理,然后将两部分特征拼接,并经过另一个 1x1 卷积来恢复原始通道数。
- PSA(Pyramid Squeeze Attention)机制:PSA 机制通过多种卷积核(如 3x3、5x5、7x7 等)来提取多尺度特征。不同卷积核的卷积操作并行进行,之后将特征图拼接,并使用 SE (Squeeze-and-Excitation) 模块为特征通道加权。
- 最后,通过 Softmax 生成的注意力权重应用到各个特征图上,从而实现通道逐点加权 (Channel-wise multiplication),提升对重要特征的关注度。
C2PSA 模块实现代码
import torch
import torch.nn as nn
class C2PSA(nn.Module):
"""
C2PSA 模块实现,结合了卷积和 Pyramid Squeeze Attention (PSA) 注意力机制,
用于增强特征表示能力。
"""
def __init__(self, c1, c2, n=1, e=0.5):
"""
初始化 C2PSA 模块。
参数:
- c1: 输入通道数,确保与 c2 相等
- c2: 输出通道数
- n: 重复 PSABlock 的次数
- e: 扩展因子,控制隐藏通道数的大小
"""
super().__init__()
assert c1 == c2 # 确保输入通道数与输出通道数相同
self.c = int(c1 * e) # 计算隐藏通道数
# 1x1 卷积层,将输入通道数变为 2 倍的隐藏通道数
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
# 最终的 1x1 卷积层,将通道数恢复到原始的输出通道数
self.cv2 = Conv(2 * self.c, c1, 1, 1)
# 使用 PSA Block 处理分割后的特征,定义一个包含多个 PSABlock 的序列
# PSA Block 中的注意力比率设置为 0.5,num_heads 控制多头注意力的数量
self.m = nn.Sequential(
*(PSABlock(self.c, attn_ratio=0.5, num_heads=self.c // 64) for _ in range(n))
)
def forward(self, x):
"""
前向传播函数,处理输入张量 x,通过 PSA blocks 后返回处理后的张量。
参数:
- x: 输入的张量
返回:
- 经过处理的输出张量
"""
# 输入张量 x 经过第一个 1x1 卷积层 self.cv1 处理
# 使用 split 将通道维度按隐藏通道数 self.c 分割为两个部分 a 和 b
a, b = self.cv1(x).split((self.c, self.c), dim=1)
# 通过 PSA blocks 处理 b 分支
b = self.m(b)
# 将经过处理的 b 分支和未处理的 a 分支在通道维度拼接
# 然后经过第二个 1x1 卷积层恢复原通道数
return self.cv2(torch.cat((a, b), dim=1))
C2PSA模块结构图

PSA (EPSANet)
Pyramid Squeeze Attention (PSA) 是一种高效的注意力机制,旨在提升卷积神经网络在多尺度特征提取中的表现。PSA 模块通过引入不同大小的卷积核来提取多尺度的空间信息,同时结合 Squeeze-and-Excitation (SE) 模块对特征通道进行加权,从而增强网络对不同尺度目标的注意力聚焦。
PSA 模块结构特点
- 多尺度卷积:PSA 模块使用不同大小的卷积核(如 3x3、5x5、7x7 等),并行处理输入特征图。每个卷积核能够在不同的感受野上提取特征,从而捕捉多尺度信息。卷积核越大,感受野越大,适合检测大物体;卷积核越小,适合捕捉小物体的细节。
- Squeeze-and-Excitation (SE) 模块:SE 模块用于对特征通道进行加权。通过全局平均池化,SE 模块提取全局信息,然后通过两个全连接层生成每个通道的注意力权重,最后使用 Sigmoid 函数生成权重。这样,网络可以根据不同通道的重要性重新调整特征。
- Softmax 权重加权:PSA 模块使用 Softmax 机制对每个通道生成的权重进行归一化处理,从而为每个特征通道赋予不同的重要性。这使得网络能够更加专注于最重要的特征,同时忽略冗余或不相关的特征。
PSA 模块实现代码
# PSA (Pyramid Squeeze Attention) 模块定义
class PSAModule(nn.Module):
"""
Pyramid Squeeze Attention (PSA) 模块:
通过多种不同卷积核大小和分组卷积提取多尺度特征,并使用 SE 模块进行特征加权。
"""
def __init__(self, inplans, planes, conv_kernels=[3, 5, 7, 9], stride=1, conv_groups=[1, 4, 8, 16]):
"""
初始化 PSA 模块。
参数:
- inplans: 输入通道数
- planes: 输出通道数
- conv_kernels: 使用的卷积核大小列表
- stride: 卷积的步长
- conv_groups: 分组卷积数量列表
"""
super(PSAModule, self).__init__()
# 定义四个不同卷积核大小和分组数的卷积层
self.conv_1 = conv(inplans, planes // 4, kernel_size=conv_kernels[0], padding=conv_kernels[0] // 2,
stride=stride, groups=conv_groups[0])
self.conv_2 = conv(inplans, planes // 4, kernel_size=conv_kernels[1], padding=conv_kernels[1] // 2,
stride=stride, groups=conv_groups[1])
self.conv_3 = conv(inplans, planes // 4, kernel_size=conv_kernels[2], padding=conv_kernels[2] // 2,
stride=stride, groups=conv_groups[2])
self.conv_4 = conv(inplans, planes // 4, kernel_size=conv_kernels[3], padding=conv_kernels[3] // 2,
stride=stride, groups=conv_groups[3])
# 使用 SE 模块进行加权
self.se = SEWeightModule(planes // 4)
self.split_channel = planes // 4
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
"""
前向传播函数。
参数:
- x: 输入张量 (batch_size, channels, height, width)
返回:
- 加权后的输出张量
"""
batch_size = x.shape[0]
# 四个不同卷积核的特征提取
x1 = self.conv_1(x)
x2 = self.conv_2(x)
x3 = self.conv_3(x)
x4 = self.conv_4(x)
# 将四个分支特征拼接
feats = torch.cat((x1, x2, x3, x4), dim=1)
feats = feats.view(batch_size, 4, self.split_channel, feats.shape[2], feats.shape[3])
# 使用 SE 模块加权
x1_se = self.se(x1)
x2_se = self.se(x2)
x3_se = self.se(x3)
x4_se = self.se(x4)
# 将所有加权后的特征拼接
x_se = torch.cat((x1_se, x2_se, x3_se, x4_se), dim=1)
attention_vectors = x_se.view(batch_size, 4, self.split_channel, 1, 1)
attention_vectors = self.softmax(attention_vectors)
# 使用注意力权重重新加权特征
feats_weight = feats * attention_vectors
for i in range(4):
x_se_weight_fp = feats_weight[:, i, :, :, :]
if i == 0:
out = x_se_weight_fp
else:
out = torch.cat((out, x_se_weight_fp), 1)
return outPSA模块结构图

SE(Squeeze-and-Excitation Networks)
Squeeze-and-Excitation (SE) 是一种注意力机制模块,首次由 Jie Hu 等人 在 2018 年提出,目的是增强卷积神经网络中的特征表示能力。它通过动态调整每个特征通道的权重来提升模型的表示能力,从而使模型能够更加关注重要的特征并忽略不相关的信息。
SE模块结构特点
-
Squeeze(压缩):通过 全局平均池化,将输入特征图的空间维度压缩为全局特征向量,得到每个通道的全局特征表示。这一步使得模型可以在全局范围内整合空间信息。
-
Excitation(激发):然后通过两层全连接网络对通道权重进行建模,计算出每个通道的重要性。在第一层全连接层中,通道数量首先被减少(通过降维操作,通常是减少 16 倍),以减小计算成本。第二层全连接层恢复通道数,最终通过 Sigmoid 激活函数生成每个通道的权重。
-
Reweighting(重新加权):最后,生成的通道权重被应用到输入的特征图上,通过逐通道乘法调整每个通道的特征强度。这样,重要的特征通道被增强,而不重要的特征被抑制。
SE模块实现代码
# Squeeze-and-Excitation (SE) 模块,用于特征加权
class SEWeightModule(nn.Module):
"""
Squeeze-and-Excitation (SE) 模块:
通过全局池化和两层全连接网络,对特征通道进行重新加权。
"""
def __init__(self, channels, reduction=16):
"""
初始化 SE 模块。
参数:
- channels: 输入的通道数
- reduction: 降维比率,通常是 16
"""
super(SEWeightModule, self).__init__()
# 全局平均池化,将空间维度压缩为 1x1
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# 第一个 1x1 卷积层用于减少通道数,通道数为 channels // reduction
self.fc1 = nn.Conv2d(channels, channels // reduction, kernel_size=1, padding=0)
self.relu = nn.ReLU(inplace=True)
# 第二个 1x1 卷积层用于恢复通道数
self.fc2 = nn.Conv2d(channels // reduction, channels, kernel_size=1, padding=0)
# 使用 sigmoid 激活函数生成注意力权重
self.sigmoid = nn.Sigmoid()
def forward(self, x):
"""
前向传播函数。
参数:
- x: 输入张量 (batch_size, channels, height, width)
返回:
- weight: 通道权重 (batch_size, channels, 1, 1)
"""
# 全局平均池化
out = self.avg_pool(x)
# 通过全连接层减少通道数
out = self.fc1(out)
out = self.relu(out)
# 恢复通道数并生成权重
out = self.fc2(out)
weight = self.sigmoid(out)
return weightSE模块结构图

SPPF(YOLOv5)
SPPF (Spatial Pyramid Pooling - Fast) 是 YOLOv5 和 YOLOv8 中用于提升特征提取能力的一个模块。它的设计初衷是为了在不显著增加计算量的情况下,通过引入多尺度特征图池化,扩展网络的感受野并捕捉不同尺度的特征。SPPF 是对 SPP (Spatial Pyramid Pooling) 的优化版本,主要通过减少池化操作的复杂度来加速网络的推理速度。
SPPF模块结构特点
-
多尺度池化:SPPF 在特征图上进行多种不同尺度的池化操作(如 5x5、3x3、1x1 池化),并将这些池化后的特征图拼接在一起。这样,模型可以从不同的空间尺度提取有用的上下文信息,从而提升对不同大小物体的检测能力。
-
计算优化:相比传统的 SPP 模块,SPPF 通过减少池化操作的次数来提升效率。例如,SPPF 中可能只会使用 5x5 的池化,但其结果能够通过有效的计算得到更小池化窗口的结果(如 3x3、1x1 的池化),这样避免了重复的计算,显著提升了速度。
SPPF模块实现代码
class SPPF(nn.Module):
"""
SPPF (Spatial Pyramid Pooling - Fast) 模块:
用于多尺度特征提取,通过减少池化操作的计算量来提升推理速度。
"""
def __init__(self, c1, c2, k=5):
"""
初始化 SPPF 模块。
参数:
- c1: 输入通道数
- c2: 输出通道数
- k: 池化核大小 (默认 5x5)
"""
super(SPPF, self).__init__()
# 1x1 卷积,减少通道维度并调整特征
self.cv1 = Conv(c1, c2, 1, 1)
# 3x3 卷积,用于进一步处理特征,并结合不同尺度的特征
self.cv2 = Conv(c2, c2, 3, 1, k // 2)
# 最大池化层,使用 5x5 的池化核,保持输入尺寸,提取更大感受野的特征
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
"""
前向传播函数。
参数:
- x: 输入张量 (batch_size, channels, height, width)
返回:
- 经过多尺度池化和卷积处理的特征张量
"""
# 第一次卷积,通道数从 c1 降低到 c2
x = self.cv1(x)
# 最大池化操作,得到不同尺度的特征图
y1 = self.m(x) # 第一次 5x5 池化
y2 = self.m(y1) # 第二次 5x5 池化
y3 = self.m(y2) # 第三次 5x5 池化
# 将输入和三次池化得到的特征图在通道维度上拼接
return self.cv2(torch.cat([x, y1, y2, y3], 1)) # 最终通过 3x3 卷积输出SPPF模块结构图

SPP(Spatial Pyramid Pooling)
SPP (Spatial Pyramid Pooling) 是一种经典的深度学习模块,最早由 He et al. 在 2014 年的论文 "Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition" 中提出。SPP 的主要目的是解决卷积神经网络在处理不同输入尺寸图像时,如何生成固定大小的输出特征图的问题。
SPP模块结构特点
- 多尺度池化:SPP 模块在同一个输入特征图上应用不同尺度的池化操作(如 1x1、3x3、5x5 等),这些池化操作可以捕捉不同尺度的空间特征。较小的池化核能够捕捉局部细节,而较大的池化核可以捕捉全局上下文信息。
- 特征拼接:将每个池化操作的输出特征图在通道维度上进行拼接,形成最终的输出特征图。这使得输出特征图能够包含不同尺度的信息。
- 生成固定大小的特征图:通过这种多尺度池化的方式,SPP 模块可以将输入特征图转换为固定尺寸的输出特征图,不管输入的图像大小如何变化。
SPP模块实现代码
class SPP(nn.Module):
"""
SPP (Spatial Pyramid Pooling) 模块,通过多尺度池化增强特征提取能力。
"""
def __init__(self, pool_sizes=[1, 3, 5]):
super(SPP, self).__init__()
# 定义多种池化核大小
self.pools = nn.ModuleList([nn.MaxPool2d(pool_size, stride=1, padding=pool_size // 2) for pool_size in pool_sizes])
def forward(self, x):
"""
前向传播函数。
参数:
- x: 输入特征图 (batch_size, channels, height, width)
返回:
- 拼接后的特征图,包含多尺度信息
"""
# 将每个池化层的输出与输入特征图进行拼接
features = [x] + [pool(x) for pool in self.pools]
return torch.cat(features, dim=1)
SPP模块结构图

C2f(YOLOv8)
C2f 模块 是 YOLOv5 和 YOLOv8 中的一种特征提取模块,主要用于更高效的特征表示和跨通道特征融合。C2f 是对 CSP(Cross Stage Partial)结构的一种改进,通过更有效的特征分支和拼接策略,在保持计算效率的同时提升了网络的特征表达能力。
C2f模块结构特点
-
跨通道特征融合:C2f 模块继承了 CSP 结构的思想,将输入特征图分为两部分:一部分直接传递,另一部分通过多个 Bottleneck 模块处理。最终,两部分特征在通道维度上进行拼接。通过这种分离和融合的方式,网络能够有效地进行跨通道特征提取,提升表达能力。
-
轻量化设计:C2f 相比原始的 CSP 模块进行了简化,进一步减少了计算量。这种轻量化的设计特别适合移动设备或计算资源受限的场景。
-
支持更多 Bottleneck:C2f 模块中可以包含多个 Bottleneck 结构,以便更深入地提取特征。Bottleneck 的数量通常是可配置的,允许根据任务需求进行调整。
C2f模块实现代码
import torch
import torch.nn as nn
class C2f(nn.Module):
"""CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""
初始化函数,定义C2f模块的参数和层次结构。
参数:
- c1: 输入通道数
- c2: 输出通道数
- n: Bottleneck模块的数量
- shortcut: 是否使用残差连接
- g: 卷积层中的组数(用于分组卷积)
- e: 扩展因子,用于计算 Bottleneck 中的隐藏通道数
"""
super().__init__()
self.c = int(c2 * e) # 计算隐藏通道数,通常是输出通道数的某个比例
self.cv1 = Conv(c1, 2 * self.c, 1, 1) # 1x1 卷积层,用于减少通道数,输出2倍隐藏通道数
self.cv2 = Conv((2 + n) * self.c, c2, 1) # 最终的1x1卷积层,恢复到原输出通道数,可能使用FReLU激活函数
# 创建多个 Bottleneck 模块,每个模块有一个卷积层,使用shortcut和分组卷积
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""
前向传播函数,定义C2f模块的计算流程。
参数:
- x: 输入的张量(Tensor)
返回:
- 输出的张量(Tensor)
"""
# 使用1x1卷积将输入分成两部分,并沿通道维度进行分割
y = list(self.cv1(x).chunk(2, 1)) # 将输入切分为两块(沿通道维度)
# 对每个Bottleneck模块处理y的后一部分,并添加到列表中
y.extend(m(y[-1]) for m in self.m) # 将每个 Bottleneck 的输出添加到列表中
# 将所有分支的输出拼接,经过最后的1x1卷积生成最终输出
return self.cv2(torch.cat(y, 1)) # 在通道维度上拼接
def forward_split(self, x):
"""
前向传播的另一种方式,使用 split() 方法代替 chunk() 进行特征切分。
参数:
- x: 输入的张量(Tensor)
返回:
- 输出的张量(Tensor)
"""
# 使用1x1卷积将输入分成两部分,并使用 split() 进行分割
y = list(self.cv1(x).split((self.c, self.c), 1)) # 使用 split 按照指定尺寸切分
# 对每个Bottleneck模块处理y的后一部分,并添加到列表中
y.extend(m(y[-1]) for m in self.m) # 将每个 Bottleneck 的输出添加到列表中
# 将所有分支的输出拼接,经过最后的1x1卷积生成最终输出
return self.cv2(torch.cat(y, 1)) # 在通道维度上拼接
C2f模块结构图

Conv(全系列)
卷积层是 YOLO 系列模型的核心,用于提取特征。通常使用带有 BN (Batch Normalization) 和 Leaky ReLU 或 SiLU 激活函数的卷积层来加速收敛,并且提高模型的表达能力和鲁棒性。
Conv典型结构
-
Conv -> BN -> Leaky ReLU/SiLU
- 输入维度:
(batch_size, c1, height, width) - 输出维度:
(batch_size, c2, height, width)(与输入相同的空间尺寸,通道数变为c2) - 操作:
- 卷积操作:使用
k x k的卷积核(默认 3x3)进行特征提取,步长s控制卷积移动的步长。 - Batch Normalization:归一化卷积后的特征图,使其数值稳定。
- 激活函数:使用 SiLU(或 Leaky ReLU)进行非线性映射。
- 卷积操作:使用
- 卷积核大小:
k x k(通常为 3x3) - 步长:
s(默认 1) - 通道数变化:
c1 -> c2 - 空间尺寸变化:空间尺寸根据步长、填充等因素可能保持不变。
Conv模块实现代码
class Conv(nn.Module):
"""
标准卷积模块,包含卷积、Batch Normalization 和激活函数 (SiLU)。
"""
def __init__(self, c1, c2, k=3, s=1, p=None, g=1, act=True):
"""
参数:
- c1: 输入通道数
- c2: 输出通道数
- k: 卷积核大小 (默认 3x3)
- s: 步长 (默认 1)
- p: 填充 (如果为 None,则自动计算)
- g: 分组卷积数 (默认 1)
- act: 是否使用激活函数 (默认 True)
"""
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False) # 卷积层
self.bn = nn.BatchNorm2d(c2) # Batch Normalization
self.act = nn.SiLU() if act else nn.Identity() # 激活函数 (SiLU)
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def autopad(k, p=None): # 自动填充函数
return p if p is not None else k // 2Conv模块结构图

BottleneckCSP/CSP(YOLOv4)
BottleneckCSP(Bottleneck Cross Stage Partial) 是 YOLOv4 引入的模块,用于特征融合,减少梯度信息的冗余。
BottleneckCSP/CSP模块结构特点
-
输入特征图分支:输入特征图首先被分成两部分:一部分通过多个 Bottleneck 结构进行处理,另一部分直接传递。
-
Bottleneck 处理:一部分特征通过多个 Bottleneck 结构进行深层次的特征提取。Bottleneck 是一种轻量化的卷积模块,使用 1x1 卷积降维,3x3 卷积进行特征提取,再通过 1x1 卷积恢复通道数,并通过残差连接来保留输入信息。
-
特征拼接:经过 Bottleneck 处理后的特征图和未处理的特征图在通道维度上进行拼接。
-
通道恢复:拼接后的特征通过 1x1 卷积恢复输出通道数,并最终输出融合后的特征图。
BottleneckCSP/CSP模块实现代码
class BottleneckCSP(nn.Module):
"""
BottleneckCSP 模块:结合 Bottleneck 和 CSP 的模块,用于更高效的特征提取。
通过通道分离和拼接的方式,保留浅层信息并进行深层特征提取。
"""
def __init__(self, c1, c2, n=1, shortcut=True, expansion=0.5):
"""
参数:
- c1: 输入通道数
- c2: 输出通道数
- n: Bottleneck 的重复次数
- shortcut: 是否使用残差连接
- expansion: 通道扩展因子,控制隐藏通道数
"""
super(BottleneckCSP, self).__init__()
hidden_channels = int(c2 * expansion) # 根据 expansion 计算隐藏通道数
# 第一分支,使用 1x1 卷积进行降维
self.conv1 = nn.Conv2d(c1, hidden_channels, 1, 1)
# 第二分支,使用 1x1 卷积直接传递输入特征
self.conv2 = nn.Conv2d(c1, hidden_channels, 1, 1)
# 拼接后的 1x1 卷积,用于恢复通道数
self.conv3 = nn.Conv2d(2 * hidden_channels, c2, 1, 1)
# Batch Normalization
self.bn = nn.BatchNorm2d(2 * hidden_channels) # 批量归一化,用于提高网络的稳定性
# 激活函数 LeakyReLU
self.act = nn.LeakyReLU(0.1, inplace=True) # 激活函数 LeakyReLU
# 定义 Bottleneck 序列,重复 n 次 Bottleneck
self.m = nn.Sequential(*[Bottleneck(hidden_channels, hidden_channels, shortcut) for _ in range(n)])
def forward(self, x):
"""
前向传播函数,将输入特征图分为两部分,一部分通过 Bottleneck 进行处理,
另一部分直接传递,最后将两部分拼接并恢复通道数。
"""
# 第一分支:输入经过 1x1 卷积,并传递给 Bottleneck 序列
y1 = self.conv1(x)
y1 = self.m(y1) # 多个 Bottleneck 进行特征提取
# 第二分支:输入直接通过 1x1 卷积
y2 = self.conv2(x)
# 将两个分支的特征图在通道维度拼接
out = torch.cat((y1, y2), dim=1)
# 拼接后的特征图通过 BatchNorm 和 LeakyReLU 激活
out = self.act(self.bn(out))
# 最终通过 1x1 卷积恢复通道数,输出结果
return self.conv3(out)
BottleneckCSP/CSP模块结构图

C3(YOLOv5)
C3 模块 是 YOLOv5 和 YOLOv8 中引入的一个高效特征提取模块,作为 CSP(Cross Stage Partial) 的改进版,C3 通过引入多个 Bottleneck 层来进一步提升特征的表达能力,同时保持了轻量化的计算量。C3 模块的主要功能是在分支结构的基础上,结合多个 Bottleneck 模块,对特征进行更深层次的提取和融合。它在 YOLO 系列模型的骨干网络和检测头部分起到重要作用。
C3模块结构特点
-
输入特征图分支:输入特征图被分为两部分,一部分通过多个 Bottleneck 层进行深层次特征提取,另一部分直接传递。
-
Bottleneck 处理:一部分特征通过多个 Bottleneck 层提取特征,形成更深层次的特征表示。
-
特征拼接:将两部分特征在通道维度上拼接。
-
通道恢复:拼接后的特征通过 1x1 卷积恢复通道数。
C3模块实现代码
class C3(nn.Module):
"""
C3 模块:结合多个 Bottleneck 和分支结构,用于高效的特征提取和融合。
"""
def __init__(self, c1, c2, n=1, shortcut=True, expansion=0.5):
"""
参数:
- c1: 输入通道数
- c2: 输出通道数
- n: Bottleneck 模块的重复次数
- shortcut: 是否使用残差连接
- expansion: 通道扩展因子
"""
super(C3, self).__init__()
hidden_channels = int(c2 * expansion) # 计算隐藏通道数
# 分支 1:通过多个 Bottleneck 层处理
self.conv1 = nn.Conv2d(c1, hidden_channels, 1, 1)
# 分支 2:直接传递特征
self.conv2 = nn.Conv2d(c1, hidden_channels, 1, 1)
# 最终 1x1 卷积恢复通道数
self.conv3 = nn.Conv2d(2 * hidden_channels, c2, 1)
# Bottleneck 模块
self.m = nn.Sequential(*[Bottleneck(hidden_channels, hidden_channels, shortcut) for _ in range(n)])
def forward(self, x):
"""
前向传播函数,将输入特征图分为两部分,
一部分通过多个 Bottleneck 模块进行处理,另一部分直接传递。
最终通过拼接和 1x1 卷积恢复通道数。
"""
# 第一分支经过 Bottleneck 模块
y1 = self.conv1(x)
y1 = self.m(y1)
# 第二分支直接传递
y2 = self.conv2(x)
# 两分支的特征图在通道维度上进行拼接
return self.conv3(torch.cat((y1, y2), dim=1))
C3模块结构图

Focus(YOLOv5)
Focus 模块 是在 YOLOv5 中引入的一个模块,用于在模型的前几层对输入图像进行处理。Focus 模块通过将输入图像分割为四个子区域并在通道维度上拼接,从而实现降采样和特征提取。相比于直接使用卷积来降采样,Focus 模块更加高效,并且可以保留更多的局部细节信息。
Focus模块结构特点
- 像素分割:Focus 模块将输入特征图的每个像素按位置分割为四个子区域,分别提取四个子像素。
- 通道拼接:通过将这四个子区域在通道维度上拼接,从而实现特征图的扩展。
- 卷积处理:拼接后的特征图通过一个卷积层,提取重要特征并进行降采样。
Focus模块实现代码
class Focus(nn.Module):
"""
Focus 模块:通过将输入图像的像素分割成四个子像素并进行拼接,从而实现高效的降采样和特征提取。
"""
def __init__(self, c1, c2, k=1, s=1, p=None):
"""
参数:
- c1: 输入通道数
- c2: 输出通道数
- k: 卷积核大小 (默认 1x1)
- s: 步长
- p: 填充
"""
super(Focus, self).__init__()
# 使用 1x1 卷积进行通道调整
self.conv = nn.Conv2d(c1 * 4, c2, k, s, autopad(k, p))
def forward(self, x):
"""
前向传播函数,将输入图像分割为四个部分,并在通道维度上拼接。
最终通过卷积进行特征提取。
"""
# 通过 slicing 将输入图像的四个子区域提取出来
return self.conv(torch.cat([x[..., ::2, ::2], # Top-left
x[..., 1::2, ::2], # Top-right
x[..., ::2, 1::2], # Bottom-left
x[..., 1::2, 1::2]], dim=1)) # Bottom-right
def autopad(k, p=None):
# 自动填充函数,计算合适的 padding 大小
return p if p is not None else k // 2
Focus模块结构图 
2024年10月09日更新
CSPDarknet53(YOLOv4)
CSPDarknet53 是在 YOLOv4 中引入的一种骨干网络,它基于原始的 Darknet53 进行了改进,采用了 CSP(Cross Stage Partial) 结构。CSPDarknet53 的设计目标是通过减少计算冗余和增强特征融合来提升模型的精度和计算效率。相比于传统的 Darknet53,CSPDarknet53 通过在每个残差块中引入 CSP 结构,将输入特征图分为两部分,一部分进行残差块的深度处理,另一部分直接传递,最终在通道维度上进行拼接。这种设计使得网络能够更好地保留浅层和深层特征信息,同时降低了模型的计算复杂度。
CSPDarknet53模块结构特点
-
CSP 结构:在每个残差块中引入了 CSP 结构,将输入特征图分为两部分:一部分通过深度卷积处理,另一部分直接传递。这种设计有助于减少计算冗余,并增强特征表达能力。
-
残差结构:和原始的 Darknet53 一样,CSPDarknet53 仍然使用了大量的 Bottleneck 模块,通过残差连接保留输入特征信息,使得网络在深层次时仍能保持信息传递。
-
高效的特征提取:通过 CSP 设计的跨阶段连接,CSPDarknet53 能在保持高效计算的同时,获取到更丰富的特征表示。
CSPDarknet53模块实现代码
class CSPDarknet53(nn.Module):
"""
CSPDarknet53:基于 CSP 的 Darknet53 网络,用于高效的特征提取。
"""
def __init__(self):
super(CSPDarknet53, self).__init__()
self.conv1 = Conv(3, 32, 3, 1)
self.conv2 = Conv(32, 64, 3, 2)
self.csp1 = CSPBlock(64, 64, n=1)
self.conv3 = Conv(64, 128, 3, 2)
self.csp2 = CSPBlock(128, 128, n=2)
self.conv4 = Conv(128, 256, 3, 2)
self.csp3 = CSPBlock(256, 256, n=8)
self.conv5 = Conv(256, 512, 3, 2)
self.csp4 = CSPBlock(512, 512, n=8)
self.conv6 = Conv(512, 1024, 3, 2)
self.csp5 = CSPBlock(1024, 1024, n=4)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.csp1(x)
x = self.conv3(x)
x = self.csp2(x)
x = self.conv4(x)
x = self.csp3(x)
x = self.conv5(x)
x = self.csp4(x)
x = self.conv6(x)
x = self.csp5(x)
return x
CSPDarknet53模块结构图 
ELAN(YOLOv7)
ELAN 模块是 YOLOv7 中用于增强特征融合和表达能力的模块。它通过多层次的卷积路径,将输入特征分为多个部分进行处理,最终通过通道拼接和卷积融合,获得更丰富的特征。
ELAN模块结构特点
-
变种模块:ELAN-H在 ELAN 的基础上引入更深层次的特征处理,如更深的卷积路径或更复杂的残差块。
- 多路径特征提取:通过多个 1x1 和 3x3 的卷积路径,ELAN 可以对输入特征图进行多层次处理。
- 特征融合:将不同路径的特征在通道维度拼接,然后通过 1x1 卷积调整通道数,使得融合后的特征更具表现力。
- 平衡计算量:尽管增加了路径数,但通过 1x1 卷积的降维操作,能够平衡计算量。
ELAN模块实现代码
class ELAN(nn.Module):
def __init__(self, c1, c2, c3=0, n=4, e=1, ids=[-1, -3, -5, -6]):
"""
ELAN 模块:Extended Efficient Layer Aggregation Network,用于增强特征提取能力。
参数:
- c1: 输入通道数
- c2: 输出通道数
- c3: 额外可选通道数(通常未使用)
- n: 3x3 卷积层的数量
- e: 扩展因子,控制中间层通道数(通常为 1)
- ids: 选择拼接特征的索引列表
"""
super(ELAN, self).__init__()
# 将输入通道数减半,用于特征分割
c_ = c1 // 2
self.ids = ids # 用于选择哪些特征进行拼接的索引
# 定义两个 1x1 卷积层,将输入通道数降维
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
# 定义一个包含多个 3x3 卷积层的 ModuleList
# 这些卷积层依次对特征进行处理
self.cv3 = nn.ModuleList(
[Conv(c_ if i == 0 else c_, c_, 3, 1) for i in range(n)]
)
# 最终通过 1x1 卷积融合所有的特征
self.cv4 = Conv(c1 * 2, c2, 1, 1)
def forward(self, x):
"""
前向传播函数。
参数:
- x: 输入张量
返回:
- out: 经过 ELAN 模块处理后的输出特征
"""
# x_1 和 x_2 分别通过两个 1x1 卷积处理
x_1 = self.cv1(x)
x_2 = self.cv2(x)
# 将 x_1 和 x_2 加入到特征列表中
x_all = [x_1, x_2]
# 依次通过多个 3x3 卷积层,并将输出加入到特征列表中
for i in range(len(self.cv3)):
x_2 = self.cv3[i](x_2)
x_all.append(x_2)
# 根据 self.ids 中的索引选择特定的特征进行拼接
# 例如 [-1, -3, -5, -6] 对应的是最新、第三个、第五个和第六个特征
out = self.cv4(torch.cat([x_all[id] for id in self.ids], 1))
return out
ELAN模块结构图
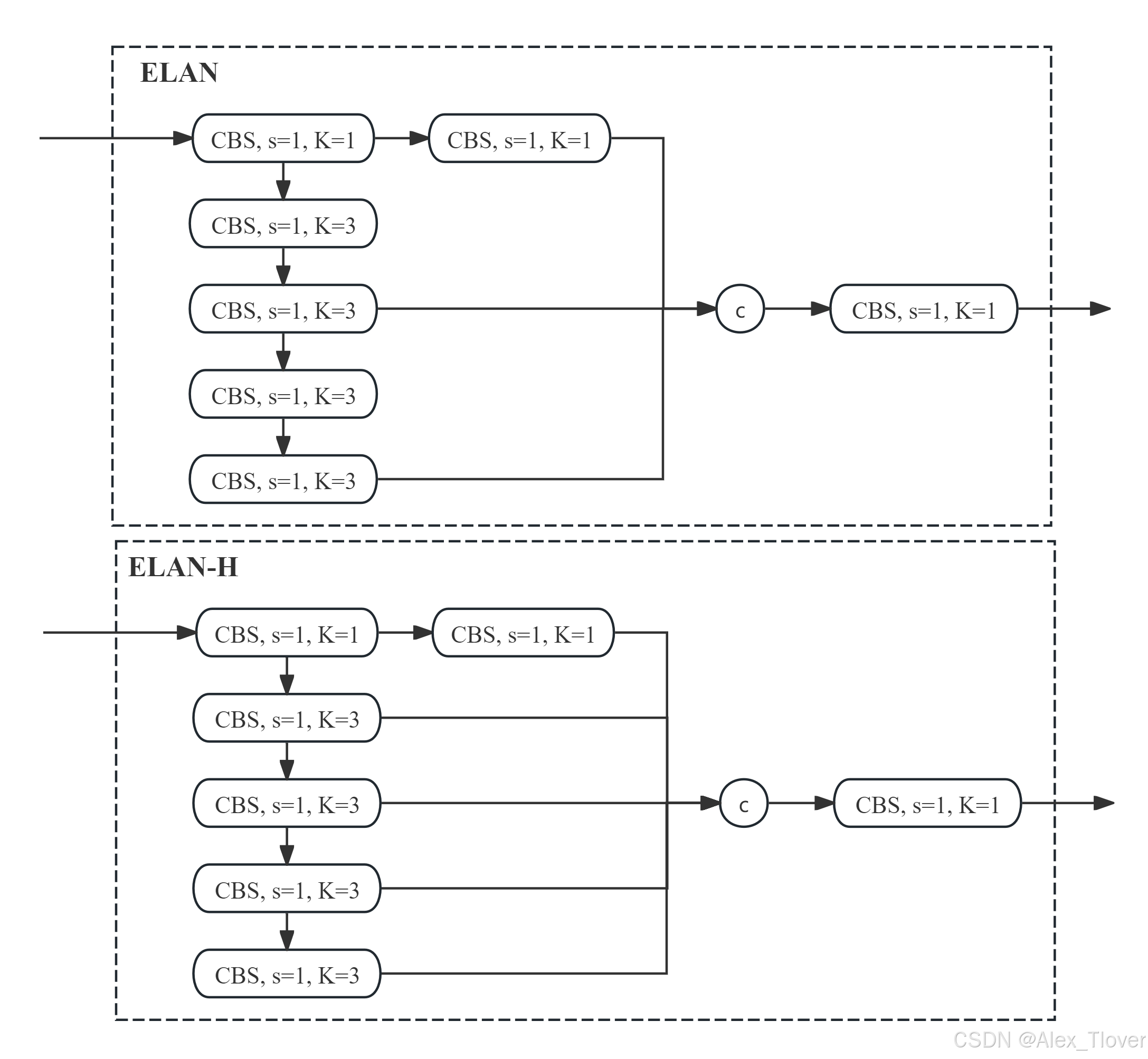
SPPCSPC(YOLOv7)
SPPCSPC (Spatial Pyramid Pooling with Cross Stage Partial Connections) 模块结合了 SPP 和 CSP 的特性,用于增强多尺度特征的表达能力,同时降低计算冗余。
SPPCSPC模块结构特点
-
多尺度上下文信息捕获:通过 SPP 部分的不同尺寸的最大池化操作(5x5、9x9、13x13),SPPCSPC 模块能够在不同的空间尺度上获取特征信息,提升对大小不同的目标的检测能力。
-
CSP 特征融合:SPPCSPC 中的
cv2和cv7使用了 CSP(Cross Stage Partial)结构的思想,保留了部分原始输入特征,并在最后与深度卷积处理后的特征进行融合。这种方式可以减少梯度信息的冗余,提升训练稳定性。 -
计算量平衡:通过
cv1和cv2的 1x1 卷积对输入特征进行压缩,减少了后续 3x3 卷积和池化操作的计算负担。SPP 部分尽管增加了池化操作,但这些操作在同一尺度上并行进行,因此对计算量的增加较为有限。
SPPCSPC模块实现代码
class SPPCSPC(nn.Module):
# CSP https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=(5, 9, 13)):
"""
初始化 SPPCSPC 模块。
参数:
- c1: 输入通道数
- c2: 输出通道数
- n: 重复次数(在此模块中未使用)
- shortcut: 是否使用残差连接(在此模块中未使用)
- g: 组卷积数(在此模块中未使用)
- e: 扩展因子,控制中间层通道数
- k: SPP 使用的池化核大小列表
"""
super(SPPCSPC, self).__init__()
# 计算隐藏通道数,c_ 为两倍 c2 乘以扩展因子 e 的整数部分
c_ = int(2 * c2 * e) # hidden channels
# 定义多个卷积层,用于特征提取和通道调整
self.cv1 = Conv(c1, c_, 1, 1) # 1x1 卷积,用于通道压缩
self.cv2 = Conv(c1, c_, 1, 1) # 1x1 卷积,用于通道压缩(直接通道调整)
self.cv3 = Conv(c_, c_, 3, 1) # 3x3 卷积,提取更多局部特征
self.cv4 = Conv(c_, c_, 1, 1) # 1x1 卷积,进一步调整通道
# SPP 部分,定义多个不同大小的池化层,捕获多尺度上下文信息
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
# 定义后续的卷积层用于特征融合
self.cv5 = Conv(4 * c_, c_, 1, 1) # 1x1 卷积,用于合并 SPP 的特征
self.cv6 = Conv(c_, c_, 3, 1) # 3x3 卷积,提取特征
self.cv7 = Conv(2 * c_, c2, 1, 1) # 最终的 1x1 卷积,调整通道到输出数
def forward(self, x):
"""
前向传播函数。
参数:
- x: 输入张量
返回:
- 输出特征张量
"""
# 特征路径 1:通过多个卷积层处理
x1 = self.cv4(self.cv3(self.cv1(x)))
# 使用 SPP 获取多尺度特征,将 x1 通过多个池化层处理后拼接
spp_features = torch.cat([x1] + [m(x1) for m in self.m], 1)
# 使用 1x1 和 3x3 卷积处理 SPP 特征
y1 = self.cv6(self.cv5(spp_features))
# 特征路径 2:通过 cv2 进行通道调整,保留原始特征信息
y2 = self.cv2(x)
# 最后将两个特征路径拼接,并通过 cv7 调整通道数输出
return self.cv7(torch.cat((y1, y2), dim=1))
SPPCSPC模块结构图
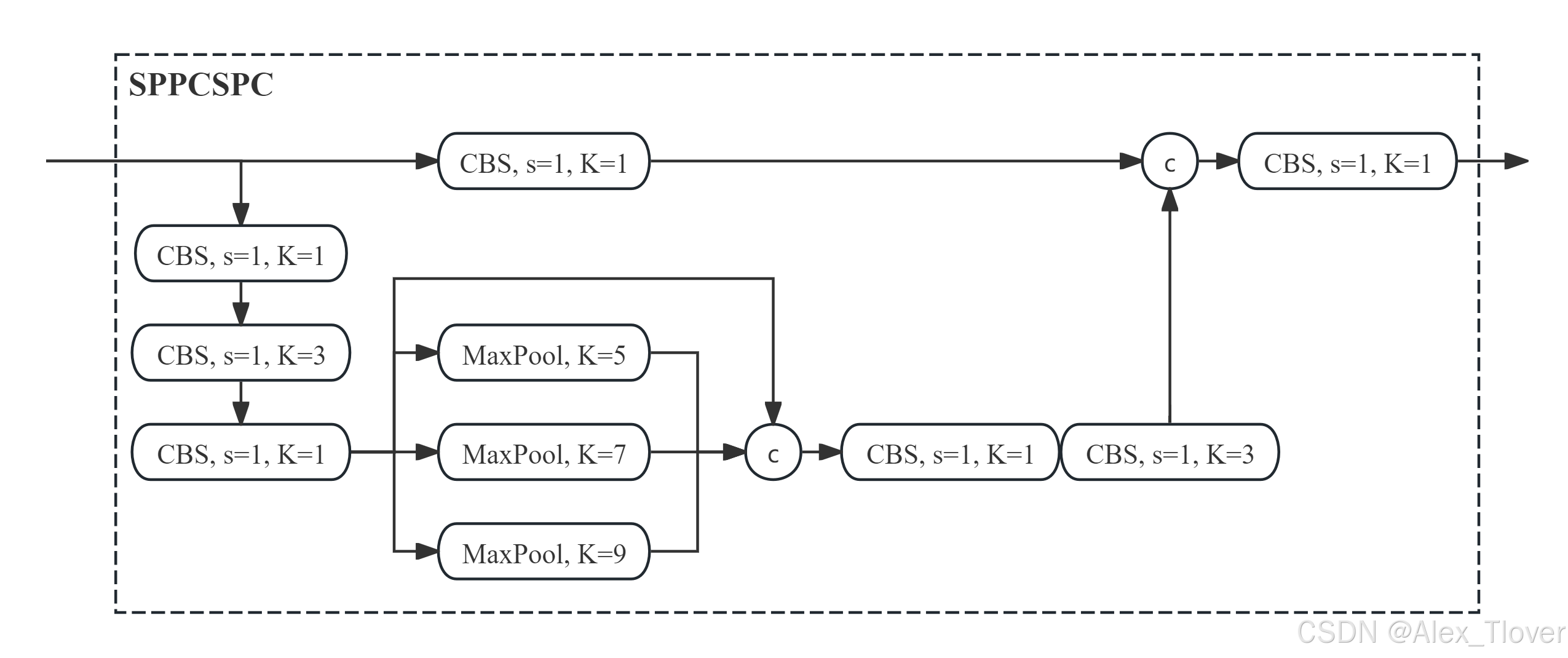
SCDown(YOLOv10)
SCDown (Spatial-Channel Decoupled Downsampling) 模块是 YOLOv10 中的重要组件之一,它通过将空间维度的下采样和通道维度的下采样解耦,从而实现更加有效的特征提取和降维操作。这种方式可以在下采样的过程中保留更多关键信息,减少特征信息丢失,进而提升模型在不同尺度上的检测能力。
SCDown模块结构特点
- 空间下采样:通过一个 3x3 卷积层,采用步长为 2(默认)进行空间维度的下采样,减少输入特征图的宽度和高度。
- 通道下采样:通过 1x1 卷积来降低输入特征图的通道数,同时保持下采样后特征图的空间信息。
- 解耦:SCDown 模块的创新点在于将这两个步骤(空间降维和通道降维)分开进行,避免了传统下采样过程中信息的丢失。
SCDown模块实现代码
class SCDown(nn.Module):
def __init__(self, in_channels, out_channels, stride=2):
"""
初始化 SCDown 模块
参数:
- in_channels: 输入特征图的通道数
- out_channels: 输出特征图的通道数
- stride: 下采样的步长,默认为2
"""
super(SCDown, self).__init__()
# 使用卷积层进行空间下采样
self.spatial_downsample = nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=stride, padding=1)
# 使用1x1卷积层进行通道降维
self.channel_downsample = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
"""
前向传播函数
参数:
- x: 输入特征图
返回:
- 下采样后的特征图
"""
# 空间下采样
x_spatial = self.spatial_downsample(x)
# 通道下采样
x_channel = self.channel_downsample(x_spatial)
return x_channel
SCDown模块结构图
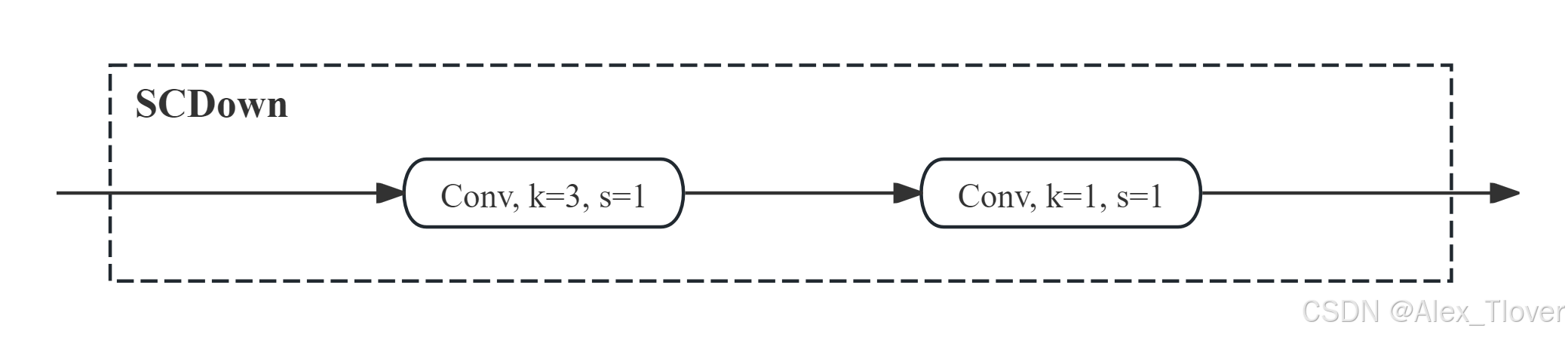
C2fCIB(YOLOv10)
SCDown (Spatial-Channel Decoupled Downsampling) 模块是 YOLOv10 中的重要组件之一,它通过将空间维度的下采样和通道维度的下采样解耦,从而实现更加有效的特征提取和降维操作。这种方式可以在下采样的过程中保留更多关键信息,减少特征信息丢失,进而提升模型在不同尺度上的检测能力。
C2fCIB模块结构特点
-
C2f 模块:首先通过 1x1 卷积将输入特征分为两部分,
y1和y2。对y2进行多层 3x3 卷积操作,提取不同尺度的特征。将y1和y2拼接后,通过 1x1 卷积调整为输出通道数。 -
CIB 模块:通过 1x1 卷积扩展通道数(将通道数放大
expand_ratio倍)。使用深度可分离卷积提取特征,减少计算量的同时保持特征表达能力。最后使用 1x1 卷积将通道数压缩回目标值。 -
C2fCIB 模块:该模块先通过 C2f 模块提取和融合多路径的特征,再通过 CIB 模块对特征进行扩展和压缩,从而提高整体特征的表达能力。
C2fCIB模块实现代码
class C2fCIB(nn.Module):
"""
C2fCIB 模块:结合了 C2f 和 CIB 两种模块的优势,既能通过多路径特征提取聚合特征,
也能通过扩展和压缩通道的方式高效提取特征。
"""
def __init__(self, in_channels, out_channels, num_blocks=4):
"""
初始化 C2fCIB 模块。
参数:
- in_channels: 输入特征图的通道数
- out_channels: 输出特征图的通道数
- num_blocks: C2f 模块中卷积层的数量
"""
super(C2fCIB, self).__init__()
# C2f 模块:负责多路径特征提取和融合
self.c2f = C2f(in_channels, out_channels, num_blocks=num_blocks)
# CIB 模块:负责通过扩展和压缩来提取和优化特征
self.cib = CIB(out_channels, out_channels)
def forward(self, x):
"""
前向传播函数
参数:
- x: 输入的特征图 (batch_size, in_channels, height, width)
返回:
- y: 输出特征图 (batch_size, out_channels, height, width)
"""
# 先通过 C2f 模块提取和融合特征
x = self.c2f(x)
# 再通过 CIB 模块进一步处理
y = self.cib(x)
return y

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









