







目录
前不久我们去了解了YOLO系列模型最新≠最强!(YOLO版本迷信终结!)以及根据实验对模型在那个行业应用最合适做出分析归纳。
今天我要掀开底牌——真正决定YOLO版本胜负的,是藏在神经网络里的三大神秘模块:C3K2、C2F、C3K!
它们就像AI视觉的“芯片架构”,直接操控着检测速度、精度和场景适应力。你以为自己在选模型?其实是它们在暗中支配你的选择!
YOLO(You Only Look Once)技术不断发展,力求在实时物体检测的速度、准确性和效率之间取得平衡。自诞生以来,YOLO在特征提取和架构设计方面进行了多项改进,以提升其在不同计算环境下的检测性能。
YOLO架构的最新进展之一包括专门的特征提取模块,例如 :
-
C3K2
-
C2F
-
C3K
这些定制的特征块提高了YOLO检测不同尺度物体的能力,提高了计算效率,并优化了特征融合——同时在实际应用中保持低延迟推理。
随着YOLO变得更加模块化和适应性,了解其构建模块的工作原理对于将其定制到自动驾驶、机器人、监控和医学成像等不同领域至关重要。
本文对C3K2、C2F和C3K特征提取模块进行了技术解析,探讨了它们的设计原理、差异和性能权衡。读完本文后,您将了解 C3K2、C2F 和 C3K 模块的具体工作原理,以及何时在自定义 YOLO 实现中使用它们。
一、理解 YOLO 的特征提取层
YOLOv3中的extraarknet-53功能可结合更高效的模块化特征提取器来平衡速度和准确性。
-
YOLO为什么使用模块化?
✅多尺度特征提取:有效捕获细粒度细节和高级对象表示。
✅计算效率:模块化设计减少冗余操作,使YOLO 在实时应用中速度更快。
✅优化的主干架构:不同的层专门用于对象检测、特征融合和空间注意。
为了提高效率,YOLO模型集成了跨阶段部分 (CSP) 网络、Transformer层和新颖的特征聚合技术。
-
传统YOLO特征提取器(C3K2、C2F和C3K之前)
在C3K2、C2F和C3K推出之前,YOLO模型依赖于几种著名的特征提取主干,每种主干在速度、深度和效率方面都引入了不同的权衡。
-
Darknet Backbone(YOLOv3及更早版本)
用于YOLOv1、YOLOv2和YOLOv3。受到VGG和 ResNet的启发,但针对速度进行了优化。由依次排列的3x3和1x1卷积层组成。速度快,但对于更深的网络来说效率低。
📌示例—YOLOv3中的Darknet-53
Darknet- 53:- 53个卷积层- 无特征融合技术- 完全卷积架构
优点—简单快捷;缺点—多尺度特征表示有限。
-
CSPDarknet(YOLOv4和YOLOv5)
引入跨阶段部分网络(CSPNet)以减少计算量同时保持准确性。将特征图分成两部分,分别应用变换,然后再合并它们。针对硬件效率进行了优化,在保持高性能的同时减少了 FLOP。
📌示例—YOLOv4中的CSPDarknet-53
CSPDarknet- 53:- 53个卷积层- 跨阶段特征融合-用于物体检测的空间金字塔池化(SPP)
优点—提高效率和准确性;缺点—与原始暗网相比,复杂性更高。
-
具有C3层的缩放YOLOv4
引入了 C3 层,扩展了 CSP 连接以实现更深层的网络。改进梯度流,减少深度架构中的计算开销。成为YOLOv5特征提取器的基础。
📌示例—缩放版YOLOv4中的C3块
C3:- 引入类似 CSPNet 的结构- 提高特征重用效率- 减少内存占用
优点—速度和准确性之间取得更好的平衡;缺点—比CSPDarknet更复杂
-
YOLOv7和YOLOv8引入高级特征聚合层
YOLOv7引入了E-ELAN(高效ELAN),以实现更好的梯度传播和特征重用。YOLOv8集成了基于Transformer的模块,增强了检测的鲁棒性。模型开始使用C2F(跨阶段特征融合)、C3K2和C3K 块。
📌示例—YOLOv7的E-ELAN架构
E-ELAN:- 使用多个并行分支- 增强功能传播- 提高网络效率
优点— 训练效率更高,特征提取更佳;缺点——比以前的 YOLO 版本需要更多内存
二、C3K2块是什么?
-
C3K2区块概述
C3K2 模块是 YOLOv7 和 YOLOv8 中引入的 C3 模块的增强版本。它旨在提高特征提取效率,同时保持较低的计算成本,从而高效地实现实时目标检测。
-
“K2”是什么意思?
C3K2 中的“K2”指的是卷积层核结构的修改。这一变化——增加感受野,提高模型检测小物体的能力。提高特征提取效率,减少冗余计算。改善梯度流,从而实现训练期间更好的收敛。
-
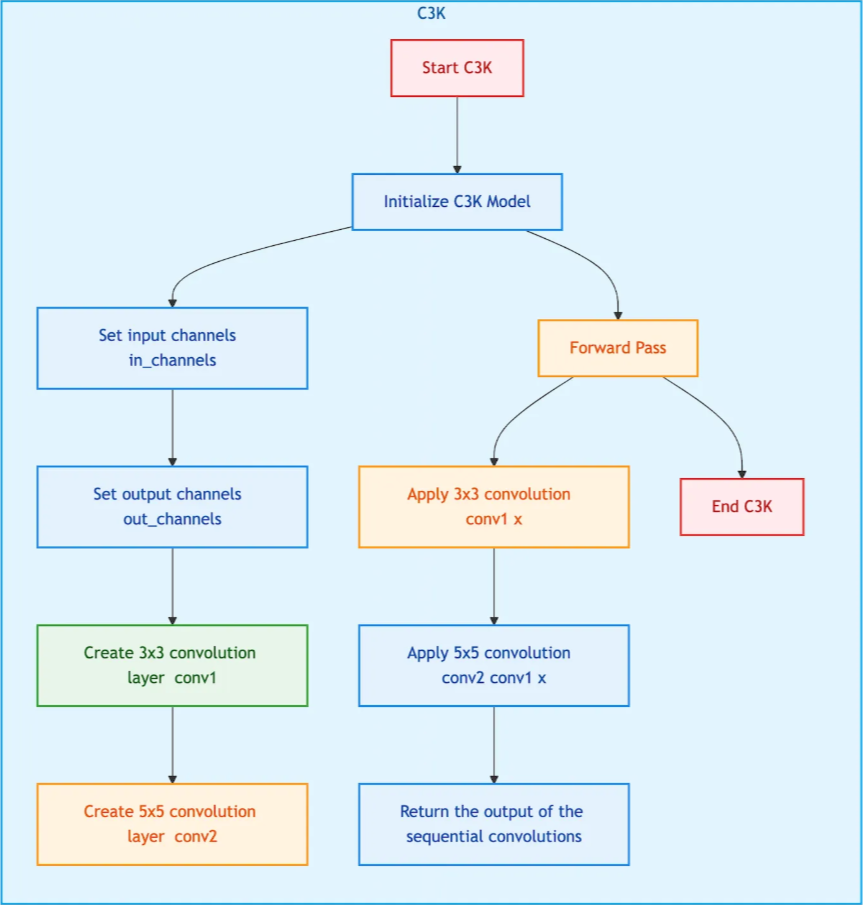
C3K2区块的结构
C3K2 块是基于 CSPNet 的 C3 层的扩展,但在关键架构上进行了改进。
C3K2 区块特点:
✅ 保留多个瓶颈层,类似于 CSPNet,以实现功能重用。
✅ 使用改进的核结构(K2)来扩展感受野,从而改善空间信息捕获。
✅用优化的特征融合层替换标准残差连接,从而实现更好的梯度传播。
-
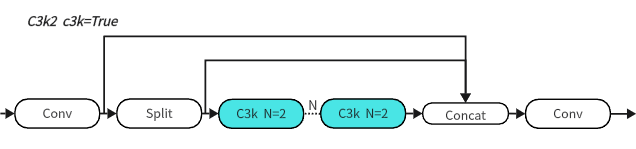
C3K2 区块与标准 C3 区块
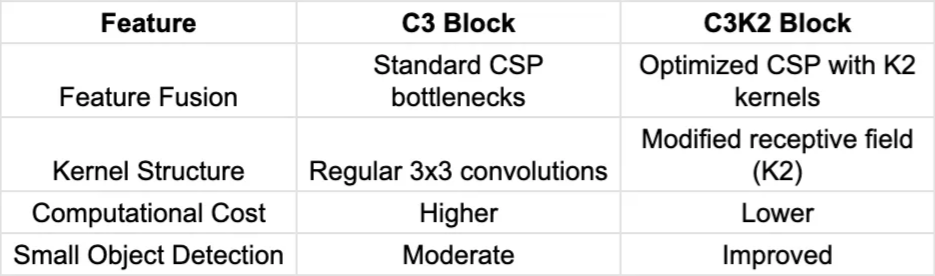
-
在 PyTorch 中实现 C3K2 块
可以使用 PyTorch 通过修改标准 C3 瓶颈内的内核交互来实现 C3K2 块。
import torch
import torch.nn as nn
class C3K2 (nn.Module):
def __init__ ( self, in_channels, out_channels, expansion= 0.5 ):
super (C3K2, self).__init__()
hidden_channels = int (out_channels * expansion)
# 第一个卷积层,采用K2改进的核结构
self.conv1 = nn.Conv2d(in_channels, hidden_channels, kernel_size= 3 , padding= 1 , stride= 1 )
# 第二个卷积层,用于增强特征表示
self.conv2 = nn.Conv2d(hidden_channels, out_channels, kernel_size= 3 , padding= 1 , stride= 1 )
def forward ( self, x ):
x1 = self.conv1(x) # 第一次卷积操作
return self.conv2(x1) # 第二次卷积操作引入了使用优化核结构(K2)的两层特征提取管道。有效捕捉局部和全局特征以改进物体检测。降低计算开销,同时提高检测准确性。
-
C3K2相较于C3的优势
C3K2块比标准C3块有了显著的改进,为YOLO模型提供了更好的效率和准确性。
-
更高效的特征提取
K2修改后的核结构捕获了更多的空间细节,从而实现了更好的特征表示。
-
增强感受野→更好地检测小物体
更宽的感受野使得模型能够检测到否则会丢失的细粒度细节。
-
与标准C3相比,计算成本更低
优化的特征融合机制减少了冗余操作,从而加快了推理时间。
三、什么是C2F区块?
-
C2F概述(具有2F连接的CSP瓶颈)
C2F块(具有2F连接的跨阶段部分)是一种增强的特征提取块,旨在改善梯度流、特征重用和计算效率。
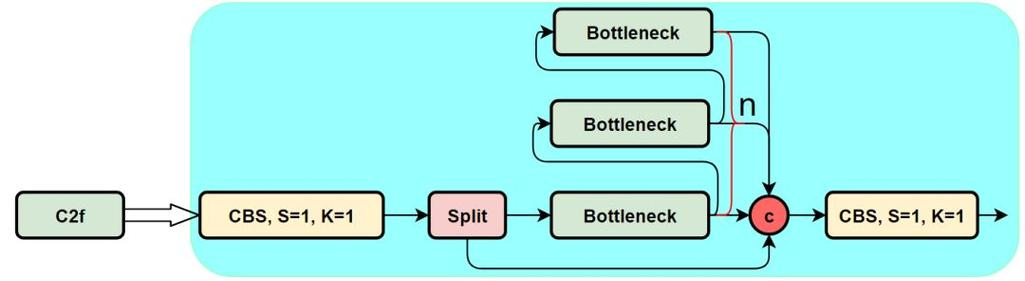
C2F 首次在 YOLOv7 中引入,通过改进特征融合策略来优化轻量级模型。增强局部特征提取,使其更有效地检测小型、遮挡或低光物体。与标准 CSP 块不同,C2F 引入了双融合路径以改进特征传播。
-
C2F的主要功能
-
更好的特征重用:更多样化的路径提高了检测准确性。
-
更强的梯度流:减少深度网络中的梯度消失问题。
-
针对低资源设备进行了优化:高效的内存使用使其适用于移动和边缘 AI 应用程序。
-
C2F区块的工作原理
C2F块是CSPNet的扩展,但修改了特征融合过程以包括两条连接路径(2F 连接)。
使用 CSPNet 的变体,但不是单一的融合路径,而是引入了两个特征融合连接。提高物体检测性能,特别是在弱光、遮挡或密集物体环境中。通过优化卷积层处理空间特征的方式来减少冗余计算。
-
C2F区块vs.之前的CSP区块

-
C2F 块的 PyTorch 实现
C2F 块可以在 PyTorch 中实现如下
import torch
import torch.nn as nn
class C2F (nn.Module):
def __init__ ( self, in_channels, out_channels ):
super (C2F, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size= 1 )
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size= 3 , padding= 1 )
def forward ( self, x ):
return self.conv2(self.conv1(x)) + x # 使用跳跃连接进行特征融合将多个特征提取层组合成一个紧凑、高效的结构。使用残差连接(+x)来改善梯度流,减少梯度消失的机会。支持小物体检测和复杂场景的特征传播。
-
C2F 相较于之前的 CSP 区块的优势
C2F 模块是对早期基于 CSP 的特征提取器的重大改进,它提供
-
改进特征传播 → 减少梯度消失
双重特征融合(2F)确保深层保留关键信息。实现更好的物体检测,特别是在混乱或遮挡的环境中。
-
更强的局部特征提取 → 有助于应对低光和密集物体场景
更有效地检测小物体、低对比度物体或阴影中的物体。与早期的 CSP 实现相比,增强了空间特征表示。
-
高效内存使用 → 适用于边缘设备推理
降低计算开销,使其成为移动和嵌入式设备上的实时 AI 应用的理想选择。在保持准确性的同时减少冗余计算。
四、什么是 C3K 块?
-
C3K简介
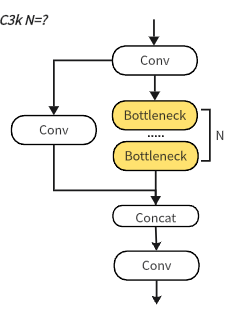
C3K 模块是标准 C3 模块的变体,它引入了优化的核大小,以增强多尺度特征提取。与传统的基于 C3 的架构不同,C3K 旨在:
✅ 改进对不同尺度物体(小、中、大物体)的检测。
✅ 在保持计算效率的同时增强空间特征学习。
✅ 减少推理延迟,使其成为自动驾驶和监控等实时应用的理想选择。
-
为什么内核大小很重要?
-
较小的内核(3×3)可以捕捉细粒度的细节,但缺乏整体视角。
-
较大的核(5×5 或 7×7)可以改善空间环境,但计算成本较高。
-
C3K 通过在同一个块内集成多种内核大小来平衡这种权衡。
-
C3K的主要功能
-
在同一层内集成多种内核大小。
-
在不显著增加计算成本的情况下增强空间特征学习。
-
在改进物体检测的同时保留了标准 C3 层的效率。
-
C3K 与标准 C3 区块
-
C3K 的 PyTorch 实现
C3K 块可以在 PyTorch 中实现如下:
import torch
import torch.nn as nn
class C3K(nn.Module):
def __init__(self, in_channels, out_channels):
super(C3K, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1) # 3x3 内核
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=5, padding=2) # 5x5 内核
def forward(self, x):
return self.conv2(self.conv1(x)) # 顺序应用两个卷积使用 3×3 核进行细粒度特征提取。使用 5×5 内核来获得更大的感受野。保持轻量级结构以避免过多计算。
-
C3K 的优势
C3K模块是YOLO特征提取的一个重要进步,它提供了针对不同尺度的物体进行更好的特征提取,多内核设计可以捕获不同对象大小的细节。提高密集环境中小物体的检测精度。
-
高效卷积运算,实现高速推理
与传统的多尺度方法不同,C3K 平衡了准确性和计算成本。针对边缘设备和嵌入式 AI 系统的实时处理进行了优化。
-
比传统的多尺度特征提取器计算成本更低
使用轻量级内核组合,减少不必要的开销。避免了早期 YOLO 版本中使用的堆叠 CNN 层的成本过高。
五、C3K2、C2F 和 C3K 的比较分析
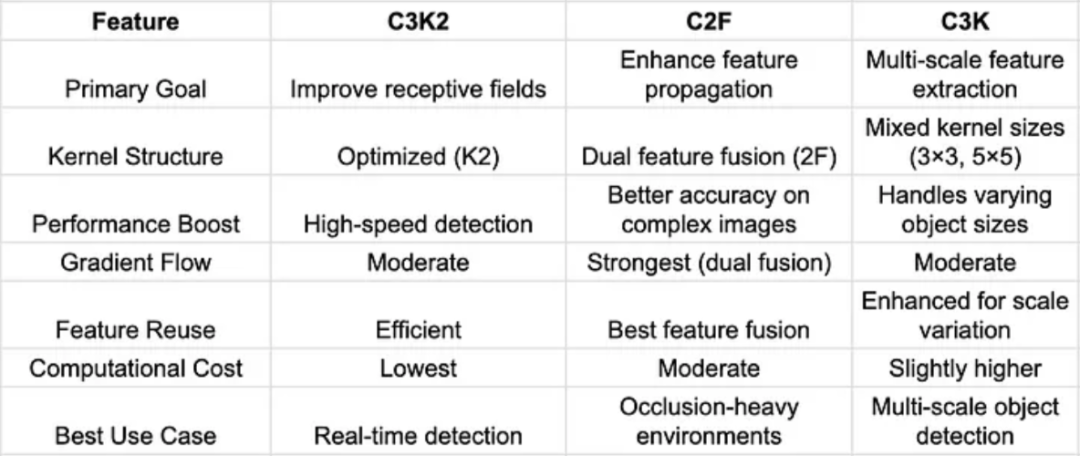
C3K2、C2F 和 C3K 模块在 YOLO 架构中发挥着不同的作用,它们分别针对特定的目标检测挑战优化特征提取。以下是基于功能、内核结构和用例对这三个模块的详细比较。
-
功能比较
-
C3K2—针对高速检测进行了优化
-
主要优势
通过优化的 K2 核结构提高感受野覆盖率。轻量且快速,非常适合实时推理。平衡准确性和速度,减少边缘 AI 应用中的延迟。
-
最佳用例
✔ 自动驾驶(高速处理)。
✔ 无人机和机器人(低功耗实时推理)。
-
C2F—针对遮挡和密集环境进行了优化
-
主要优势
双特征融合(2F)可确保更好的梯度流,防止梯度消失。在存在遮挡和重叠物体的复杂场景中表现出色。更强大的局部特征提取,使其非常适合低光和高对比度环境。
-
最佳用例
✔ 人群监视(处理遮挡)。
✔ 医学成像(细粒度特征检测)。
-
C3K—最适合多尺度物体检测
-
主要优势
集成多种内核大小(3×3、5×5)以实现更好的尺度变化检测。确保高效的空间特征学习,捕捉小物体和大物体。平衡计算成本和改进不同尺寸的物体检测。
-
最佳用例
✔ 航空图像分析(小型和大型物体检测)。
✔ 零售和仓库自动化(多尺度物体识别)。
-
关键要点
✅ C3K2 最适合高速物体检测。
最适合自动驾驶和无人机等实时应用。
✅ C2F 增强了遮挡场景中的检测准确性。
最适合物体重叠的环境,例如监视和医学成像。
✅ C3K 擅长检测不同尺度的物体。
最适合混合尺度物体检测,例如航空图像和工业自动化。
六、Coovally AI模型训练与应用平台
如果你也想要感受模型改进或者模型训练,Coovally平台满足你的要求!
Coovally平台整合了国内外开源社区1000+模型算法和各类公开识别数据集,无论是YOLO系列模型还是Transformer系列视觉模型算法,平台全部包含,均可一键下载助力实验研究与产业应用。
而且在该平台上,无需配置环境、修改配置文件等繁琐操作,一键上传数据集,使用模型进行训练与结果预测,全程高速零代码!
具体操作步骤可参考:YOLO11全解析:从原理到实战,全流程体验下一代目标检测
平台链接:https://www.coovally.com
如果你想要另外的模型算法和数据集,欢迎后台或评论区留言,我们找到后会第一时间与您分享!
七、性能基准测试
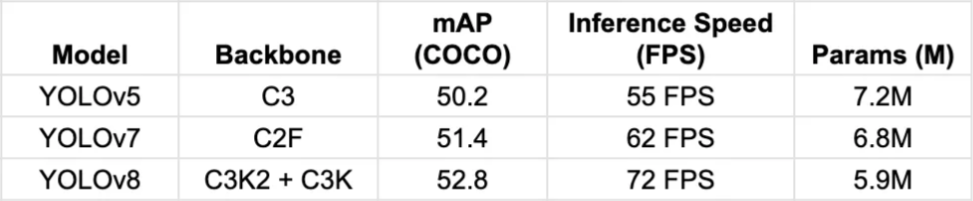
为了了解 C3K2、C2F 和 C3K 如何影响目标检测模型,我们使用 COCO 目标检测基准进行了性能基准测试。评估重点关注平均准确率 (mAP)、推理速度 (FPS) 和模型大小(以百万为单位的参数数量,M)。
-
COCO 基准性能比较
-
关键观察
-
YOLOv8的C3K2 +C3K可提供最高的FPS和极高的准确度。达到72 FPS,成为比较中最快的型号。利用C3K2优化的感受野和C3K的多尺度特征提取,以更少的参数实现更高的准确度。
-
YOLOv7的C2F提高了密集物体场景下的精度。在物体重叠、遮挡或高度密集的复杂物体检测任务中表现更佳。更强的梯度流有助于监视和人群分析等场景。
-
传统的基于C3的模型速度较慢且效率较低。带有C3的 YOLOv5 已经过时,FPS较低且计算成本较高。较大的参数大小(~7.2M)会导致内存消耗增加。
-
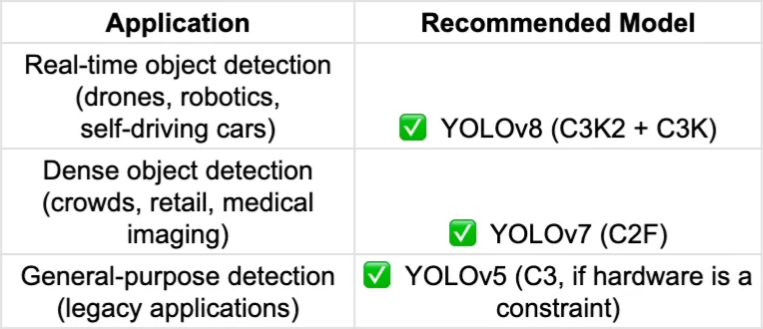
部署要点
八、实际应用
C3K2、C2F和C3K特征提取模块针对特定的实际应用优化 YOLO模型,平衡了速度、准确性和效率。这些模块可提升自主系统、监控和工业自动化领域的物体检测能力。
-
自动驾驶汽车
C3K2 增强实时行人检测,自动驾驶汽车需要超快的推理速度来实时检测行人、骑行者和其他移动物体。C3K2模块非常适合此类应用,因为:
✅ 优化的感受野提高了不同距离的物体检测精度。
✅ 较低的计算开销确保实时响应的高 FPS。
✅ 增强对动态环境中小型、快速移动物体的检测。
-
示例用例—自动驾驶汽车中的行人检测
-
挑战:即使在光线不足和距离不同的情况下,自动驾驶汽车也必须能够检测到行人。
-
解决方案:带有C3K2的YOLOv8可提供更快的推理速度,同时保持检测准确性。
-
结果:提高了行人安全性、更好地跟踪物体并更可靠地避免碰撞。
-
智能监控
C2F 提高了遮挡人脸识别的准确性,安全和监控系统依赖于面部识别和人员追踪,通常用于拥挤或遮挡的环境。C2F 模块非常适合此类应用,因为:
✅ 更强的梯度流改善了部分可见物体的特征传播。
✅ 双特征融合(2F)增强抗遮挡能力。
✅ 在弱光和复杂场景下表现更佳。
-
示例用例—拥挤区域的人脸识别
-
挑战:机场、公共交通和零售场所的摄像头必须能够识别面部,即使被口罩、帽子或障碍物部分遮挡。
-
解决方案:带有 C2F 的 YOLOv7 提高了密集和遮挡环境中的检测准确性。
-
结果:安全性更高、人员重新识别速度更快、误报率更低。
-
工业质量控制
C3K 改进了制造业的缺陷检测,工厂和生产线依靠实时缺陷检测系统来保证产品质量。C3K 模块是此类应用的最佳选择,因为:
✅ 多尺度内核架构确保检测到不同大小的缺陷。
✅ 高效的空间特征提取可提高异常检测能力。
✅ 快速的推理速度允许实时缺陷标记。
-
示例用例 — 电子制造中的缺陷检测
-
挑战:电路板存在小规模缺陷(微观划痕、焊接错误),必须在不减慢生产线速度的情况下检测出来。
-
解决方案:带有 C3K 的 YOLOv8 通过使用混合内核大小捕获细粒度细节来改进缺陷检测。
-
结果:减少生产错误,提高质量保证,加快在线检查。
九、总结
YOLO架构的演进不断增强实时目标检测能力,并在速度、准确率和计算效率之间取得平衡。C3K2、C2F和C3K模块的引入进一步优化了各种应用中的特征提取、多尺度检测和遮挡处理。
随着物体检测的进步,利用C3K2、C2F和C3K等优化的特征提取器已成为构建高效、准确且可扩展的基于YOLO的应用程序的关键。



















 9813
9813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









