






本站文章一览:
在AI应用中,无论是多轮对话场景、RAG场景还是AI Agent场景中,记忆能力都是不可或缺的一部分。然而,记忆能力是目前大模型的短板,所以,现在很多框架,诸如 LangChain、MetaGPT 等,都封装了自己的记忆模块,以方便开发者实现自己大模型应用的记忆功能。
本文我们来系统看下实现大模型应用记忆的方法,包括短期记忆和长期记忆。还是以LangChain为例来进行实战。
0. LangChain中 Memory 实战
我这里将记忆简单理解为对话历史,查询历史等历史记录。
0.1 记忆封装罗列
在 LangChain 中提供了多种获取记忆的封装,例如ConversationBufferMemory、ConversationBufferWindowMemory、ConversationTokenBufferMemory等。
简单罗列如下:
ConversationBufferMemory可以理解为通用的将全部的历史记录取出来。ConversationBufferWindowMemory可以理解为滑动窗口,每次只取最近的K条记录。ConversationTokenBufferMemory可以理解为控制每次取的历史记录的Token数。ConversationSummaryMemory: 对上下文做摘要ConversationSummaryBufferMemory: 保存 Token 数限制内的上下文,对更早的做摘要VectorStoreRetrieverMemory: 将 Memory 存储在向量数据库中,根据用户输入检索回最相关的部分ConversationEntityMemory:保存一些实体信息,例如从输入中找出一个人名,保存这个人的信息。ConversationKGMemory:将历史记录按知识图谱的形式保存和查询
“https://blog.csdn.net/Attitude93/article/details/136024862”)。
下面看下 VectorStoreRetrieverMemory 的使用和实现效果。
0.2 实践:VectorStoreRetrieverMemory的使用
0.2.1 完整代码
from langchain.memory import VectorStoreRetrieverMemory
from langchain_openai import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import ConversationChain
from langchain.prompts import PromptTemplate
vectorstore = Chroma(embedding_function=OpenAIEmbeddings())
retriever = vectorstore.as_retriever(search_kwargs=dict(k=1))
memory = VectorStoreRetrieverMemory(retriever=retriever)
memory.save_context({"input": "我喜欢学习"}, {"output": "你真棒"})
memory.save_context({"input": "我不喜欢玩儿"}, {"output": "你可太棒了"})
PROMPT_TEMPLATE = """以下是人类和 AI 之间的友好对话。AI 话语多且提供了许多来自其上下文的具体细节。如果 AI 不知道问题的答案,它会诚实地说不知道。
以前对话的相关片段:
{history}
(如果不相关,你不需要使用这些信息)
当前对话:
人类:{input}
AI:
"""
prompt = PromptTemplate(input_variables=["history", "input"], template=PROMPT_TEMPLATE)
chat_model = ChatOpenAI()
conversation_with_summary = ConversationChain(
llm=chat_model,
prompt=prompt,
memory=memory,
verbose=True
)
print(conversation_with_summary.predict(input="你好,我叫同学小张,你叫什么"))
print(conversation_with_summary.predict(input="我喜欢干什么?"))
0.2.2 代码解释
(1)代码中我们使用了 VectorStoreRetrieverMemory 作为记忆存储和获取的模块。它既然是向量存储和查询,所以接收参数:retriever=retriever,必须要穿给它一个向量数据库才能工作。
(2)然后使用了 ConversationChain 作为对话的Chain。它接收一个 memory = memory 参数设置,指定使用的记忆类型。默认是最普通的 ConversationBufferMemory 类型。
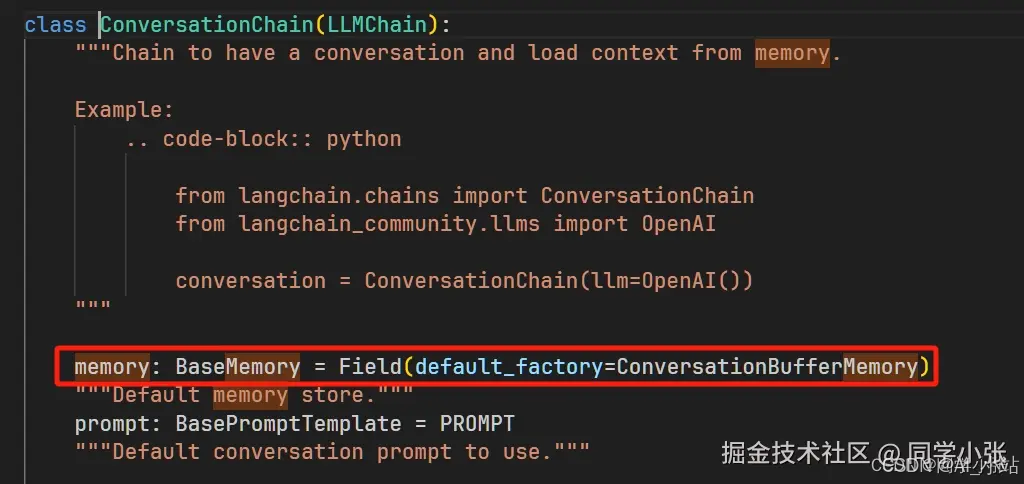
(3)什么时候会去检索记忆呢?在Chain运行 invoke 的一开始,就加载了。源码如下:
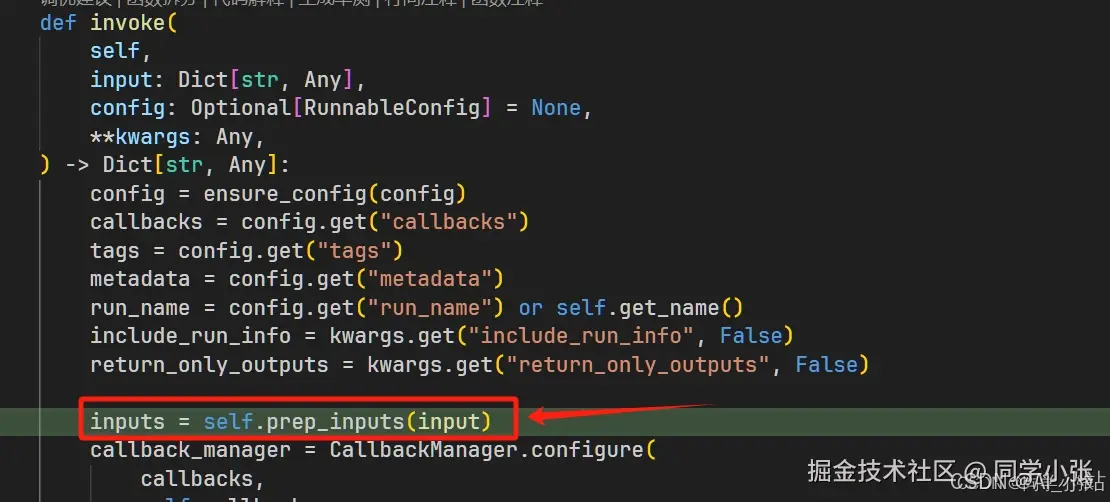
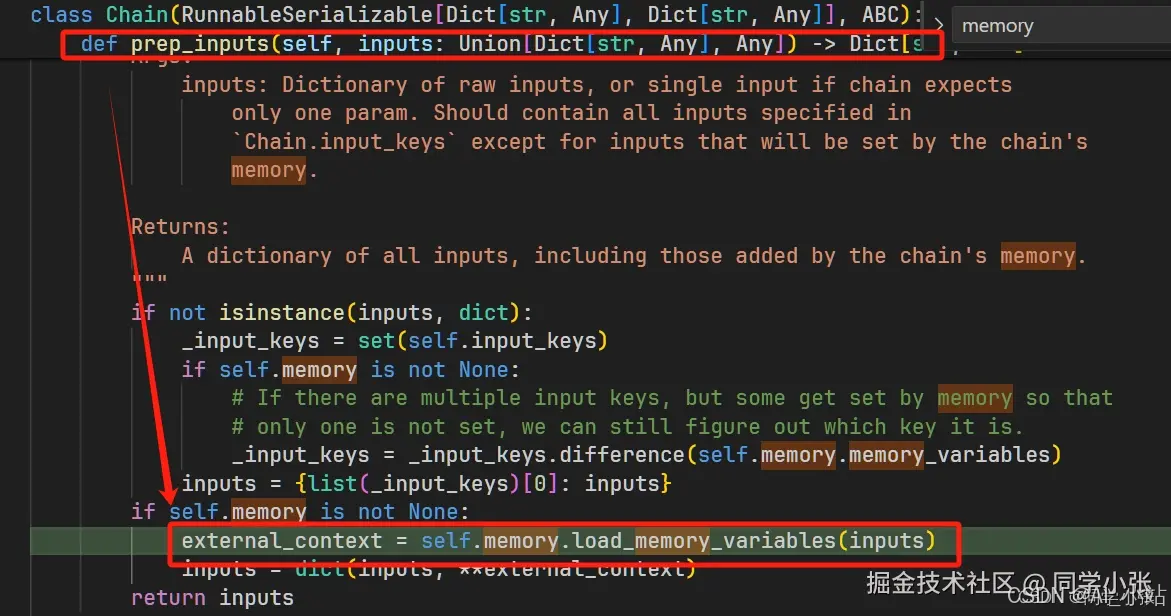
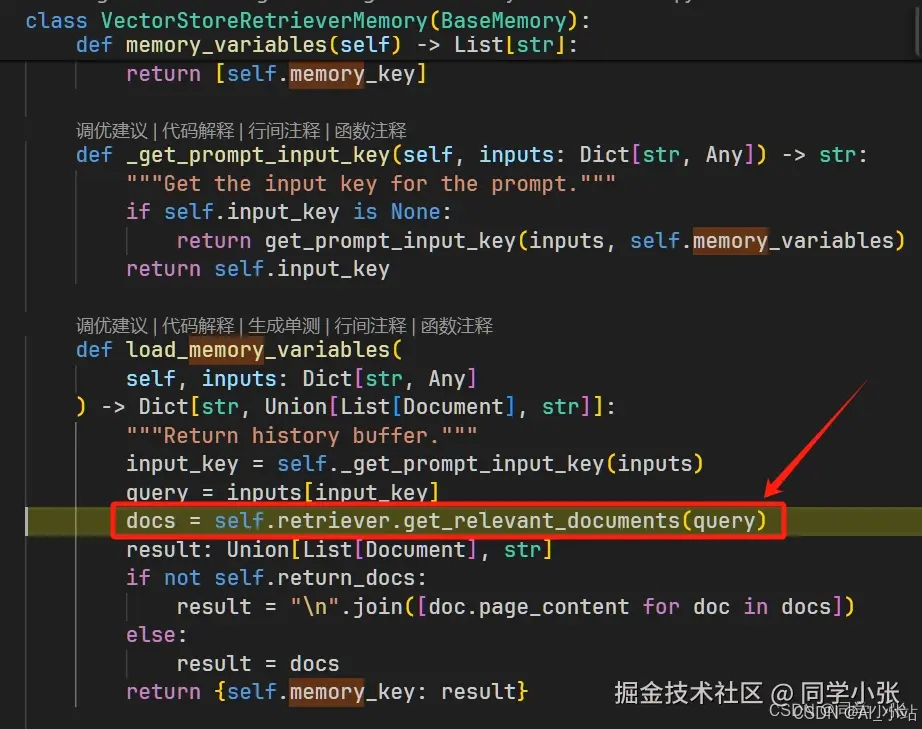
可以看到,最后就是用用户的输入,去向量数据库中检索相关的片段作为需要的记忆。
0.2.3 运行效果展示
第一个问题,检索到的内容不相关,但是也得检索出一条。 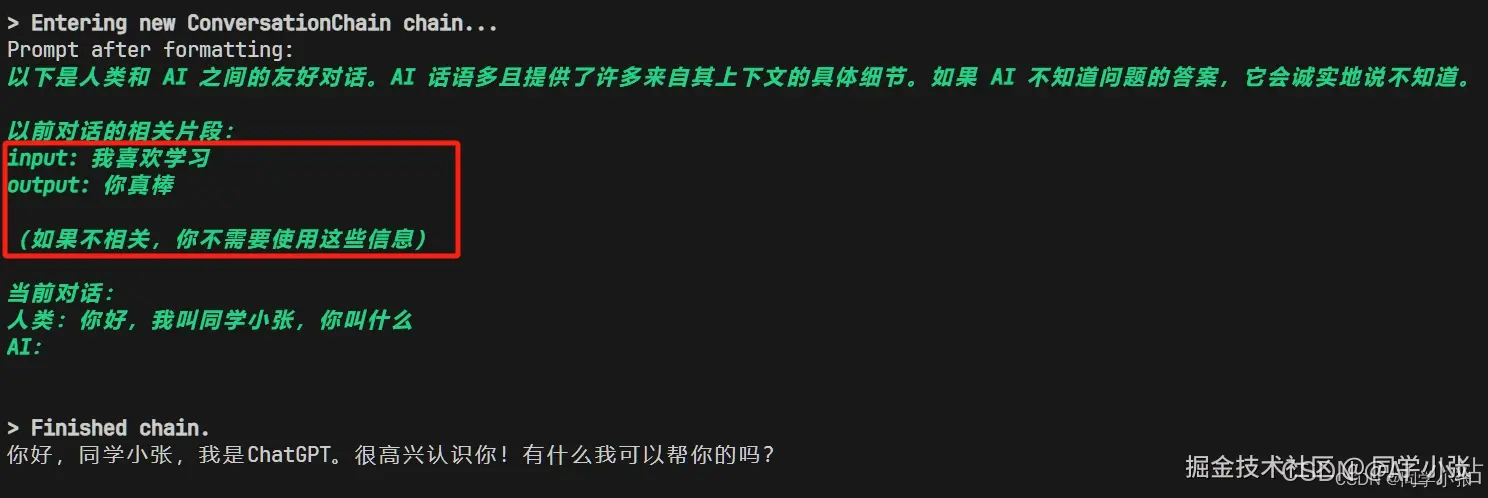
第二个问题,检索到的内容相关,用检索到的内容回答问题。 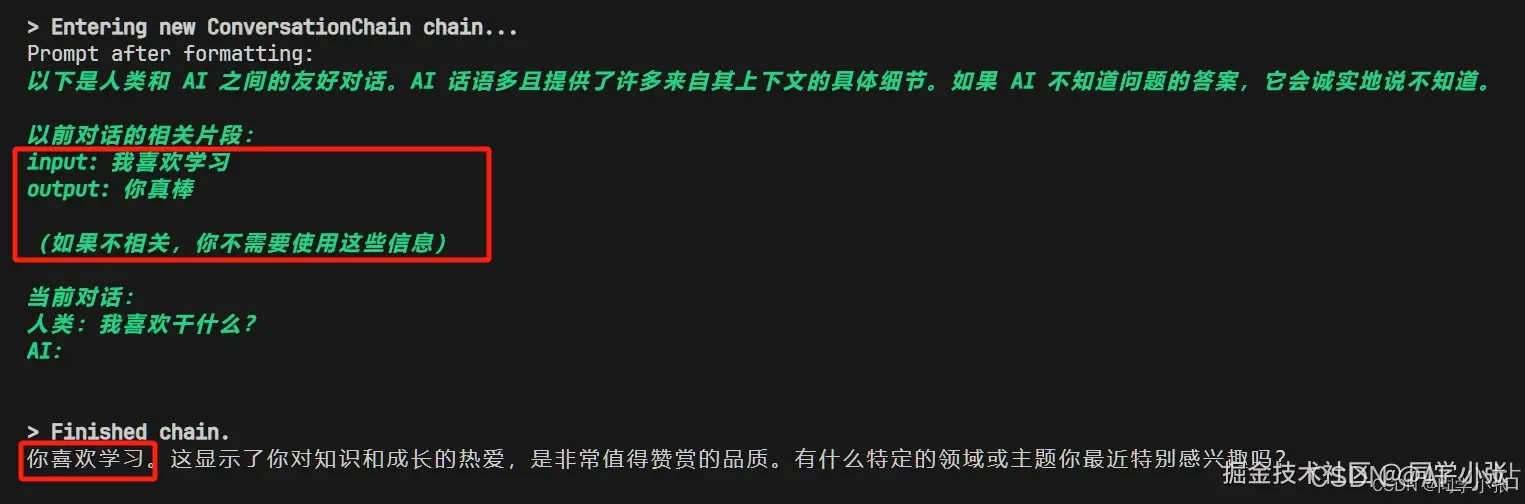
1. 如何让AI应用具备长期记忆?
我这里将“长期记忆”理解为持久化记忆或者长上下文记忆。也就是两种形式的记忆我都认为是“长期记忆”:
- 第一种:持久化记忆,对话历史等历史记录持久化保存,不会随着进程的退出而消失。例如保存成功文件或存储进数据库等。
- 第二种:长上下文记忆,当历史记录特别多时,如何从历史记录中找出有用的记忆,而不是只关注最近的几条历史记录。
1.1 LangChain 中的记忆模块是否具有长期记忆的能力?
上面罗列的和实战的 LangChain 中的记忆模块,ConversationBufferMemory、 ConversationBufferWindowMemory、ConversationTokenBufferMemory 看起来都无法实现长期记忆的能力:无法持久化(看源码,底层都是一个List类型,保存到内存,随着进程消亡而消亡),也没法查询长的上下文。
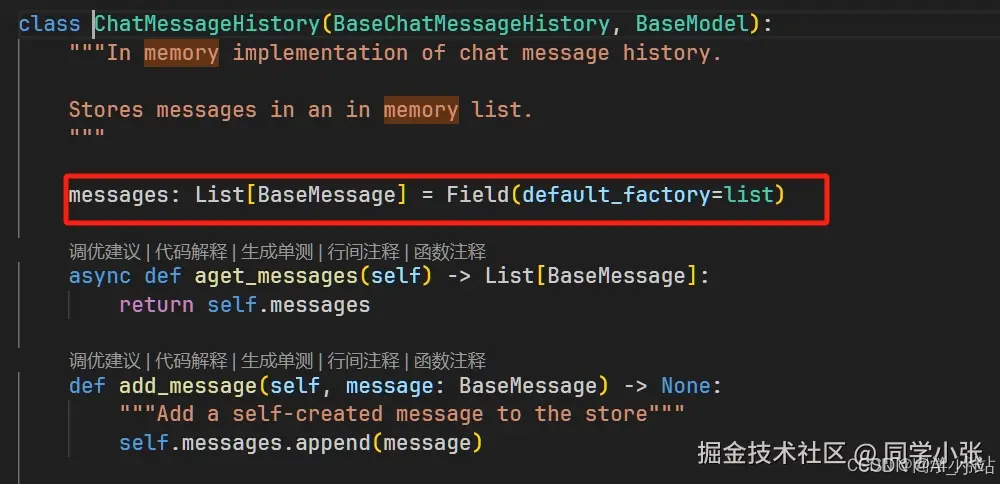
ConversationSummaryMemory、ConversationSummaryBufferMemory 在一定程度上能提供更多的记忆信息(因为其对之前的历史记录做了总结压缩),所以在某些上下文不是特别长的场景中,还是可以用一用来实现简单的长期记忆能力的。
ConversationEntityMemory、ConversationKGMemory一个只保存实体信息,一个将历史记录组织成知识图谱,会对长上下文场景中的长时记忆功能非常有用。它可以从全局的角度将用户提问中的实体或相关知识作补充,而不是关注最近的几次对话。
VectorStoreRetrieverMemory应该是最好和最能实现长期记忆能力的类型了。一方面,它是向量数据库存储,可以方便的持久化数据,另一方面,它的向量检索能力,本来就是针对用户提问检索出最相关的文档片段,不受长上下文的窗口限制。但是其检索的相关片段之间是否存在信息缺失等,会影响长时记忆的准确性,从而影响最终的结果。
所以,
ConversationEntityMemory、ConversationKGMemory+VectorStoreRetrieverMemory是否可以一试?三者结合,保持相关片段的相关性,同时利用实体关系和知识图谱进行补充,是否可以更好地实现长时记忆的能力?感兴趣的可以一起讨论~
1.2 关于让AI应用具备长期记忆的一些研究
1.2.1 记忆思考:回忆和后思考使LLM具有长期记忆
论文原文:Think-in-Memory: Recalling and Post-thinking Enable LLMs with Long-Term Memory
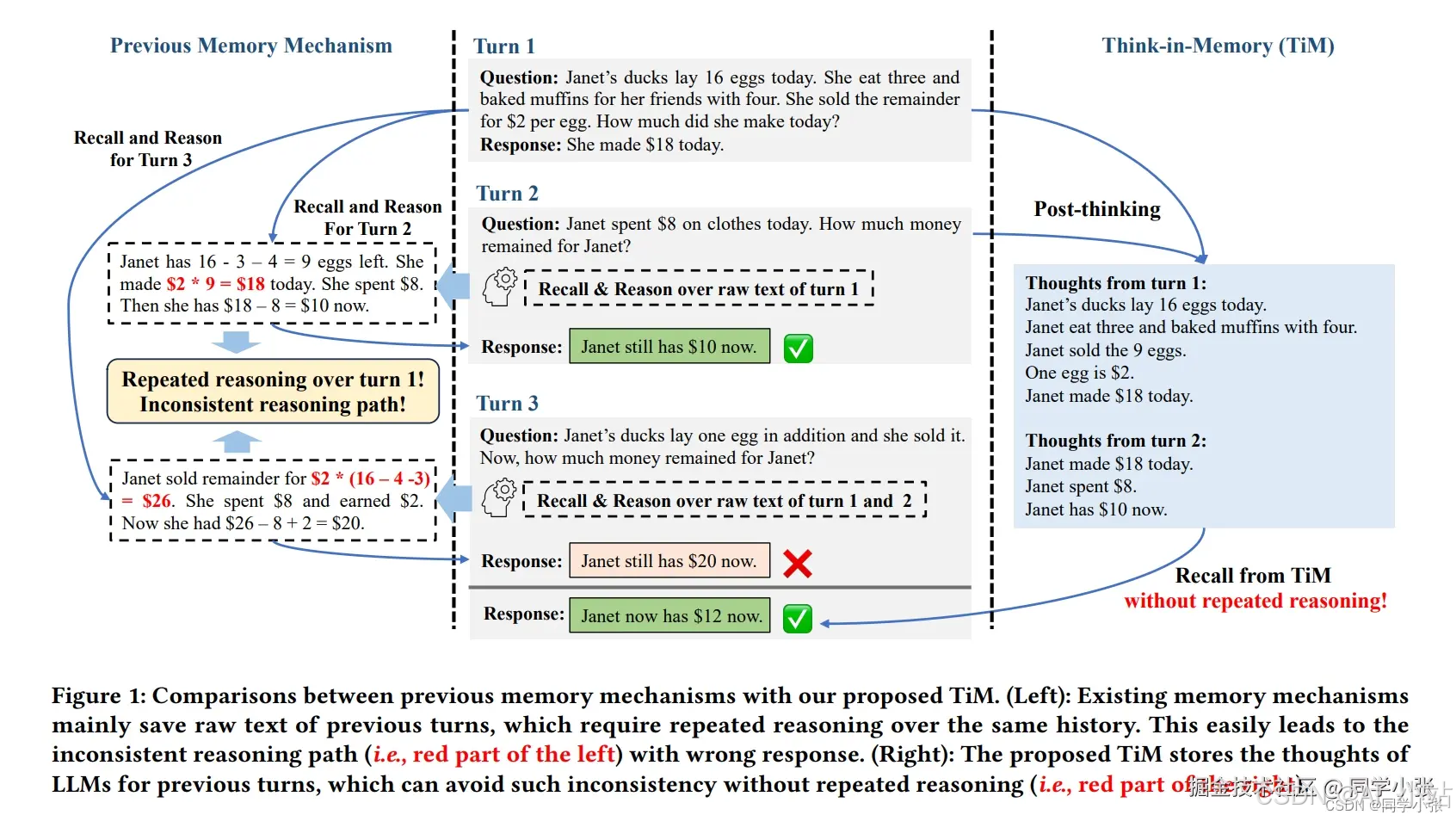
这篇文章提出了一种名为TiM(Think-in-Memory)的记忆机制,旨在使LLM在对话过程中保持记忆,存储历史思考。TiM包括两个关键阶段:在生成回复之前,LLM从记忆中回想相关思考;在生成回复之后,LLM进行后思考并将历史和新思考结合起来更新记忆。
下图描述了TiM方法的使用方式:
(1)在回答第二个问题时,需要考虑问题1的内容,从问题1中推理出答案,而后在回答问题2。 (2)在回答第三个问题时,需要同时考虑问题1和问题2,从问题1和问题2中推理出答案,而后再回答问题3。
这就导致了问题的存在:问题1被推理了两遍,两遍的结果还可能不一样,导致最终的错误。
而TiM的思路,是将每一个问题的思考也存起来,这样,在回答问题3时,可以使用问题2之前的思考,避免重新思考问题1,从而避免多次思考结果不一致导致的错误。
具体步骤如下:
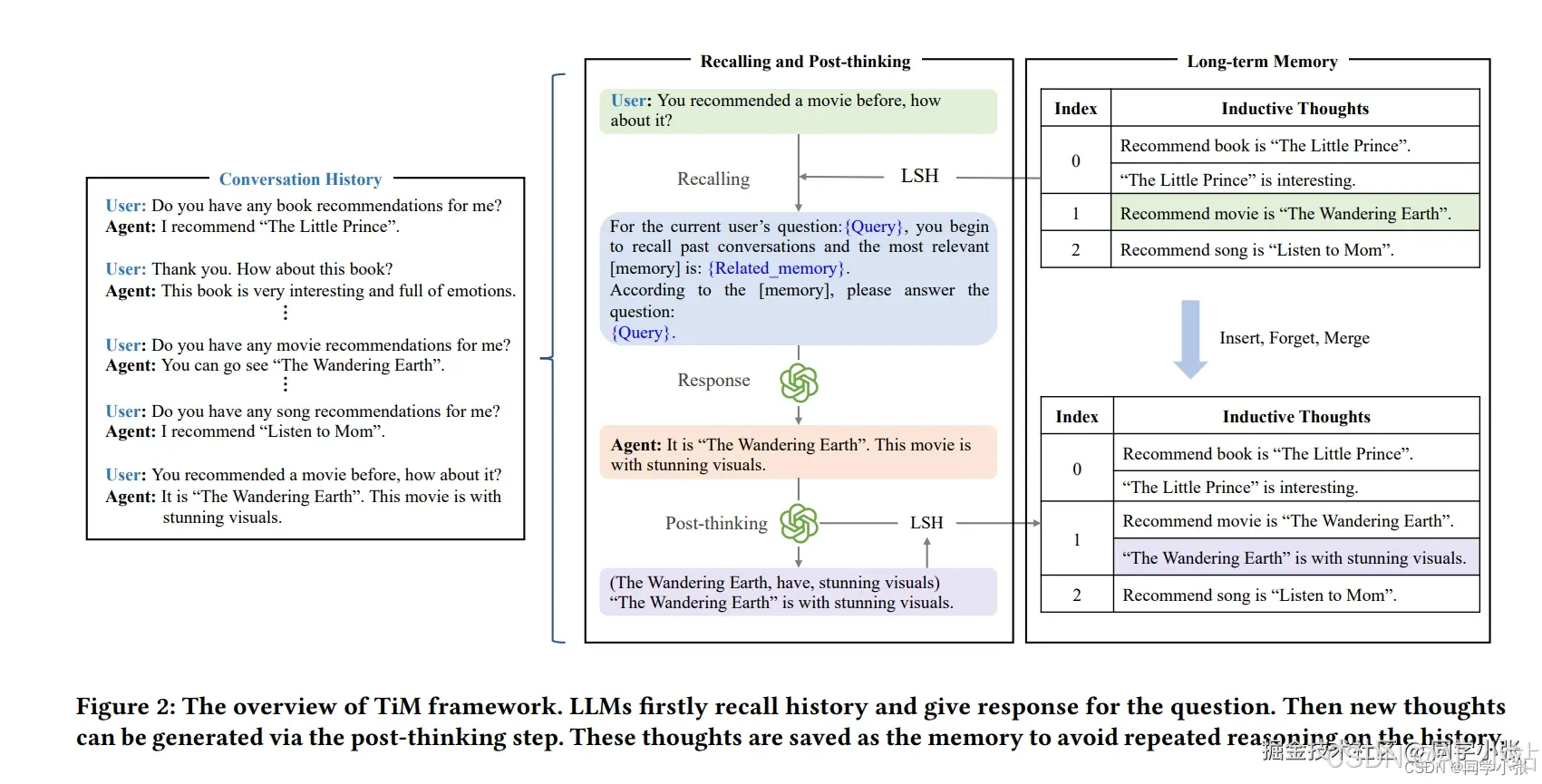
总的原理是,将相关的记忆放到一起,例如上图中,关于book的谈话放到index 0中,关于moive的谈话放到index 1中。
如何将相关内容放到一起的?论文中实现了一种基于局部敏感哈希(LSH)的存储系统,用于高效地存储和检索大规模的向量数据。LSH的作用是将每个向量映射到一个哈希索引,相似的向量有更高的概率被映射到相同的哈希索引。
而相同的哈希索引可以将用户问题固定到某一块记忆中,然后只在这一块记忆中进行向量检索,大大提高了检索效率。
这篇文章还是值得精读一下的,数据的组织方式和索引方式都比较高级,很有启发。
1.2.2 递归总结在大型语言模型中实现长期对话记忆
论文原文:Recursively Summarizing Enables Long-Term Dialogue Memory in Large Language Models
这篇文章提出了一种递归总结的方法,用于增强大模型的长期记忆能力,以解决在长对话中无法回忆过去信息和生成不一致响应的问题。该方法首先刺激LLM记忆小的对话上下文,然后递归地使用先前的记忆和后续的上下文生成新的记忆。
其流程如下: 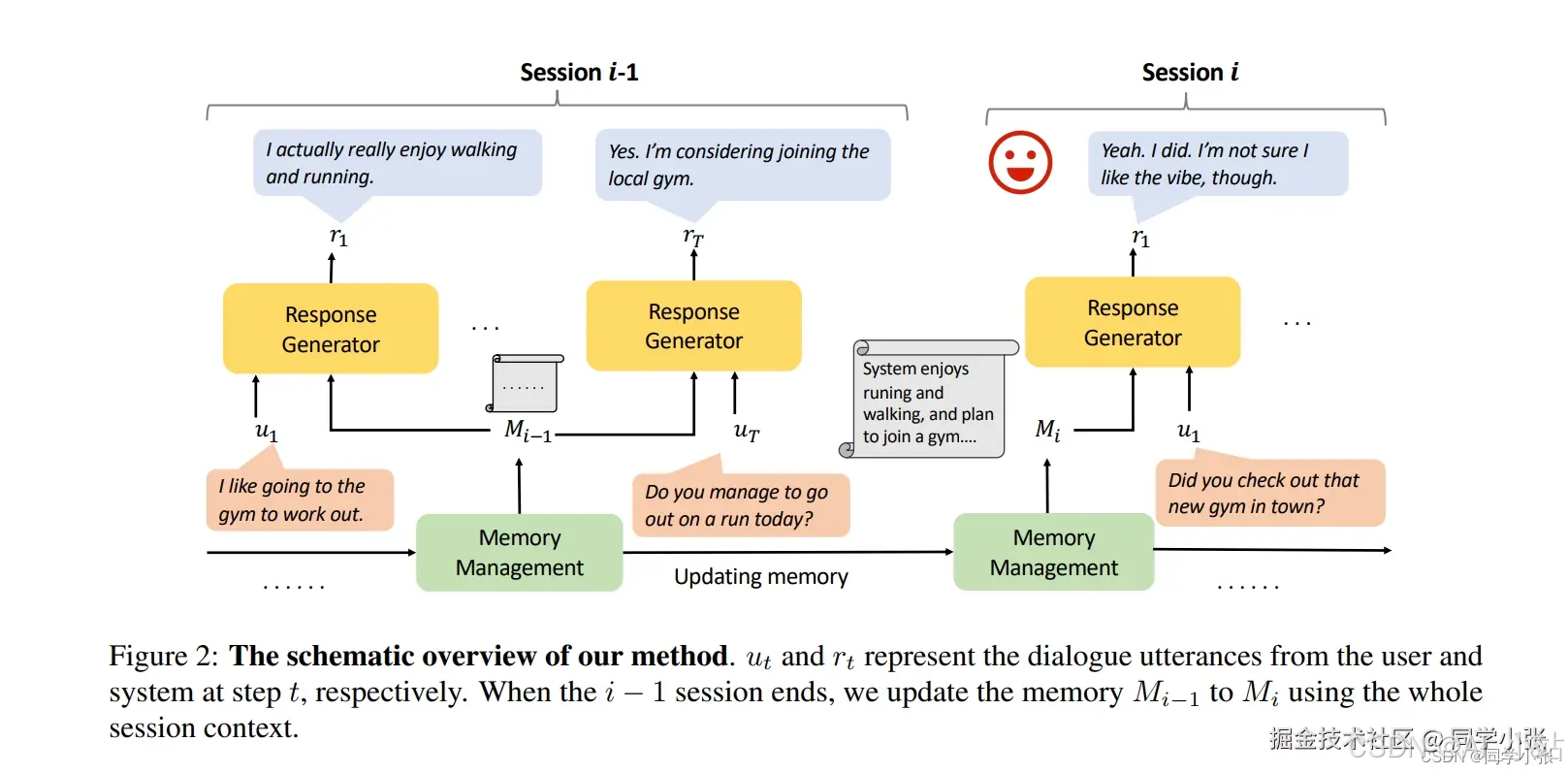
简单概括,就是:上一轮的内容总结 + 本轮的问题回答 = 本轮的内容总结。本轮的内容总结 + 下轮的问题回答 = 下轮的内容总结。… 不断迭代。与 LangChain中ConversationSummaryMemory 的实现很类似。
这种方法每一轮都要总结一次,也就是调用一次大模型,使用成本很高啊… 实际生产中应该落地比较难。
如果你对AI大模型应用感兴趣,这套大模型学习资料一定对你有用。
1.大模型应用学习大纲
AI大模型应用所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。

2.从入门到精通全套视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。

3.技术文档和电子书
整理了行业内PDF书籍、行业报告、文档,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。


朋友们如果有需要全套资料包,可以点下面卡片获取,无偿分享!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









