







在人工智能领域,特别是自然语言处理(NLP)中,大型语言模型(LLMs)的长期记忆能力一直是研究的热点和难点。人类大脑能够在不断变化的环境中存储和更新大量知识,而现有的LLMs在预训练后整合新经验时仍面临挑战。为了解决这一问题,本文介绍了HippoRAG,这是一种受人类长期记忆中的海马体索引理论启发的新颖检索框架,旨在实现更深层次、更高效的知识整合。
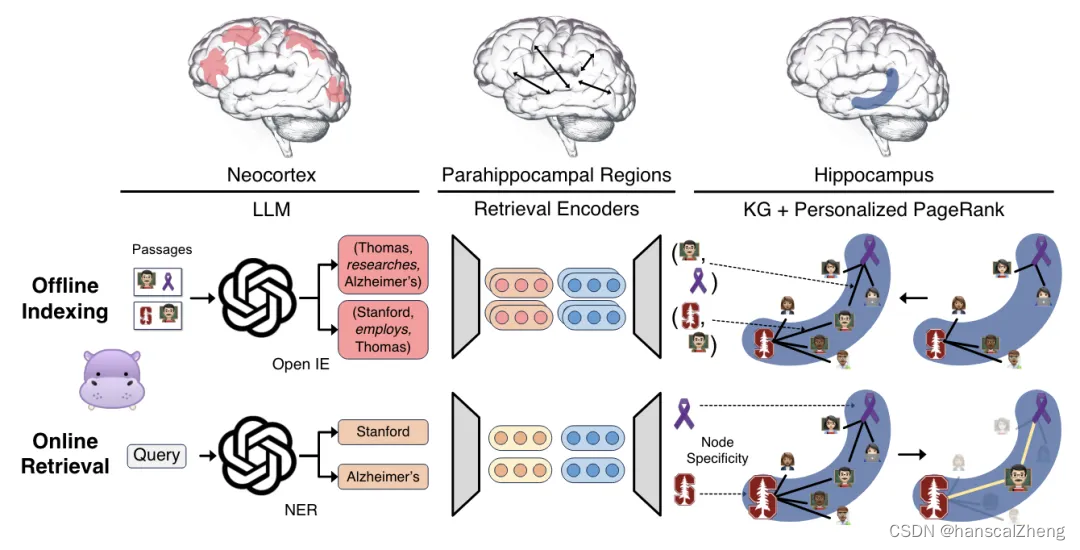
1 海马记忆索引理论
HippoRAG 的设计灵感来自海马记忆索引理论,该理论指出海马体在大脑中负责快速索引和存储新的经验和知识,而新皮层则负责长期存储和稳定化这些信息。该理论认为,人类的长期记忆由模式分离和模式完成两个过程协同工作:模式分离确保不同感知经验的表示是独特的,而模式完成则从部分刺激中检索完整的记忆。
HippoRAG 的核心创新基于海马体记忆索引理论,其具体方法和步骤如下:
- 使用 LLM 进行 OpenIE:从每个篇章中提取名词短语节点和关系边。
- 构建知识图谱(KG):将提取的三元组整合成知识图谱,作为人工海马索引。
- 使用检索编码器:为 KG 中相似但不相同的名词短语添加额外的边,帮助下游模式完成。
- 查询命名实体提取:从查询中提取命名实体,并由检索编码器编码。
- PPR 算法ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1406
1406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









