






一、大模型的痛点
大模型技术席卷全球,为日常工作和生活带来便利,但也面临时效性、准确性等问题。如何提升大模型的性能?解决其挑战?构建高级应用?成为重要待解决问题。

RAG(检索增强生成) 技术通过信息检索和文本生成,显著提升了大模型的性能。但 RAG 也存在局限性,比如:数据依赖、检索效率等。如何解决这些痛点?如何进一步提升 RAG 性能?是本文剖析的重点。
二、RAG 的痛点
Naive RAG 通过检索和生成,提升大模型在问答、智能助手等任务上的性能。但 Naive RAG 难以处理复杂问题或大型文档集,举例如下:

简单问题:“特斯拉的主要风险因素是什么?” 和 “作者在 YC 期间做了什么?” 等问题,Naive RAG 可以给出准确答案。
复杂问题:“总结 XXX 公司年度报告”、“比较开发者 A 和 B 贡献” 或 “分析滴滴公司风险” 等问题,Naive RAG 可能无法提供满意结果。
针对复杂问题,我们需要探索更高级 RAG 解决方案。
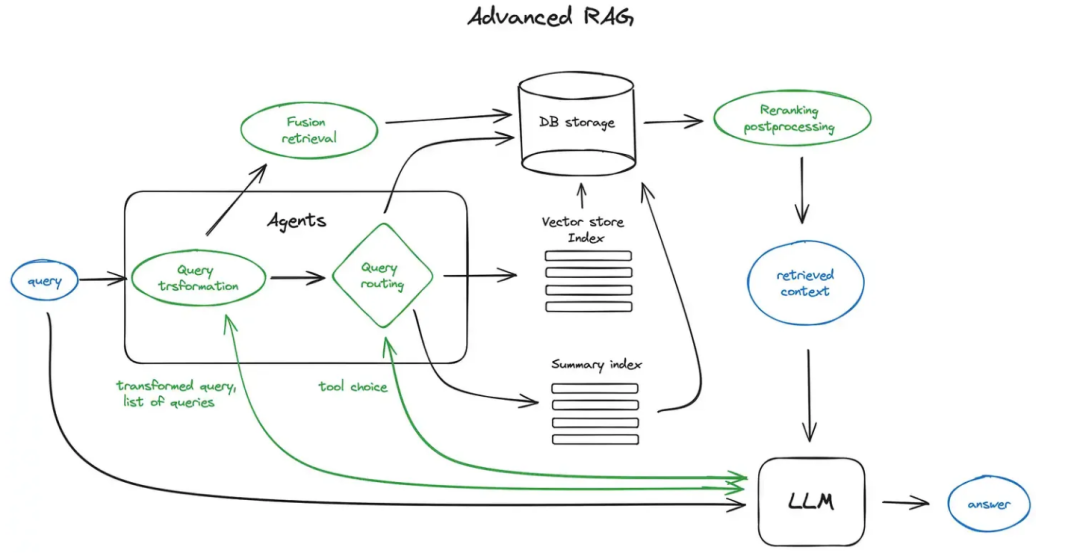
三、From RAG to Agent
Naive RAG(基于检索的增强生成)应用主要是在整合自身知识库的基础上,提升大型模型的性能,以产出更精准、即时和丰富的行业内容或定制化信息。然而,这种应用仍限于内容生成的领域。若要人工智能像一位“目标导向”的高效工作者一样,自主选择多种工具,与不同系统互动合作,直至完成最终任务,那么我们就需要从 RAG 升级至 Agent 模式。
以下是 RAG 向 Agent 转变的描述:
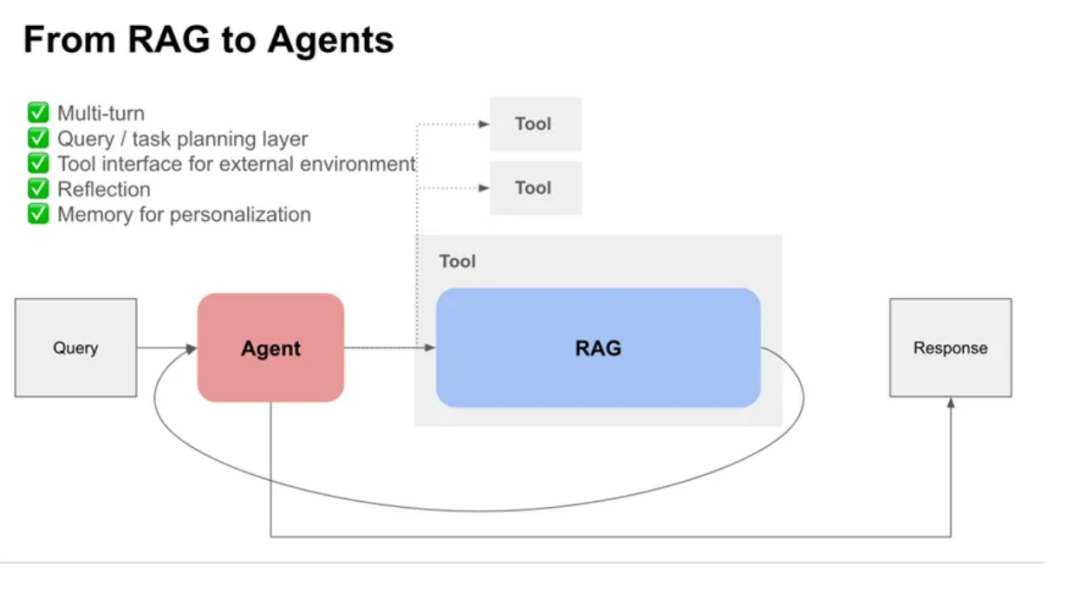
从 RAG 到 Agent 的演进,并非完全摒弃 RAG,而是在其基础上拓展以下几层功能:
-
多轮对话能力:与用户进行更深层次的交流,准确把握用户需求。
-
查询/任务规划层:理解和规划复杂的查询与任务流程。
-
外部工具接口:利用外部工具来完成特定任务。
-
反思机制:对执行结果进行反思、总结和评估。
-
记忆功能:记录用户交互历史,以提供更加个性化的服务。
通过这些功能的增强,Agent 不仅能应对复杂任务,还能在多变的环境中灵活应对。与 RAG 相比,Agent更专注于完成特定任务,并更注重与现有系统的融合。它不仅理解语言,还能在现实世界或数字系统中采取行动。Agent 不仅能执行复杂的多步骤任务,比如;信息检索、数据处理,还能无缝接入各种系统和 API 接口,访问用户数据,与数据库互动。
人类之所以独特,很大程度上是因为我们会使用工具。同样,作为智能体的Agent 也能借助外部工具,处理更为复杂的任务。比如:Agent 能够利用图表生成工具制作在线图表,使用天气查询工具获取天气信息。因此,Agent 是真正释放大模型潜能的关键。
因此,我们的大模型应用也将从 RAG 迈向 Agent,可以说,Agent 是 RAG 发展的必然归宿。
四、案例剖析
最近,阿里巴巴千问团队成功开发了一款新型 Agent(智能体),该智能体整合了 RAG 技术,旨在解析包含数百万字词的文档。尽管它仅利用了 Qwen2 大模型的 8k 上下文窗口,但其性能表现却超越了传统的 RAG 模型和长序列原生模型。
Agent 构建流程如下:
该智能体的构建涉及三个级别,每一级都是基于前一级的构建:
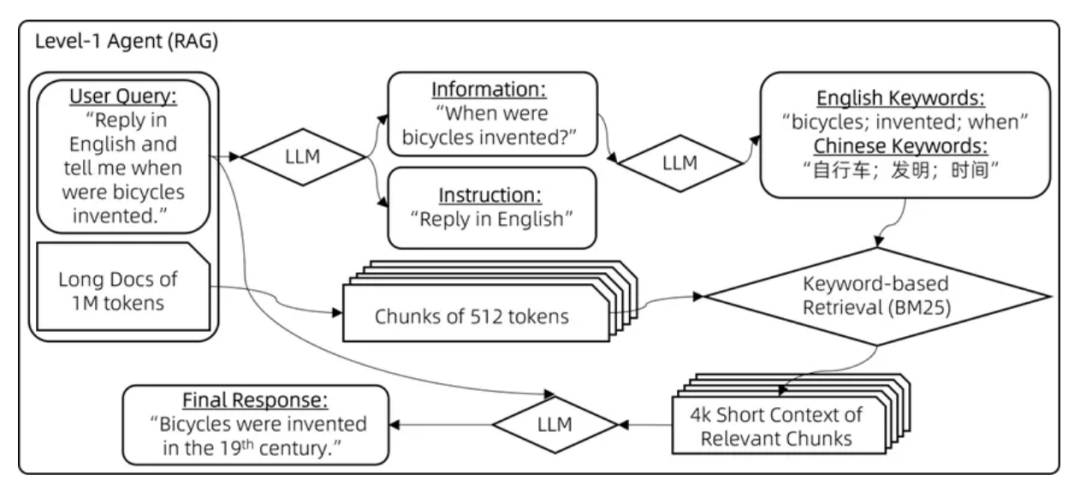
级别一:检索
这一级别关注的是如何识别并提取与关键词最相关的文档片段,主要分为以下三个步骤:
步骤1:区分指令信息与非指令信息
用户输入示例:“请用2000字的篇幅详细说明,我的问题是,自行车是什么时候发明的?请用英文回答。”
信息分解:{“问题内容”: \[“自行车是什么时候发明的”\], “指令要求”: \[“2000字详细说明”, “用英文回答”\]}。
步骤2:多语言关键词推导
输入问题:“自行车是什么时候发明的”
信息转换:{“英文关键词”: \[“bicycles”, “invention”, “timing”\], “中文关键词”: \[“自行车”, “发明”, “时间”\]}。
步骤3:应用 BM25 关键词检索算法
通过 BM25 算法,对关键词进行高效的检索,以定位相关文档片段。
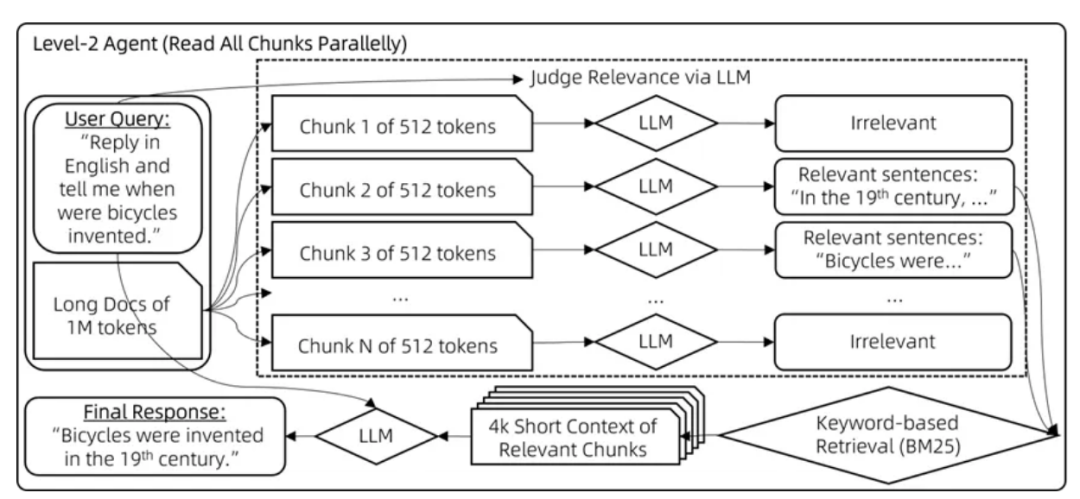
级别二:分块阅读
当相关文档片段与用户查询关键词的重叠度不足,可能导致这些片段在检索过程中被忽略,未能传递给大模型。为了解决这个问题,我们采用了以下策略:
步骤1:相关性评估
使用聊天模型对每个512字节的文档片段进行评估,判断其与用户查询的相关性。如果模型判断为不相关,则输出“无”;若判断为相关,则输出相关的句子。
步骤2:基于相关句子的检索
从步骤1中提取出的相关句子,将它们作为搜索查询词,利用BM25算法检索出与用户查询最相关的文档块。
步骤3:生成答案
根据检索到的上下文信息,生成最终的答案。
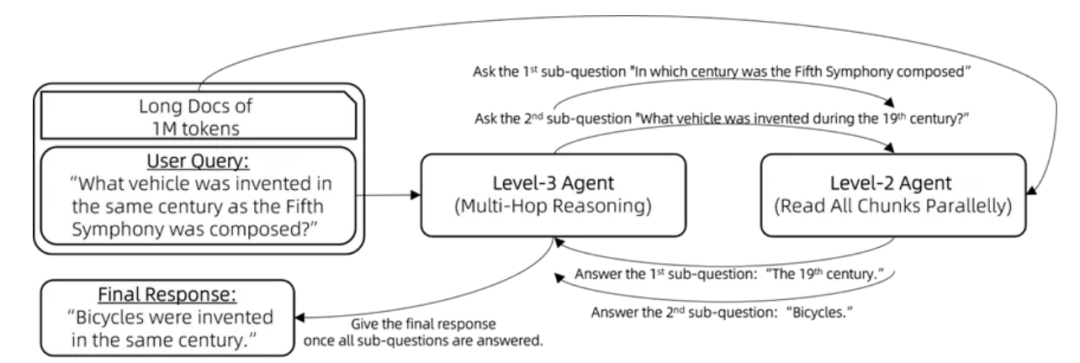
级别三:递进推理
面对多跳推理问题,比如:用户提问:“与贝多芬的第五交响曲创作于同一世纪的交通工具是什么?”大模型需要将问题分解为多个子问题来逐一解答:“贝多芬的第五交响曲是在哪个世纪创作的?”以及“自行车是在哪个世纪发明的?”
这一挑战可以通过以下步骤,利用工具调用(又称函数调用)智能体或 ReAct智能体来解决:
1. 向三级智能体(Lv3-Agent)提出原始问题。
2. 当三级智能体无法根据其现有记忆回答问题时,执行以下步骤:
a. 三级智能体生成一个新的子问题。
b. 三级智能体将这个子问题提交给二级智能体(Lv2-Agent)。
c. 将二级智能体的回答整合到三级智能体的记忆库中。
3. 重复上述过程,直到三级智能体能够回答原始问题。
4. 最终,三级智能体提供原始问题的解答。
如何学习大模型?
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

5. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方CSDN官方认证二维码,免费领取【
保证100%免费】


















 9623
9623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









