







前言:以下是对大模型常见术语的扫盲解释,帮助快速理解核心概念。
1. 基础概念
-
大模型(Large Language Model, LLM)
基于海量数据训练的、参数规模巨大的深度学习模型(如千亿级参数),能够理解和生成自然语言文本。
例子:GPT-4、PaLM、LLAMA。 -
Transformer
一种深度学习架构,通过“自注意力机制”(Self-Attention)处理序列数据(如文本),成为大模型的核心技术基础。
特点:并行计算能力强,适合处理长文本。 -
参数(Parameters)
模型内部的可调节数值,决定模型如何从输入数据中提取特征并生成输出。参数规模越大,模型复杂度通常越高。
例子:GPT-3有1750亿参数。 -
Token
语言模型中最小的独立单位,即文本处理的最小单元,可以是单词、子词或字符。大模型将输入文本拆分为Token进行理解和生成。
例子:英文中“unhappy”可能被拆分为“un”和“happy”两个Token。 -
RAG(Retrieval Augmented Generation):检索增强生成,结合信息检索与语言模型生成技术,提升生成文本的准确性和相关性。
-
上下文窗口(Context window):语言模型在生成新文本时可以回溯并参考的文本量。
-
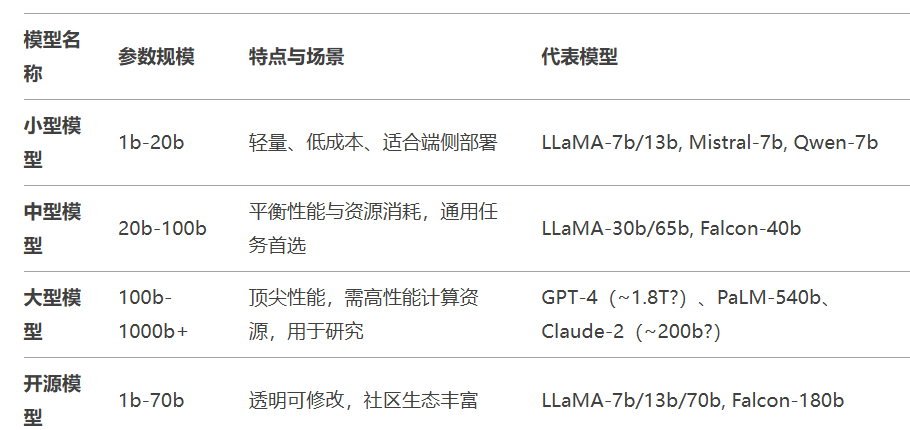
大模型几b: 通常指的是模型参数的数量,这里的“B”是英文单词“Billion”的首字母缩写,表示“十亿”。例如: 1B 模型意味着该模型拥有大约10亿个参数。10B 模型则代表这个模型有大约100亿个参数。模型的参数量对其性能有着重要影响。一般来说,参数越多,模型能够学习到的数据特征就越复杂,理论上可以提供更精确、更丰富的输出。然而,这并不意味着参数越多越好,因为更多的参数也会带来更高的计算成本和资源消耗,并且可能引起过拟合的问题,即模型对训练数据中的细节和噪声过度适应,从而影响其在新数据上的表现。
2. 训练与优化
-
预训练(Pre-training)
在大规模无标注数据上训练模型,学习通用的语言规律(如语法、语义)。
常用任务:掩码语言建模(BERT)、自回归预测(GPT)。 -
微调(Fine-tuning)
在预训练模型基础上,用特定领域的小规模数据进一步训练,使其适应具体任务(如客服、医疗)。 -
SFT (Supervised Fine-Tuning):监督微调,通过使用标注好的数据集对模型进行进一步训练,使其在特定任务上表现更好。
-
LORA(Low-Rank Adaptation):一种微调大型预训练语言模型的技术,通过低秩分解来降低更新所需的参数数量。
-
QLORA(Quantized Low-Rank Adaptation):结合低秩适应与量化技术,减少微调的计算开销同时保持性能。
-
注意力机制(Attention Mechanism)
模型根据输入的不同部分分配权重,决定哪些信息更重要。
核心公式:Q(Query)、K(Key)、V(Value)矩阵运算。 -
缩放定律(Scaling Laws)
模型性能随参数规模、数据量和计算资源的增加而提升的规律。
3. 关键技术
-
Prompt Engineering(提示工程)
通过设计输入提示(Prompt)引导模型生成预期输出。例如:“请用一句话总结下文:___”。 -
Few-shot / Zero-shot Learning
-
Zero-shot:模型无需额外示例,直接根据任务描述生成结果。
-
Few-shot:提供少量示例(如3-5个)指导模型完成任务。
-
-
模型蒸馏(Knowledge Distillation)
将大模型的知识“压缩”到小模型中,降低计算资源需求。 -
RLHF(Reinforcement Learning from Human Feedback)
通过人类反馈优化模型输出,使其更符合人类价值观。ChatGPT的核心技术之一。
4. 应用与挑战
-
幻觉(Hallucination)
模型生成与事实不符或逻辑错误的内容,是大模型的核心缺陷之一。 -
多模态(Multimodal)
模型能处理多种类型数据(文本、图像、音频等)。例如:GPT-4V支持图文交互。 -
伦理与安全
-
对齐(Alignment):确保模型目标与人类价值观一致。
-
偏见(Bias):训练数据中的偏见可能导致模型输出歧视性内容。
-
5. 常见模型架构
-
GPT(Generative Pre-trained Transformer)
OpenAI开发的自回归模型,通过预测下一个Token生成文本。 -
BERT(Bidirectional Encoder Representations)
谷歌提出的双向编码器,擅长理解上下文语义。 -
MoE(Mixture of Experts)
将模型拆分为多个“专家”网络,根据输入动态选择激活部分参数,提升效率。
6. 延伸概念
-
Embedding
将文本映射为高维向量,用于表示语义相似性。 -
Temperature
控制生成文本的随机性:值越高输出越多样,值越低输出越保守。 -
Beam Search
一种解码策略,通过保留多个候选序列生成更优结果。 -
Temperature:控制模型生成预测时随机性的参数,影响输出的创造性和确定性。
-
Latency:模型从接收提示到生成响应所需的时间。
-
TTFT(Time to First Token):模型在接收提示后生成首个Token所需的时间,评估实时系统中模型响应速度的重要指标。
参考链接:


















 231
231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











