







本文首发于微信公众号 CVHub,严禁私自转载或售卖到其他平台,违者必究。

Title: MixFormerV2: Efficient Fully Transformer Tracking
Paper: https://arxiv.org/pdf/2305.15896.pdf
Code: https://github.com/MCG-NJU/MixFormerV2
导读
本文主要介绍了一种基于Transformer的目标跟踪框架。传统的三阶段模型范式,即特征提取、信息交互和位置估计。这些方法大都采用了更统一的单流模型结构来同时进行特征提取和交互,这对于建模视觉目标跟踪任务非常有效。然而,一些现代的跟踪架构过于庞大和计算昂贵,难以在实际应用中部署。
为了解决这个问题,作者提出了一种名为MixFormerV2的完全Transformer跟踪框架,该框架不需要密集卷积运算和复杂的分数预测模块。该框架的设计关键是引入四个特殊的预测标记,并将它们与目标模板和搜索区域的标记连接起来。随后,作者在这些混合标记序列上应用统一的Transformer主干网络。这些预测标记能够通过混合注意力捕捉目标模板和搜索区域之间的复杂相关性。
基于这些预测标记,通过简单的多层感知器头部,便能够轻松地预测跟踪框并估计其置信度分数。此外,为了进一步提高模型效率,本文提出了一种基于蒸馏的模型压缩方法,包括以下两种方式:
- 密集到稀疏的蒸馏
- 深度到浅层的蒸馏
最后,本文根据不同的应用场景设计了不同的缩放架构,并在LaSOT数据集上分别达到了 70.6% AUC 和实时 CPU 速度下超过 FEAR-L 2.7% AUC的结果。
动机
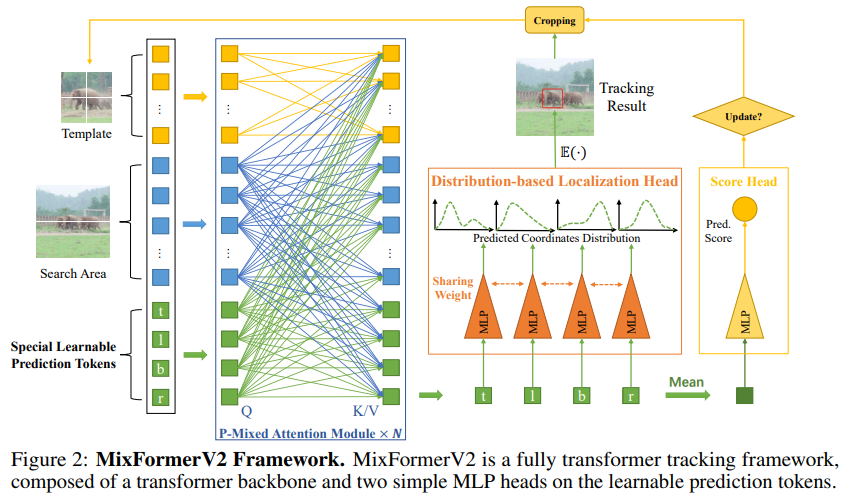
上图展示了MixFormerV2,可以看出,这是一个完全的Transformer跟踪框架,没有任何卷积操作和复杂的评分预测模块。它的骨干是一个简单的Transformer,作用于混合的令牌序列,包括目标模板令牌、搜索区域令牌和可学习的预测令牌。然后,网络使用最简单的 MLP 头部用于预测边界框坐标的概率分布和相应的目标质量得分。
与其他基于Transformer的跟踪器如MixFormer和SimTrack等相比,本文方法首次有效地删除了定制的卷积分类和回归头部,使跟踪流程更加统一、高效和灵活。只需通过输入模板令牌、搜索区域令牌和可学习的预测令牌,模型便能以端到端的方式预测目标边界框和质量得分。
Prediction-Token-Involved Mixed Attention
与MixViT中的原始的混合注意力相比,本文所设计的混合注意力模块关键区别在于引入了特殊的可学习预测令牌,用于捕捉目标模板和搜索区域之间的相关性。这些预测令牌可以逐步压缩目标信息,并用作后续回归和分类的紧凑表示。具体而言,给定多个模板、搜索和四个可学习的预测令牌的拼接令牌,我们将它们传入 N 层预测令牌参与的混合注意力模块(如图中的P-MAM所示):

与原始的 MixFormer 类似,本文使用非对称混合注意方案进行高效的在线推理。与标准 ViT 中的 CLS 令牌一样,可学习预测令牌会自动在跟踪数据集上学习以压缩模板和搜索信息。
Direct Prediction Based on Tokens
在经过骨干网络提取完embedding之后,让我们一起看下如何直接使用预测令牌来回归目标位置并估计其可靠得分。
具体而言,本文首先利用基于四个特殊可学习预测令牌的分布回归。需要注意的是,此处回归的是四个边界框坐标的概率分布,而不是它们的绝对位置。其次,由于预测令牌可以通过预测令牌参与的混合注意力模块来压缩与目标相关的信息,我们可以使用相同的 MLP 头来简单地预测四个边界框坐标:
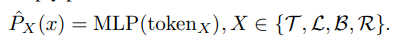
在具体实现中,这四个预测令牌之间共享 MLP 权重。对于预测的目标质量评估,本文对输出的预测令牌取平均,并使用 MLP 头来估计目标的置信度得分。这些基于令牌的头部大大降低了边界框估计和质量评分估计的复杂性,从而实现了更简单和统一的跟踪架构。(具体可以参考上述框架图配套理解下~~~)
下面简单讲讲上面提到的两种蒸馏方法。

Dense-to-Sparse Distillation
在MixFormerV2中,我们直接基于预测令牌回归目标边界框到四个随机变量的分布,分别表示边界框的上、左、下和右坐标。具体而言,首先预测每个坐标的概率密度函数。最终的边界框坐标可以通过对回归概率分布的期望值得出。由于原始的MixViT使用密集的卷积角点头部来预测二维概率图,即用于左上角和右下角的联合分布,通过边缘分布便可以轻松推导出边界框坐标的一维分布。
因此,这种建模方法可以有效弥补密集角点预测和本文的稀疏基于令牌的预测之间的差距,即原始MixViT的回归输出可以视为对密集到稀疏的蒸馏的软标签。具体而言,作者应用了 KL 散度损失来监督。通过这种方式,定位信息从 MixViT 的密集角点头部传递到 MixFormerV2 的稀疏基于令牌的头部。
Deep-to-Shallow Distillation
为了进一步提高效率,本文尝试修剪Transformer的骨干网络。然而,设计一个新的轻量级骨干网络并不适合快速的单流跟踪。因为单流跟踪器的新骨干通常高度依赖大规模预训练以获得良好的性能,而这需要大量的计算资源。因此,作者采用特征模仿和 logits 蒸馏的方式直接剪裁 MixFormerV2 骨干网络的一些层。
由于直接删除一些层可能导致不一致和不连续性,因此论文基于特征和 logits 蒸馏探索了一种渐进的模型深度剪裁方法。这个策略是为了在剪裁过程中保持学生模型与教师模型的一致性,并提供平滑的过渡方案。在开始时,学生模型完全复制了教师模型的结构和权重。然后,通过逐步消除学生模型的某些层,剩余的层被训练成模仿教师模型的表示。这样做的好处是在剪裁过程中保持了学生和教师之间的一致性,减少了特征模仿的难度。
具体而言,通过引入一个衰减率 γ \gamma γ,对被剪裁层的权重进行衰减。在训练的前几个时期,衰减率从1逐渐减小到0,使用余弦函数来实现渐进的剪裁过程。这样,被剪裁的层将逐渐减少其对输出的影响,并最终变为恒等变换,从而实现深度的剪裁。通过这种渐进的模型深度剪裁策略,可以在减少模型复杂度的同时保持较好的性能,提高模型的运行效率。
Intermediate Teacher
上面我们通过这种教师-学生的蒸馏方式虽然在一定程度上完成了模型压缩工作,但引入中间教师模型对于极浅模型(例如4层 MixFormerV2)的蒸馏有一定影响。通常情况下,对于一个小型学生模型来说,教师模型的知识可能过于复杂难以学习。因此,本文这这里还特别引入一个中间角色作为助教,以缓解极端知识蒸馏的困难。在这种情况下,我们可以将教师和小型学生之间的知识蒸馏问题分解为几个子问题。
具体而言,中间教师模型的层数介于深度教师模型(12层MixFormerV2)和浅层学生模型之间(4层MixFormerV2)。中间教师模型的作用是将知识蒸馏问题分解成多个子问题,让小型学生模型更容易学习和吸收。通过这种分解和渐进的方式,可以有效地传递复杂知识,并在不同层级之间建立起桥梁,提高知识蒸馏的效果。
实验
消融实验
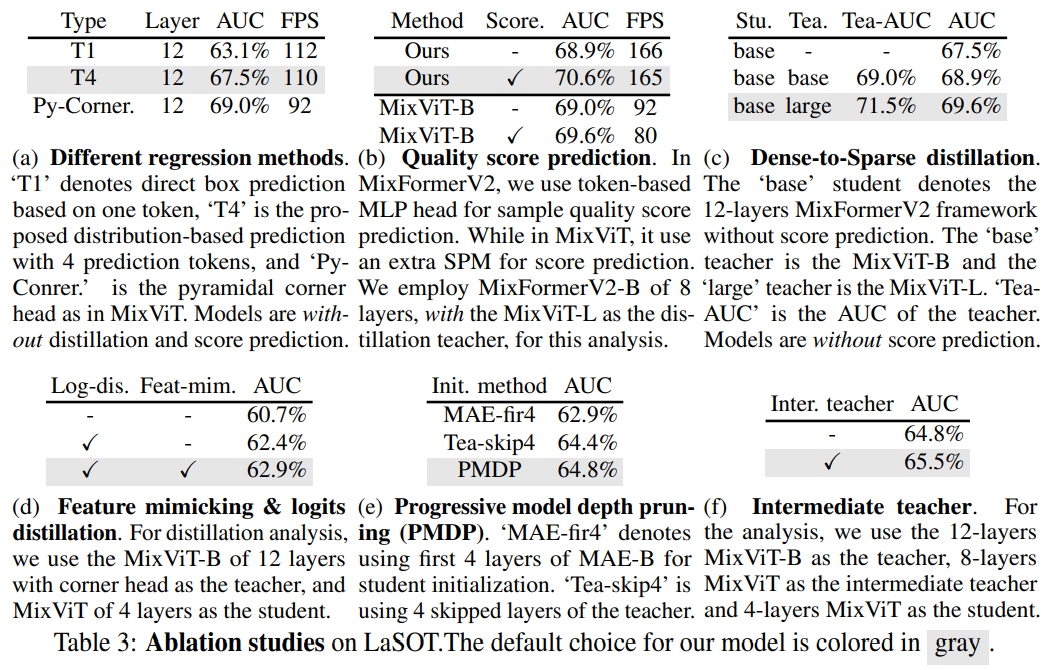
定性分析
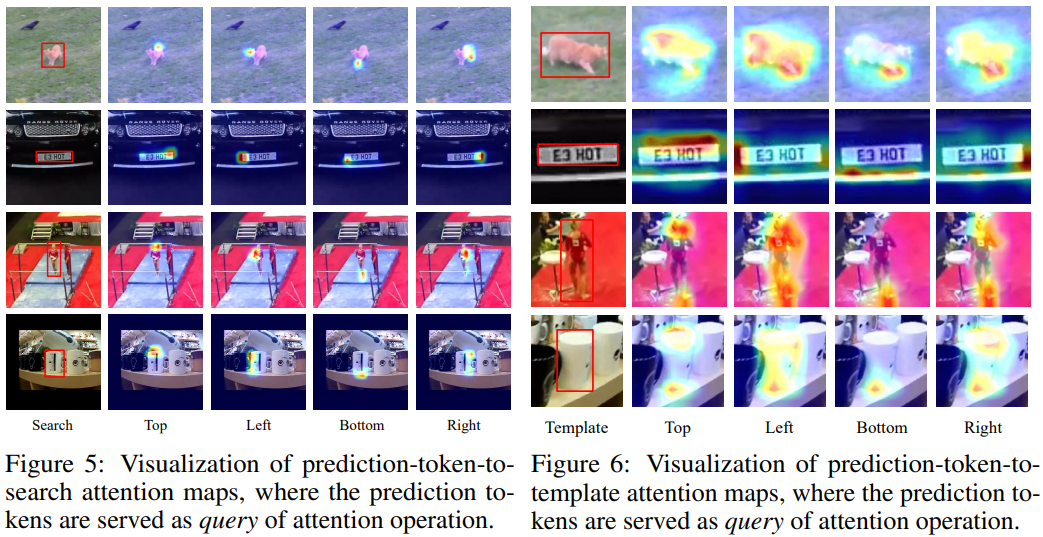
定性分析
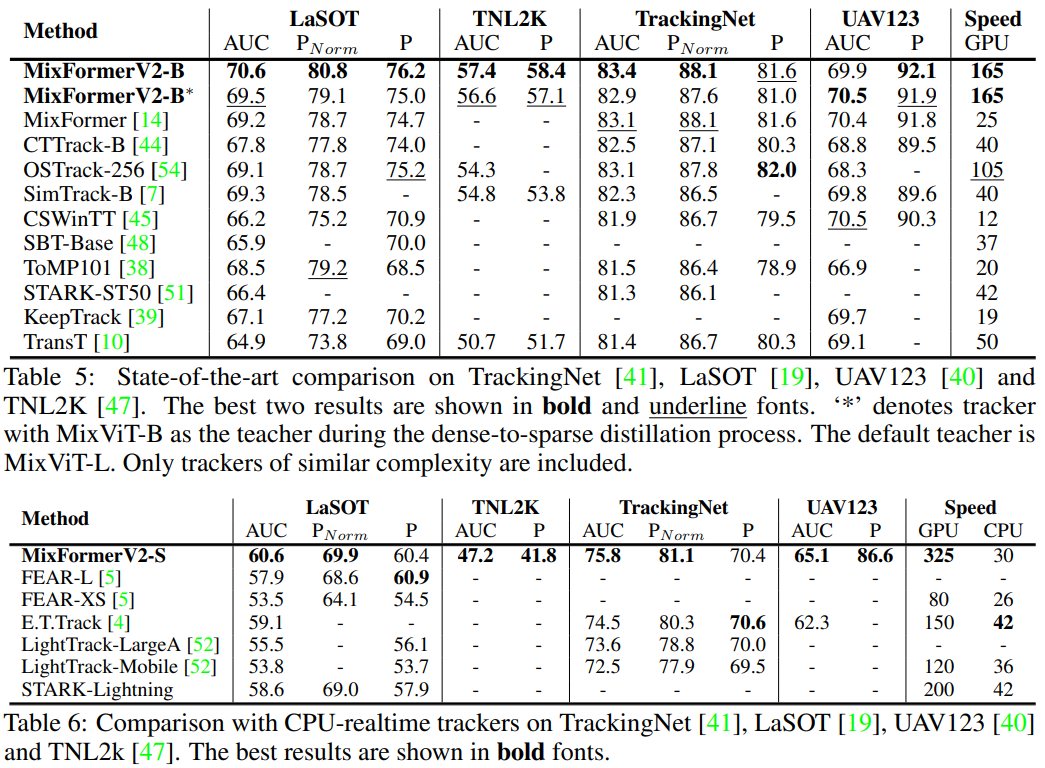
综上所述, MixFormerV2 跟踪器在性能和效率方面取得了显著的改进,超越了现有的跟踪器,并在多个基准数据集上达到了最优性能。对于实时运行要求,作者的轻量级模型 MixFormerV2-S 在 CPU 设备上实现了实时速度,表现出色。这些结果证明了作者提出的方法的有效性和优越性。
总结
本文提出了一种创新的跟踪框架MixFormerV2,通过使用Transformer网络和简化的头部结构,实现了高效而准确的目标跟踪。通过模型简化和知识蒸馏等方法,MixFormerV2 在速度和性能方面取得了显著的改进,并在多个基准数据集上达到了最优性能。这一研究为未来的跟踪器设计和开发提供了有价值的参考。
CVHub是一家专注于计算机视觉领域的高质量知识分享平台,全站技术文章原创率达99%,每日为您呈献全方位、多领域、有深度的前沿AI论文解决及配套的行业级应用解决方案,提供科研 | 技术 | 就业一站式服务,涵盖有监督/半监督/无监督/自监督的各类2D/3D的检测/分类/分割/跟踪/姿态/超分/重建等全栈领域以及最新的AIGC等生成式模型。关注微信公众号,欢迎参与实时的学术&技术互动交流,领取CV学习大礼包,及时订阅最新的国内外大厂校招&社招资讯!

















 618
618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











