






作者 | sonta 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/9300089039
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
TL;DR: 实在受不了傻13工作还有眼瞎reviewer给8分,并且作者在rebuttal阶段全程嘴硬,遂直接在Openreview贴脸开大,正义制裁:https://openreview.net/forum?id=GrmFFxGnOR¬eId=2QR0ZJjvCm
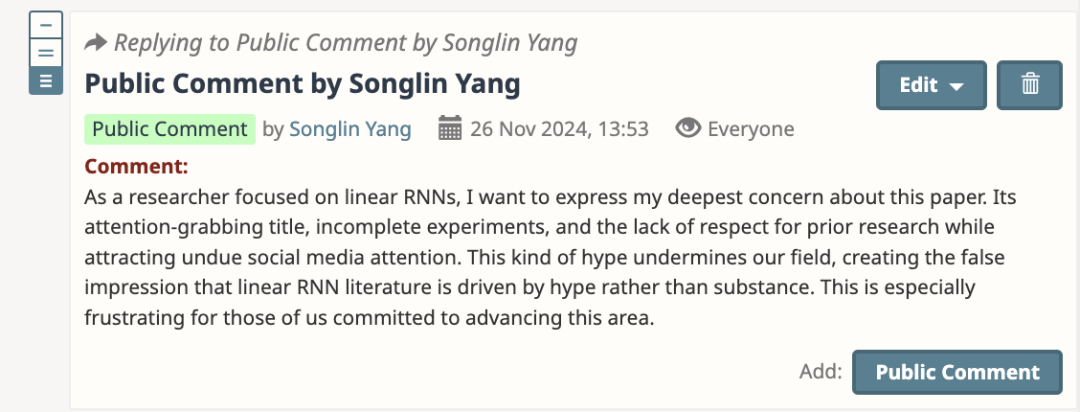
Were RNNs all we needed? 受到了毫无相关技术背景的小编们的无脑吹捧和热议
机器之心:图灵奖得主Yoshua Bengio新作:Were RNNs All We Needed?
量子位:Bengio精简了传统RNN,性能可与Transformer媲美
新智元:RNN回归!Bengio新作大道至简与Transformer一较高下
这篇文章核心思路就是把hidden to hidden state之间的nonlinear dependency全部扔掉,然后RNN就变成了一个Linear RNN,可以用associative scan的思路来并行训练

然而这个idea早就在linear RNN领域里玩烂了。其中ICLR '18最经典也最被低估的一篇工作 Parallelizing Linear Recurrent Neural Nets Over Sequence Length 里提到的Gated Impluse Linear Recurrent (GILR) layer几乎完全等价于minGRU.

我在之前也早有blog来理清这一系列的工作的发展
sonta:RNN最简单有效的形式是什么?
https://zhuanlan.zhihu.com/p/616357772
并且我NeurIPS '23 Spotlight的一个工作,HGRN,正是基于这个思路来进行的
Hierarchically Gated Recurrent Neural Network for Sequence Modeling
arxiv.org/abs/2311.04823
其中有一个审稿人锐评道:

作者的狡辩是:
Martin & Cundy (2018) focus on parallelizing linear RNNs and propose the GILR (Generalized Linear RNN) architecture. GILR is used as a linear surrogate for the hidden state dependencies of traditional LSTMs, allowing for parallelization. The resulting architecture GILR-LSTM retains much of the complexity of LSTMs but with parallelizability, resulting in a larger memory footprint due to the use of surrogate states.
这是十足的偷换概念:我们可以在上面的recurrent形式可以看到,GILR完全等价于minGRU。作者在用另外一个extension GILR-LSTM来混淆视听,狡辩道
Martin & Cundy (2018) focus on parallelizing linear RNNs and propose the GILR (Generalized Linear RNN) architecture. GILR is used as a linear surrogate for the hidden state dependencies of traditional LSTMs, allowing for parallelization. The resulting architecture GILR-LSTM retains much of the complexity of LSTMs but with parallelizability, resulting in a larger memory footprint due to the use of surrogate states. In contrast, our work takes a different approach by simplifying traditional RNN architectures rather than augmenting them
这种被审稿人按着捶还不认错,反过来混淆视听的做法真是一点b脸都不要了。此外,这篇文章的完成度低的令人发指,几乎没有稍微大一点的实验。对此,某图灵奖得主挂名的团队给的解释是:

而我们发表在一年前的HGRN就已经做了Billion level的language modeling的实验了。看不下去的我直接openreview发了个public comment:

提到了我们HGRN和之后一系列的work,并且重新提了minGRU和GILR的关系。作者依然用上面糊弄审稿人的做法来糊弄我,
并且解释道这篇的motivation是为了simplify existing architecture

变得新手友好,老少皆宜。
我哭笑不得,首先勒令他们解释跟GILR的区别,

并且痛批他们开倒车,把整个领域这一年的发展直接清零,梦回一年半前

同时作者团队还在解释,不是他们博人眼球特意宣传,是大家自发进行的:

(内心OS:对对对,你们有这么大一个图灵奖得主挂名,标题起的这么大,可不得是一堆自干五来做宣传吗)
我的使命到此结束,等待AC和其他审稿人的正义制裁
结言
肉眼可见,ICLR ‘25 是一届特别糟糕的会议。主办方大聪明觉得把审稿人的池子放水,引入了一堆本来没有资格审稿的人加入审稿大军,那么每个审稿人的workload不就小了吗?这一大放水的结果可想而知,这么离谱的一篇工作,还有两个reviewer给出了8分和6分的高分,并且8分reviewer直呼novel,气的我反手一个public comment:
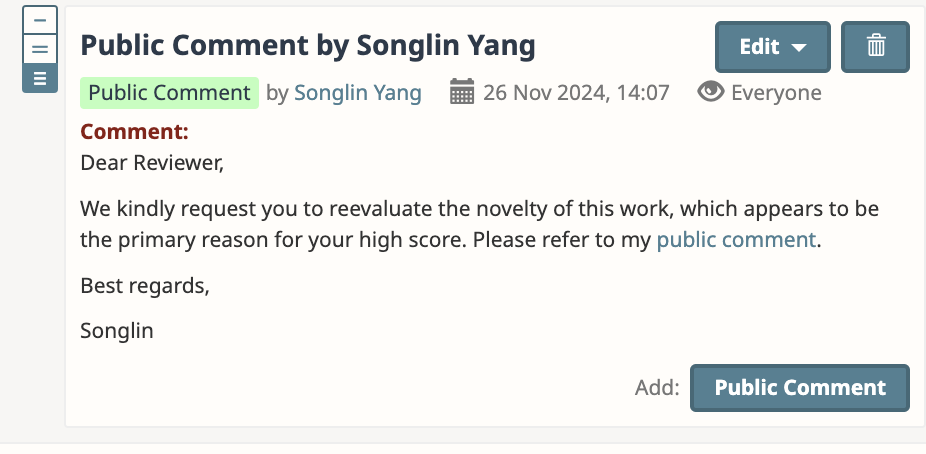
审稿workload变低了,但审稿质量离谱了,大家又得花更多的时间去处理不称职审稿人的意见,导致本届会议的discussion氛围感人,主办方直接延期rebuttal一周,让大家感受三周rebuttal的快乐,真是不戳呢(
同时,我发现审稿人对linear RNN的进展的了解真是少的令人发指,我一个一年前的starting point工作,被人重新包装了一遍还能受到一些好评。感觉提高自己工作的曝光度是一件非常重要的事情,教育community也是(不多说了,赶紧去写blog来系统的介绍自己这两年的工作了)
① 2025中国国际新能源技术展会
自动驾驶之心联合主办中国国际新能源汽车技术、零部件及服务展会。展会将于2025年2月21日至24日在北京新国展二期举行,展览面积达到2万平方米,预计吸引来自世界各地的400多家参展商和2万名专业观众。作为新能源汽车领域的专业展,它将全面展示新能源汽车行业的最新成果和发展趋势,同期围绕个各关键板块举办论坛,欢迎报名参加。

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









