







花了差不多一周写了这个总结
希望对一些小伙伴有帮助
目录
各大生信资源的使用流行程度
生信数据库的霸主-NCBI以及Entrez检索系统
Gene查找好帮手-Entrez Gene数据库
人类基因命名委员会-HGNC
Ensembl计划
NCBI非冗余序列数据库-RefSeq
NCBI核酸序列数据库-GenBank
蛋白质序列数据库-Uniprot
GEO数据库
拓展阅读-GENCODE
要想成为一名合格的生物信息工程师,首要条件就是能在各大生信数据库中自由翱翔。目前的生信数据库大体可以分为三类:核酸数据库(例如:GenBank,Ensembl等),蛋白质数据库(例如:Uniprot,PDB等)以及专用数据库(例如:KEGG,GO,GEO等等)。可以说数据库的种类和数量都非常的繁多!同时,每个数据库都有自己独特的检索ID编号(例如Entrez ID,Ensembl ID 等等),也就是说同一个基因在不同的数据库中会有不同的名称。这么多生信ID和数据库看着真是眼花缭乱。。。我们几乎不可能全部都记住!
所以,为了提高学习效率,我们首先来看看生信领域最流行使用的数据库有哪些吧,然后再针对性地去学习相应的数据库和它们的编号系统!
各大生信资源的使用流行程度
PLOS-ONE上的一篇文章利用bioNerDS工具分析了Pubmed的 5,411,968篇文献的语料库,最终得到下列生信领域的资源使用排名:
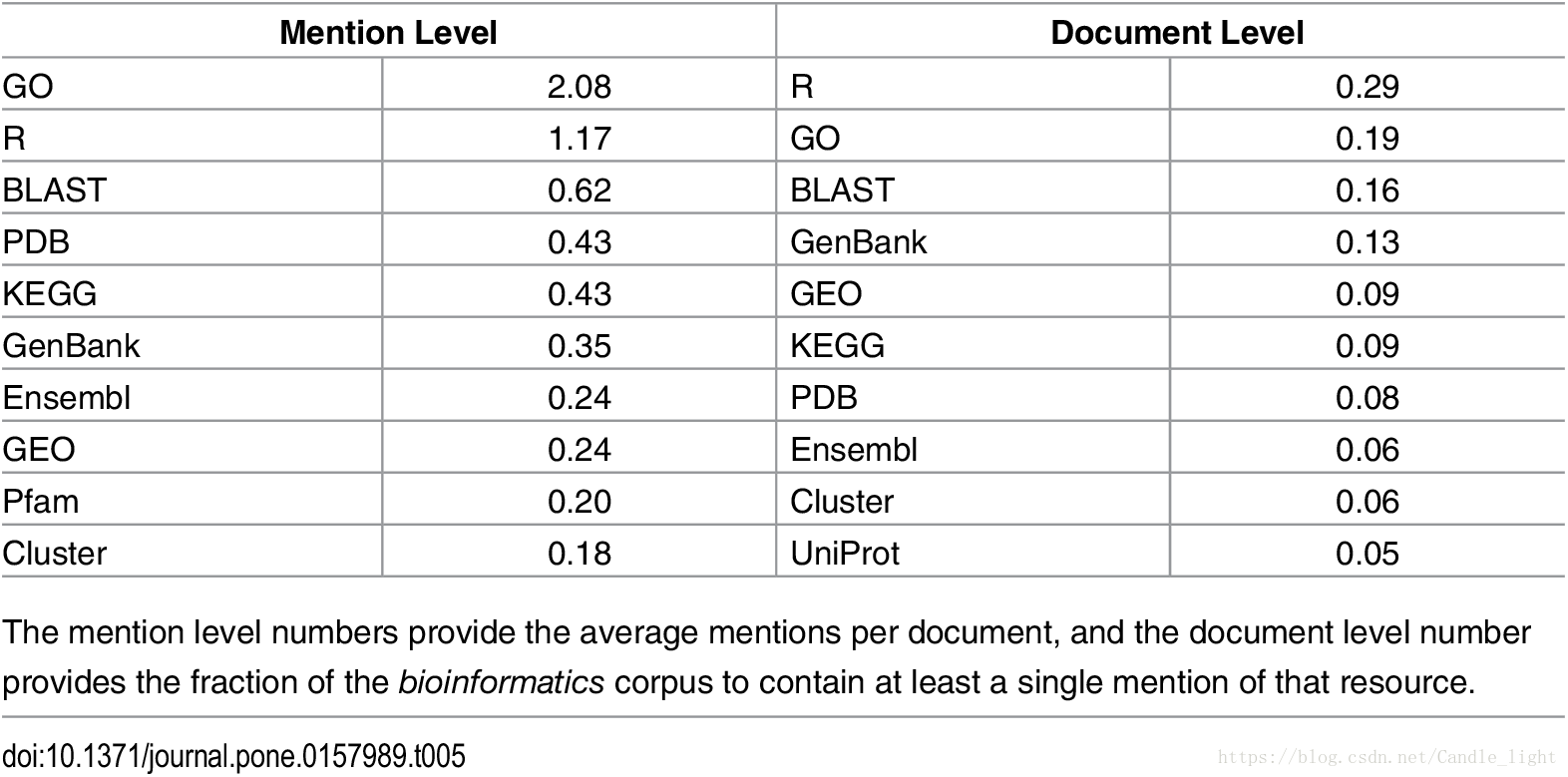
从这张表,我们可以明显发现生信领域的NCBI-GenBank, UniProt, GO, KEGG和GEO等数据库的使用频率都非常高。所以,我们的学习就从这些主要的数据库开始!
生信数据库的霸主-NCBI以及Entrez检索系统
谈到生信数据库,就不得不提非常著名的NCBI。NCBI是什么呢
NCBI(National Center for Biotechnology information)即美国国家生物技术信息中心,由美国国立卫生医学图书馆(NLM)于1988年建立。该中心的任务是:为储存和分析分子生物学、生物化学、遗传学知识创建自动化系统;从事研究基于计算机的信息处理过程的高级方法,用于分析生物学上重要的分子和化合物的结构与功能;促进生物学研究人员和医护人员应用数据库和软件;努力协作以获取世界范围内的生物技术信息。
所以,需要明确的是,我们常说的NCBI是一个机构组织,而不是数据库喔。那么,我们登陆的NCBI的网页(https://www.ncbi.nlm.nih.gov/) 所访问的数据库和NCBI是什么关系呢?那就不得不提Entrez啦!
Entrez是归属于NCBI的一个综合的文本检索引擎系统。这个检索引擎整合了PubMed数据库的生物医学文献与其他39个文献和分子数据库(例如GEO,Entrez Gene等,这些数据库基本涵盖了DNA和蛋白质序列,结构,基因,基因组,遗传变异和基因表达方面的数据)。
所以,我们通常所说的检索NCBI数据库,其实就是在检索Entrez这个引擎系统所整合的生信数据库。简而言之就是,NCBI组织建立了Entrez,Entrez整合了各大数据库的入口,方便我们进行数据库检索
了解了NCBI和Entrez的关系之后,我们来看看还有哪些常用的数据库吧。
假设我们现在想检索一个名字叫做TP53的基因,了解它的故事,我们应该去哪个数据库呢?同时,TP53只是这个基因多个名称中的一个(它还有其它的名字,例如:7157,HGNC:11998等等),所以这些不同的基因名称之间又有什么区别呢?
OK , 让我们一一道来!
首先,要想快速了解一个Gene并且获取和它相关链接的外链数据库,我们首推Entrez Gene数据库!什么是Entrez Gene数据库呢?
Gene查找好帮手-Entrez Gene数据库
Entrez Gene数据库是Gene查找的好帮手,一般情况下我们如果想快速了解一个Gene的基本信息,可以直接进入(https://www.ncbi.nlm.nih.gov/gene/) 进行搜索。
NCBI的Gene数据库
Entrez Gene数据库其实就是我们现在指的NCBI中的Gene数据库(这两个名字指的是同一个数据库)
Gene数据库建立的目的是,整合各个方面和基因相关的数据资源,构建一个能够使人快速访问并且获取特定基因信息的访问入口,从而为数据交换以及科学家们的研究提供便利。它的数据包含了和基因相关的序列,结构,以及基因表达等等的信息,是基因资源的综合数据库。
我们输入TP53之后会得到这样的检索结果界面:

在标题下面,我们可以看到Gene ID: 7157 这一行,7157就是我们耳熟能详的Entrez Gene ID啦,它是目前国际上最权威的Gene ID编号!
Entrez Gene ID 又可以称为Entrez ID ,也是我们通常所说的Gene ID 。它是来源于Entrez Gene数据库的编号系统。每个Gene数据库中的记录数据都会被分配一个唯一的Gene ID编号。编号的格式就是一串数字,例如:7157,2131这样的。同时,Gene ID的数字并不是连续分配的(也就是说有间隔)。
Gene ID的分配规则:Gene ID通常被分配给RefSeq数据库中注释为基因的对象,当然,并不是所有的Gene ID都基于RefSeq,如果RefSeq数据库中没有记录,也可以指定GeneID。
需要注意的是,Gene ID编号的命名是具有物种特异性的(例如,编码人的肌营养不良蛋白的基因和编码小鼠肌营养不良蛋白的基因,它们俩的Gene ID在Gene数据库中编号是不一样的,分别是:1756 和 13405)。
关于Entrez Gene数据库,我们还可以来看看一个统计数字
Entrez Gene 中目前一共有61118条人类的Gene ID记录(记录包括功能基因,假基因,预测基因等等),68389条小鼠Gene ID的记录,可以说是非常全面了。
同时,Gene数据库中的ID记录是每日更新一次,可以保证我们每天看到的Gene ID记录都是最新的啦


Entrez Gene数据库现在既然这么厉害,那它最初的时候是什么模样呢,聊聊历史吧
历史
Gene数据库首次公开是在1999年,那时它的名字还不叫Gene,而是叫做LocusLink(曾用名,现已不再使用)。当时刚刚发表的LocusLink只包含了人类这一个物种的数据信息,而且只有不多于9000条的记录。LocusLink的外链数据库也只有dbSNP, OMIM, RefSeq, GenBank, 和UniGene。(见下图)
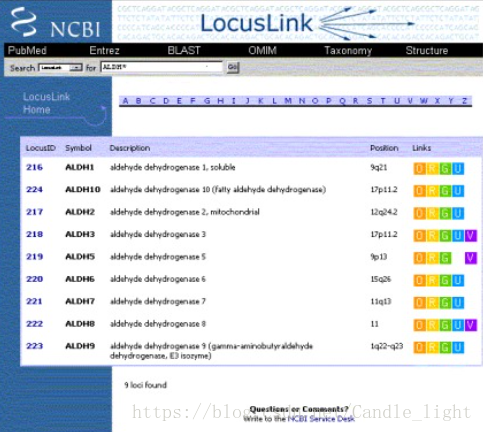
而到2003年,Entrez Gene数据库发布,Gene数据库的数据已经包含了10个物种,195000条记录,外链数据库也增加了许多,包括dbSNP, Ensembl, the HUGO Gene Nomenclature Committee (HGNC), GEO, Map Viewer等等。至今,随着生物大数据的爆发式增长,Gene数据库包含的数据记录与外链数据库也越来越多,已经成为生信工作者必不可少的工具之一。
可见,我们的Enrez Gene数据库的发展也是很迅速哒!
了解完Entrez Gene之后,我们再接着往下看,出现了Summary这一栏,首先映入眼帘的是三行
- Official Symbol : TP53 provided by HGNC
- Official Full Name tumor protein p53 provided by HGNC
- Primary source HGNC: HGNC:11998
不约而同,这三行的内容来源均是HGNC,什么是HGNC呢?
人类基因命名委员会-HGNC
人类中大多数基因的命名,是由HGNC(HUGO Gene Nomenclature Committee,人类基因命名委员会)来完成的。
HGNC(HUGO Gene Nomenclature Committee)即人类基因命名委员会,是由美国国家人类基因组研究所(NHGRI)和英国惠康信托基金(Wellcome Trust)共同出资成立的非盈利机构。
早在二十世纪60年代的时候,科学家们就意识到基因规范命名的重要性。于是1979年,在爱丁堡的人类基因组会议(HGM)上,Phyllis J. McAlpine博士所组成的命名委员会首次提出了人类基因命名规范。2007年9月,HGNC搬迁到欧洲生物信息学研究所(EBI)。目前,HGNC可以说是国际上非常权威的人类基因命名组织了
目前,HGNC已经批准了超过41500个Gene Symbol ,其中超过19190个基因属于蛋白质编码基因,超过 7300个基因属于非编码RNA的基因,同时HGNC还为假基因以及基因组特征命名。HGNC也允许个人在遵循命名规范的前提下,向他们提交Gene Symbol的命名。
所以,刚才我们看到的Official Symbol(Gene Symbol),Official Full Name,HGNC:ID的含义分别是:
- HUGO Gene Symbol:HUGO Gene Symbol(也叫做HGNC Symbol,即基因符号)是HGNC组织对基因进行命名描述的一个缩写标识符(如:TP53),这些基因符号都是唯一的。
- Gene Name:Gene Name是经过HGNC批准的全基因名称;对应于上面批准的符号(Gene Symbol)。例如TP53对应的Gene Name就是:tumor protein p53 。
- HGNC ID:HGNC ID是HGNC数据库分配的基因编号,每一个标准的Symbol都有对应的HGNC ID 。我们可以用这个编号,在HGNC数据库中搜索相关的基因。例如:HGNC:11998
- 有时候HGNC会对一些已经命名过的基因进行重新审查和重新命名,以确保新的基因命名在描述基因功能方面更加的准确。当一个基因被HGNC分配了新的Gene Symbol时,它之前的命名,会被当作同义词继续使用,所以一般建议使用HGNC ID而不是HGNC Symbol来作为我们处理数据中的唯一标识符。
同时,需要明确的是,因为HGNC只对人类基因进行命名,而且并不是所有的基因都有Official Symbol。所以如果基因缺少HGNC提供的Gene Symbol ,Entrez Gene数据库中的Official symbol就会变成Gene Symbol,并且Gene Symbol的编号会变成LOC前缀+Entrez ID,例如:LOC4333818

关于基因命名的组织委员会:
除了人类之外,对于一些典型的模式物种而言,也有相关的命名委员会。小鼠(mouse)的基因命名是来源于MGNC(可访问MGI数据库),大鼠(rat)基因命名来源于RGNC(可访问RGD数据库),斑马鱼的基因命名来源于ZFIN。还有一些其它物种的基因命名,基本就来源于NCBI的Gene数据库和Uniprot数据库。如果有些基因这些数据库里都没有命名,那么一般会直接从一些典型的模式物种(例如小鼠,斑马鱼等)的同源基因命名中引进。
了解完HGNC之后,回到刚才的话题,在TP53的检索结果接着向下看,会看到See related这一行,它提供了和TP53这个基因相关的外链数据库的连接。即Ensembl ,MIM以及Vega 。
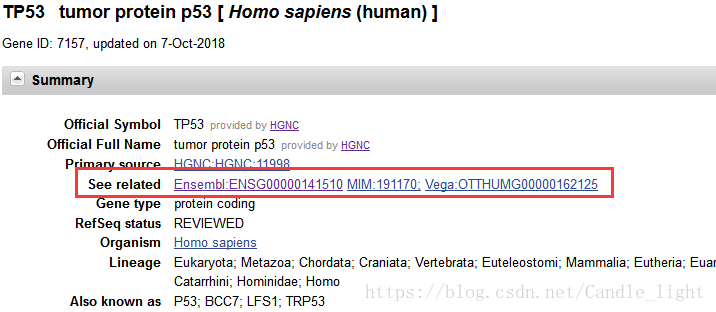
Ensembl:ENSG00000141510 即Ensembl数据库的ID编号,MIM:191170是来源于OMIM数据库(Online Mendelian Inheritance in Man ,人类孟德尔遗传在线数据库)的编号。Vega:OTTHUMG00000162125来自Vega数据库(Vertebrate Genome Annotation,脊椎动物基因组注释 )
其中,Ensembl ID可以说是非常常见了,基本做生信的人都要接触。所以,让我们来详细了解一下Ensembl数据库!
Ensembl计划
首先看看Ensembl是什么
Ensembl基因组数据库项目是欧洲生物信息研究所和Wellcome Trust Sanger研究所之间的一个联合科学项目,该项目于1999年启动,以应对即将完成的人类基因组计划。Ensembl旨在为遗传学家,分子生物学家和其他研究我们自己的物种和其他脊椎动物和模式生物的基因组的研究人员提供集中资源。Ensembl是用于检索基因组注释信息的几种众所周知的基因组浏览器之一。
同时,需要注意的是,Ensembl中的基因组注释由两部分组成:计算机自动注释(例如全基因组的转录本注释)以及人工注释。人工注释主要针对选定的物种(如:人类,小鼠,斑马鱼等等)。人工注释由Havana(Human and Vertebrate Analysis and Annotation)小组来完成。(我们在gtf注释文件中看到的HAVANA指的就是他们!HAVANA小组最开始是在Sanger研究所,2017年的时候迁往EBI了)
提到Ensembl,还有2个大名鼎鼎的计划也不得不提!那就是ENCODE和GENCODE
Ensembl与ENCODE以及GENCODE计划之间的关系
Ensembl是ENCODE计划的子项目。而GENCODE计划(由Sanger研究所维护)则是ENCODE项目的衍生品,它的目标是为ENCODE项目提供可用的人类基因组和小鼠基因组注释。Ensembl在ENCODE计划中的作用是,为人类基因组的组装提供计算机的自动注释信息,并且把这些自动注释的信息和来自HAVANA的人工注释信息进行合并。GENCODE中的人类和小鼠的基因组注释和Ensembl数据库是同步发行的。
关于GENCODE的详细介绍,可以看本文最后的拓展阅读。
OK,了解完Ensembl数据库是做什么的之后,我们就可以使用Ensembl数据库来检索感兴趣的基因在基因组上的信息了。
我们在Ensembl中进行检索主要使用的是Ensembl Stable ID(也就是常说的Ensembl ID),例如:ENSG00000141510 。Ensembl ID也是有自己的命名规则的
Ensembl Stable ID的定义,格式,版本
Ensembl Stable ID是来源于Ensembl数据库的编号系统。它的命名由三部分组成:[species prefix][feature type prefix][a unique eleven digit number]. (根据不同物种设置的前缀+数据所指类型【例如,蛋白质,基因】+一段特定的数字),所以一个小鼠的基因在Ensmebl中的编号命名就应该是:ENSMUSG########### 。有时可以有不同的版本, 则在 Ensembl ID 后面加上小数点和版本号(例如:ENSG00000223972.5)。Ensembl Stable ID版本号的更替是遵循一定规则的,具体可看:https://asia.ensembl.org/info/genome/stable_ids/index.html 和 https://asia.ensembl.org/info/genome/compara/stable_ids.html
常用的物种前缀
前缀 物种学名 ENSMUS Mus musculus (Mouse) ENSRNO Rattus norvegicus (Rat) ENSMZE Maylandia zebra (Zebra mbuna) MGP_LPJ_ Mus musculus (Mouse LP/J) FB Drosophila melanogaster (Fruitfly) ENS Homo sapiens (Human) 其它 … 类型前缀
前缀 类型 E exon FM Ensembl protein family G gene GT gene tree P protein R regulatory feature T transcript
关于Ensembl,还有一点很重要,那就是它的数据是定期更新的!
Ensembl的数据更新
Ensembl的数据大概2-3个月会更新一次,每次发布不同的版本的时候或者有什么计划安排,Ensembl都会在他们的博客或者Face-book,Twitter上发布消息(墙内的同学可以访问博客)。每次数据更新的范围涵盖新物种、新的基因集注释、新的变异数据等等。
到目前为止Ensembl的数据版本已经发布到94版了(2018年10月)
如果想了解详细的版本信息和不同版本的数据可以访问(http://asia.ensembl.org/info/website/archives/index.html 和 ftp://ftp.ensembl.org/pub/)
既然数据更新了,那就有一个非常重要的问题,存储在Ensembl数据库中的Ensembl Stable ID是否会发生变动?
OK,毕竟是大牛们做的项目,他们早就替我们想好啦。
Ensembl Stable ID 名副其实的“Stable”,一旦被分配之后,是尽可能的保持稳定不更改的。但是也有不稳定的情况存在:
一般情况下,如果某个基因数据发生一些小的改动,(例如某个基因对应的转录本信息发生变化),Ensembl Stable ID是不会变动的。但是Stable ID后面的Version会变化,就是在Ensembl ID 后面加上小数点和版本号。比如说:ENSG00000223972.5 。
不一般的情况下,例如基因组组装序列的一些改变较大,或者基因组注释的更新影响了某个基因的整体模式。这时,我们的Ensembl才会分配新的Ensembl Stable ID啦!
目前蛋白质家族的ID(fam),Ensembl EST基因的ID(ENSESTG)和 Genscan的ID (GENSCAN) 都是不稳定的。所以如果有小伙伴用了这些数据的Ensembl ID要注意保持这些ID的实时更新喔!
如果我们想看自己感兴趣的Gene在Ensembl中是否发生过ID变动,我们应该怎么做呢? OK,Ensembl是非常全面哒!
ID历史版本转换
Ensembl非常贴心的为我们提供了ID History Converter工具帮助使用者进行ID的新旧版本转换。有些数据的record里面,会有ID History一栏,帮助我们查看ID目前的版本和历史版本。例如:ENSG00000139618 的记录里就有
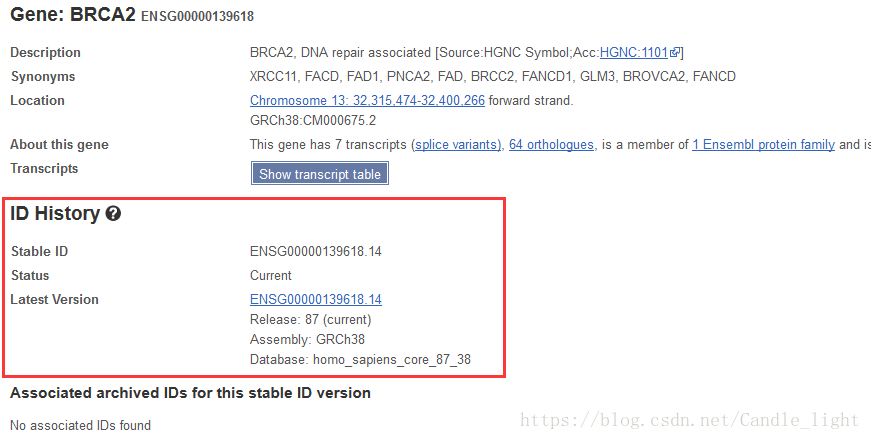
好啦,关于Ensembl和Ensembl ID的介绍就到这里,了解完Ensembl之后,我们接着向下看,发现有一个RefSeq status REVIEWED

RefSeq status用于指明这个基因记录所对应的状态,REVIEWED说明它已经被专家审核。来看看RefSeq数据库
NCBI非冗余序列数据库-RefSeq
RefSeq数据库,即RefSeq参考序列数据库,是美国国家生物信息技术中心(NCBI)提供的具有生物意义上的非冗余的基因和蛋白质等片段序列的数据库。
RefSeq的序列数据来源于大名鼎鼎的INSDC(International Nucleotide Sequence Database Collaboration,国际核苷酸序列数据库联盟),所以RefSeq非常权威和全面!
要知道现在是大数据时代,有非常多的数据,很多冗余的信息是没有用处的,而RefSeq能提供非冗余的序列,真的是非常有用了!我们来看看怎么在RefSeq中进行检索吧
RefSeq 有一套特殊的 Accesion Number(就是我们通常用的RefSeq ID)让我们来进行检索。RefSeq数据库中的Accession number和GenBank数据库中的AC号格式不同。
RefSeq数据库Accession number的格式以两个字母开头,后跟一个下划线和六个或多个数字开头,例如:
NT_123456 constructed genomic contigs
NM_123456 mRNAs
NP_123456 proteins
NC_123456 chromosomes
ID的常见前缀是
前缀 类型 说明 AC_ Genomic Complete genomic molecule, usually alternate assembly NC_ Genomic Complete genomic molecule, usually reference assembly NG_ Genomic Incomplete genomic region NW_ Genomic Contig or scaffold, primarily WGS NZ_ Genomic Complete genomes and unfinished WGS data NM_ mRNA Protein-coding transcripts (usually curated) NR_ RNA Non-protein-coding transcripts NP_ Protein Associated with an NM_ or NC_ accession 其它 … …
所以了解这些之后,我们就可以快乐的畅游在RefSeq的序列数据中了!
同时,RefSeq的数据是每日更新的,所以大大的保障了我们科研的效率和及时性!对于人类的RefSeq而言,每条RefSeq后面都会有一个COMMENT,COMMENT会显示这条RefSeq的状态。主要有这些状态:MODEL(说明是自动被NCBI提供的,没有被审核过),INFERRED(由序列分析预测得到,没有经过实验验证),PREDICTED(没有经过人工审核),PROVISIONAL,REVIEWED(已被人工审核),VALIDATED(已经过初步审查,但还没有过最后审查)以及WGS。
所以我们在用RefSeq的序列时也要注意看看它的Status哟,看它是否是经过审核的!
了解完RefSeq之后,我们也来看看其它著名的核酸序列数据库吧!
NCBI核酸序列数据库-GenBank
谈到核酸序列数据库,就不得不提NCBI的GenBank了
GenBank是由美国国立生物技术信息中心(NCBI)维护的一级核酸序列数据库。GenBank数据库中也包括部分蛋白质序列,源于核酸序列注释结果。数据每天更新,每年发行六版release 。GenBank,EMBL和DDBJ同时组成了国际核苷酸序列数据库联盟,让核酸的序列信息得以共享,三大数据库的数据资源都是每天进行更新和交换。
GenBank的数据来源渠道主要有三种:1. 科研工作者提交的序列数据 2.与其他数据机构协作交换的数据 3.其他从测序中心获得的高通量数据。再来看一组数字
GenBank的数据来源于260,000多个物种
GenBank中约有13%的序列来自于人类
数据量排名第一的物种是Homo sapiens(人类),其次是小鼠
目前GenBank的数据已经发布到第227版本(截至2018年8月)

可见我们的科研工作者对人类方面的研究是非常多的!所以数据很多。
GenBank中既然有这么多数据,如果我们想在GenBank中进行序列检索,应该怎么做呢?
可以有两种方式在GenBank中进行检索:(1)泛式检索:例如直接输入感兴趣序列所在基因的名称或者提交作者的姓名等 (2)特殊标识符检索:即GI号和Genbank的Accession number。
第一种检索方式非常简单,这里就不再赘述。需要我们谈谈的是,第二种检索方式中的GI号和Accession number(注册号/登陆号)是什么含义
GI number: GI号(GenInfo Identifier,有时用小写字母“gi”表示)是核苷酸序列的序列标识号,由一系列简单的数字组成。它们被连续分配给NCBI处理的每个序列记录,如果一个序列以任何方式改变,那么一个新的GI号将被分配。需要注意的是,GI号和序列的Accession number没有什么关联。
GenBank-Accession Number:Accession Number又叫做注册号/登录号,像GI号一样,它也是唯一的序列标识符。但是与GI号不同的是,AC号一旦分配就不会改变了。一个AC号通常是字母和数字的组合,例如一个字母后跟5位数(如U12345)或两个字母后跟6位数(如AF123456)。
好啦,所以GI号和Accession number都是GenBank数据库中对某条序列进行标识的标识符。这里呢,还需要注意两个概念,那就是GI号和Accession Number.Version.我们的GI号和Accession Number.Version都是可以用来追踪一条序列的演化的。那么这两种标识符之间又有什么关系呢
GI号和Accession Number.Version
NCBI的GI号和Accesion Number.Version是两种不同系统的标识符,它们是平行使用的。当序列的数据改变或升级时,将会分配一个新的GI number。Accession number主体编号不会改变,但是它所对应的版本(Accession number.Version)会随着增加。如NM_008261.1–>NM_008261.2(GI number:6680238–>46575915)。
此外,关于GI号的使用,还有一段不得不说的历史。。。来看看吧:
历史
GI(GenInfo Identifier)号是NCBI很早就用来作为序列标识符的编号系统。但是国际核酸序列数据库联盟(GenBank、EMBL和DDBJ)刚成立时并没有统一的使用GI号,而是使用它们各自数据库内部的编号来追踪序列。后来,国际核酸序列数据库联盟(GenBank、EMBL和DDBJ)决定统一使用一个编号来唯一标识序列,于是它们创造了NID(核酸序列标识号)和PID(蛋白质序列标识号)。直到1999年12月,NID和PID的叫法才中断使用,对序列的唯一标识符又恢复成我们现在所熟知的GI号。
同时,1992年的时候国际核苷酸序列数据库联盟(GenBank、EMBL和DDBJ)开始启用Accession Number.Version系统,确保了国际的通用性,并且对序列的标识性与追踪性更加地方便,Accession Number.Version与GI number平行运行。
想了解更多详细的GI历史以及GI和Accession number.version的区别可见:https://www.ncbi.nlm.nih.gov/genbank/sequenceids/
好啦,到此为止,我们就学习完GenBank数据库了。学完核酸序列数据库之后,下面,我们再来谈谈蛋白质序列数据库-Uniprot。
蛋白质序列数据库-Uniprot
UniProt是Universal Protein 的英文缩写,是一级蛋白质序列数据库。
Uniprot整合了三大数据库(Swiss-Prot,TrEMBL和PIR-PSD)的数据,是目前国际上最广泛使用的蛋白质数据库(没有之一)。
大多数情况,我们检索蛋白质序列信息,都是去的UniprotKB,所以掌握UniprotKB的搜索技巧就很重要啦!了解一下UniprotKB
Uniprot中的UniprotKB(UniProt Knowledgebase)是收集蛋白质功能信息的中心枢纽,具有准确,一致,丰富的注释。UniprotKB主要由两部分组成:UniProtKB/Swiss-Prot (包含检查过的、手工注释的条目) 和 UniProtKB/TrEMBL (包含未校验的、自动注释的条目)。
由于UniProtKB/TrEMBL中的条目是由计算机自动注释的,所以我们可以看到UniProtKB/TrEMBL的数据数量远远超过了UniProtKB/Swiss-Prot中的数据数量。
了解完基础背景知识之后,我们来看看UniprotKB中的编号ID是什么样的吧
UniprotKB中主要有两种编号系统:Accession number和Entry name 。
由于UniprotKB包括了Swiss-Prot(人工注释)和TrEMBL(计算机注释),所以entry name有两种命名方式:UniprotKB/Swiss-Prot entry name和UniprotKB/TrEMBL entry names 。
UniprotKB/Swiss-Prot entry name
UniProt 中录入的数据都被分配了一个唯一的 Entry name。UniprotKB/Swiss-Prot Entry name可以由多达11个的大写字母+数字组成。它的命名方式可以表示为X_Y的形式。X是蛋白质或基因名称的缩写(并不是标准的Gene name),最多可以由五个字符组成。“—”表示下划线。Y代表物种的编码,最多也是只能由五个字符组成(通常由属名的前三个字母和种名的前两个字母组成)。
例如:
PURQ_ZYMMO
INS_HUMAN
UniprotKB/TrEMBL entry names
UniProtKB/TrEMBL的Entry name 由多达16个大写字母数字字符组成,其命名形式类似于UniProtKB/Swiss-Prot,也是X_Y的形式。其中,X与登录号(Accession number)相同,由6或10个字母数字字符组成。“—”代表下划线。Y代表物种的编码,最多也是只能由五个字符组成。因为TrEMBL中的蛋白质数据太多,不可能所有的条目都人工进行物种编码。所以TrEMBL启用了“虚拟编码”来对物种进行分类。这些虚拟的物种编码都是以数字9为前缀,举例来说,如下:
Mnemomnic code Taxonomic identifier Scope 9BACT 2 Bacteria 9CNID 6073 Cnidaria 9FUNG 4751 Fungi 9REOV 10880 Reoviridae Accession Number
UniprotKB中的每个条目都会分配一个唯一的Accession Number。accession number不会随数据的更新而变化,只有数据被删除的时候,accession number才会被删除。所以它是非常稳定的标识符,相当于数据库中的主键。
Uniprot的登录号(accession number)由6个或者10个字母数字的组合构成。构成方式是:
[OPQ][0-9][A-Z0-9]{3}[0-9]|[A-NR-Z]0-9{1,2}
例如:A2BC19, P12345, A0A022YWF9
刚才我们看到了UniprotKB有两种编号系统,那么这两种编号之间有什么关系和区别呢?
Entry name与Accession Number的关系和区别
提交数据到UniprotKB之后,每个数据都会被分配一个Accession Number(AC号),这个AC号是唯一的。为了减少数据冗余,如果将UniprotKB中的多个数据合并成一个,AC号仍然是保持不变的。Entry name也是每个数据唯一具有的标识符,它可以展示数据的生物学信息。但是Entry name并不是稳定存在的,比如说我们要将TrEMBL中的数据转入Swiss-Prot,那么我们需要变更数据的Entry name,此时同一个数据的Entry name就发生了改变,但是它的AC号仍然保持不变。这就是他们之间的区别!
还有需要注意的是,一个数据可能有两个或者多个accession number 。原因主要有两个:(1)当合并两个或多个数据条目时,保留所有数据条目的登录号。第一个AC编号称为“主要AC编号”,其他编号称为“次要AC编号”。编号排序是按字母数字顺序排列的。
(2)如果现有数据条目被分割为两个或多个数据条目(“拆分”),新的“主要”登录号将归属于所有分裂的条目,而所有原始登录号将保留为“次要”登录号。例如:P29358 被拆分成 P68250 和 P68251 。P68250 和 P68251的次级登录号均为P29358 。
所以,UniprotKB建议,我们最好使用数据的主登录号作为数据引用的方式(不是Entry name ,也不是二级登录号),因为主登录号是唯一并且稳定存在的数据标识符。
了解完AC号和Entry name之后,以UniProtKB/Swiss-Prot为例,我们来看看一组数字
UniProtKB/Swiss-Prot数据小统计
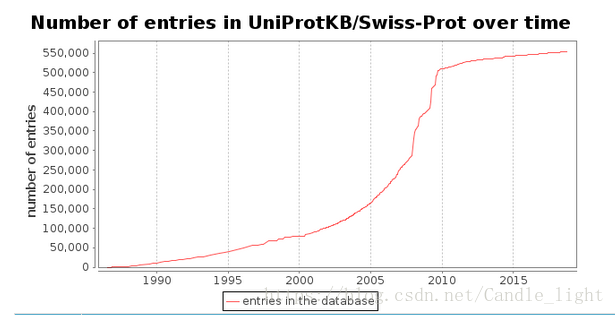
截至2018年9月,UniProtKB/Swiss-Prot中共有558,590个Entry name,可见Entry name数量随时间是迅猛增长的
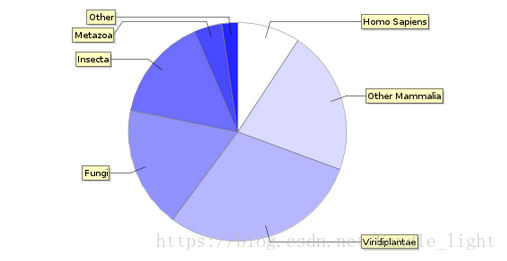
在UniProtKB/Swiss-Prot的数据中,植物占很大一部分,人类数据也占比很多!
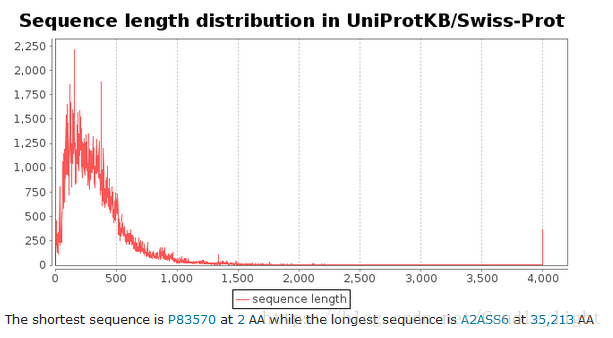
蛋白质序列长度分布在0-500左右,最短的蛋白质序列长度只包含2个氨基酸,最长的蛋白质序列包含35,213个氨基酸
截至2018年9月,UniProtKB/Swiss-Prot 包含 558590条注释条目,UniProtKB/TrEMBL包含126780198条注释条目。
Uniprot确实很厉害!这么多数据,以后我们要是找蛋白质信息,都去Uniprot啦!
数据库和ID介绍到这里,基本就快结束啦,最后,我们再学习学习GEO
GEO数据库
基因表达数据库(Gene Expression Omnibus,GEO)隶属于美国国立卫生研究院的NCBI。是当今最大、最全面的公共基因表达数据资源。GEO数据库的数据由两部分构成:
用户提交的原始数据:GEO Platform (GPL),GEO Sample (GSM),GEO Series (GSE)。其中,GSE=GPL(Platform)+GSA(Sample)
GEO数据库整理后的数据:Data set ,Profile
下面我们简单介绍一下GPL,GSM和GSE
GEO Platform(GPL):平台数据包含阵列或序列以及阵列平台的简要描述。
每个平台都分配了一个特有的登录号用于检索(格式是:GPL+数字编号),例如:平台GPL341 https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GPL341
GEO Sample (GSM) :样本数据描述了每个样本的操作环境,处理方法和分离出的各个成分的丰度测量。每个样本都分配了一个特有的登录号用于检索(格式是:GSM+数字编号)例如:样本GSM12793 https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSM12793
GEO Series (GSE) :GSE=GPL(Platform)+GSA(Sample)
系列数据将一系列相关的样本联系起来,提供了整个研究的关注点和描述,也包含了描述提取数据、简要结论和分析的表格。每个系列都分配了一个特有的登录号用于检索(格式是:GSE+数字编号)例如:系列GSE830 https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE830
看到这里,我们对主流生信数据库的ID规则和数据库的基本情况也就有所了解啦,之后想要进阶还需要不断学习和努力。关于ID转换的部分本文没有讲述,其实这也是一个大坑,等未来再继续填坑!
拓展阅读-GENCODE计划
什么是GENCODE计划呢,我们首先来看一段历史
2003年9月,美国国家人类基因组研究所(NHGRI)发起了一个名为ENCODE((DNA元件百科全书))的公共研究计划。项目的目标是识别人类基因组序列中的所有功能元件。GENCODE计划属于ENCODE计划的衍生品,由Sanger研究所进行维护。2003年的时候GENCODE获得了第一批资助,当时GENCODE的目标是对人类基因组中的功能元件进行注释。GENCODE小组在2013年时获得了第二次资助,以继续他们的人类基因组注释工作,并将GENCODE扩展到包括小鼠基因组注释。2017年的时候GENCODE又获得了一批资助,用以完成小鼠基因和人类基因组功能元件的注释工作。
所以GENCODE计划目前的主要工作就是对人类和小鼠的基因组进行功能元件注释。
上文介绍Ensembl的时候也提到过,GENCODE的注释和Ensembl注释的关系是:GENCODE注释来源于havana团队人工完成的基因注释和Ensembl计算机自动完成的基因注释的合并。所以我们查看gtf文件的时候,会发现有“HAVANA"和"ENSEMBL"这两个名称交替出现。HAVANA表示注释来自于人工。ENSEMBL表示注释来源于计算机程序的自动注释。
从GENCODE提供的信息来看,人类一共有58721个基因(包括假基因),目前大概有19940个蛋白质编码基因,16066个长非编码RNA的基因,等等。(如下图)

GENCODE中,小鼠一共有54446,其中有21969个蛋白质编码基因(比人类多),12840个长非编码RNA的基因,等等。(如下图)

GENCODE的注释文件的发行版本和Ensembl是一致的,目前GENCODE中的人类gtf注释已经发布到version 29了,小鼠是发布到version 19版本了
更多想要了解的,可以点击:https://www.gencodegenes.org/

















 518
518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









