







目录
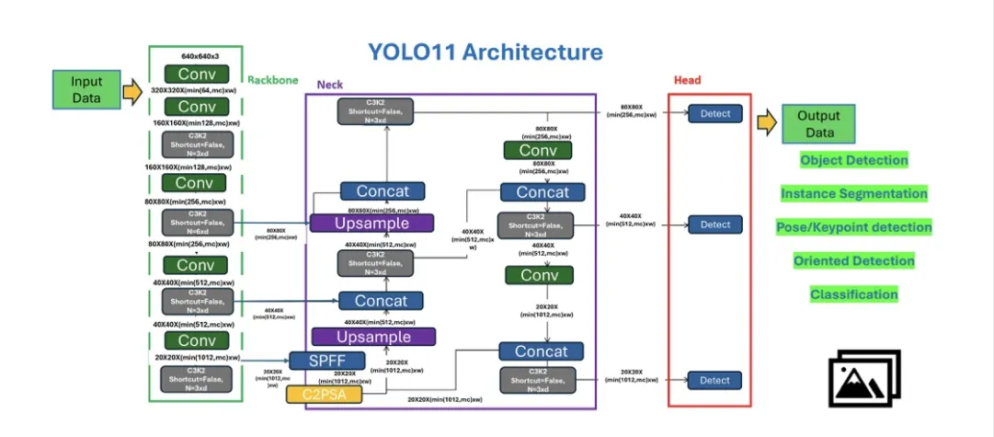
总说YOLO11强大,可强大在何处呢?一篇文章让你看懂YOLO11模型架构如何超越前者。
模型算法下载
在Coovally AI Hub公众号后台回复「模型算法」,即可获取模型下载链接!
C3k2模块:高效特征提取与并行化设计
-
核心作用与结构特点
C3k2模块是YOLO11对传统CSP Bottleneck结构的优化版本,核心目标是通过并行卷积设计和灵活参数配置提升特征提取效率。其结构特点包括:
并行卷积分支:输入特征图被分为两部分, 一部分直接传递(保留浅层特征),另一部分通过多个Bottleneck或C3k模块(可变卷积核)处理深层特征,最终拼接融合。
参数灵活性:支持通过c3k参数选择使用C3k(可变卷积核)或标准Bottleneck,并通过n控制模块重复次数,g控制分组卷积,e调节通道扩展率,实现计算效率与性能的平衡。
-
改进与优势
相比C2f模块:C3k2引入并行卷积层替代单一卷积,减少了冗余计算,提升了推理速度。例如,C3k2使用两个卷积层代替C2f的一个大卷积层,同时通过通道分割策略降低计算复杂度。
多尺度特征融合:通过可变卷积核(如3×3、5×5)扩展感受野,尤其擅长处理大物体和复杂背景场景。
轻量化设计:结合分组卷积(参数g)和通道压缩(参数e),在保持精度的同时减少参数量,适合移动端部署。
-
模块流程图(代码)
Input → Split → [Identity]
→ [Conv3×3 → Bottleneck×n → Conv1×1]
Concatenate → Output-
C3k2模块的数学表达
输入特征图 X∈RC×H×WX∈RC×H×W
分割操作 X1,X2=split(X,dim=C)X1,X2=split(X,dim=C)

SPPF组件:快速空间金字塔池化
-
核心作用与结构特点
SPPF(Spatial Pyramid Pooling Fast)是YOLO系列中用于增强感受野的经典组件,通过多尺度池化融合不同粒度的空间特征:
并行池化操作:输入特征依次通过多个不同尺寸的最大池化层(如5×5),输出拼接后通过卷积融合,捕捉多尺度上下文信息。
计算优化:相较于原始SPP模块,SPPF通过串行重复池化操作(如5×5池化重复3次)减少计算量,同时保持性能。
传统SPP模块需要并行计算多个池化层,而SPPF通过重复使用中间计算结果,将计算复杂度从O(∑kCHWk2)O(∑kCHWk2)降低至O(CHW⋅max(k)2)O(CHW⋅max(k)2),其中kk为池化核尺寸。
-
改进与优势
保留YOLOv8设计:YOLO11沿用了YOLOv8的SPPF结构,未做显著改动,但其后新增的C2PSA模块进一步增强了多尺度特征处理能力。
C2PSA模块:注意力机制与CSP的融合
-
核心作用与结构特点
C2PSA(Cross Stage Partial with Pyramid Squeeze Attention)是YOLO11新增的核心模块,结合CSP结构与注意力机制:
CSP分段处理:特征图被分为两部分,一部分直接传递,另一部分通过PSA注意力模块处理,最终拼接融合。
PSA注意力机制:通过机制动态调整特征来调整不同位置的关注度,增强模型对目标细节的感知,提升复杂场景下的检测精度。
多尺度卷积核:使用3×3、5×5、7×7等卷积核并行提取特征,生成多尺度特征图。
通道加权:通过SE(Squeeze-and-Excitation)机制对通道特征进行动态加权,增强重要通道的响应。
-
改进与优势
相比传统注意力机制:C2PSA通过多尺度卷积和通道加权,显著提升对复杂遮挡物体和关键区域的关注能力,例如在定向物体检测任务中表现突出。
轻量化设计:CSP结构减少了50%的计算量,而PSA机制仅增加少量参数,整体保持了高效性。
-
C2PSA注意力机制(代码)
Input → Split → [Identity]
→ [PSA Block(SE + Pyramid Conv)]
Concatenate → OutputConv2D层的优化
YOLO11中的常规卷积层(Conv2D)主要用于下采样和基础特征提取,其改进包括:
参数调整:在骨干网络中,初始卷积层的步幅(stride=2)和核尺寸(如3×3)优化了特征图的下采样效率,减少信息丢失。
与模块协同:Conv2D与C3k2、C2PSA等模块配合,形成层次化特征提取流程。例如,骨干网络通过多次Conv2D下采样后,由C3k2模块处理不同尺度的特征。
-
下采样策略改进

-
深度可分离卷积应用
在检测头引入深度可分离卷积(DWConv),计算复杂度从O(CinCoutK2HW)O(CinCoutK2HW)降为O(CinK2HW+CinCoutHW)O(CinK2HW+CinCoutHW)参数量减少约22%。
Coovally AI模型训练与应用平台
Coovally AI模型训练与应用平台整合了30+国内外开源社区1000+模型算法。
包含YOLO系列下的所有模型,无需配置环境、修改配置文件等繁琐操作,可一键另存为我的模型,上传数据集,即可使用YOLO11等热门模型进行训练与结果预测,全程高速零代码!而且模型还可分享与下载,满足你的实验研究与产业应用。
总结:YOLO11的架构创新
YOLO11通过C3k2的并行特征工程、SPPF-C2PSA级联优化、硬件感知的Conv2D设计三大创新,在目标检测的帕累托前沿(Pareto Frontier)上实现突破。
C3k2模块:并行卷积与灵活参数配置,平衡速度与精度。
SPPF组件:保留高效多尺度池化,为后续模块提供丰富特征。
C2PSA模块:注意力机制与CSP结合,增强关键区域关注。
Conv2D优化:基础卷积层与高级模块协同,提升整体特征提取效率。
与YOLOv8相比,YOLO11的检测精度提升约15%,推理速度加快20%,尤其适用于实时场景和复杂背景任务。为实时视觉系统树立了新的技术标杆。



















 443
443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









