







资源链接:
链接:https://pan.baidu.com/s/1HXCSOarJSSSI7qBWO_ZbEQ?pwd=xg77
提取码:xg77传送门:
预后模型模块化代码分享(1):数据读取与整理
预后模型模块化代码分享(2):Lasso-COX回归分析
预后模型模块化代码分享(4):nomogram-ROC曲线-DCA决策曲线
废话不多说,直接开始,打开Auto_riskScore_plot.R,首先处理上一个脚本中传递的数据,根据第一篇脚本中输入的时间类型自动处理生存时间,计算危险分数百分位:
if (max(sur$status)>1) {
sur$status <- sur$status-1
}
if (time_type == "days") {
data_risk$sur_time <- sur$days_to_death/365
}
if (time_type == "month") {
data_risk$sur_time <- sur$days_to_death/12
}
data_risk$status <- sur$status
data_risk$id <- row.names(data_risk)
k <- length(data_risk)
data_risk <- arrange(data_risk,riskScore)
row.names(data_risk) <- data_risk$id
data_risk <- data_risk[,1:k]
q <- length(row.names(data_risk))
s <- 100/q
i <- 1
precent <- 1
while (i<=q){
precent[i] <- i*s;
i <- i+1
}
}
随后将precemt转为分组的变量risk_group,并利用grid包绘制拼接的散点图和生存时间分布图
data_risk$precent <- precent
dat1 <- data_risk[data_risk$precent <= 50,]
dat2 <- data_risk[data_risk$precent > 50,]
dat3 <- data_risk[data_risk$status==0,]
dat4 <- data_risk[data_risk$status==1,]
data_risk <- within(data_risk,{ ##gourp precent data
risk_group <- NA
risk_group[precent <= 50] <- 1
risk_group[precent >50] <- 0
})
tiff(file="KM_Risk_score.tiff",width = 15,height = 15,units ="cm",compression="lzw",bg="white",res=300)
fit <- survfit(Surv(sur_time, status) ~ risk_group, data = data_risk)
diff <- survdiff(Surv(sur_time,status) ~ risk_group,data = data_risk,rho = 0)
res <- ggsurvplot(fit,data = data_risk,pval = T,
legend.title = "risk score",
legend.labs = c("high risk score","low risk score"),
risk.table = F, # Add risk table
linetype = "strata", # Change line type by groups
ggtheme = theme_bw(), # Change ggplot2 theme
fun = "pct") # Reverse plot
res$plot <- res$plot + labs(title = "Survival Curve of Risk score",x="Time (years)")+
theme(plot.title = element_text(hjust = 0.5))
res
dev.off()
data_risk$status <- as.factor(data_risk$status)
tiff(file="plot_risk.tiff",width = 15,height = 15,units ="cm",compression="lzw",bg="white",res=300)
layout_1 <- grid.layout(nrow = 3, ncol = 1, heights = c(1,4.5,4.5))
pushViewport(viewport(layout = layout_1))
grid.text("Risk score(AP) for muti-cox analysis", x = 0.5, y = 0.95, gp = gpar(col = "black", fontsize = 15)) # ???ӻ???????
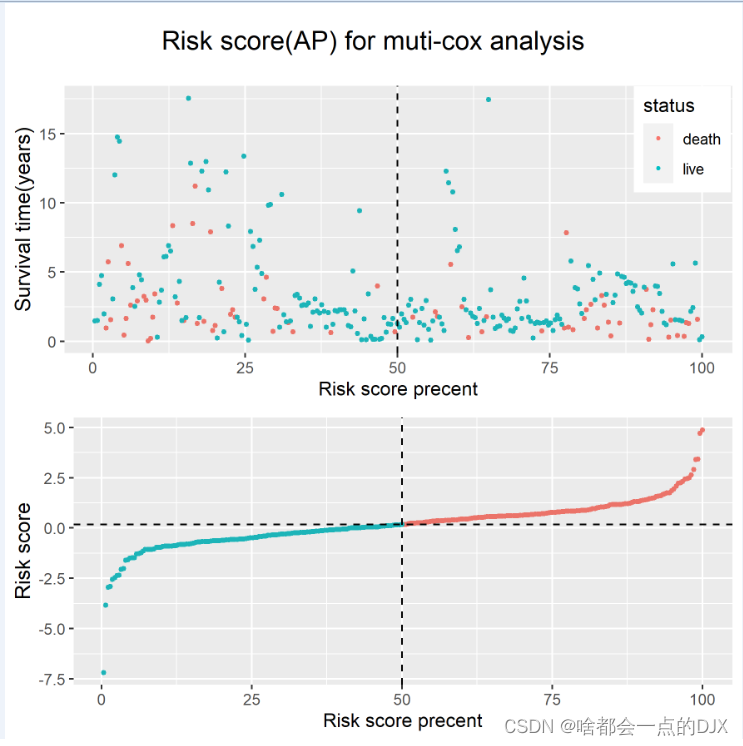
plot1 <- ggplot(data_risk,aes(x=precent,y=sur_time,color=status)) +
geom_point(cex=0.8)+
geom_point(data=dat4,aes(x=precent,y=sur_time),colour="#EB7369",cex=1) +
geom_point(data=dat3,aes(x=precent,y=sur_time),colour="#1CB4B8",cex=1) +
labs(y = "Survival time(years)",x="Risk score precent")+
theme(axis.title.y = element_text(size=12),legend.position = c(0.925,0.8))+
scale_color_discrete(labels=c("death","live"))+
geom_vline(aes(xintercept=50),linetype="dashed")
plot2 <- ggplot(data_risk,aes(x=precent,y=riskScore)) +
geom_point(cex=0.5)+
geom_point(data=dat2,aes(x=precent,y=riskScore),colour="#EB7369",cex=1) +
geom_point(data=dat1,aes(x=precent,y=riskScore),colour="#1CB4B8",cex=1) +
labs(y = "Risk score",x="Risk score precent")+
theme(axis.title.y = element_text(size=12))+
geom_vline(aes(xintercept=50),linetype="dashed")+
geom_hline(aes(yintercept=median(data_risk$riskScore)),linetype="dashed")
print(plot1, vp = viewport(layout.pos.row = 2, layout.pos.col = 1))
print(plot2, vp = viewport(layout.pos.row = 3, layout.pos.col = 1))
dev.off()
rm(plot1,plot2,dat1,dat2,dat3,dat4,layout_1)
从上图可以看出,危险分数越大的样本,生存时间越短,这里以年为单位,所以一开时输入的天被转换为了年
最后绘制危险分数热图:
l <- length(data_risk)-6
data_heat <- data_risk[,1:l]
an_risk <- subset(data_risk,select=c("risk_group"))
row.names(an_risk) <- row.names(data_heat)
an_risk[an_risk==1] <- "low risk score"
an_risk[an_risk==0] <- "high risk score"
colnames(an_risk) <- c("group")
data_heat <- as.data.frame(t(data_heat))
ann_colors = list(group = c("high risk score"="#ff9289","low risk score"="#00dae0"))
tiff(file="risk_heapmap_risk.tiff",width = 16,height = 12,units ="cm",compression="lzw",
bg="white",res=300)
pheatmap(data_heat,scale = "row",show_colnames = F,annotation_col = an_risk,annotation_colors = ann_colors,
cluster_cols = F,cluster_rows = F,color = colorRampPalette(c("navy", "white", "firebrick3"))(50))
dev.off()
rm(data_heat,an_risk,ann_colors)
rm(diff,fit,res)
欢迎各位读者批评指正!
















 341
341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











