







BEV视角是什么
BEV视角就是鸟瞰图又称为上帝视角。相当于人眼俯视看桌子,每一个物体都是三维的,例如铅笔盒或者橡皮擦,但是你又能明确的看出两者之间的遮挡关系(橡皮擦在铅笔盒后面多远)这就相当于鸟瞰图。如果单纯的3D视角进行遮挡你无法确定后面是有什么东西,如果俯视看,你又无法确定他们的高度,所以BEV视角在解决3D分割等问题中具有很大的优势,具体如下:
- 可以直观地展示汽车周围环境
- 避免图像视角下的尺度(scale)和遮挡(occulsion)问题,可以有效识别有遮挡或交叉交通的情况
- 有利于后续规划控制模块的开发
特征融合过程中可能遇到的问题
- 自身运动补偿:车载运动,不同时刻之间的特征需要对齐
- 时间差异:不同传感器可能具有时间差,要对齐这部分信息
- 空间差异:最后肯定要映射到同一坐标系,空间位置特征也要对齐
- 不依赖传感器的参数(latent variable)
BEV特征空间可以得到什么
- 相当于我们在上帝视角下重构了一个特征空间,空间的大小我们自己定义(特征空间中的点不是一个数值而是一个特征,对于特征空间中的每一个点需要从不同特征图中所有的点提取特征后计算)
- 特征空间相当于一个网络,网络的间隔也可以自己定义,对应的精度也会由差异
- 在特征空间中我们可以以全局的视角来进行预测,特征都给你了。
BEVformer
模型学习如何将特征从图像坐标系转换到BEV坐标系。

此时为模型的主要操作流程,多个摄像头图片通过主干网络得到不同视角下的特征图。于此同时我们保留t-1时刻的BEV特征。对于每一个编码器结构,我们首先采用BEV query通过时间自注意力机制与前一时刻的BEV特征进行交互,之后我们在通过空间交叉注意力机制提取多个特征图的信息,通过全连接层之后得到一个细化后的BEV特征,但此时的BEV特征仍然不是一个完整的情况,我们需要经过6个迭代的编码器结构才能得到一个完整的处于t时刻的BEV特征。此时的BEV特征可以用于3D的目标检测和图像分割。
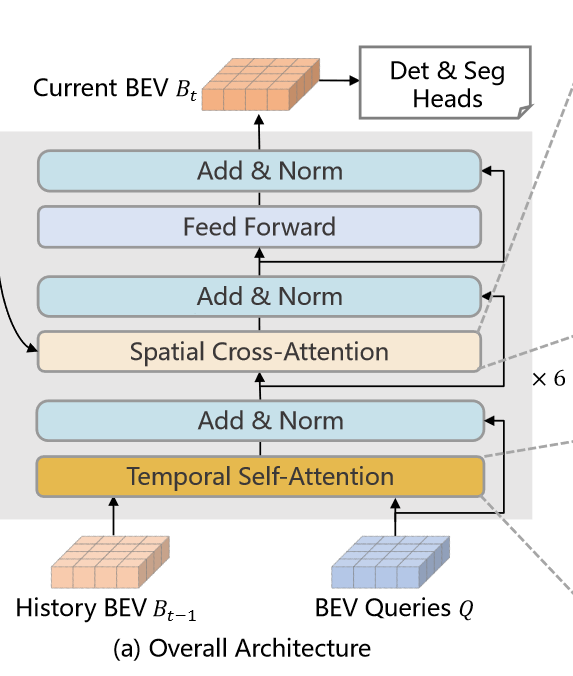 图1 BEVFormer主干部分 图1 BEVFormer主干部分
|
 图2 Transfomer主干部分 图2 Transfomer主干部分
|
如图所示BEVFormer中有六个编码层结构,与Transformer的结构类似,但是新建立了三个特殊的结构分别为:BEV Queries,spatial cross-attention,temporal self-attention结构。
BEV Query

如图所示BEV Query本身是一个栅格化的可学习参数
Q
∈
R
H
×
W
×
C
Q\in R^{H\times W\times C}
Q∈RH×W×C,其中H,W分别代表BEV空间形状,每个网格中的数据并不是一个固定的数值,而是一个向量,用来去计算该点所处位置BEV平面的特征信息。每个网格的大小对应真实世界上的距离为s,且BEV特征空间的中心对应自车系统的位置。同时与Transformer类似,在输入到BEVFormer之前,我们也增加了一个位置编码信息。
空间交叉注意力机制

如果采用多头注意力机制会造成巨大的计算量,因此在可变形注意力机制上,该文提出了空间交叉注意力机制。每个BEV Query只和感兴趣区域进行交互。
如上图所示,我们将维度为C的查询向量形成一个柱状图,在柱状图上进行采样,并且将采样形成的点投影到2D平面上。对于每一个BEV 查询来说,投影得到的2D坐标点并不一定会落在每一个特征图上。我们将具有投影点的特征图称为 V h i t V_hit Vhit。与可变形注意力机制一样,我们将投影点作为参考点,并且在投影点周围采样用于更新BEV Query以及特征图信息。
针对于投影点,我们计算真实世界坐标系下的二维平面,并且在z轴上进行多个采样,生成3D的参考点,在经过相机自带的投影矩阵形成2D的参考点。
时间自注意力机制

时间自注意力机制通过融合历史的BEV特征,可以用于表达当前的环境特征,在用于推测运动物体的速度和检测静态图片中被遮挡的物体而言都很有用。
对于t-1时刻的BEV特征和当前时刻(未计算)的BEV特征,我们首先进行对齐处理得到
B
t
−
1
′
B_{t-1}^\prime
Bt−1′,但是针对于t-1时刻到t时刻运动物体会出现各种的偏移,人工设计不同时刻的偏差工作量大,且精度较低。因此本文采用了可变形注意力机制,通过Q与
B
t
−
1
′
B_{t-1}^\prime
Bt−1′联合预测偏差,在t-1时刻上的BEV特征中根据偏差在参考点周围进行采样,获取当前时刻的信息。与单纯的堆叠BEV特征而言效果更好。















 1202
1202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









