







 本文介绍了一种通过模拟探索学习,增强机械臂操作策略鲁棒性的方法。Value-UCL算法有效发现故障并训练恢复技能,实验证明了在仿真与真实环境中显著提高任务成功率。关键在于PessimisticDiscovery和EarlyTermination策略,以及符号技能图的使用。
本文介绍了一种通过模拟探索学习,增强机械臂操作策略鲁棒性的方法。Value-UCL算法有效发现故障并训练恢复技能,实验证明了在仿真与真实环境中显著提高任务成功率。关键在于PessimisticDiscovery和EarlyTermination策略,以及符号技能图的使用。
Efficiently Learning Recoveries from Failures Under Partial Observability
【背景】
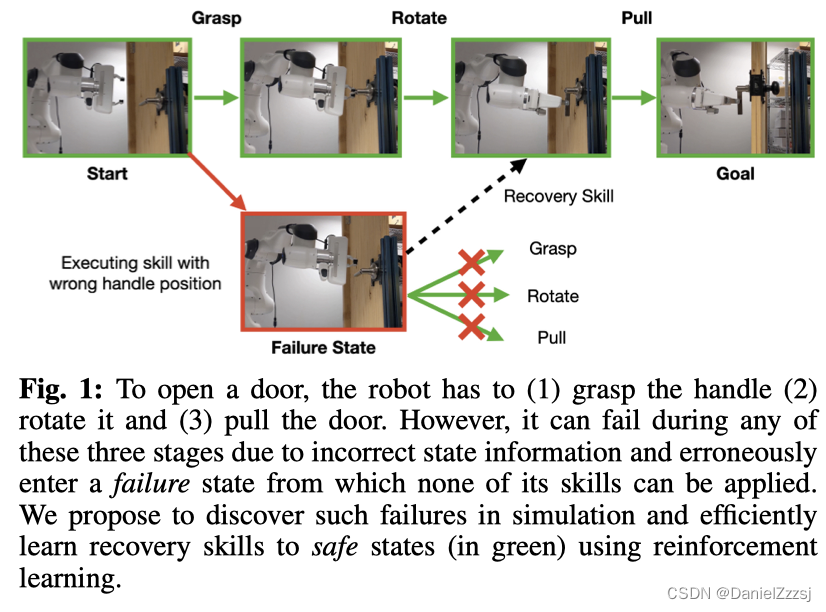
在现实条件下,由于部分可观测性可能导致各种各样的失败。在实际上,状态很少是完全已知的,而是使用在线状态估计模块进行估计。机器人在执行任务时,由于状态和驱动中的噪音而犯错是很常见的。机器人可能在执行过程中出错,并进入未经训练的状态—故障状态。如下图1所示,机器人在试图打开门时,可能会因为错误的把姿态估计导致没有握住把手。
在实践中,此类错误通常通过手工设计或启发式行为和状态机来处理。这类解决方法对于受控环境中相对简单的任务是可行的。使用启发法来选择恢复的位置,该方式生成的恢复可能是次优的,因为并不考虑恢复的质量。例如,一种常见的启发式方法是在检测到故障时恢复到以前的状态。这类方法并不广泛适用在现实世界中部署的系统,如需要大量接触的顺序操作任务:开门和组装家具,因为可能会以各种不同的方式失败。因此,需要一种算法方法来(1)发现潜在故障,(2)在发现新故障时不断改进机器人。通过发现模拟中的潜在故障,并使机器人学习能够从这些故障中恢复的恢复技能(recoveries skill),逐步提高机器人对部分可观测性的鲁棒性。
演示视频链接:https://sites.google.com/view/recoverylearning/home
【主要工作】
为了解决背景中的问题,本文提出了一种通用方法,以样本有效的方式增强操纵策略的鲁棒性。本文的方法在模拟中进行探索,首先发现当前策略的故障模式,然后学习处理这些故障的额外的恢复技能,从而逐步提高稳健性。为了确保学习的有效性,本文提出了Value Upper Confidence Limit(Value-UCL),该算法可以选择要优先考虑的故障模式以及要恢复到的状态,以便在每次培训中最大限度地提高预期性能。
本文解决操作任务定义为起始状态 D D D,目标函数 f g o a l : S → { 0 , 1 } {}_{f_{goal} : S\rightarrow \{0,1 \}} fgoal:S→{0,1} 。机器人会根据其动作产生成本 c ( s , a ) c(s,a) c(s,a)以及一个 c f a i l c_{fail} cfail如果陷入死胡同或者无法在 T T T时间步内完成任务。给定一组控制策略 { π 1 , ⋅ ⋅ , π k } \{π_1,··,π_k\} {π1,⋅⋅,πk}和一个高级策略 Π \Pi Π可以在控制策略中进行选择。如下公式,将最大化在任务分布上高级策略 Π \Pi Π的期望回报。
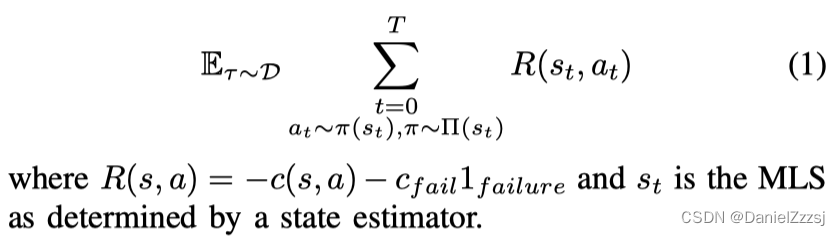
本文提出两种故障发现策略:(1)Pessimistic Discovery(2)Early Termination。其中,Pessimistic Discovery指的是机器人在模拟的状态高度不确定性下开环执行其nominal skill。该策略发现了比实际执行过程中遇到的数量更多、种类更多样化的故障。虽然这使得恢复学习的计算成本更高,但它不需要状态估计器的模型。Early Termination,机器人使用模拟状态估计器的观测值执行其nominal skill,如果没有满足任何先决条件,则终止。该策略可以发现更准确的故障分布,如果状态估计器模型可用时则更适合。
本文构建了一个紧凑的符号技能图 G = ( V , E ) G=(V, E) G=(V,E),而不是直接用低层真实状态(高维)进行推理。该图中的每个顶点都是一个符号化的状态。如果有一个技能的前提包含 u u u,并且它的效果包含在 v v v中,则在两个顶点 u , v ∈ V u, v∈ V u,v∈V之间存在一条边。我们将这个图初始化为一个链,其中顶点 V = { ρ 1 , ⋅ ⋅ , ρ k , ρ g o a l } V={\{ρ_1,··,ρ_k,ρ_{goal}}\} V={ρ1,⋅⋅,ρk,ρgoal}与边 E E E分别对应nominal skill的前提条件、nominal policies。这些顶点为安全状态,因为它们被nominal policies覆盖。学习这种符号表示法的主要优点包括能够在抽象层次上进行计划,并根据与符号的距离使用先决条件分类器定义密集的奖励函数。
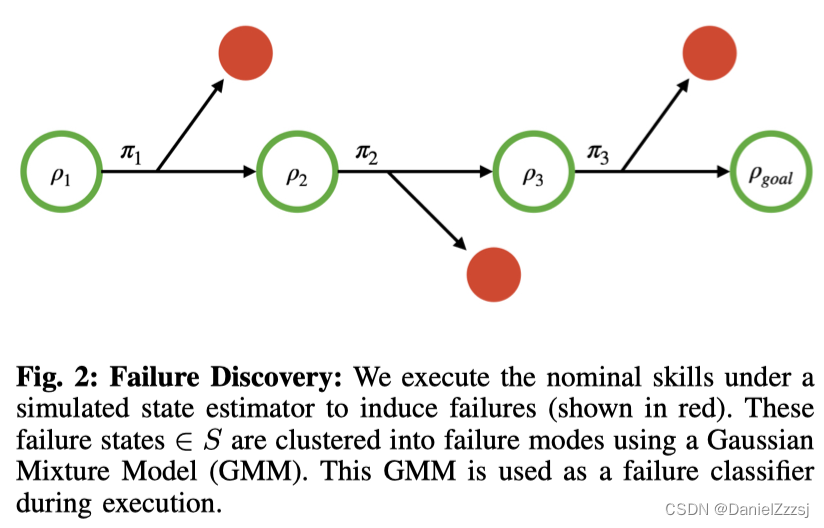
如图2所示,本文通过在模拟状态估计模型下执行策略,在模拟中发现故障。然后,使用高斯混合模型(Gaussian Mixture Model, GMM)对相似的故障进行聚类。而后,学习每个簇(聚类)的恢复技能,使机器人能够恢复到安全状态。每个簇都有多个潜在的恢复,每个恢复都对应一个安全状态,那么基于n个故障簇m个安全状态总计共有n×m个潜在恢复技能。
如下图3,乐观的恢复学习图,$\rho{f}_{1},\rho{f}{2} 分 别 是 两 个 最 初 与 任 何 安 全 状 态 无 关 的 故 障 模 式 , 任 何 回 复 的 成 功 率 分别是两个最初与任何安全状态无关的故障模式,任何回复的成功率 分别是两个最初与任何安全状态无关的故障模式,任何回复的成功率q{ij} 均 为 0 。 在 恢 复 学 习 开 始 时 , 故 障 模 式 均为0。在恢复学习开始时,故障模式 均为0。在恢复学习开始时,故障模式V(\rho{f}_{i})=-c_{fail}$。随着训练持续进行,$V(\rho{f}{i})=max_jq{ij}V(\rho_{i})-c_{fail} 提 高 。 提高。 提高。V(\rho_{i}) 表 示 n o m i n a l s k i l l 可 以 在 表示nominal skill可以在 表示nominalskill可以在\rho_{i}$可靠的执行。综上,定义如下失败值公式(Failure Value, FV),直观地看高故障值意味着执行过程中的故障问题较少,因为机器人对恢复非常有信心。
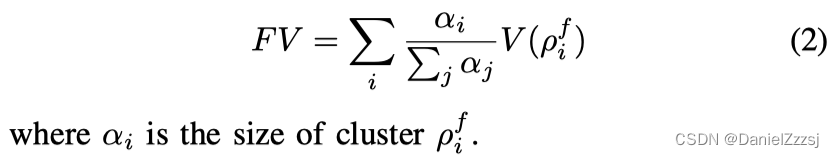
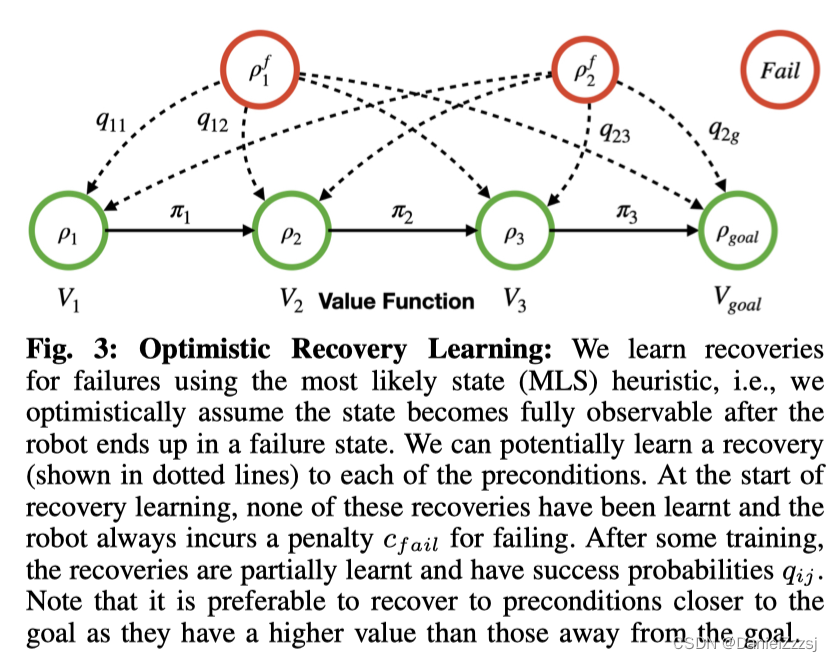
Value-UCL的核心思想是基于所有恢复的成功率 q i j q_{ij} qij的变化率 △ q i j \bigtriangleup q_{ij} △qij计算和使用其乐观上届 △ q i j U \bigtriangleup q^{U}_{ij} △qijU。这可以提供一个乐观的估计,即在一轮训练后,恢复可以改善多少。

【实验】
本文使用上述方法学习开门的恢复技能,并在模拟与一些微调的真实机器人上进行评估。任务目标是在初始状态高度不确定性下,用Franka Panda机器人打开门至少0.3 rad。关于仿真环境,基于MuJoCo框架构建。世界状态是18维的,包括机器人的关节角度以及门和把手的姿势。不确定的初始状态从门把手的x、y和z位置的N中进行采样。
作者将REACHANDGRASPHANDLE, ROTATEHANDLE, PULLHANDLE定义为nominal skill。每项技能都由机器人使用任务空间阻抗控制(impedance control)到达的一个或多个7D路点组成,其中每个目标都由一个夹持器打开/关闭状态和一个6D末端执行器姿势组成。如果有准确的状态信息,这些技能能够在模拟和现实世界中打开门,且成功率为100%。符号技能图:作者使用1223个正负样本,通过先决条件链来训练nominal skill的先决条件。每个先决条件都是一个生成性分类,正分布 D + D+ D+学习为高斯分布,负分布 D − D− D−学习为高斯混合模型。这3种nominal skill产生了4个符号,分别表示开始、子目标和目标。每个恢复技能π都是一种参数化技能,基于开始状态s使用回归模型预测机器人动作θ。本文使用k近邻回归预测21D向量,即与初始末端执行器姿势和抓取器打开/关闭状态相关的三个6D姿势序列,作为机器人动作。
作者为故障发现执行了1000次nominal skill,以收集总计1400个故障状态,并使用高斯混合模型(GMM)将其分为6个簇。常见的故障模式包括:(1)机器人丢失手柄(2)机器人因抓取不当导致在拉动手柄时打滑等。仅通过150个REPS(Relative Entropy Policy Search)查询在模拟中学习恢复技能。共24种潜在的恢复技能,这意味着每个恢复策略平均只能获得6个数据点。
本文通过假设每个机器人动作后噪声分布的标准偏差减半来模拟状态估计器。如表一所示,在提高成功率方面,学会的恢复比启发式恢复策略要好得多。从开门过程中的故障中恢复通常需要机器人(1)小心地移动把手,以免削弱抓力(2)避免与环境碰撞。启发式恢复无法实现这一点,所以表现不佳。与开环执行相比,本文的方法大大提高了任务成功率,从71%提高到92.4%。这表明(1)使用Pessimistic Discovery确实涵盖了机器人在使用状态估计器时遇到的许多实际故障(2)通过使用先决条件定义的通用奖励函数可以可靠地学习恢复。
进一步,将在模拟中学习到的前置条件、故障分类、标称技能和恢复技能转移到一个真正的Franka Panda机器人。如下图所示,五种不同的门把手以及一个全尺寸的门。在训练中只使用了门把手1与一个小尺寸的门,门把手2-5以及全尺寸门是未见过的。OPEN-LOOP的成功率对手柄敏感从50−80%,相比之下,尽管恢复只针对门把手1进行了训练,却将成功率提高到80−90%。 但是,由于光滑的圆柱形把手,不论是open loop还是恢复在全尺寸门上都表现不佳。

作者将round-robin与本文提出的Value-UCL进行对比,如图6所示使用5种不同种子进行了比较。我们使用α=0.95来计算置信区间,窗口大小w为3,并在每轮中查询一个新数据点的REPS,即η=1。Value-UCL用于从第41至100回合中选择要学习的恢复。它不仅比round-robin提高得更快,而且在所有试验中都会收敛到更好的失败值(FV)。在3/5次试验中,相比于round-robin,Value-UCL仅使用了训练预算的70%实现了最佳FV,即提前1小时。这表明它可以更好地利用训练资源来提高鲁棒性。

【个人总结】
在机械臂的应用场景下,本文提出了一个可扩展的算法框架,可以有效地增强给定的操作策略的鲁棒性,防止因状态不确定性而导致的故障。提出了故障发现的策略,并使用高斯混合模型聚类。提出了一种有效的恢复学习算法Value-UCL,它可以选择要学习的恢复,从而使故障状态的预期值提高最多,进而提高任务的预期回报。最后,分别测试了算法在模拟与真实场景下的表现。在表二真实机器人测试结果中,测试次数较少,感觉不具有很强的说服力。


















 1444
1444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









