






Datawhale干货
作者:郑程睿,算法工程师
最近,具身智能的概念很火。
不论是这几天稚晖君开源人形机器人全套图纸+代码,引发圈内热议。
还是各类具身智能产品,如李飞飞的 Voxposer、谷歌的 RT1 和 RT2、谷歌的 RTX、字节跳动的 Robot Flamingo、斯坦福的 ACT 和卡耐基梅隆的 3D_diffuser_act,均在不同任务和场景中展示了强大的能力,并有潜力带来革命性的变革。
那什么是具身智能呢?它又有什么用?
一文带你了解。
本文拆分为上下两篇,明天会更新下篇,聚焦人机交互、发展讨论。
本文部分参考中国信息通信研究院和北京人形机器人创新有限公司的《具身智能发展报告》
具身智能基本概念
具身智能,即“具身+智能”,是将机器学习算法适配至物理实体,从而与物理世界交互的人工智能范式。以 ChatGPT 为代表的“软件智能体”(或称“离身智能体”)使用大模型通过网页端、手机 APP 与用户进行交互,能够接受语音、文字、图片、视频的多种模态的用户指令,从而实现感知环境、规划、记忆以及工具调用,执行复杂的任务。在这些基础之上,具身智能体则将大模型嵌入到物理实体上,通过机器配备的传感器与人类交流,强调智能体与物理环境之间的交互。
通俗一点讲,就是要给人工智能这个聪明的“头脑”装上一副“身体”。这个“身体”可以是一部手机,可以是一台自动驾驶汽车。
而人形机器人则是集各类核心尖端技术于一体的载体,是具身智能的代表产品。
具身智能的三要素:本体、智能、环境
具身智能的三要素:“本体”,即硬件载体;“智能”,即大模型、语音、图像、控制、导航等算法;“环境”,即本体所交互的物理世界。本体、智能、环境的高度耦合才是高级智能的基础。
不同环境下的会有不同形态的硬件本体以适应环境。比如室内平地更适用轮式机器人,崎岖不平的地面更适用四足机器人(机器狗)。在具身智能体与环境的交互中,智能算法可以通过本体的传感器以感知环境,做出决策以操控本体执行动作任务,从而影响环境。在智能算法与环境的交互中还可以通过“交互学习”和拟人化思维去学习和适应环境,从而实现智能的增长。

具身智能的四个模块:感知-决策-行动-反馈
一个具身智能体的行动可以分为“感知-决策-行动-反馈”四个步骤,分别由四个模块完成,并形成一个闭环。
感知模块
感知模块负责收集和处理信息,通过多种传感器感知和理解环境。在机器人上,常见的传感器有:
1. 可见光相机:负责收集彩色图像。
2. 红外相机:负责收集热成像、温度测量、夜视和透视。红外相机能够检测物体发出的热辐射,即使在完全黑暗的环境中也能生成图像。这种能力使得红外相机适用于夜视和热成像。红外相机可以测量物体表面的温度,广泛应用于设备过热检测、能源审计和医学成像等领域。某些红外相机能够穿透烟雾、雾气和其他遮挡物,适用于应急救援和安全监控。

3. 深度相机:负责测量图像中每个点与相机之间的距离,获取场景的三维坐标信息。

4. 激光雷达(LiDAR):负责测量目标物体的距离和速度。通过发射激光脉冲并接收反射回来的光来计算与物体的距离,生成高精度的三维点云数据,广泛应用于自动驾驶和机器人导航。

5. 超声波传感器:负责避障。通过发射超声波脉冲并接收这些脉冲的反射来确定机器人与障碍物之间的距离,判断障碍物是否存在。

6. 压力传感器:负责测量机器人手或脚部的压力,用于行走和抓取力的控制以及避障。

7. 麦克风:负责收音。

此外,根据不同应用场景,还可以使用一些特定的传感器实现特定功能。例如,电子鼻可以检测气体,应用于防爆和环境监测场景;湿度传感器可以应用于农业机器人和室内环境控制。环境理解在通过传感器获取环境信息后,机器人需要通过算法理解环境。在一些空间和场景相对稳定可控的环境中,算法并不需要强泛化能力,因此只需要针对特定场景的模型。例如,可以使用YOLO进行目标检测,使用SLAM实现导航和定位。而对于多变和陌生的场景,算法需要强泛化能力,因此需要使用多模态大模型,将声音、图像、视频、定位等多种环境信息融合并进行判断。后续章节将详细讨论这一点。
决策模块(大模型)
决策模块是整个具身智能系统的核心,它负责接收来自感知模块的环境信息,进行任务规划和推理分析,以指导行动模块生成动作。在早期的技术发展中,决策模块主要依赖于人工编程的规则判断和专用任务的算法设计。然而,这些定制化的算法很难应对动态变化的环境和未知情况。基于近端策略优化算法(Proximal Policy Optimization, PPO)和Q-learning算法的强化学习方法在具身智能自主导航、避障和多目标收集等任务中展现出更好的决策灵活性。然而,这些方法在复杂环境的适应能力、决策准确度和效率方面仍存在局限。
大模型的涌现,极大地增强了具身智能体的智能程度,大幅提高了环境感知、语音交互和任务决策的能力。相较于“软件智能体”的AIGC(AI-generated Content),即由大模型生成文字、图片等内容,调用的工具是函数;具身智能体的大模型是AIGA(AI-generated Actions),即由大模型生成动作,调用的工具是机械臂、相机等身体部件。在多模态的视觉语言模型(Vision Language Model, VLM)的基础上,具身智能的大模型的发展方向是视觉语言动作模型(Vision Language Action Model, VLA)和视觉语言导航模型(Vision Language Navigation Model, VLN)。
VLA:输入是语言、图像或视频流,输出是语言和动作。在一个统一的框架内融合了互联网、物理世界以及运动信息,从而实现了从自然语言指令到可执行动作指令的直接转换。
VLN:输入是语言、图像或视频流,输出是语言和移动轨迹。针对导航任务中的语言描述、视觉观测对象以及运动轨迹等多个阶段的任务需求,VLN用于统一的指令输入框架,使得大模型可以直接生成运动方向、目标物体位置等操作信息。
近年来,诸如VoxPoser、RT-2和Palme等初期的VLA模型,以及NaviLLM这样的VLN模型已展示出令人期待的能力。在面向未来的发展中,多模态大模型与世界模型(World Model)的结合可以实现感知预测,即模拟环境中的动态变化。3D-VLA在此基础上进一步整合了三维世界模型的模态,能够预演环境动态变化及其对行动结果的影响。随着多模态处理技术的发展,具身智能系统将能够融合语言、视觉、听觉、触觉等多种感官信息,从而更自动化地理解指令并增强任务泛化能力。也许在具身智能大模型发展的最终阶段,一个具备感知-决策-执行的端到端大模型将孕育而生。它如同融合了人类的大脑和小脑,将原本不同模块的功能融合至一个统一的框架下,能够直接推理语言回复、精细动作、自主导航、工具使用以及与人协同合作,从而实现低延时和强泛化。
行动模块
行动模块是具身智能系统中的“执行单元”,负责接收来自决策模块的指令,并执行具体的动作。行动模块的主要任务包括使用导航定位算法实现移动,以及使用控制算法操纵机械臂等身体元件实现物体操作。例如,导航任务需要智能体通过移动来寻找目标位置,而物体操作和交互则涉及对环境中物体的抓取、移动和释放等动作。在行动模块中,实现精细的动作控制是一个重要的挑战。行动模块如何响应决策模块的指令并生成动作,具体实现可以分为以下三种方式:
1. 决策模块(大模型)调用预编动作算法:
导航定位算法通过在事先建好的地图和点位上实现移动。
机械臂等身体元件通过预编好的控制算法执行特定动作。
这种方式的优点在于动作的可控性强。在与真实物理世界交互的过程中,动作生成的容错率低,由模型推理的动作一旦出错可能会造成巨大损失。这种方式的缺点在于算法开发量大,且泛化能力弱,难以将动作迁移至新环境中。
2. 决策模块(大模型)与动作算法协同工作:使用视觉语言模型(VL)读取行动模块的实时视频流,从而指导导航与控制算法生成动作。例如:
在执行导航任务时,将Rviz显示的地图视频流与相机捕捉的实时视频流输入至VL中,结合用户语言指令,指导导航系统移动。
在执行物体操作任务时,将机械臂上的相机的实时视频流输入至VL中,结合用户语言指令,指导控制算法操作机械臂完成精准抓取等任务。
这种方式使得机器人能够在与环境的交互中不断输入新的环境信息,以不断优化决策和行动,增强行动的泛化性。然而,这种方式对数据吞吐量和算力是一个挑战。
3. 决策模块(大模型)与行动模块的融合:如上所述,未来的发展方向将是使用VLA(Vision Language Action Model)和VLN(Vision Language Navigation Model)这样的端到端具身智能大模型直接推理动作。这种模型将互联网知识、物理世界概念与运动信息融合到统一框架中,能够直接依据自然语言描述生成可执行的动作指令,传入执行器中。这种方式将决策、行动甚至是感知逐渐融合,使行动模块的能力和灵活性进一步提高,从而使具身智能系统在各种应用场景中发挥更大的作用。
以上三种方式从上到下,随着技术的不断进步,将决策、行动甚至是感知逐渐融合,使行动模块的能力和灵活性不断提高,从而使具身智能系统在各种应用场景中发挥更大的作用。
反馈模块
反馈模块通过多层交互不断接收来自环境的反馈经验并进行调整和优化。具体来说,反馈模块分别反馈上述的感知、决策、行动模块。以提高对环境的适应性和智能化水平。
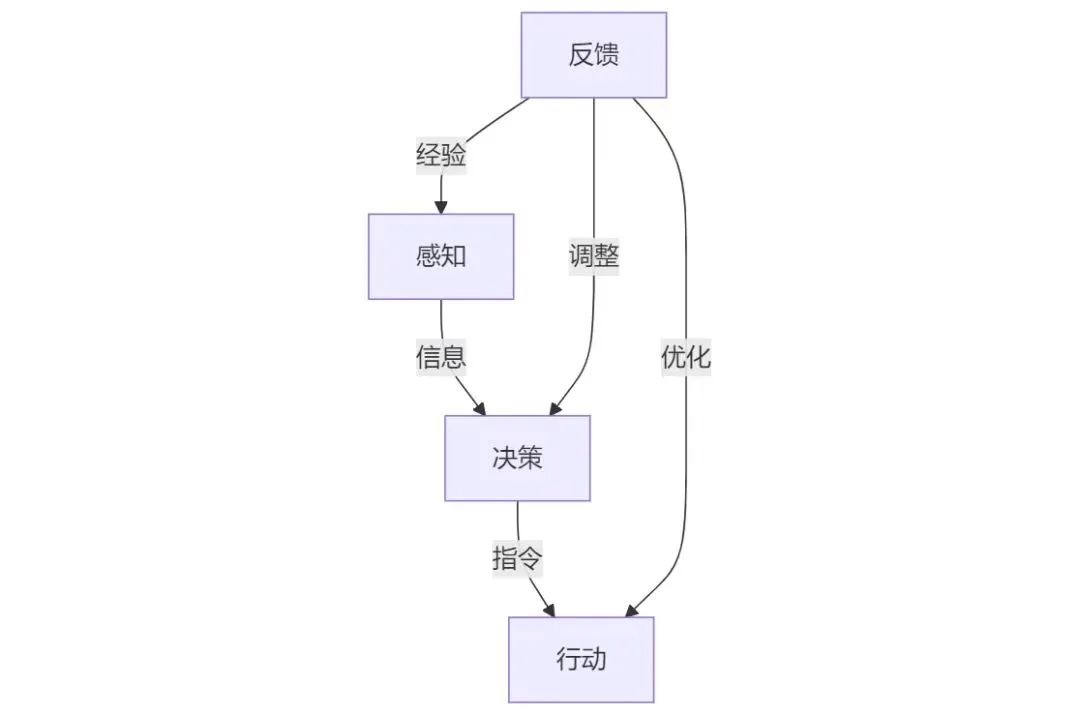
1. 反馈感知模块:反馈模块通过提供持续的反馈,增强了感知模块对实时环境数据的敏感度。这包括但不限于图像、声音、压力和触感等多模态数据,使得感知模块能够更加精准地捕捉和响应环境变化。
反馈模块将感知模块先前捕获的环境信息视为“经验”或“记忆”,并将这些信息作为“提醒”重新输入到感知模块中。例如,在人机对话的场景中,如果感知模块识别到一个新用户,即一个尚未建立用户习惯档案的个体,或者是一个已经存在于记忆中的老用户,即一个已经拥有熟悉操作流程的用户,反馈模块会将这些识别信息反馈给感知模块。这一过程模拟了人类在遇到陌生人或熟人时的自然反应,从而使得感知模块能够根据用户的不同身份和历史交互数据,调整其感知和响应策略,以提供更加个性化和适应性的服务。
2. 反馈决策模块:反馈模块通过提供持续的任务完成度、用户指令的反馈。决策模块利用这些反馈进行自我优化,调整其算法的参数。通过这种闭环反馈机制,决策模块能够不断学习和适应,提高对环境的适应性和智能化水平。
例如,在自动驾驶的决策规划控制技术中,反馈模块的作用是对感知到的周边物体的预测轨迹的基础上,结合无人车的路由意图和当前位置,对车辆做出最合理的决策和控制。
3. 反馈行动模块:反馈模块通过感知模块获取环境变化信息,并将这些信息反馈给决策模块。决策模块根据反馈信息灵活调整动作,确保执行器在多变的环境中能够调整运动轨迹、力量输出和动作顺序。例如,机器人的超声避障功能能够在遇到突然出现的障碍物或前方行人时立即停止运动,避免碰撞。导航系统在规划自由路径时,遇到突发的障碍物和人群时能够立即重新规划路径并绕行。
明天会更新下篇,聚焦人机交互、发展讨论。
 一起“点赞”三连↓
一起“点赞”三连↓

















 356
356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









