







文章目录
前言
我们知道小智AI机器人是一款能够对话且可视的Ai语音聊天机器人。
语音对话和语音控制可以说是其核心功能,我寻思着先了解这些语音方案,之后再看代码,也更方便我们对语音这块代码逻辑的理解。
本篇主要是记录下自己所了解到的小智AI聊天机器人背后的语音技术的一部分(ESP-SR+SenseVoice),这块内容有点多所以估计要拆成几篇去记录了。
前面的文章:
小智AI机器人 - 代码框架梳理1
小智AI机器人 - 代码框架梳理2
小智AI 地址:
github地址
gitcode地址(这个国内访问起来比较快)
1.简介

从项目的README中已实现功能我们了解到小智AI 确实已经实现了很多强大的语音功能,后面我们会根据这些实现的功能,一步步的进行代码分析,看看它是如何实现的。
当前的话我会根据实现列表中所提到的语音技术,来对其一一进行分析和了解。(由于自身只接触过思必驰的离线语音所以对于其他语音技术了解有限,这里也只是和大家对这些语音技术先形成一个概念。)
2. 离线语音唤醒 ESP-SR
我个人过去使用离线语音的体验
关于离线语音这一块我之前在做带屏网关时,使用过思必驰的离线语音方案,这种方案也支持配置各种唤醒词(但是实际上是通过将输入的唤醒词转换为pinyin然后告诉思必驰的SDK,这里有个很难受的点是用户输入的是文字,但是转换为拼音时经常会因为多音字转换成了另外一个读音,导致唤不醒)。
而对于离线语音来说它是预先通过写入脚本,将用户输入的语音转换成为某个我们预定的动作,例如我想要支持“打开空调”,就需要先预先用脚本告知到离线语音的SDK
“打开空调“对应OPEN_AIR,
“关闭空调”对应CLOSE_AIR,
不然的话如果你说“打开空调”它是识别不出来到底对应啥动作的,然后如果支持了“打开空调”的语音,但是脚本上没写“把空调打开”那么用户说“把空调打开”时也是识别不出来的,不过这些都能够通过对应脚本的语法来实现不同的组合。离线语音整体上就没那么智能。这也导致我有一段时期对离线语音的方案智能和灵活产生了一丝怀疑。
2.1 什么是ESP-SR
ESP-SR 是乐鑫科技(Espressif Systems)开发的嵌入式语音识别解决方案,专为低功耗、资源受限的物联网设备设计,支持本地离线语音交互。
当然也可以进行联网扩展(扩展后就是在线语音方案,更加灵活),例如本地唤醒后,将语音数据上传到云端进行更复杂的自然语言处理
2.2 核心功能
AFE 声学前端算法框架
智能语音设备需要在远场噪声环境中,仍具备出色的语音交互性能,声学前端 (Audio Front-End, AFE)
算法在构建此类语音用户界面 (Voice-User Interface, VUI) 时至关重要。
乐鑫 AI 实验室自主研发了一套乐鑫 AFE 算法框架,可基于功能强大的 ESP32
系列芯片进行声学前端处理,使用户获得高质量且稳定的音频数据,从而构建性能卓越且高性价比的智能语音产品。
大概的流程就是,从
1.音视频编解码器获取音频原始数据
2.AEC算法消除回声
3.BSS和NS更进一步的消除周围的噪声
4.VAD识别出是否有有效的语音被检测到(例如检测是否有人说话)
5.之后将数据交给模型匹配是否是预先配置的唤醒词。

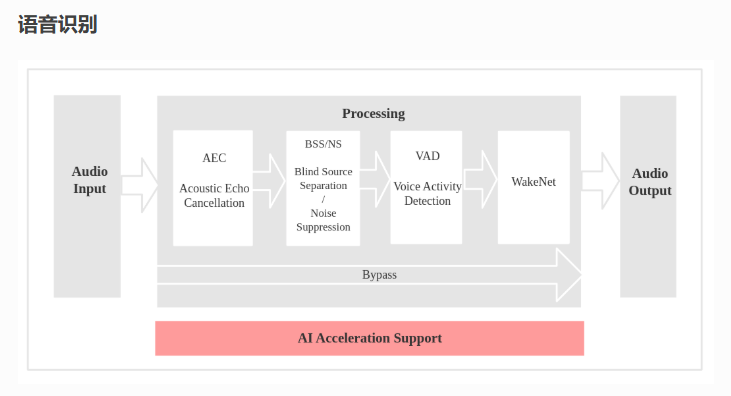
语音活动检测模型 - VAD
VADNet 是一个基于神经网络的语音活动检测模型,专为低功耗嵌入式MCU设计。它的功能主要是判断音频信号中是否存在人声,从连续音频流中定位人声片段(如对话段落),过滤静音或背景噪声。
低功耗设计的体现点: 在低功耗设备中,仅在人声出现时启动完整语音处理流程,减少持续运算的能耗。
唤醒词模型 - WakeNet

WakeNet 是一个基于神经网络,为低功耗嵌入式 MCU 设计的唤醒词模型,目前支持 5 个以内的唤醒词识别。
其支持自定义唤醒词(如“嗨,小乐”),低误触发率(False Accept Rate, FAR)和高唤醒率。
典型唤醒响应时间 < 200ms,功耗优化适合电池供电设备。
语音指令模型 - MultiNetm
MultiNet 命令词识别模型是为了在 ESP32 系列上离线实现多命令词识别而设计的轻量化模型,目前支持 200 个以内的自定义命令词识别。
MultiNet 输入为经过前端语音算法(AFE)处理过的音频(格式为 16 KHz,16 bit,单声道)。通过对音频进行识别,则可以对应到相应的汉字或单词。
特点:

命令词识别原理
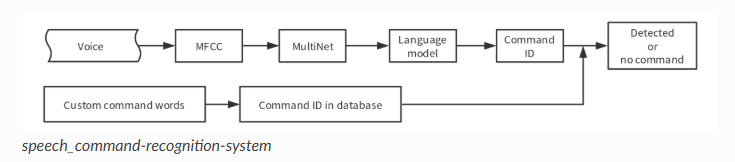
命令词识别的使用
命令词的增删改查可以通过上面的接口进行修改

MultiNet 命令词识别建议和 ESP-SR 中的 AFE 声学算法模块一起运行,用户开启 AFE 且使能 WakeNet 后,则可以运行 MultiNet。
而MultiNet的识别结果必须和唤醒词搭配使用,当唤醒后可以运行命令词检测,要不然很容易误触发,例如我们聊天时说打开空调,如果不唤醒就识别,可能就真的打开空调了,但是我们本意并非如此。如果先唤醒则识别则相当于给了一个前提条件,另外如果一直运行MultiNet这个模型,耗电会非常快,设备可能也会发热。 通过唤醒后再识别也能降低一些功耗。
语音合成模型 - TTS
语音合成(Text-to-Speech, TTS)是将文本转化为自然语音的技术,例如识别文字播放小说,语音导航、智能助手之类的经常使用。
TTS技术,这是让AI小智发声的关键技术啊(小智AI上也支持其它的TTS方案,这些方案发声更加自然,处理速度也更快,后续会提到)。
工作原理
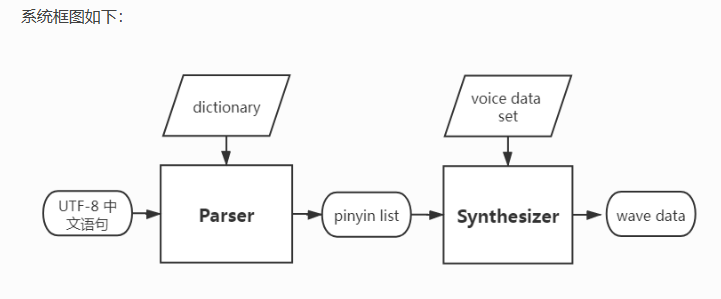
乐鑫 TTS 的当前版本基于拼接法,主要组成部分包括:
- 解析器 (Parser):根据字典与语法规则,将输入文本(采用 UTF-8 编码)转换为拼音列表。
- 合成器 (Synthesizer):根据解析器输出的拼音列表,结合预定义的声音集,合成波形文件。默认输出格式为:单声道,16 bit @ 16000Hz。
2.3 总结
一个语音技术里面可用了不少模型。整体上就是先通过AFE的算法框架提取出有效的人的声音,然后再根据情况送给不同的模型进行识别,应用则根据识别的结果去执行对应的动作。
3. 多语言语音理解模型-SenseVoice
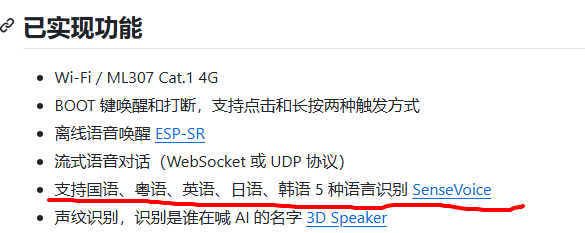
看介绍,小智AI是通过这个SenseVoice进行多国语言的语音识别啊
项目地址:https://github.com/FunAudioLLM/SenseVoice/blob/main/README_zh.md
3.1 什么是SenseVoice
SenseVoice 是一个由 FunAudioLLM团队(阿里通义实验室支持)开发的 多语言语音理解模型。它不仅能识别语音(把你说的话转成文字),还能分析你的情绪(比如高兴、生气)、检测背景声音(比如笑声、音乐),甚至支持50多种语言(包括中文、英语、日语等)。
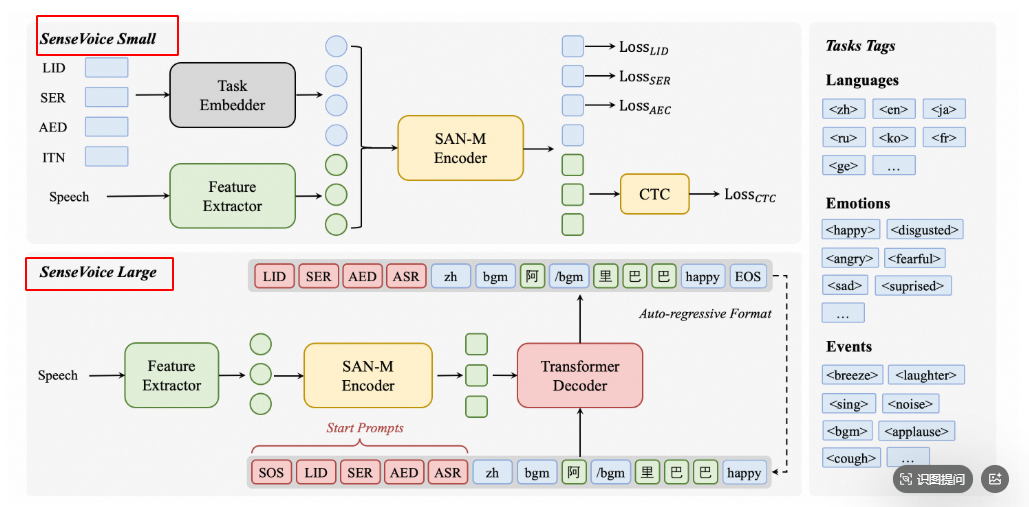
核心功能
- 语音识别(ASR):准确转写你说的话,比 Whisper(另一个知名语音模型)更快、更准。
- 情感识别(SER):能听出你是开心、生气还是难过。
- 事件检测(AED):能识别背景音,比如掌声、咳嗽声、音乐等。
- 高效推理:处理10秒的语音只要70毫秒,速度是同类模型的15倍。
3.2 SenseVoice 的历史
2024年7月,SenseVoice 正式开源,主打“多任务合一”(语音+情感+事件检测),之前很多语音模型只能做单一任务(比如只转文字),而 SenseVoice 把多个功能打包在一起,适合需要复杂交互的场景(比如智能音箱、客服机器人)。它的训练数据超过 40万小时,尤其擅长中文和粤语。
3.3 为什么要使用SenseVoice
- 多语言支持:小智AI想支持中、英、日、韩等语言,SenseVoice 正好覆盖。
- 情感交互:如果小智AI能听出用户情绪(比如你生气了),就能更贴心地回应。SenseVoice 的情感识别功能直接满足了这一点。
- 背景音处理:比如检测到用户咳嗽,可以主动问“需要帮忙吗?”——这种场景化交互需要 SenseVoice 的事件检测能力。
3.4 小智AI如何使用SenseVoice
小智AI上是SenseVoice与ESP-SR一起使用的,例如:
- 语音唤醒:用乐鑫的 ESP-SR(离线唤醒词,比如“嗨,小智”)。
- 语音理解:用 SenseVoice 转文字+分析情绪。
- 大模型回复:AI生成回答,再通过麦克风播放出来
3.5 总结
SenseVoice这个语言模型很明显要比ESP-SR中的MulitiNet(离线语音识别)具备更加强大的功能,
不过MulitiNet属于离线语音识别,功能有限也很正常。
SenseVoice可以在本地部署也可以在云端部署,通过云服务的方式去使用该功能,考虑到ESP32-S3的资源非常有限,所以小智AI应该是采用了云端部署通过远程API接口调用的方式(相当于在线语音)。

















 720
720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









