



机器学习分类预测与SHAP可解释性分析
研究目的
今天,我将尝试预测一个人是否会中风。首先,我将进行广泛的数据可视化。这将帮助我了解是否有任何特征看起来预示着中风,或者实际上预示着不会中风。
接下来,我将建立多个模型,并选出表现最好的一个。我将使用f1分数作为主要指标,因为我们的数据集是不平衡的(不过我也会用 SMOTE 解决这个问题)。
模型解释
我还将深入研究模型解释。我们经常需要向非技术人员解释非常技术性的算法,因此我们应该掌握任何有助于这一过程的工具。
# 这个 Python 3 环境安装了许多有用的分析库
# 它由 kaggle/python Docker 镜像定义:https://github.com/kaggle/docker-python
# 例如,这里有几个需要加载的有用软件包
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# 输入数据文件位于只读的“.../input/”目录下
# 例如,运行此程序(点击运行或按 Shift+Enter 键)将列出输入目录下的所有文件
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# 你可以将最多 20GB 的文件写入当前目录(/kaggle/working/),当你使用 “全部保存并运行 ”创建版本时,这些文件将作为输出保存。
# 你也可以将临时文件写入 /kaggle/temp/,但它们不会被保存到当前会话以外的地方。
import matplotlib.pyplot as plt
import matplotlib.ticker as mtick
import matplotlib.gridspec as grid_spec
import seaborn as sns
from imblearn.over_sampling import SMOTE
import scikitplot as skplt
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler,LabelEncoder
from sklearn.model_selection import train_test_split,cross_val_score
from sklearn.linear_model import LinearRegression,LogisticRegression
from sklearn.tree import DecisionTreeRegressor,DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.metrics import accuracy_score, recall_score, roc_auc_score, precision_score, f1_score
import warnings
warnings.filterwarnings('ignore')
!pip install pywaffle
数据检查
df = pd.read_csv('/kaggle/input/stroke-prediction-dataset/healthcare-dataset-stroke-data.csv')
df.head(3)
df.isnull().sum()
如何处理数据中的空白?
方法有很多。我们可以简单地删除这些记录,用平均值、中位数,甚至是缺失值之前或之后的记录来填补空白。但还有其他更特别的方法。在这里,我将使用决策树来预测缺失的BMI值。其他值得探索的有趣方法还包括使用K近邻法来填补空白。
# Thoman Konstantin 在 https://www.kaggle.com/thomaskonstantin/analyzing-and-modeling-stroke-data 中介绍了一种既奇特又聪明的处理空白的方法。
DT_bmi_pipe = Pipeline( steps=[
('scale',StandardScaler()),
('lr',DecisionTreeRegressor(random_state=42))
])
X = df[['age','gender','bmi']].copy()
X.gender = X.gender.replace({'Male':0,'Female':1,'Other':-1}).astype(np.uint8)
Missing = X[X.bmi.isna()]
X = X[~X.bmi.isna()]
Y = X.pop('bmi')
DT_bmi_pipe.fit(X,Y)
predicted_bmi = pd.Series(DT_bmi_pipe.predict(Missing[['age','gender']]),index=Missing.index)
df.loc[Missing.index,'bmi'] = predicted_bmi
探索性数据分析
我们现在已经处理了数据中的缺失值。接下来,我想探索一下数据。
年龄是否会使人更容易中风?性别呢?还是体重指数?
这些问题都可以通过数据可视化来探索和回答。首先,我们来看看数值/连续变量的分布情况
variables = [variable for variable in df.columns if variable not in ['id','stroke']]
conts = ['age','avg_glucose_level','bmi']
fig = plt.figure(figsize=(12, 12), dpi=150, facecolor='#fafafa')
gs = fig.add_gridspec(4, 3)
gs.update(wspace=0.1, hspace=0.4)
background_color = "#fafafa"
plot = 0
for row in range(0, 1):
for col in range(0, 3):
locals()["ax"+str(plot)] = fig.add_subplot(gs[row, col])
locals()["ax"+str(plot)].set_facecolor(background_color)
locals()["ax"+str(plot)].tick_params(axis='y', left=False)
locals()["ax"+str(plot)].get_yaxis().set_visible(False)
for s in ["top","right","left"]:
locals()["ax"+str(plot)].spines[s].set_visible(False)
plot += 1
plot = 0
for variable in conts:
sns.kdeplot(df[variable] ,ax=locals()["ax"+str(plot)], color='#0f4c81', shade=True, linewidth=1.5, ec='black',alpha=0.9, zorder=3, legend=False)
locals()["ax"+str(plot)].grid(which='major', axis='x', zorder=0, color='gray', linestyle=':', dashes=(1,5))
#locals()["ax"+str(plot)].set_xlabel(variable) removed this for aesthetics
plot += 1
ax0.set_xlabel('Age')
ax1.set_xlabel('Avg. Glucose Levels')
ax2.set_xlabel('BMI')
ax0.text(-20, 0.022, 'Numeric Variable Distribution', fontsize=20, fontweight='bold', fontfamily='serif')
ax0.text(-20, 0.02, 'We see a positive skew in BMI and Glucose Level', fontsize=13, fontweight='light', fontfamily='serif')
plt.show()
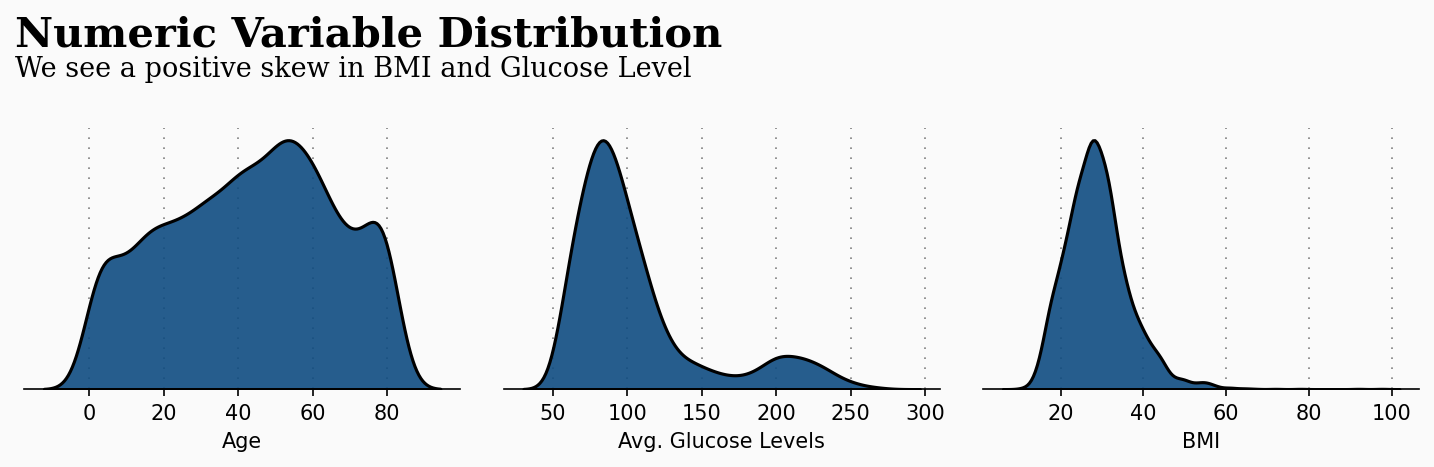
因此,我们已经对数字变量的分布有了一些了解,但我们还可以为这幅图添加更多信息。让我们看看有笔画和没有笔画的数字变量的分布有何不同。这对以后的建模可能很重要。
fig = plt.figure(figsize=(12, 12), dpi=150,facecolor=background_color)
gs = fig.add_gridspec(4, 3)
gs.update(wspace=0.1, hspace=0.4)
plot = 0
for row in range(0, 1):
for col in range(0, 3):
locals()["ax"+str(plot)] = fig.add_subplot(gs[row, col])
locals()["ax"+str(plot)].set_facecolor(background_color)
locals()["ax"+str(plot)].tick_params(axis='y', left=False)
locals()["ax"+str(plot)].get_yaxis().set_visible(False)
for s in ["top","right","left"]:
locals()["ax"+str(plot)].spines[s].set_visible(False)
plot += 1
plot = 0
s = df[df['stroke'] == 1]
ns = df[df['stroke'] == 0]
for feature in conts:
sns.kdeplot(s[feature], ax=locals()["ax"+str(plot)], color='#0f4c81', shade=True, linewidth=1.5, ec='black',alpha=0.9, zorder=3, legend=False)
sns.kdeplot(ns[feature],ax=locals()["ax"+str(plot)], color='#9bb7d4', shade=True, linewidth=1.5, ec='black',alpha=0.9, zorder=3, legend=False)
locals()["ax"+str(plot)].grid(which='major', axis='x', zorder=0, color='gray', linestyle=':', dashes=(1,5))
#locals()["ax"+str(plot)].set_xlabel(feature)
plot += 1
ax0.set_xlabel('Age')
ax1.set_xlabel('Avg. Glucose Levels')
ax2.set_xlabel('BMI')
ax0.text(-20, 0.056, 'Numeric Variables by Stroke & No Stroke', fontsize=20, fontweight='bold', fontfamily='serif')
ax0.text(-20, 0.05, 'Age looks to be a prominent factor - this will likely be a salient feautre in our models',
fontsize=13, fontweight='light', fontfamily='serif')
plt.show()
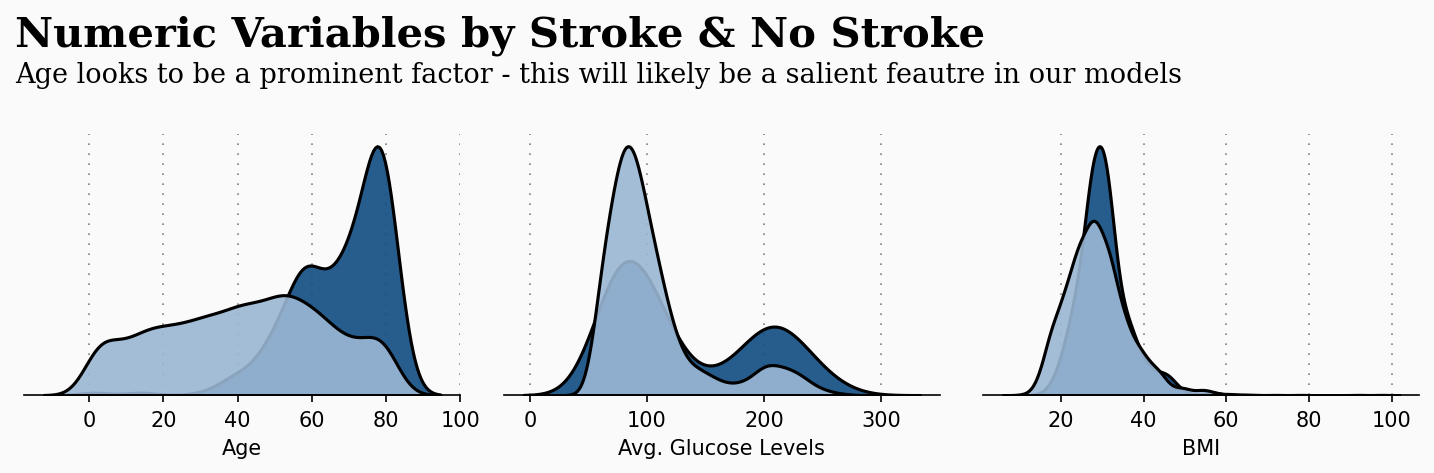
根据上述图表,很明显年龄是影响中风患者的一个重要因素–年龄越大,风险越高。虽然不那么明显,但平均血糖水平和体重指数也存在差异。葡萄糖水平和体重指数也存在差异。让我们进一步探讨这些变量…
str_only = df[df['stroke'] == 1]
no_str_only = df[df['stroke'] == 0]
# Setting up figure and axes
fig = plt.figure(figsize=(10,16),dpi=150,facecolor=background_color)
gs = fig.add_gridspec(4, 2)
gs.update(wspace=0.5, hspace=0.2)
ax0 = fig.add_subplot(gs[0, 0:2])
ax1 = fig.add_subplot(gs[1, 0:2])
ax0.set_facecolor(background_color)
ax1.set_facecolor(background_color)
# glucose
sns.regplot(no_str_only['age'],y=no_str_only['avg_glucose_level'],
color='lightgray',
logx=True,
ax=ax0)
sns.regplot(str_only['age'],y=str_only['avg_glucose_level'],
color='#0f4c81',
logx=True,scatter_kws={'edgecolors':['black'],
'linewidth': 1},
ax=ax0)
ax0.set(ylim=(0, None))
ax0.set_xlabel(" ",fontsize=12,fontfamily='serif')
ax0.set_ylabel("Avg. Glucose Level",fontsize=10,fontfamily='serif',loc='bottom')
ax0.tick_params(axis='x', bottom=False)
ax0.get_xaxis().set_visible(False)
for s in ['top','left','bottom']:
ax0.spines[s].set_visible(False)
# bmi
sns.regplot(no_str_only['age'],y=no_str_only['bmi'],
color='lightgray',
logx=True,
ax=ax1)
sns.regplot(str_only['age'],y=str_only['bmi'],
color='#0f4c81', scatter_kws={'edgecolors':['black'],
'linewidth': 1},
logx=True,
ax=ax1)
ax1.set_xlabel("Age",fontsize=10,fontfamily='serif',loc='left')
ax1.set_ylabel("BMI",fontsize=10,fontfamily='serif',loc='bottom')
for s in ['top','left','right']:
ax0.spines[s].set_visible(False)
ax1.spines[s].set_visible(False)
ax0.text(-5,350,'Strokes by Age, Glucose Level, and BMI',fontsize=18,fontfamily='serif',fontweight='bold')
ax0.text(-5,320,'Age appears to be a very important factor',fontsize=14,fontfamily='serif')
ax0.tick_params(axis=u'both', which=u'both',length=0)
ax1.tick_params(axis=u'both', which=u'both',length=0)
plt.show()
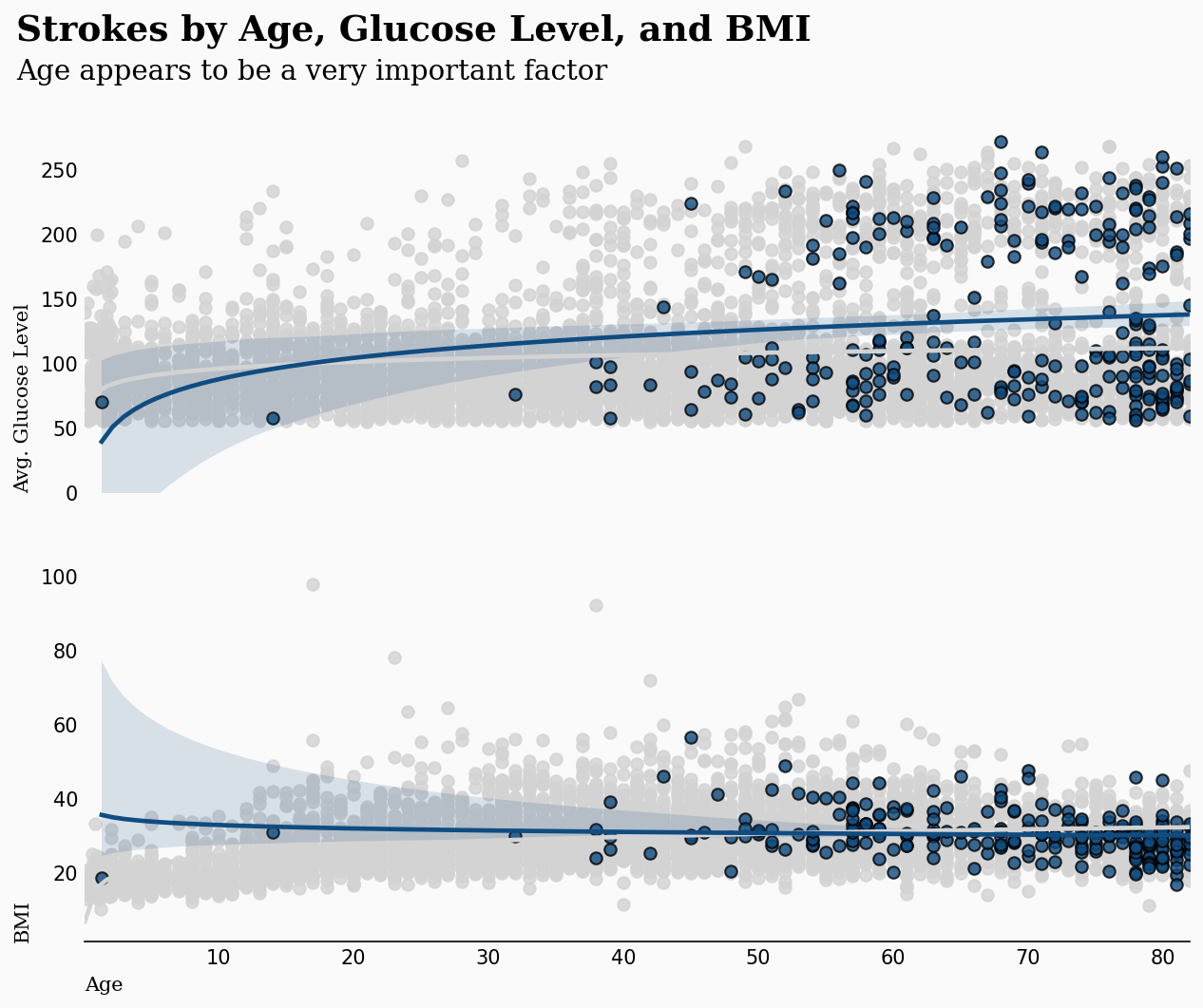
正如我们所猜测的那样,年龄是一个重要因素,与体重指数和平均血糖水平也有轻微关系。葡萄糖水平也有轻微关系。
我们可以直观地理解,随着年龄的增长,中风的风险也会增加,但你能想象吗?
fig = plt.figure(figsize=(10, 5), dpi=150,facecolor=background_color)
gs = fig.add_gridspec(2, 1)
gs.update(wspace=0.11, hspace=0.5)
ax0 = fig.add_subplot(gs[0, 0])
ax0.set_facecolor(background_color)
df['age'] = df['age'].astype(int)
rate = []
for i in range(df['age'].min(), df['age'].max()):
rate.append(df[df['age'] < i]['stroke'].sum() / len(df[df['age'] < i]['stroke']))
sns.lineplot(data=rate,color='#0f4c81',ax=ax0)
for s in ["top","right","left"]:
ax0.spines[s].set_visible(False)
ax0.tick_params(axis='both', which='major', labelsize=8)
ax0.tick_params(axis=u'both', which=u'both',length=0)
ax0.text(-3,0.055,'Risk Increase by Age',fontsize=18,fontfamily='serif',fontweight='bold')
ax0.text(-3,0.047,'As age increase, so too does risk of having a stroke',fontsize=14,fontfamily='serif')
plt.show()
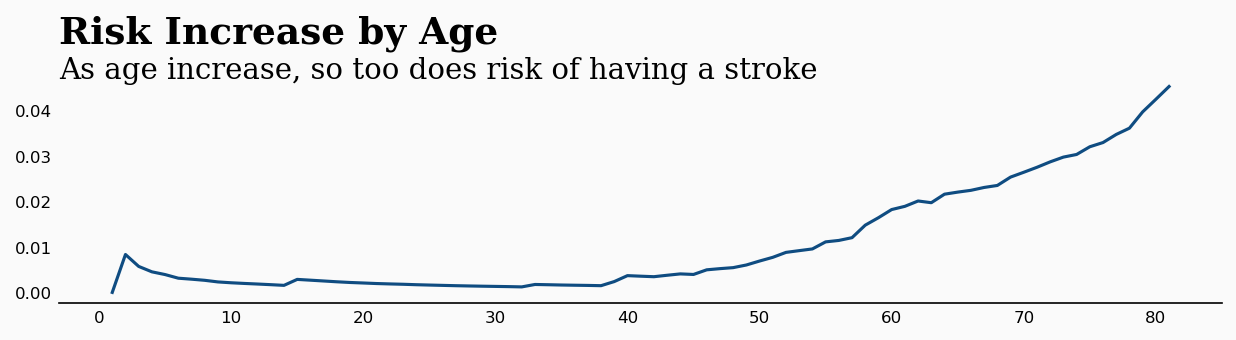
这证实了我们的直觉。年龄越大,风险越高。不过,您可能注意到了y轴上的低风险值。这是因为数据集高度不平衡。我们的数据集中只有249例脑卒中,而总数为5000例,大约每20例中就有1例。
from pywaffle import Waffle
fig = plt.figure(figsize=(7, 2),dpi=150,facecolor=background_color,
FigureClass=Waffle,
rows=1,
values=[1, 19],
colors=['#0f4c81', "lightgray"],
characters='⬤',
font_size=20,vertical=True,
)
fig.text(0.035,0.78,'People Affected by a Stroke in our dataset',fontfamily='serif',fontsize=15,fontweight='bold')
fig.text(0.035,0.65,'This is around 1 in 20 people [249 out of 5000]',fontfamily='serif',fontsize=10)
plt.show()

当然,在建模时需要考虑到这一点,但在制定风险时也需要考虑到这一点。
中风仍然比较罕见,我们并不是说任何事情都有保证,只是风险在增加。
总体概述
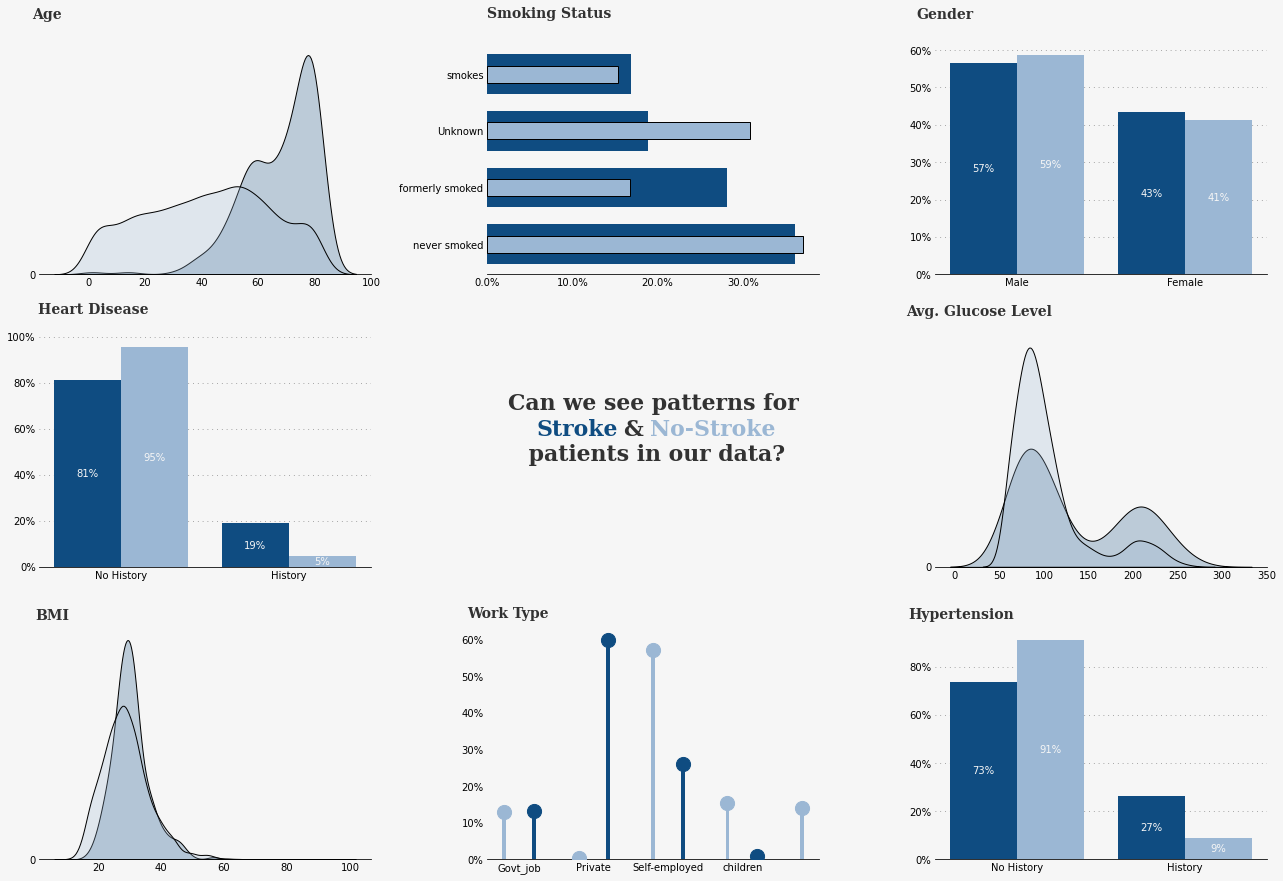
到目前为止,我们已经评估了几个变量,并获得了一些有力的见解。现在,我将把几个变量绘制在一处,以便我们发现有趣的趋势或特征。我将把数据分为 “中风 ”和 “非中风”,这样我们就能看到这两个人群是否有任何有意义的不同。
fig = plt.figure(figsize=(22,15))
gs = fig.add_gridspec(3, 3)
gs.update(wspace=0.35, hspace=0.27)
ax0 = fig.add_subplot(gs[0, 0])
ax1 = fig.add_subplot(gs[0, 1])
ax2 = fig.add_subplot(gs[0, 2])
ax3 = fig.add_subplot(gs[1, 0])
ax4 = fig.add_subplot(gs[1, 1])
ax5 = fig.add_subplot(gs[1, 2])
ax6 = fig.add_subplot(gs[2, 0])
ax7 = fig.add_subplot(gs[2, 1])
ax8 = fig.add_subplot(gs[2, 2])
background_color = "#f6f6f6"
fig.patch.set_facecolor(background_color) # figure background color
# Plots
## Age
ax0.grid(color='gray', linestyle=':', axis='y', zorder=0, dashes=(1,5))
positive = pd.DataFrame(str_only["age"])
negative = pd.DataFrame(no_str_only["age"])
sns.kdeplot(positive["age"], ax=ax0,color="#0f4c81", shade=True, ec='black',label="positive")
sns.kdeplot(negative["age"], ax=ax0, color="#9bb7d4", shade=True, ec='black',label="negative")
#ax3.text(0.29, 13, 'Age',
# fontsize=14, fontweight='bold', fontfamily='serif', color="#323232")
ax0.yaxis.set_major_locator(mtick.MultipleLocator(2))
ax0.set_ylabel('')
ax0.set_xlabel('')
ax0.text(-20, 0.0465, 'Age', fontsize=14, fontweight='bold', fontfamily='serif', color="#323232")
# Smoking
positive = pd.DataFrame(str_only["smoking_status"].value_counts())
positive["Percentage"] = positive["smoking_status"].apply(lambda x: x/sum(positive["smoking_status"])*100)
negative = pd.DataFrame(no_str_only["smoking_status"].value_counts())
negative["Percentage"] = negative["smoking_status"].apply(lambda x: x/sum(negative["smoking_status"])*100)
ax1.text(0, 4, 'Smoking Status', fontsize=14, fontweight='bold', fontfamily='serif', color="#323232")
ax1.barh(positive.index, positive['Percentage'], color="#0f4c81", zorder=3, height=0.7)
ax1.barh(negative.index, negative['Percentage'], color="#9bb7d4", zorder=3,ec='black', height=0.3)
ax1.xaxis.set_major_formatter(mtick.PercentFormatter())
ax1.xaxis.set_major_locator(mtick.MultipleLocator(10))
##
# Ax2 - GENDER
positive = pd.DataFrame(str_only["gender"].value_counts())
positive["Percentage"] = positive["gender"].apply(lambda x: x/sum(positive["gender"])*100)
negative = pd.DataFrame(no_str_only["gender"].value_counts())
negative["Percentage"] = negative["gender"].apply(lambda x: x/sum(negative["gender"])*100)
x = np.arange(len(positive))
ax2.text(-0.4, 68.5, 'Gender', fontsize=14, fontweight='bold', fontfamily='serif', color="#323232")
ax2.grid(color='gray', linestyle=':', axis='y', zorder=0, dashes=(1,5))
ax2.bar(x, height=positive["Percentage"], zorder=3, color="#0f4c81", width=0.4)
ax2.bar(x+0.4, height=negative["Percentage"], zorder=3, color="#9bb7d4", width=0.4)
ax2.set_xticks(x + 0.4 / 2)
ax2.set_xticklabels(['Male','Female'])
ax2.yaxis.set_major_formatter(mtick.PercentFormatter())
ax2.yaxis.set_major_locator(mtick.MultipleLocator(10))
for i,j in zip([0, 1], positive["Percentage"]):
ax2.annotate(f'{j:0.0f}%',xy=(i, j/2), color='#f6f6f6', horizontalalignment='center', verticalalignment='center')
for i,j in zip([0, 1], negative["Percentage"]):
ax2.annotate(f'{j:0.0f}%',xy=(i+0.4, j/2), color='#f6f6f6', horizontalalignment='center', verticalalignment='center')
# Heart Dis
positive = pd.DataFrame(str_only["heart_disease"].value_counts())
positive["Percentage"] = positive["heart_disease"].apply(lambda x: x/sum(positive["heart_disease"])*100)
negative = pd.DataFrame(no_str_only["heart_disease"].value_counts())
negative["Percentage"] = negative["heart_disease"].apply(lambda x: x/sum(negative["heart_disease"])*100)
x = np.arange(len(positive))
ax3.text(-0.3, 110, 'Heart Disease', fontsize=14, fontweight='bold', fontfamily='serif', color="#323232")
ax3.grid(color='gray', linestyle=':', axis='y', zorder=0, dashes=(1,5))
ax3.bar(x, height=positive["Percentage"], zorder=3, color="#0f4c81", width=0.4)
ax3.bar(x+0.4, height=negative["Percentage"], zorder=3, color="#9bb7d4", width=0.4)
ax3.set_xticks(x + 0.4 / 2)
ax3.set_xticklabels(['No History','History'])
ax3.yaxis.set_major_formatter(mtick.PercentFormatter())
ax3.yaxis.set_major_locator(mtick.MultipleLocator(20))
for i,j in zip([0, 1], positive["Percentage"]):
ax3.annotate(f'{j:0.0f}%',xy=(i, j/2), color='#f6f6f6', horizontalalignment='center', verticalalignment='center')
for i,j in zip([0, 1], negative["Percentage"]):
ax3.annotate(f'{j:0.0f}%',xy=(i+0.4, j/2), color='#f6f6f6', horizontalalignment='center', verticalalignment='center')
## AX4 - TITLE
ax4.spines["bottom"].set_visible(False)
ax4.tick_params(left=False, bottom=False)
ax4.set_xticklabels([])
ax4.set_yticklabels([])
ax4.text(0.5, 0.6, 'Can we see patterns for\n\n patients in our data?', horizontalalignment='center', verticalalignment='center',
fontsize=22, fontweight='bold', fontfamily='serif', color="#323232")
ax4.text(0.15,0.57,"Stroke", fontweight="bold", fontfamily='serif', fontsize=22, color='#0f4c81')
ax4.text(0.41,0.57,"&", fontweight="bold", fontfamily='serif', fontsize=22, color='#323232')
ax4.text(0.49,0.57,"No-Stroke", fontweight="bold", fontfamily='serif', fontsize=22, color='#9bb7d4')
# Glucose
ax5.grid(color='gray', linestyle=':', axis='y', zorder=0, dashes=(1,5))
positive = pd.DataFrame(str_only["avg_glucose_level"])
negative = pd.DataFrame(no_str_only["avg_glucose_level"])
sns.kdeplot(positive["avg_glucose_level"], ax=ax5,color="#0f4c81",ec='black', shade=True, label="positive")
sns.kdeplot(negative["avg_glucose_level"], ax=ax5, color="#9bb7d4", ec='black',shade=True, label="negative")
ax5.text(-55, 0.01855, 'Avg. Glucose Level',
fontsize=14, fontweight='bold', fontfamily='serif', color="#323232")
ax5.yaxis.set_major_locator(mtick.MultipleLocator(2))
ax5.set_ylabel('')
ax5.set_xlabel('')
## BMI
ax6.grid(color='gray', linestyle=':', axis='y', zorder=0, dashes=(1,5))
positive = pd.DataFrame(str_only["bmi"])
negative = pd.DataFrame(no_str_only["bmi"])
sns.kdeplot(positive["bmi"], ax=ax6,color="#0f4c81", ec='black',shade=True, label="positive")
sns.kdeplot(negative["bmi"], ax=ax6, color="#9bb7d4",ec='black', shade=True, label="negative")
ax6.text(-0.06, 0.09, 'BMI',
fontsize=14, fontweight='bold', fontfamily='serif', color="#323232")
ax6.yaxis.set_major_locator(mtick.MultipleLocator(2))
ax6.set_ylabel('')
ax6.set_xlabel('')
# Work Type
positive = pd.DataFrame(str_only["work_type"].value_counts())
positive["Percentage"] = positive["work_type"].apply(lambda x: x/sum(positive["work_type"])*100)
positive = positive.sort_index()
negative = pd.DataFrame(no_str_only["work_type"].value_counts())
negative["Percentage"] = negative["work_type"].apply(lambda x: x/sum(negative["work_type"])*100)
negative = negative.sort_index()
ax7.bar(negative.index, height=negative["Percentage"], zorder=3, color="#9bb7d4", width=0.05)
ax7.scatter(negative.index, negative["Percentage"], zorder=3,s=200, color="#9bb7d4")
ax7.bar(np.arange(len(positive.index))+0.4, height=positive["Percentage"], zorder=3, color="#0f4c81", width=0.05)
ax7.scatter(np.arange(len(positive.index))+0.4, positive["Percentage"], zorder=3,s=200, color="#0f4c81")
ax7.yaxis.set_major_formatter(mtick.PercentFormatter())
ax7.yaxis.set_major_locator(mtick.MultipleLocator(10))
ax7.set_xticks(np.arange(len(positive.index))+0.4 / 2)
ax7.set_xticklabels(list(positive.index),rotation=0)
ax7.text(-0.5, 66, 'Work Type', fontsize=14, fontweight='bold', fontfamily='serif', color="#323232")
# hypertension
positive = pd.DataFrame(str_only["hypertension"].value_counts())
positive["Percentage"] = positive["hypertension"].apply(lambda x: x/sum(positive["hypertension"])*100)
negative = pd.DataFrame(no_str_only["hypertension"].value_counts())
negative["Percentage"] = negative["hypertension"].apply(lambda x: x/sum(negative["hypertension"])*100)
x = np.arange(len(positive))
ax8.text(-0.45, 100, 'Hypertension', fontsize=14, fontweight='bold', fontfamily='serif', color="#323232")
ax8.grid(color='gray', linestyle=':', axis='y', zorder=0, dashes=(1,5))
ax8.bar(x, height=positive["Percentage"], zorder=3, color="#0f4c81", width=0.4)
ax8.bar(x+0.4, height=negative["Percentage"], zorder=3, color="#9bb7d4", width=0.4)
ax8.set_xticks(x + 0.4 / 2)
ax8.set_xticklabels(['No History','History'])
ax8.yaxis.set_major_formatter(mtick.PercentFormatter())
ax8.yaxis.set_major_locator(mtick.MultipleLocator(20))
for i,j in zip([0, 1], positive["Percentage"]):
ax8.annotate(f'{j:0.0f}%',xy=(i, j/2), color='#f6f6f6', horizontalalignment='center', verticalalignment='center')
for i,j in zip([0, 1], negative["Percentage"]):
ax8.annotate(f'{j:0.0f}%',xy=(i+0.4, j/2), color='#f6f6f6', horizontalalignment='center', verticalalignment='center')
# tidy up
for s in ["top","right","left"]:
for i in range(0,9):
locals()["ax"+str(i)].spines[s].set_visible(False)
for i in range(0,9):
locals()["ax"+str(i)].set_facecolor(background_color)
locals()["ax"+str(i)].tick_params(axis=u'both', which=u'both',length=0)
locals()["ax"+str(i)].set_facecolor(background_color)
plt.show()
模型准备
首先进行数据编码,代码如下
# Encoding categorical values
df['gender'] = df['gender'].replace({'Male':0,'Female':1,'Other':-1}).astype(np.uint8)
df['Residence_type'] = df['Residence_type'].replace({'Rural':0,'Urban':1}).astype(np.uint8)
df['work_type'] = df['work_type'].replace({'Private':0,'Self-employed':1,'Govt_job':2,'children':-1,'Never_worked':-2}).astype(np.uint8)
平衡数据集
首先,我将使用 SMOTE(合成少数群体过度采样技术)来平衡我们的数据集。目前,正如我上面提到的,中风的负面例子较多,这可能会妨碍我们的模型。使用SMOTE可以解决这个问题。
对于这样一个不平衡的数据集,一个有用的基线可以是击败“空精确度”,而在我们的例子中,由于我们正在寻找正值(“中风”),我将取其倒数。换句话说,总是预测最常见的结果。
在这种情况下,249/(249+4861)=0.048
因此,中风阳性患者的召回率为 5%~是一个不错的目标。
# Inverse of Null Accuracy
print('Inverse of Null Accuracy: ',249/(249+4861))
print('Null Accuracy: ',4861/(4861+249))
X = df[['gender','age','hypertension','heart_disease','work_type','avg_glucose_level','bmi']]
y = df['stroke']
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.3, random_state=42)
# Our data is biased, we can fix this with SMOTE
oversample = SMOTE()
X_train_resh, y_train_resh = oversample.fit_resample(X_train, y_train.ravel())
模型设定
在这项分类任务中,我将使用随机森林、SVM 和逻辑回归模型。此外,我还将使用10倍交叉验证。
# Models
# Scale our data in pipeline, then split
rf_pipeline = Pipeline(steps = [('scale',StandardScaler()),('RF',RandomForestClassifier(random_state=42))])
svm_pipeline = Pipeline(steps = [('scale',StandardScaler()),('SVM',SVC(random_state=42))])
logreg_pipeline = Pipeline(steps = [('scale',StandardScaler()),('LR',LogisticRegression(random_state=42))])
#X = upsampled_df.iloc[:,:-1] # X_train_resh
#Y = upsampled_df.iloc[:,-1]# y_train_resh
#retain_x = X.sample(100)
#retain_y = Y.loc[X.index]
#X = X.drop(index=retain_x.index)
#Y = Y.drop(index=retain_x.index)
rf_cv = cross_val_score(rf_pipeline,X_train_resh,y_train_resh,cv=10,scoring='f1')
svm_cv = cross_val_score(svm_pipeline,X_train_resh,y_train_resh,cv=10,scoring='f1')
logreg_cv = cross_val_score(logreg_pipeline,X_train_resh,y_train_resh,cv=10,scoring='f1')
print('Mean f1 scores:')
print('Random Forest mean :',cross_val_score(rf_pipeline,X_train_resh,y_train_resh,cv=10,scoring='f1').mean())
print('SVM mean :',cross_val_score(svm_pipeline,X_train_resh,y_train_resh,cv=10,scoring='f1').mean())
print('Logistic Regression mean :',cross_val_score(logreg_pipeline,X_train_resh,y_train_resh,cv=10,scoring='f1').mean())
Mean f1 scores:
Random Forest mean : 0.9346427778803479
SVM mean : 0.872643809848914
Logistic Regression mean : 0.8271089986873392
可以看到随机森林表现最佳,通常,树方法是首选模型。现在,让我们在未见过的负面数据上试一试:
rf_pipeline.fit(X_train_resh,y_train_resh)
svm_pipeline.fit(X_train_resh,y_train_resh)
logreg_pipeline.fit(X_train_resh,y_train_resh)
#X = df.loc[:,X.columns]
#Y = df.loc[:,'stroke']
rf_pred =rf_pipeline.predict(X_test)
svm_pred = svm_pipeline.predict(X_test)
logreg_pred = logreg_pipeline.predict(X_test)
rf_cm = confusion_matrix(y_test,rf_pred )
svm_cm = confusion_matrix(y_test,svm_pred)
logreg_cm = confusion_matrix(y_test,logreg_pred )
rf_f1 = f1_score(y_test,rf_pred)
svm_f1 = f1_score(y_test,svm_pred)
logreg_f1 = f1_score(y_test,logreg_pred)
print('Mean f1 scores:')
print('RF mean :',rf_f1)
print('SVM mean :',svm_f1)
print('LR mean :',logreg_f1)
Mean f1 scores:
RF mean : 0.1553398058252427
SVM mean : 0.15082644628099173
LR mean : 0.19384902143522834
from sklearn.metrics import plot_confusion_matrix, classification_report
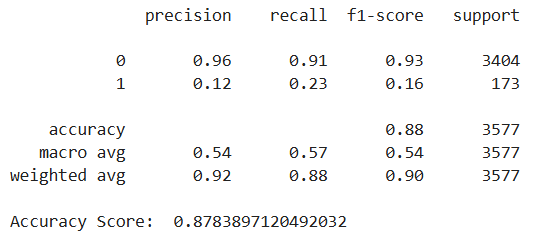
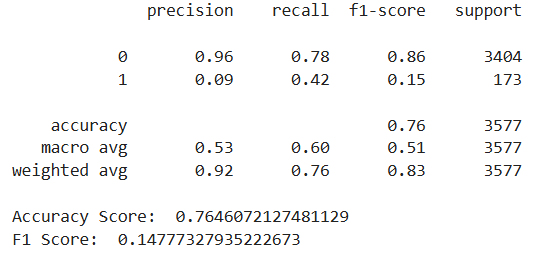
print(classification_report(y_test,rf_pred))
print('Accuracy Score: ',accuracy_score(y_test,rf_pred))
RF最优参数搜索
由于模型结果准确率高,召回率低。我将尝试使用网格搜索为我们的随机森林找到最佳参数。
# 准确率相当高,但召回率较低!
# 未缩放和未升采样的负值
from sklearn.model_selection import GridSearchCV
n_estimators =[64,100,128,200]
max_features = [2,3,5,7]
bootstrap = [True,False]
param_grid = {'n_estimators':n_estimators,
'max_features':max_features,
'bootstrap':bootstrap}
rfc = RandomForestClassifier()
#grid = GridSearchCV(rfc,param_grid)
#grid.fit(X_train,y_train)
#grid.best_params_
#{'bootstrap': True, 'max_features': 2, 'n_estimators': 100}
# Let's use those params now
rfc = RandomForestClassifier(max_features=2,n_estimators=100,bootstrap=True)
rfc.fit(X_train_resh,y_train_resh)
rfc_tuned_pred = rfc.predict(X_test)
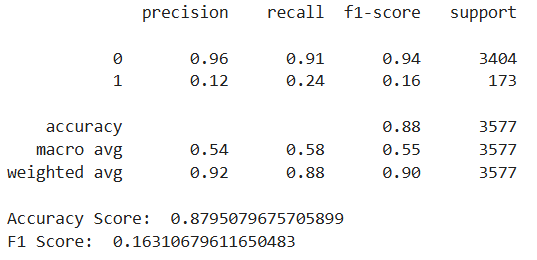
print(classification_report(y_test,rfc_tuned_pred))
print('Accuracy Score: ',accuracy_score(y_test,rfc_tuned_pred))
print('F1 Score: ',f1_score(y_test,rfc_tuned_pred))
Logistic优化
逻辑回归的上述 f1 分数最高,因此我们或许可以对其进行调整,以获得更好的结果。
penalty = ['l1','l2']
C = [0.001, 0.01, 0.1, 1, 10, 100]
log_param_grid = {'penalty': penalty,
'C': C}
logreg = LogisticRegression()
grid = GridSearchCV(logreg,log_param_grid)
#grid.fit(X_train_resh,y_train_resh)
#grid.best_params_
#output:
# {'C': 0.1, 'penalty': 'l2'}
# Let's use those params now
logreg_pipeline = Pipeline(steps = [('scale',StandardScaler()),('LR',LogisticRegression(C=0.1,penalty='l2',random_state=42))])
logreg_pipeline.fit(X_train_resh,y_train_resh)
#logreg.fit(X_train_resh,y_train_resh)
logreg_tuned_pred = logreg_pipeline.predict(X_test)
print(classification_report(y_test,logreg_tuned_pred))
print('Accuracy Score: ',accuracy_score(y_test,logreg_tuned_pred))
print('F1 Score: ',f1_score(y_test,logreg_tuned_pred))
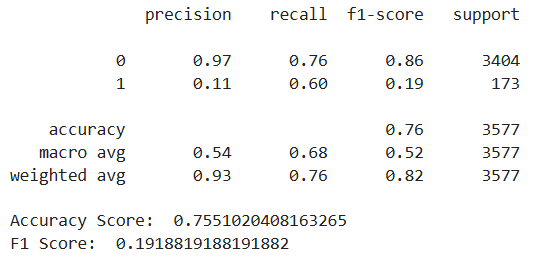
因此,超参数调整对 Logisitc 回归模型很有帮助。尽管总体准确率有所下降,但它的召回分数要比随机森林高得多。
不过,我们可以调整模型用于分类中风和非中风的阈值。
让我们试试看…
#source code: https://www.kaggle.com/prashant111/extensive-analysis-eda-fe-modelling
# modified
from sklearn.preprocessing import binarize
for i in range(1,6):
cm1=0
y_pred1 = logreg_pipeline.predict_proba(X_test)[:,1]
y_pred1 = y_pred1.reshape(-1,1)
y_pred2 = binarize(y_pred1, i/10)
y_pred2 = np.where(y_pred2 == 1, 1, 0)
cm1 = confusion_matrix(y_test, y_pred2)
print ('With',i/10,'threshold the Confusion Matrix is ','\n\n',cm1,'\n\n',
'with',cm1[0,0]+cm1[1,1],'correct predictions, ', '\n\n',
cm1[0,1],'Type I errors( False Positives), ','\n\n',
cm1[1,0],'Type II errors( False Negatives), ','\n\n',
'Accuracy score: ', (accuracy_score(y_test, y_pred2)), '\n\n',
'F1 score: ', (f1_score(y_test, y_pred2)), '\n\n',
'Sensitivity: ',cm1[1,1]/(float(cm1[1,1]+cm1[1,0])), '\n\n',
'Specificity: ',cm1[0,0]/(float(cm1[0,0]+cm1[0,1])),'\n\n',
'====================================================', '\n\n')
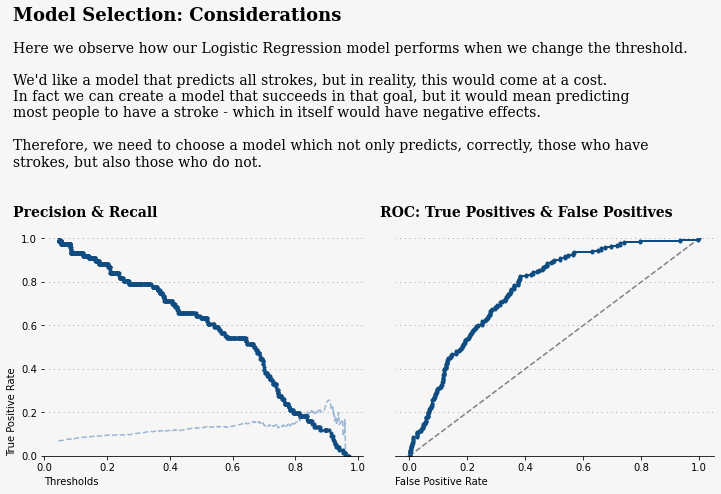
我们可以看到,通过调整阈值,我们可以捕捉到更多的笔画。
但是,我们需要谨慎使用这种方法。我们可以改变阈值,预测每个病人都会中风,以避免漏诊,但这对任何人都没有帮助。
艺术在于找到 “命中 ”与 “遗漏 ”之间的平衡点。F1 评分是一个很好的起点,因为它是多个指标的加权平均值。
下面的图表显示了我的意思
# source code: https://www.kaggle.com/ilyapozdnyakov/rain-in-australia-precision-recall-curves-viz
# heeavily modified plotting
from sklearn.metrics import roc_curve
from sklearn.metrics import roc_auc_score
from sklearn.metrics import precision_recall_curve
ns_probs = [0 for _ in range(len(y_test))]
lr_probs = logreg_pipeline.predict_proba(X_test)
lr_probs = lr_probs[:, 1]
ns_auc = roc_auc_score(y_test, ns_probs)
lr_auc = roc_auc_score(y_test, lr_probs)
# calculate roc curves
ns_fpr, ns_tpr, _ = roc_curve(y_test, ns_probs)
lr_fpr, lr_tpr, _ = roc_curve(y_test, lr_probs)
y_scores = logreg_pipeline.predict_proba(X_train)[:,1]
precisions, recalls, thresholds = precision_recall_curve(y_train, y_scores)
# Plots
fig = plt.figure(figsize=(12,4))
gs = fig.add_gridspec(1,2, wspace=0.1,hspace=0)
ax = gs.subplots()
background_color = "#f6f6f6"
fig.patch.set_facecolor(background_color) # figure background color
ax[0].set_facecolor(background_color)
ax[1].set_facecolor(background_color)
ax[0].grid(color='gray', linestyle=':', axis='y', zorder=0, dashes=(1,5))
ax[1].grid(color='gray', linestyle=':', axis='y', dashes=(1,5))
y_scores = logreg_pipeline.predict_proba(X_train)[:,1]
precisions, recalls, thresholds = precision_recall_curve(y_train, y_scores)
ax[0].plot(thresholds, precisions[:-1], 'b--', label='Precision',color='#9bb7d4')
ax[0].plot(thresholds, recalls[:-1], '.', linewidth=1,label='Recall',color='#0f4c81')
ax[0].set_ylabel('True Positive Rate',loc='bottom')
ax[0].set_xlabel('Thresholds',loc='left')
#plt.legend(loc='center left')
ax[0].set_ylim([0,1])
# plot the roc curve for the model
ax[1].plot(ns_fpr, ns_tpr, linestyle='--', label='Dummy Classifer',color='gray')
ax[1].plot(lr_fpr, lr_tpr, marker='.', linewidth=2,color='#0f4c81')
ax[1].set_xlabel('False Positive Rate',loc='left')
ax[1].set_ylabel('')
ax[1].set_ylim([0,1])
for s in ["top","right","left"]:
ax[0].spines[s].set_visible(False)
ax[1].spines[s].set_visible(False)
ax[0].text(-0.1,2,'Model Selection: Considerations',fontsize=18,fontfamily='serif',fontweight='bold')
ax[0].text(-0.1,1.26,
'''
Here we observe how our Logistic Regression model performs when we change the threshold.
We'd like a model that predicts all strokes, but in reality, this would come at a cost.
In fact we can create a model that succeeds in that goal, but it would mean predicting
most people to have a stroke - which in itself would have negative effects.
Therefore, we need to choose a model which not only predicts, correctly, those who have
strokes, but also those who do not.
''',fontsize=14,fontfamily='serif')
ax[0].text(-0.1,1.1,'Precision & Recall',fontsize=14,fontfamily='serif',fontweight='bold')
ax[1].text(-0.1,1.1,'ROC: True Positives & False Positives',fontsize=14,fontfamily='serif',fontweight='bold')
ax[1].tick_params(axis='y', colors=background_color)
plt.show()
SVM模型优化
# defining parameter range
#svm_param_grid = {'C': [0.1, 1, 10, 100, 1000],
# 'gamma': [1, 0.1, 0.01, 0.001, 0.0001],
# 'kernel': ['rbf']}
#svm = SVC(random_state=42)
#grid = GridSearchCV(svm,svm_param_grid)
#grid.fit(X_train_resh,y_train_resh)
#grid.best_params_
#output:
# {'C': 1000, 'gamma': 0.01, 'kernel': 'rbf'}
# Let's use those params now
svm_pipeline = Pipeline(steps = [('scale',StandardScaler()),('SVM',SVC(C=1000,gamma=0.01,kernel='rbf',random_state=42))])
svm_pipeline.fit(X_train_resh,y_train_resh)
svm_tuned_pred = svm_pipeline.predict(X_test)
print(classification_report(y_test,svm_tuned_pred))
print('Accuracy Score: ',accuracy_score(y_test,svm_tuned_pred))
print('F1 Score: ',f1_score(y_test,svm_tuned_pred))
最优模型决策
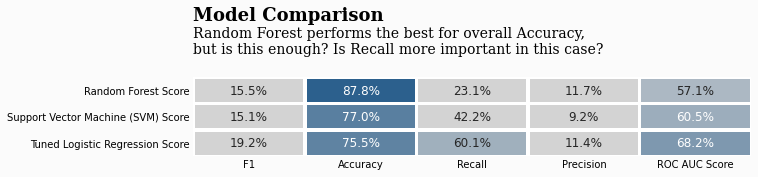
经过调整的随机森林模型为我们提供了更高的准确率,约为94%,但对中风患者的召回率仅为2%。
原始模型的准确率为88%,但中风患者的召回率为24%。
在我看来,该模型更适合预测哪些人会中风,而不是预测哪些人不会中风。
# Make dataframes to plot
rf_df = pd.DataFrame(data=[f1_score(y_test,rf_pred),accuracy_score(y_test, rf_pred), recall_score(y_test, rf_pred),
precision_score(y_test, rf_pred), roc_auc_score(y_test, rf_pred)],
columns=['Random Forest Score'],
index=["F1","Accuracy", "Recall", "Precision", "ROC AUC Score"])
svm_df = pd.DataFrame(data=[f1_score(y_test,svm_pred),accuracy_score(y_test, svm_pred), recall_score(y_test, svm_pred),
precision_score(y_test, svm_pred), roc_auc_score(y_test, svm_pred)],
columns=['Support Vector Machine (SVM) Score'],
index=["F1","Accuracy", "Recall", "Precision", "ROC AUC Score"])
lr_df = pd.DataFrame(data=[f1_score(y_test,logreg_tuned_pred),accuracy_score(y_test, logreg_tuned_pred), recall_score(y_test, logreg_tuned_pred),
precision_score(y_test, logreg_tuned_pred), roc_auc_score(y_test, logreg_tuned_pred)],
columns=['Tuned Logistic Regression Score'],
index=["F1","Accuracy", "Recall", "Precision", "ROC AUC Score"])
df_models = round(pd.concat([rf_df,svm_df,lr_df], axis=1),3)
import matplotlib
colors = ["lightgray","lightgray","#0f4c81"]
colormap = matplotlib.colors.LinearSegmentedColormap.from_list("", colors)
background_color = "#fbfbfb"
fig = plt.figure(figsize=(10,8)) # create figure
gs = fig.add_gridspec(4, 2)
gs.update(wspace=0.1, hspace=0.5)
ax0 = fig.add_subplot(gs[0, :])
sns.heatmap(df_models.T, cmap=colormap,annot=True,fmt=".1%",vmin=0,vmax=0.95, linewidths=2.5,cbar=False,ax=ax0,annot_kws={"fontsize":12})
fig.patch.set_facecolor(background_color) # figure background color
ax0.set_facecolor(background_color)
ax0.text(0,-2.15,'Model Comparison',fontsize=18,fontweight='bold',fontfamily='serif')
ax0.text(0,-0.9,'Random Forest performs the best for overall Accuracy,\nbut is this enough? Is Recall more important in this case?',fontsize=14,fontfamily='serif')
ax0.tick_params(axis=u'both', which=u'both',length=0)
plt.show()
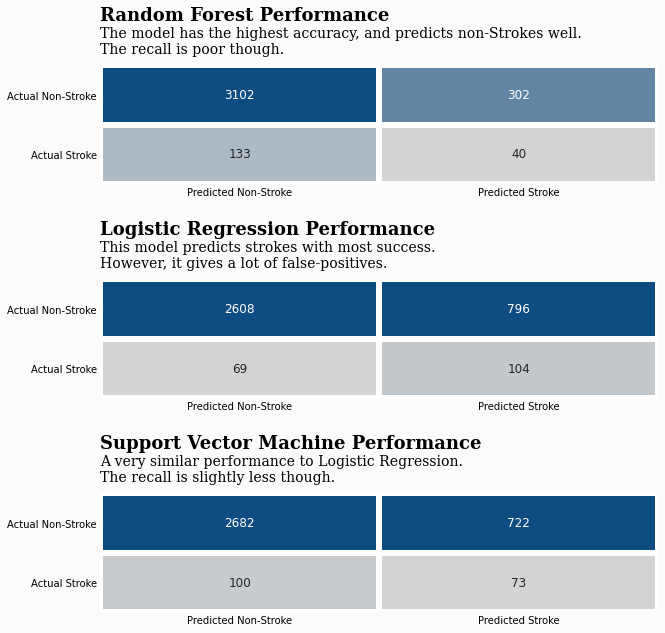
逐个模型的混淆矩阵
现在我们已经选择了模型,可以查看它们在每次预测中的表现。
这是一种很好的方法,可以直观地看出数据在哪些方面表现良好,哪些方面表现不佳。
# Plotting our results
colors = ["lightgray","#0f4c81","#0f4c81","#0f4c81","#0f4c81","#0f4c81","#0f4c81","#0f4c81"]
colormap = matplotlib.colors.LinearSegmentedColormap.from_list("", colors)
background_color = "#fbfbfb"
fig = plt.figure(figsize=(10,14)) # create figure
gs = fig.add_gridspec(4, 2)
gs.update(wspace=0.1, hspace=0.8)
ax0 = fig.add_subplot(gs[0, :])
ax1 = fig.add_subplot(gs[1, :])
ax2 = fig.add_subplot(gs[2, :])
ax0.set_facecolor(background_color) # axes background color
# Overall
sns.heatmap(rf_cm, cmap=colormap,annot=True,fmt="d", linewidths=5,cbar=False,ax=ax0,
yticklabels=['Actual Non-Stroke','Actual Stroke'],xticklabels=['Predicted Non-Stroke','Predicted Stroke'],annot_kws={"fontsize":12})
sns.heatmap(logreg_cm, cmap=colormap,annot=True,fmt="d", linewidths=5,cbar=False,ax=ax1,
yticklabels=['Actual Non-Stroke','Actual Stroke'],xticklabels=['Predicted Non-Stroke','Predicted Stroke'],annot_kws={"fontsize":12})
sns.heatmap(svm_cm, cmap=colormap,annot=True,fmt="d", linewidths=5,cbar=False,ax=ax2,
yticklabels=['Actual Non-Stroke','Actual Stroke'],xticklabels=['Predicted Non-Stroke','Predicted Stroke'],annot_kws={"fontsize":12})
ax0.tick_params(axis=u'both', which=u'both',length=0)
background_color = "#fbfbfb"
fig.patch.set_facecolor(background_color) # figure background color
ax0.set_facecolor(background_color)
ax1.tick_params(axis=u'both', which=u'both',length=0)
ax1.set_facecolor(background_color)
ax2.tick_params(axis=u'both', which=u'both',length=0)
ax2.set_facecolor(background_color)
ax0.text(0,-0.75,'Random Forest Performance',fontsize=18,fontweight='bold',fontfamily='serif')
ax0.text(0,-0.2,'The model has the highest accuracy, and predicts non-Strokes well.\nThe recall is poor though.',fontsize=14,fontfamily='serif')
ax1.text(0,-0.75,'Logistic Regression Performance',fontsize=18,fontweight='bold',fontfamily='serif')
ax1.text(0,-0.2,'This model predicts strokes with most success.\nHowever, it gives a lot of false-positives.',fontsize=14,fontfamily='serif')
ax2.text(0,-0.75,'Support Vector Machine Performance',fontsize=18,fontweight='bold',fontfamily='serif')
ax2.text(0,-0.2,'A very similar performance to Logistic Regression.\nThe recall is slightly less though.',fontsize=14,fontfamily='serif')
plt.show()
我们所有的模型都有相当高的准确率,最高的达到95%(调整随机森林)。但 “中风 ”的召回率却很低。
因此,在现实世界中,我可能会选择召回率最高的模型。
可以认为该模型是成功的,也就是说,医疗保健专业人员使用该模型会比不使用该模型更好。
鉴于随机森林的准确率确实最高,我将深入研究该模型及其工作原理–包括特征重要性和LIME。
您会选择哪种模型?
我会选择逻辑回归。它的准确率很高,召回率也最好。总的来说,我觉得它能提供最好的整体结果。
模型可解释分析
我将使用一些有价值的工具,帮助揭开机器学习算法所谓的 “黑匣子”。正如我常说的,我们创建的模型需要出售给业务利益相关者。如果业务利益相关者不了解我们创建的模型,他们可能就不会支持这个项目。
特征重要性
作为 “准确率 ”最高的模型(并不是本项目的最佳指标),我想我应该再做一些分析,让我们看看随机森林是如何进行预测的。
def rf_feat_importance(m, df):
return pd.DataFrame({'Feature':df.columns, 'Importance':m.feature_importances_}).sort_values('Importance', ascending=False)
fi = rf_feat_importance(rf_pipeline['RF'], X)
fi[:10].style.background_gradient(cmap=colormap)
background_color = "#fbfbfb"
fig, ax = plt.subplots(1,1, figsize=(10, 8),facecolor=background_color)
color_map = ['lightgray' for _ in range(10)]
color_map[0] = color_map[1] = color_map[2] = '#0f4c81' # color highlight
sns.barplot(data=fi,x='Importance',y='Feature',ax=ax,palette=color_map)
ax.set_facecolor(background_color)
for s in ['top', 'left', 'right']:
ax.spines[s].set_visible(False)
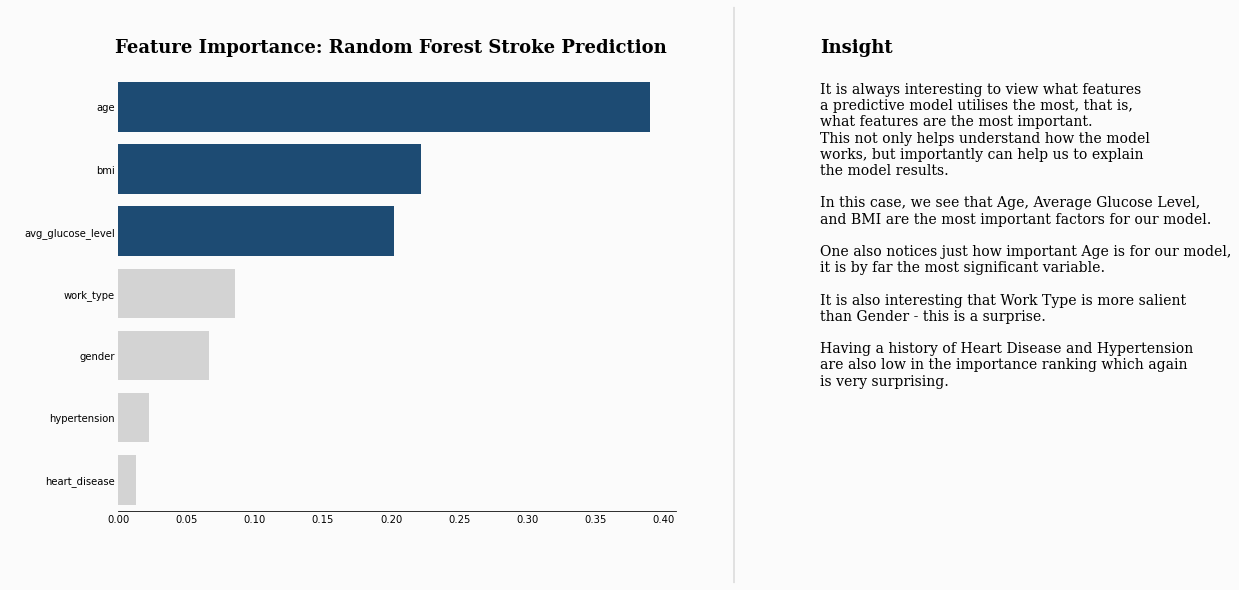
fig.text(0.12,0.92,"Feature Importance: Random Forest Stroke Prediction", fontsize=18, fontweight='bold', fontfamily='serif')
plt.xlabel(" ", fontsize=12, fontweight='light', fontfamily='serif',loc='left',y=-1.5)
plt.ylabel(" ", fontsize=12, fontweight='light', fontfamily='serif')
fig.text(1.1, 0.92, 'Insight', fontsize=18, fontweight='bold', fontfamily='serif')
fig.text(1.1, 0.315, '''
It is always interesting to view what features
a predictive model utilises the most, that is,
what features are the most important.
This not only helps understand how the model
works, but importantly can help us to explain
the model results.
In this case, we see that Age, Average Glucose Level,
and BMI are the most important factors for our model.
One also notices just how important Age is for our model,
it is by far the most significant variable.
It is also interesting that Work Type is more salient
than Gender - this is a surprise.
Having a history of Heart Disease and Hypertension
are also low in the importance ranking which again
is very surprising.
'''
, fontsize=14, fontweight='light', fontfamily='serif')
ax.tick_params(axis=u'both', which=u'both',length=0)
import matplotlib.lines as lines
l1 = lines.Line2D([0.98, 0.98], [0, 1], transform=fig.transFigure, figure=fig,color='black',lw=0.2)
fig.lines.extend([l1])
plt.show()
SHAP分析
SHAP值(SHapley Additive exPlanations)对预测进行细分,以显示每个特征的影响。
它将给定特征的某个值与我们在该特征取某个基线值(如零)的情况下所做的预测进行比较,从而解释其影响。
在本例中,我将把它用于随机森林模型。它可以用于任何类型的模型,但在基于树的模型中是最快的。
# great resource: https://www.kaggle.com/dansbecker/advanced-uses-of-shap-values
import shap
explainer = shap.TreeExplainer(rfc)
# calculate shap values. This is what we will plot.
shap_values = explainer.shap_values(X_test)
# custom colour plot
colors = ["#9bb7d4", "#0f4c81"]
cmap = matplotlib.colors.LinearSegmentedColormap.from_list("", colors)
shap.summary_plot(shap_values[1], X_test,cmap=cmap,alpha=0.4)
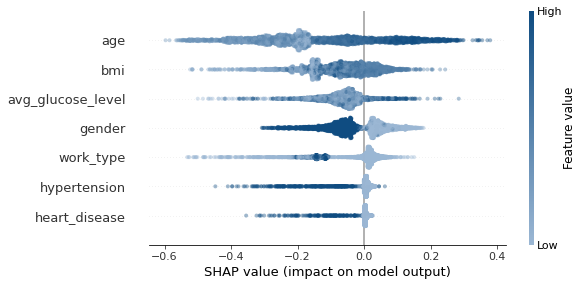
SHAP解释
上图显示了每个数据点对我们预测的影响。例如,对于年龄,左上角的点使预测值降低了0.6。
- 颜色显示的是该特征在数据集的该行中是高还是低
- 水平位置显示的是该值的影响导致的预测结果是高还是低。
我们还可以看到,我们的随机森林模型在很大程度上偏向于预测无中风。
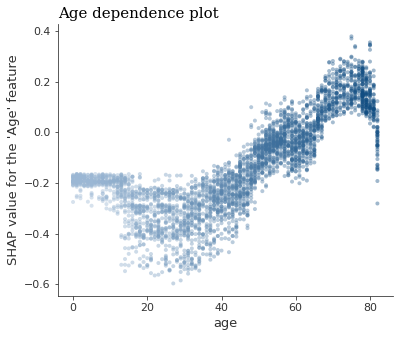
SHAP 依赖性图
我们还可以关注每个变量的影响是如何随着变量本身的变化而变化的。
例如,年龄。当该变量增加时,SHAP 值也会增加–使患者更接近我们的1条件(中风)。这也用颜色表示出来–粉色/红色代表中风患者。
shap.dependence_plot('age', shap_values[1], X_test, interaction_index="age",cmap=cmap,alpha=0.4,show=False)
plt.title("Age dependence plot",loc='left',fontfamily='serif',fontsize=15)
plt.ylabel("SHAP value for the 'Age' feature")
plt.show()
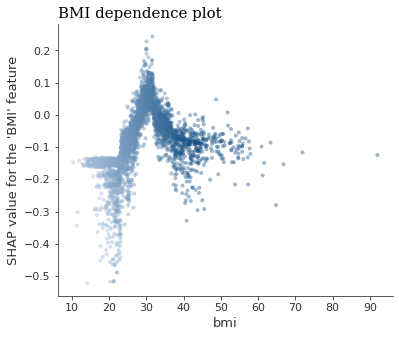
同样的图表,但有一个更有趣的变量。
在这里,我们可以看到一个明显的分界点–当体重指数(BMI)达到30左右时,中风就会变得更加常见。这就是 SHAP可视化的威力。
shap.dependence_plot('bmi', shap_values[1], X_test, interaction_index="bmi",cmap=cmap,alpha=0.4,show=False)
plt.title("BMI dependence plot",loc='left',fontfamily='serif',fontsize=15)
plt.ylabel("SHAP value for the 'BMI' feature")
plt.show()
使用 LIME 进行逻辑回归
在解释模型时,有时需要拆解并一次只关注一个例子。LIME 软件包就能做到这一点。
LIME 是 Local Interpretable Model-agnostic Explanations 的缩写,下面是一个例子:
import lime
import lime.lime_tabular
# LIME has one explainer for all the models
explainer = lime.lime_tabular.LimeTabularExplainer(X.values, feature_names=X.columns.values.tolist(),
class_names=['stroke'], verbose=True, mode='classification')
# Choose the jth instance and use it to predict the results for that selection
j = 1
exp = explainer.explain_instance(X.values[j], logreg_pipeline.predict_proba, num_features=5)
# Show the predictions
exp.show_in_notebook(show_table=True)
Intercept 0.10372756776442793
Prediction_local [0.30229972]
Right: 0.4570996057866643
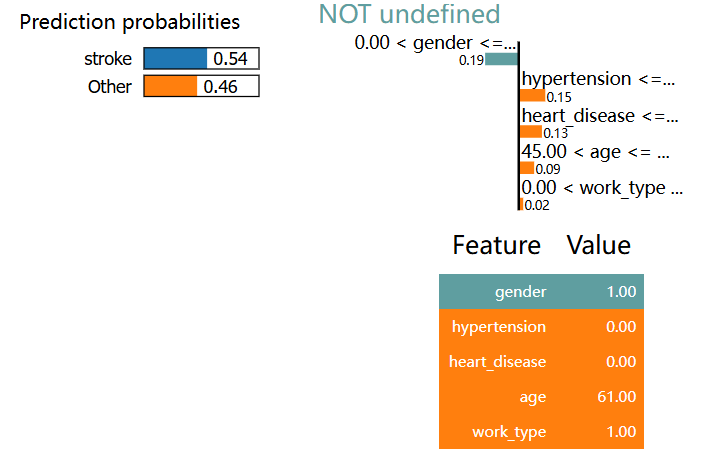
ELI5进行功能解释
在这里,我们可以看到每个变量的系数–换句话说,也就是我们的 Logistic 模型最看重的变量。
import eli5
columns_ = ['gender', 'age', 'hypertension', 'heart_disease', 'work_type',
'avg_glucose_level', 'bmi']
eli5.show_weights(logreg_pipeline.named_steps["LR"], feature_names=columns_)
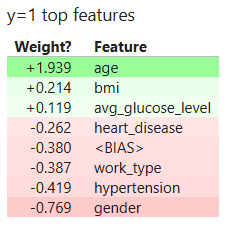
结论
我们从探索数据开始,注意到某些特征(如年龄)似乎是预测中风的良好指标。
在广泛的可视化之后,我们继续尝试多种模型。我们尝试了随机森林、SVM 和逻辑回归。然后,我尝试对所有模型进行超参数调整,看看能否改善它们的结果。
虽然随机正负模型的准确率最高,但调整后的逻辑回归模型的召回率和 f1分数最好。
因此,我选择了调整逻辑回归作为我的模型。
然而,我还没有完成。为了了解随机森林如何利用我们的数据获得最高准确率,我们研究了特征的重要性。我还引入了 SHAP。这有助于了解模型是如何进行预测的,以及它们可能会在哪些方面出错。
最后,我在我们选择的逻辑回归模型上使用了LIME和ELI5,以展示特征如何相互影响,从而在模型中产生最终预测结果。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









