







- openMP 简介
- Example 1 : 初识 openMP - Hello world!
- Example 2 : 不同线程任务分配 - for 循环
- Example 3 :不同线程任务分配 - sections 区域分配
- Example 4 : 不同线程任务分配 - master 区域分配 与 barrier 线程等待
- Example 5 : 变量线程作用域 - threadprivate 与 private
- Example 6 : atomic 与 critical
- Example 7 : 事件同步 nowait、sections、single、master
- Example 8 : 线程的调度优化
- 关键字字典
- 参考资料
在学习这个多进程方法之前, 要明确一下为什么需要这项技术。 在 C++中已经有很多库能够非常简单的部署多线程,就像boost::thread也能很容易的创建多线程。借用看到的一个回答 https://stackoverflow.com/questions/3949901/pthreads-vs-openmp
Pthreads and OpenMP represent two totally different multiprocessing paradigms.
Pthreads is a very low-level API for working with threads. Thus, you have extremely fine-grained control over thread management (create/join/etc), mutexes, and so on. It’s fairly bare-bones.
On the other hand, OpenMP is much higher level, is more portable and doesn’t limit you to using C. It’s also much more easily scaled than pthreads. One specific example of this is OpenMP’s work-sharing constructs, which let you divide work across multiple threads with relative ease. (See also Wikipedia’s pros and cons list.)
That said, you’ve really provided no detail about the specific program you’re implementing, or how you plan on using it, so it’s fairly impossible to recommend one API over the other.
同时,openMP的发展得到了各大芯片厂商的支持,比如AMD, IBM, Intel, Cray, HP, Fujitsu, Nvidia, NEC, Red Hat, Texas Instruments, Oracle Corporation。 openMP主要用于一台主机上的并行编程,而MPI( Message Passing Interface) 主要应用于多个节点之间的并行通信。
openMP 简介
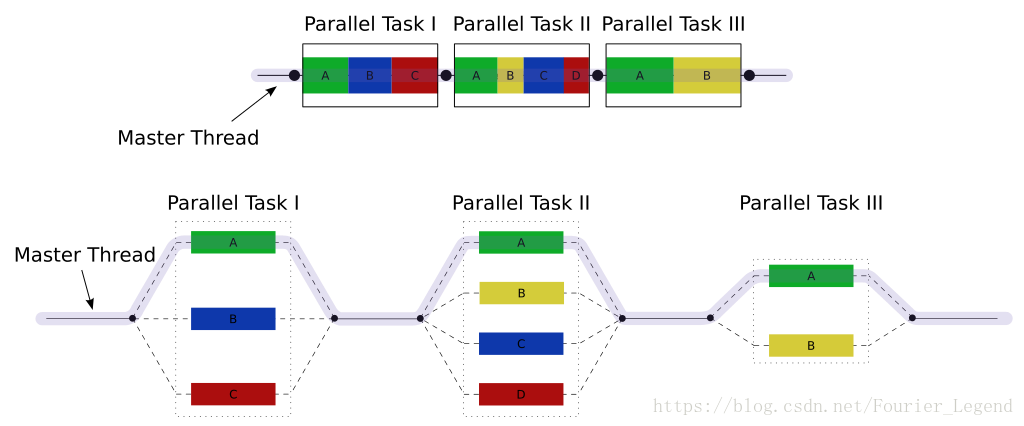
如下图所示, openMP会从主线程当中 fork() 出若干个线程,这些线程能够分配给不同的处理器并行执行,提升效率。
每一个线程都会赋予一个id,可以通过omp_get_thread_num() 命令查看当前线程的id号。 id 是一个整形的常数,主线程的id是0,各个子线程结束后主线程会返回主线程。
默认情况下, 每一个线程相互独立执行,可以使用work-sharing construct 让每个线程选择执行某一部分任务。
Example 1 : 初识 openMP - Hello world!
首先还是“hello world!” 一下
// hello.cpp
#include <stdio.h>
#include <omp.h> // 包含 openMP用到的库
int main(void)
{
#pragma omp parallel //到括号终止处的部分将会多线程执行
printf("Hello, world.\n");
return 0;
}编译
$ g++ -fopenmp hello.cpp -o hello
$ ./hello输出是
Hello, world.
Hello, world.
Hello, world.
Hello, world.奇怪了, 为什么会出现四次而不是别的数字, 这和我所用的电脑cpu有关, 我使用的电脑是双核同时有两个 虚拟核。 于是就产生了四个线程, 并行语句就执行了四次。
我们将代码稍作修改, 显示出每个线程的ID。
#include <stdio.h>
#include <omp.h>
int main(void)
{
int coreNum = omp_get_num_procs();//获得处理器个数
printf(" Core Num is %d \n", coreNum);
#pragma omp parallel
{int k = omp_get_thread_num();//获得每个线程的ID
printf("ID: %d Hello, world.\n",k);}
return 0;
}输出为
Core Num is 4
ID: 0 Hello, world.
ID: 3 Hello, world.
ID: 2 Hello, world.
ID: 1 Hello, world.综上, 电脑一共四个 Core, 并行部分会分别执行 “{ }” 内的内容。 当然让他重复输出四次显然不是我们需要的, 接下来我们看一下怎么去给每一个核分佩不一样的任务。
Example 2 : 不同线程任务分配 - for 循环
int main(int argc, char **argv)
{
int a[1000000];
#pragma omp parallel for
for (int i = 0; i < 1000000; i++) {
a[i] = 2 * i;
}
return 0;
}
这里多了一个关键字 for, 起作用编程将 for 循环中的内容分开交给各个线程去处理
Example 3 :不同线程任务分配 - sections 区域分配
#include <stdio.h>
#include <omp.h>
int main() {
#pragma omp parallel sections num_threads(4)
{
printf("Hello from thread %d\n", omp_get_thread_num());
printf("Hello from thread %d\n", omp_get_thread_num());
printf("Hello from thread %d\n", omp_get_thread_num());
#pragma omp section
{
printf("HELLO from thread %d !!!\n", omp_get_thread_num());
printf("HELLO from thread %d !!!\n", omp_get_thread_num());
printf("HELLO from thread %d !!!\n", omp_get_thread_num());
printf("HELLO from thread %d !!!\n", omp_get_thread_num());
printf("HELLO from thread %d !!!\n", omp_get_thread_num());
}
}
}
输出
Hello from thread 0
Hello from thread 0
Hello from thread 0
HELLO from thread 2 !!!
HELLO from thread 2 !!!
HELLO from thread 2 !!!
HELLO from thread 2 !!!
HELLO from thread 2 !!!一个section 内都一个线程去处理了
Example 4 : 不同线程任务分配 - master 区域分配 与 barrier 线程等待
master : 划定的部分将只有 id = 0 的主线程执行
barrier : 所有线程将会执行到这里停下, 等待所有线程执行完毕, 主线程继续执行。
#include <omp.h>
#include <stdio.h>
int main( )
{
int a[5], i;
#pragma omp parallel
{
// Perform some computation.
#pragma omp for
for (i = 0; i < 5; i++)
{a[i] = i * i;
printf(" A ---- Thread %d !!!\n", omp_get_thread_num());
}
// Print intermediate results.
#pragma omp master
for (i = 0; i < 5; i++)
{printf("a[%d] = %d ", i, a[i]);
printf(" ---- Thread %d !!!\n", omp_get_thread_num());
}
// Wait.
#pragma omp barrier // 先执行完毕的线程执行到这里会停下,直到所有线程都执行完再继续执行。
// 可以尝试注释掉看看效果, 执行数学会乱掉。
// Continue with the computation.
#pragma omp for
for (i = 0; i < 5; i++)
{a[i] += i;
printf(" B---- Thread %d !!!\n", omp_get_thread_num());
}
}
}
结果
A ---- Thread 3 !!!
A ---- Thread 0 !!!
A ---- Thread 0 !!!
A ---- Thread 1 !!!
A ---- Thread 2 !!!
a[0] = 0 ---- Thread 0 !!!
a[1] = 1 ---- Thread 0 !!!
a[2] = 4 ---- Thread 0 !!!
a[3] = 9 ---- Thread 0 !!!
a[4] = 16 ---- Thread 0 !!!
B---- Thread 1 !!!
B---- Thread 2 !!!
B---- Thread 3 !!!
B---- Thread 0 !!!
B---- Thread 0 !!!若注释掉 #pragma omp barrier , 则可能出现
A--- Thread 2 !!!
A--- Thread 0 !!!
A--- Thread 0 !!!
A--- Thread 1 !!!
A--- Thread 3 !!!
a[0] = 0 --- B--- Thread 2 !!!
C--- Thread 0 !!!
B--- Thread 3 !!!
B--- Thread 1 !!!
a[1] = 1 --- C--- Thread 0 !!!
a[2] = 6 --- C--- Thread 0 !!!
a[3] = 12 --- C--- Thread 0 !!!
a[4] = 20 --- C--- Thread 0 !!!
B--- Thread 0 !!!
B--- Thread 0 !!!可以看到, 线程执行完后就执行下一个任务,并不会等待全部完成, 直到最终的等待
规定 master 执行的地方一定是由 master 主线程去执行。 还可以看到, 在并行区域内 各个 for 循环也是先后依次执行, 只是每个for循环都调用了多个线程。
Example 5 : 变量线程作用域 - threadprivate 与 private
Specifies that a variable is private to a thread.
#pragma omp threadprivate(var)
private Example
#include <omp.h>
#include <stdio.h>
#include <time.h>
#include <iostream>
static long num_steps = 28;
double step;
#define NUM_THREADS 4
int main ()
{
int i;
double x, pi, sum = 0.0; // 多个变量定义方式
step = 1.0/(double) num_steps;
omp_set_num_threads(NUM_THREADS); // 设置使用的线程数
const clock_t begin_time = clock(); // 统计一下使用的时间
#pragma omp parallel for private(x) reduction(+:sum)
for (i=0;i< num_steps; i++){
printf("i: %d --- x: %f -- sum: %f---- Thread %d !!!\n",i, x, sum, omp_get_thread_num());
x = (i+0.5)*step;
sum = sum + 4.0/(1.0+x*x);
}
pi = step * sum;
printf("x: %f -- pi: %f---- Thread %d !!!\n", x, pi, omp_get_thread_num());
std::cout << float( clock () - begin_time ) / CLOCKS_PER_SEC << std::endl;
return 0;
}输出
i: 0 --- x: 0.000000 -- sum: 0.000000---- Thread 0 !!! // x 初始值
i: 1 --- x: 0.017857 -- sum: 3.998725---- Thread 0 !!!
i: 2 --- x: 0.053571 -- sum: 7.987278---- Thread 0 !!!
i: 3 --- x: 0.089286 -- sum: 11.955643---- Thread 0 !!!
i: 4 --- x: 0.125000 -- sum: 15.894104---- Thread 0 !!!
i: 5 --- x: 0.160714 -- sum: 19.793389---- Thread 0 !!!
i: 6 --- x: 0.196429 -- sum: 23.644786---- Thread 0 !!!
i: 7 --- x: 0.000000 -- sum: 0.000000---- Thread 1 !!! // x 初始值
i: 8 --- x: 0.267857 -- sum: 3.732223---- Thread 1 !!!
i: 9 --- x: 0.303571 -- sum: 7.394704---- Thread 1 !!!
i: 10 --- x: 0.339286 -- sum: 10.981779---- Thread 1 !!!
i: 11 --- x: 0.375000 -- sum: 14.488628---- Thread 1 !!!
i: 12 --- x: 0.410714 -- sum: 17.911275---- Thread 1 !!!
i: 13 --- x: 0.446429 -- sum: 21.246558---- Thread 1 !!!
i: 21 --- x: 0.000000 -- sum: 0.000000---- Thread 3 !!! // x 初始值
i: 22 --- x: 0.767857 -- sum: 2.516349---- Thread 3 !!!
i: 23 --- x: 0.803571 -- sum: 4.946886---- Thread 3 !!!
i: 24 --- x: 0.839286 -- sum: 7.293752---- Thread 3 !!!
i: 25 --- x: 0.875000 -- sum: 9.559239---- Thread 3 !!!
i: 26 --- x: 0.910714 -- sum: 11.745747---- Thread 3 !!!
i: 27 --- x: 0.946429 -- sum: 13.855756---- Thread 3 !!!
i: 14 --- x: 0.000000 -- sum: 0.000000---- Thread 2 !!! // x 初始值
i: 15 --- x: 0.517857 -- sum: 3.154136---- Thread 2 !!!
i: 16 --- x: 0.553571 -- sum: 6.215889---- Thread 2 !!!
i: 17 --- x: 0.589286 -- sum: 9.184883---- Thread 2 !!!
i: 18 --- x: 0.625000 -- sum: 12.061287---- Thread 2 !!!
i: 19 --- x: 0.660714 -- sum: 14.845749---- Thread 2 !!!
i: 20 --- x: 0.696429 -- sum: 17.539329---- Thread 2 !!!
x: 0.000000 -- pi: 3.141699---- Thread 0 !!! // 最后 x 值不改变, 返回主线程
0.0273threadprivate Example
#include <omp.h>
#include <stdio.h>
#include <time.h>
#include <iostream>
static long num_steps = 28;
double step;
double x; // x 必须是全局变量, 局部变量会报错
#define NUM_THREADS 4
//#pragma omp threadprivate(x)
int main ()
{
int i;
double pi, sum = 0.0; // 多个变量定义方式
step = 1.0/(double) num_steps;
omp_set_num_threads(NUM_THREADS); // 设置使用的线程数
const clock_t begin_time = clock(); // 统计一下使用的时间
#pragma omp parallel for reduction(+:sum)
for (i=0;i< num_steps; i++){
printf("i: %d --- x: %f -- sum: %f---- Thread %d !!!\n",i, x, sum, omp_get_thread_num());
x = (i+0.5)*step;
sum = sum + 4.0/(1.0+x*x);
}
pi = step * sum;
printf("x: %f -- pi: %f---- Thread %d !!!\n", x, pi, omp_get_thread_num());
std::cout << "Time Cost: "<<float( clock () - begin_time ) / CLOCKS_PER_SEC << std::endl;
return 0;
}threadprivate 必须是全局变量, 否则会报错
hello.cpp: In function ‘int main()’:
hello.cpp:15:31: error: automatic variable ‘x’ cannot be ‘threadprivate’
#pragma omp threadprivate(x)
i: 7 --- x: 0.000000 -- sum: 0.000000---- Thread 1 !!!
i: 8 --- x: 0.267857 -- sum: 3.732223---- Thread 1 !!!
i: 9 --- x: 0.303571 -- sum: 7.394704---- Thread 1 !!!
i: 10 --- x: 0.339286 -- sum: 10.981779---- Thread 1 !!!
i: 11 --- x: 0.375000 -- sum: 14.488628---- Thread 1 !!!
i: 14 --- x: 0.000000 -- sum: 0.000000---- Thread 2 !!!
i: 15 --- x: 0.517857 -- sum: 3.154136---- Thread 2 !!!
i: 16 --- x: 0.553571 -- sum: 6.215889---- Thread 2 !!!
i: 17 --- x: 0.589286 -- sum: 9.184883---- Thread 2 !!!
i: 18 --- x: 0.625000 -- sum: 12.061287---- Thread 2 !!!
i: 19 --- x: 0.660714 -- sum: 14.845749---- Thread 2 !!!
i: 20 --- x: 0.696429 -- sum: 17.539329---- Thread 2 !!!
i: 21 --- x: 0.000000 -- sum: 0.000000---- Thread 3 !!!
i: 22 --- x: 0.767857 -- sum: 2.516349---- Thread 3 !!!
i: 23 --- x: 0.803571 -- sum: 4.946886---- Thread 3 !!!
i: 24 --- x: 0.839286 -- sum: 7.293752---- Thread 3 !!!
i: 25 --- x: 0.875000 -- sum: 9.559239---- Thread 3 !!!
i: 26 --- x: 0.910714 -- sum: 11.745747---- Thread 3 !!!
i: 27 --- x: 0.946429 -- sum: 13.855756---- Thread 3 !!!
i: 12 --- x: 0.410714 -- sum: 17.911275---- Thread 1 !!!
i: 13 --- x: 0.446429 -- sum: 21.246558---- Thread 1 !!!
i: 0 --- x: 0.000000 -- sum: 0.000000---- Thread 0 !!!
i: 1 --- x: 0.017857 -- sum: 3.998725---- Thread 0 !!!
i: 2 --- x: 0.053571 -- sum: 7.987278---- Thread 0 !!!
i: 3 --- x: 0.089286 -- sum: 11.955643---- Thread 0 !!!
i: 4 --- x: 0.125000 -- sum: 15.894104---- Thread 0 !!!
i: 5 --- x: 0.160714 -- sum: 19.793389---- Thread 0 !!!
i: 6 --- x: 0.196429 -- sum: 23.644786---- Thread 0 !!!
x: 0.232143 -- pi: 3.141699---- Thread 0 !!! // 最后x 的值被改变
Time Cost: 0.006309
Difference between OpenMP threadprivate and private: https://stackoverflow.com/questions/18022133/difference-between-openmp-threadprivate-and-private
A private variable is local to a region and will most of the time be placed on the stack. The lifetime of the variable’s privacy is the duration defined of the data scoping clause. Every thread (including the master thread) makes a private copy of the original variable (the new variable is no longer storage-associated with the original variable).
A threadprivate variable on the other hand will be most likely placed in the heap or in the thread local storage (that can be seen as a global memory local to a thread). A threadprivate variable persist across regions (depending on some restrictions). The master thread uses the original variable, all other threads make a private copy of the original variable (the master variable is still storage-associated with the original variable).
Example 6 : atomic 与 critical
Specifies that a memory location that will be updated atomically.
critical与atomic的区别在于,atomic仅适用于上一节规定的两种类型操作,而且atomic所防护的仅为一句代码。critical可以对某个并行程序块进行防护
atomic Example
#include <stdio.h>
#include <omp.h>
#include <time.h>
#define MAX 100
int main() {
int count = 0;
#pragma omp parallel num_threads(MAX)
{
#pragma omp atomic //这里锁住了 count, 任何时候只能一个线程去修改访问count
count++;
printf(" Thread : %d --- Count : %d !!\n", omp_get_thread_num(), count);
}
printf("Number of threads: %d\n", count);
}
如果不加入 atomic, 可能会出错, 两个线程同事访问,但是count只进行了一个操作, 多个线程访问同一个全局变量, 注意保护每次只能有一个线程操作。
criticle Example
#include <iostream>
#include <omp.h> // OpenMP编程需要包含的头文件
int main()
{
int sum = 0;
std::cout << "Before: " << sum << std::endl;
#pragma omp parallel for
for (int i = 0; i < 100; ++i)
{
#pragma omp critical (sum)
{
sum = sum + i;
sum = sum + i * 2;
}
}
std::cout << "After: " << sum << std::endl;
return 0;
} What is the difference between atomic and critical in OpenMP?
The effect on g_qCount is the same, but what’s done is different.
An OpenMP critical section is completely general - it can surround any arbitrary block of code. You pay for that generality, however, by incurring significant overhead every time a thread enters and exits the critical section (on top of the inherent cost of serialization).
(In addition, in OpenMP all unnamed critical sections are considered identical (if you prefer, there’s only one lock for all unnamed critical sections), so that if one thread is in one [unnamed] critical section as above, no thread can enter any [unnamed] critical section. As you you might guess, you can get around this by using named critical sections).
An atomic operation has much lower overhead. Where available, it takes advantage on the hardware providing (say) an atomic increment operation; in that case there’s no lock/unlock needed on entering/exiting the line of code, it just does the atomic increment which the hardware tells you can’t be interfered with.
The upsides are that the overhead is much lower, and one thread being in an atomic operation doesn’t block any (different) atomic operations about to happen. The downside is the restricted set of operations that atomic supports.
Of course, in either case, you incur the cost of serialization.
Example 7 : 事件同步 nowait、sections、single、master
section: 用来指定不同的线程执行不同的部分
master: 只由 master 线程来执行该 部分
single : 只由一个线程来执行该部分
重点介绍一下: nowait 用来取消栅障
#include <iostream>
#include <omp.h> // OpenMP编程需要包含的头文件
int main()
{
#pragma omp parallel
{
#pragma omp for nowait
for (int i = 0; i < 100; ++i)
{
std::cout << "++" ;
}
#pragma omp for
for (int j = 0; j < 10; ++j)
{
std::cout << "--";
}
}
return 0;
} 输出
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++--++--++--++++++++++++++++++++++++++------++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++--++--++++++----观察输出,可以发现当一个线程执行完 for 循环分配的任务后, 它就去执行下一个线程的任务, 并不等待其它线程的结束。
注释掉 nowait 会出现
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++--------------------正常的顺序执行。
Example 8 : 线程的调度优化
| 调度策略 | 功能 | 适用情况 |
|---|---|---|
| static | 循环变量区域分为n等份,每个线程评分n份任务 | 各个cpu的性能差别不大 |
| dynamic | 循环变量区域分为n等份,某个线程执行完1份之后执行其他需要执行的那一份任务 | cpu之间运行能力差异较大 |
| guided | 循环变量区域由大到小分为不等的n份,运行方法类似于dynamic | 由于任务份数比dynamic,所以可以减少调度开销 |
| runtime | 在运行时来适用上述三种调度策略中的一种,默认是使用static |
static Example
#include <iostream>
#include <omp.h> // OpenMP编程需要包含的头文件
int main()
{
#pragma omp parallel for schedule(static, 2) //static调度策略,for循环每两次迭代分成一个任务
for (int i = 0; i < 10; ++i) //被分成了5个任务,其中循环0~1,4~5,8~9分配给了第一个线程,其余的分配给了第二个线程
{
std::cout << "Thread ID:" << omp_get_thread_num() << " Value:" << i << std::endl;
}
return 0;
} dynamic Example
#include <iostream>
#include <omp.h> // OpenMP编程需要包含的头文件
int main()
{
#pragma omp parallel for schedule(dynamic, 2) //dynamic调度策略,for循环每两次迭代分成一个任务
for (int i = 0; i < 20; ++i) //被分成了5个任务,只要有任务并且线程空闲,那么该线程会执行该任务
{
std::cout << "Thread ID:" << omp_get_thread_num() << " Value:" << i << std::endl;
}
return 0;
}
guided Example
guided调度策略与dynamic区别在于,所分的任务块是从大到小排列的。具体分块算法为:每块的任务大小为:[迭代次数/线程个数的二倍]。其中每个任务的最小迭代次数由guided声明决定,默认是1。
举例说明:
#pragma omp for schedule[guided, 80]
for (int i = 0; i < 800; ++i){}
有两个cpu,那么任务分配如下:
第一个任务:[800/2*2] = 200
第二个任务:第一个任务分了200,还有600,那么[600/2*2] = 150
第三个任务:第二个任务分了150,还有450,那么[450/2*2] = 113
第四个任务:第三个任务分了113,还有337,那么[337/2*2] = 85
第五个任务:第四个任务分了85,还有252,那么[252/2*2] = 63,小于声明的80,那么这里为80
第六个任务:第五个任务分了80,还有172,根据声明,这里为80(因为会小于80)
第七个任务:第六个任务分了80,还有92,根据声明,这里为80(因为会小于80)
第八个任务:第七个任务分了80,还有12,根据声明,这里为12(因为不够80)
关键字字典
| 关键字 | 解释 |
|---|---|
| Work-sharing constructs | 任务分配部分 |
| for | used to split up loop iterations among the threads, also called loop constructs. |
| sections | assigning consecutive but independent code blocks to different threads |
| single | specifying a code block that is executed by only one thread, a barrier is implied in the end |
| master | similar to single, but the code block will be executed by the master thread only and no barrier implied in the end. |
| Data sharing attribute clauses | 数据分享作用域 |
| shared | the data within a parallel region is shared, which means visible and accessible by all threads simultaneously. By default, all variables in the work sharing region are shared except the loop iteration counter. |
| private | the data within a parallel region is private to each thread, which means each thread will have a local copy and use it as a temporary variable. A private variable is not initialized and the value is not maintained for use outside the parallel region. By default, the loop iteration counters in the OpenMP loop constructs are private. |
| default | allows the programmer to state that the default data scoping within a parallel region will be either shared, or none for C/C++, or shared, firstprivate, private, or none for Fortran. The none option forces the programmer to declare each variable in the parallel region using the data sharing attribute clauses. |
| firstprivate | like private except initialized to original value. |
| lastprivate | like private except original value is updated after construct. |
| reduction | a safe way of joining work from all threads after construct. |
| Synchronization clauses | 同步关键词 |
| critical | the enclosed code block will be executed by only one thread at a time, and not simultaneously executed by multiple threads. It is often used to protect shared data from race conditions. |
| atomic | the memory update (write, or read-modify-write) in the next instruction will be performed atomically. It does not make the entire statement atomic; only the memory update is atomic. A compiler might use special hardware instructions for better performance than when using critical. |
| ordered | the structured block is executed in the order in which iterations would be executed in a sequential loop |
| barrier | each thread waits until all of the other threads of a team have reached this point. A work-sharing construct has an implicit barrier synchronization at the end. |
| nowait | specifies that threads completing assigned work can proceed without waiting for all threads in the team to finish. In the absence of this clause, threads encounter a barrier synchronization at the end of the work sharing construct. |
schedule(type, chunk): This is useful if the work sharing construct is a do-loop or for-loop. The iteration(s) in the work sharing construct are assigned to threads according to the scheduling method defined by this clause. The three types of scheduling are:
| Scheduling clauses | 任务预处理部分 |
|---|---|
| static | Here, all the threads are allocated iterations before they execute the loop iterations. The iterations are divided among threads equally by default. However, specifying an integer for the parameter chunk will allocate chunk number of contiguous iterations to a particular thread. |
| dynamic | Here, some of the iterations are allocated to a smaller number of threads. Once a particular thread finishes its allocated iteration, it returns to get another one from the iterations that are left. The parameter chunk defines the number of contiguous iterations that are allocated to a thread at a time. |
| guided | A large chunk of contiguous iterations are allocated to each thread dynamically (as above). The chunk size decreases exponentially with each successive allocation to a minimum size specified in the parameter chunk |
| IF control | if 语句 |
|---|---|
| if | This will cause the threads to parallelize the task only if a condition is met. Otherwise the code block executes serially. |
| Initialization | 初始化 |
|---|---|
| firstprivate | the data is private to each thread, but initialized using the value of the variable using the same name from the master thread. |
| lastprivate | the data is private to each thread. The value of this private data will be copied to a global variable using the same name outside the parallel region if current iteration is the last iteration in the parallelized loop. A variable can be both firstprivate and lastprivate. |
| threadprivate | The data is a global data, but it is private in each parallel region during the runtime. The difference between threadprivate and private is the global scope associated with threadprivate and the preserved value across parallel regions. |
| Data copying | 数据拷贝 |
|---|---|
| copyin | similar to firstprivate for private variables, threadprivate variables are not initialized, unless using copyin to pass the value from the corresponding global variables. No copyout is needed because the value of a threadprivate variable is maintained throughout the execution of the whole program. |
| copyprivate | used with single to support the copying of data values from private objects on one thread (the single thread) to the corresponding objects on other threads in the team. |
| Reduction | 回归操作 |
|---|---|
| reduction | the variable has a local copy in each thread, but the values of the local copies will be summarized (reduced) into a global shared variable. This is very useful if a particular operation (specified in operator for this particular clause) on a variable runs iteratively, so that its value at a particular iteration depends on its value at a prior iteration. The steps that lead up to the operational increment are parallelized, but the threads updates the global variable in a thread safe manner. This would be required in parallelizing numerical integration of functions and differential equations, as a common example. |
| other | 其它 |
|---|---|
| flush | The value of this variable is restored from the register to the memory for using this value outside of a parallel part |
| master | Executed only by the master thread (the thread which forked off all the others during the execution of the OpenMP directive). No implicit barrier; other team members (threads) not required to reach. |
参考资料
- OpenMP编程指南 https://software.intel.com/zh-cn/blogs/2009/04/20/openmp-2/
- 微软部分示例 https://msdn.microsoft.com/en-us/library/8ztckdts.aspx
- 维基百科 https://en.wikipedia.org/wiki/OpenMP
- A “Hands-on” Introduction to OpenMP: https://www.openmp.org/wp-content/uploads/omp-hands-on-SC08.pdf
- How to calculate a time difference in C++ https://stackoverflow.com/questions/728068/how-to-calculate-a-time-difference-in-c
6.一起来学OpenMP(1)——初体验 https://blog.csdn.net/lanfengfeng1120/article/details/53199291















 3064
3064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









