







//
==overview==
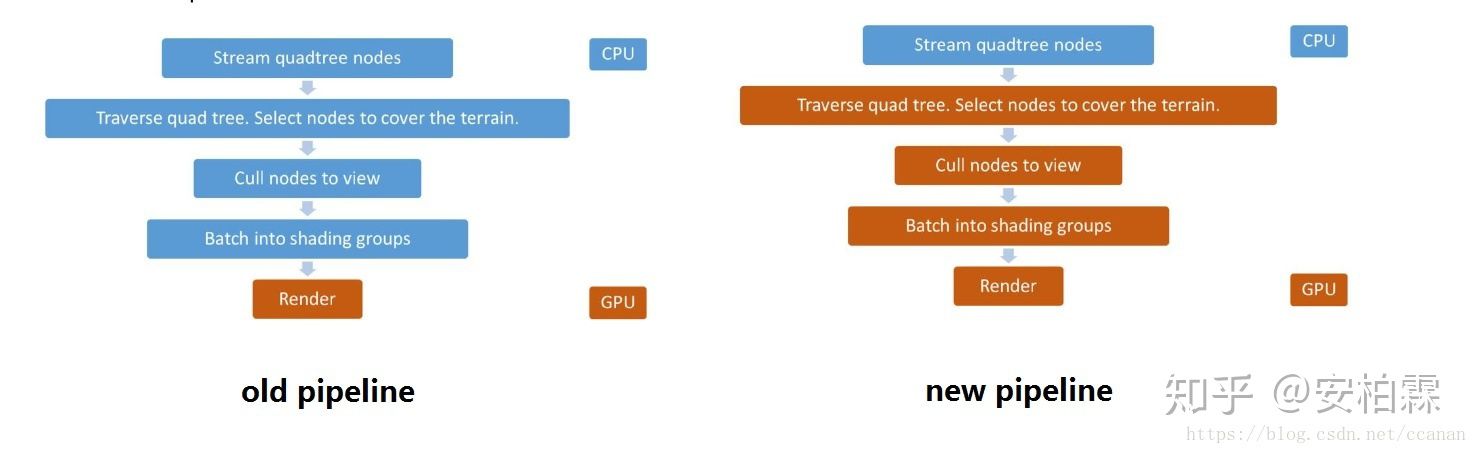
随着硬件的发展,我们可以看到GPU的计算能力远远的把CPU抛在后面,所以把更多的CPU端的计算放在GPU端,可以说是一个行业一直努力的方向。
渲染端cpu上面,一直以来,剔除和提交drawcall都是cpu做的,这部分一方面cpu可怜的计算力只能做的很粗糙,一方面消耗颇高,导致国内游戏行业谈性能必谈drawcall数量。
这部分离GPU很近,所以当然要先下手了。
其实早在PS3时代,强劲的spu,一定程度上我们可以理解为是一个更通用的GPGPU,就承担了这个任务,更激进的剔除和替代cpu进行drawcall提交,都让性能在cpu有质的飞跃,gpu也同时受益。
从dx11开始,都支持渲染的对象的部分参数由GPU来生成,可以说GPGPU来做这个事情的条件就也成熟了。
整体上在性能上的收获是非常大的:
- <刺客信条>,应该说几个paper里面受益最少的,但也非常的可观,标题图里的海量建筑
- cpu 比前一座,10x的obj,但是cpu却快了25%
- gpu也少渲染了20%到80%的triangle
- <farcry5>的地形
- gpu把quadtree traverse到lod map以及各种cull,0.1ms搞定。。。比cpu真是绝对优势
从15年的siggraph开始,ubi和EA都相继做了不少的分享,到了今年(2018)继续有新的游戏和引擎把这块用的更加成熟:
- siggraph15, < GPU-Driven Rendering Pipelines> @ ubisoft
- gdc16, < Optimizing the Graphics Pipeline With Compute> @ EA
- gdc18, TerrainRenderingFarCry5 @ ubisoft
- ...
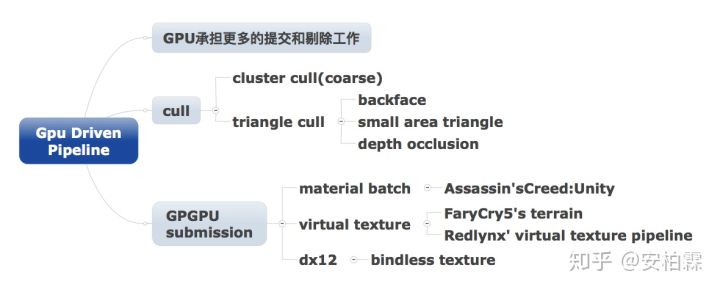
总的看来,GPU driven pipeline是有两个部分:
- 剔除--不只是offload了cpu的工作,进一步在gpu上做更aggressive的cull
- 提交--目标是一个drawcall结束战斗,根据实际情况进行折中了
==剔除==
这部分是通过gpgpu来先对要渲染的object进行剔除,这里ubi和ea都分成两个level来做,cluster和triangle
=cluster level cull=

把mesh分成固定的一些cluster,比如6400 vertices就分成100个cluster,每个cluster 64vertices,然后进行bound和orientation的cull。
=triangle level cull=
这里的backface,small area triangle都是老生常谈。
depth buffer这个,可以
- 在pc上使用cpu software rasterizer
- depth prepass, 然后downsample
- 使用上一帧的depth buffer做一个reprojection
使用其中的1个或几个组合。
==提交==
这里普遍的遇到项目老代码的问题,如果是dx12或者基于virtual texture的项目会简单些。
简单讲,就是要绑定的资源如果非常不同,还是难以硬放在一起来渲染。
这里< assassin's creed:unity >就是没法改的彻底,所以还是依据material来batch,那么可以说gpu driven的就相当不彻底。
而redlynx,pipeline是有比较重的virtual texture,farcry5的地形有virtual texture,那么资源就不需要改变绑定,那么就可以一个drawcall搞定一切,达到一个更彻底的gpu driven的程度。
dx12对此有更好的支持,可以更彻底的gpu driven了。
==效率对比==
- 刺客信条,应该说几个paper里面受益最少的,但也非常的可观
- cpu 比前一座,10x的obj,但是cpu却快了25%
- gpu也少渲染了20%到80%的triangle
farcry5
- gpu把quadtree traverse到lod map以及各种cull,0.1ms搞定。。。比cpu真是绝对优势
///
GPU-Driven Rendering Pipelines有一个口号是一个DrawCall渲染整个场景,这篇文章不讲虚拟贴图,只说mesh的处理部分。
静态合批
所谓静态合批就是在编辑器里将不同的Mesh,Instance合并成一个大Mesh的做法。
优点
合并过程不占用运行时
可以对不同Mesh进行合批
缺点
mesh不容易被剔除,因为合并的Mesh拥有一个比较大的包围盒,且包围盒不紧致。
顶点buffer中有大量重复的顶点和索引,因为相同的mesh,不同的instance,会被当成不同的mesh进行合并。
合并的索引数不能超过65536(16bit)
Instancing技术
D3D12只有两个DrwaCall接口DrawInstanced以及DrawIndexedInstanced,这两个接口都支持Instance渲染,所谓的Instance渲染,就是对于具有相同mesh的Instance,我们可以通过一个Drawcall把它们渲染出来。我们需要一个Instance buffer记录每个Instance的特有的数据比如Transfrom,在VS中我们根据Instance_Id来获取这些数据。
优点
顶点buffer没有重复的顶点和索引
单个mesh可以使用更多的索引
不需要占用CPU时间进行顶点和索引数据的合并
缺点
不支持多Mesh多Instance合批
Merge-Instancing
硬件Instance技术有一个缺点就是不能处理不同mesh,不同Instance的合并,Merge-Instancing技术就为解决这个问题提出的。首先我们需要将不同的mesh的顶点和索引,合并到一个大的Vertex Buffer及Index Buffer中,为了突破DrawCall接口的限制,我们需要手动fetch vertex。算法如下图:
无论怎样我们需要执行vs的次数=instace_count * perInstace_Index_count,上图的vertex_count就是vs执行的次数。因为每个mesh的顶点不同,我们不能使用Instance技术,我们只能将这些Instance当成是一个大Instance渲染(1个Instance,包含vertex_count个索引)。为了完成VS我们需要获取vertex数据(通过Index获取)以及Instacne data(通过Instance_id获取)。而目前的VS中只能获得vertex_id(这个id只是vs执行到了第几个顶点,也就是上图中的vertex)我们该如何获取顶点索引以及intance_id呢?
这就是Merge-Instancing的核心技术,每个mesh具有相同的拓扑结构,也就是具有相同的索引数量(上图的freq),如果拓扑结构固定,那么intance_id和顶点的索引就可以通过vertex_id求得了,如上图。使用Merge-Instancing就可以使用一个DrawCall渲染整个场景了(不考虑shader,贴图,buffer限制等其他因素)。
固定拓扑结构也就意味着如果某个mesh的索引数量小于这个值,就需要添加退化三角形来补充,这也是这套方案的缺点之一。另外我们注意到vs的执行次数和每个mesh的索引数量相关因此使用TRIANGLE_LIST和TRIANGLE_STRIP会直接影响vs的执行次数,TRIANGLE_LIST执行的次数会是TRIANGLE_STRIP的3倍。
Mesh Cluster Rendering
Mesh Cluster Rendering的主要目的是希望利用gpu高并发的特点,进行更精确的剔除操作。这个技术在预处理阶段会把mesh拆分成多个cluster,每个cluster会配备包围盒,backface mask,cone culling data等,这些数据都是为了做更精确的剔除,后面会去讲。
为什么每个Cluster包含三角面片是固定的?因为每个Cluster是由一个线程组处理,每个三角形由一个线程处理,为了保证算力能够充分利用,所以cluster需要固定数量的三角面数量。
为什么刺客信条是64 vertex strip,这个是根据不同的显卡以及项目实际性能测量确定的,对于n卡是32的倍数,对于a卡是64的倍数。
Merge-Instancing + Mesh Cluster Rendering
这两个技术加起来可以实现一个DrawCall渲染不同mesh不同Instance并且可以进行更加精确的剔除操作。但是它也由缺点,Assassin’s Creed Unity中指出其缺点:
Memory increase due to degenerate triangles,每个Instacne之间需要通过退化三角形补齐,每个Mesh的最后Cluster也需要退化三角形补齐。
Non-deterministic cluster order,首先为什么要对cluster排序,因为如果按照深度排序,可以减少overdraw(还有什么其他原因我就不知道了)。看Assassin’s Creed Unity的Paper中说到这个方法使用的是DrawInstanced接口,也就是说VS中只能拿到vertex_id。不过此时的情况和Merge-Instancing不同,这里的vertex buffer经历了各种剔除已经不是完整的vertex buffer了,因此肯定需要一个间接索引缓存,这个索引缓存中存储的是实际的vertex_id,然后通过这个vertex_id计算instance_id以及顶点的Index,这个间接的索引缓存是通过一个全量缓存计算得到的(全量缓存中标记所有三角面片是否被剔除,全量保证线程的并行性)。使用这种技术就决定了Cluster无法进行排序。
MultiDrawIndexedInstancedIndirect + Mesh Cluster Rendering
首先D3D12没有这个接口,这个接口的意思就是间接调用多次DrawIndexedInstanced,与上面的技术不同之处在于:
One (sub-)drawcall per instance
Requires appending index buffer on the fly
不需要退化三角形了
也可以Cluster排序了
这里有个细节上面的方案没有使用索引Buffer,主要原因是使用了三角形条带(顶点顺序即使索引),现在这套方案使用了索引Buffer,这里就有两种实现方式,一种是自己管理索引Buffer(不SetVB及SetIB),一种是使用VB和IB,如果使用三角条带的话,这两种方案区别不大,但是如果使用三角列表的话,自己管理索引Buffer则会调用更多次的VS,因为我们不会去做vertex fetch cache。所以这里建议使用VB和IB利用硬件的vertex fetch cache可以减少vs的调用,这也是为什么上面的方案使用的是DrawInstanced接口而这套方案使用的是DrawIndexedInstanced。
具体实现方式我在后面会详细介绍,先看一个完整的Pipeline:
第一步粗裁剪
这一步通常是大面积的剔除,比如四叉树剔除,Assassin’s Creed Unity是在cpu端做的,Far cry 5的地形系统是在gpu端做的,具体放在哪里做看实际需求。
第二步更新Instance数据
第三步Batch DrawCall
如何设置输出的Index buffer,预先设置固定大小的Buffer,大小是128K的N倍,为什么是128K,应该是和显卡的缓存相关。
异步计算,culling和rendering需要异步进行,如果是异步的话index buffer至少是同步的2倍,否则就需要同步等待了。
第四步Instance裁剪
根据Instance的包围体进行视锥体及遮挡剔除
保留的Instance需要连续存放到一个Buffer中,供后续步骤处理,这一步需要使用线程同步InterlockedAdd接口,为了提高性能可以使用前缀和算法进行改善,这里先用InterlockedAdd接口将流程串通,后面再介绍前缀和的优化处理。
关于线程组分配策略的优化,目前我还没有完全掌握,这个需要了解硬件结构以及功能需求后再做讨论,以后会单独做一篇文章。
Input资源,instance data table,这里存储了每一个instance的数据,比如包围盒信息,Transform信息,顶点数据的偏移量等等,这里的数据可以直接存储在table中,也可以在table中存储间接索引,具体权衡就是gpu读取数据的消耗以及gpu上传资源的消耗以及显存的占用情况。
Output资源,instance data index table,这里输出的是通过测试的instance的索引数据。
伪代码如下
//C++端代码
uint instanceCount = GetInstanceCount(batchId);//获取当前batch的instance个数
uint groupThreadCountX = instanceCount / perGroupThreadCount;
computeCmdList->Dispatch(groupThreadCountX,1,1);
//shader端代码
groupshared uint localValidInstanceCount;
//每个线程处理一个instance
[numthread(perGroupThreadCount,1,1)]
void main(uint3 threadGlobalId : SV_DispatchThreadID,
uint3 threadLocalId : SV_GroupThreadID)
{
if (threadLocalId.x == 0)
localValidInstanceCount = 0;
GroupMemoryBarrierWithGroupSync();
InstanceData data = LoadInstanceDataTable(threadGlobalId.x);
bool isSurvived = true;
//进行遮挡剔除以及视锥体剔除
......
uint localSlot;
if(isSurvived)
//此处有一次同步,可以通过前缀和优化
InterlockedAdd(localValidInstanceCount, 1, localSlot);
GroupMemoryBarrierWithGroupSync();
uint globalSlot;
if (threadLocalId.x == 0)
//此处有一次同步,其实是解决跨线程组计数的问题,也可以用前缀和处理,但是这样做有点本末倒置,此处同步的次数是线程组的个数相对上面的线程个数少太多了,本着否极泰来物极必反的原则,这里就不用前缀和了
InterlockedAdd(countBuffer[instanceCountIndex], localValidInstanceCount, globalSlot);
GroupMemoryBarrierWithGroupSync();
if (isSurvived)
StoreSurvieInstance(threadGlobalId.x);
GroupMemoryBarrierWithGroupSync();
if (threadGlobalId.x == 0)
//设置下一步Indirect draw参数
dispatchCommand.ThreadGroupCountX = countBuffer[instanceCountIndex];
dispatchCommand.ThreadGroupCountX = 1;
dispatchCommand.ThreadGroupCountX = 1;
}
第五步将Instacne拆分成chunk
为什么不直接拆分成cluster,因为每个instacne可能包含1~1024个cluster,这会导致每个线程的算力不平均,而且拆分cluster的数量比较多。
如何拆分,一个chunk包含64个cluster,也就是说一个instance可以包含1~16个chunk,其实拆分chunk也有算力不平均的问题,但是由于数量少,所以要比直接拆分成cluster要好
从这一步开始就需要使用ExecuteIndirect来调用DrawCall或者Dispatch,其实ExecuteIndirect接口的本质就是为了防止数据从gpu回传到cpu。
我们要记得裁剪的步骤越多因为裁剪所导致的性能消耗越多,比如ExecuteIndirect的消耗,PSO切换的消耗等等。像上面instance 裁剪以及chunk的划分这都是可选步骤,我们的原则是因为三角面片被剔除提升的性能要大于裁剪所带来的消耗,这里就不提用GPU换CPU的好处了。
这一步Input没有新增资源,使用的还是instance data index table
Output资源,需要一个存储chunk id的buffer。
//C++端代码
//切换PSO,设置根参数等
computeCmdList->ExecuteIndirect(
commandSignature.Get(),
1,
indirectCommandBuffer.Get(),
0,
nullptr,
0);
//shader端代码
groupshared uint localChunkCount;
//每个线程处理一个instance
[numthread(perGroupThreadCount,1,1)]
void main(uint3 threadGlobalId : SV_DispatchThreadID,
uint3 threadLocalId : SV_GroupThreadID)
{
if (threadLocalId.x == 0)
localChunkCount = 0;
GroupMemoryBarrierWithGroupSync();
InstanceData data = LoadInstanceDataTable(threadGlobalId.x);
uint chunkOffset = data.chunkOffset;
uint chunkCount = data.chunkCount;
GroupMemoryBarrierWithGroupSync();
uint localSlot;
//如果直接拆分成cluster这块会调用大量的InterlockedAdd函数
InterlockedAdd(localChunkCount, chunkCount , localSlot);
GroupMemoryBarrierWithGroupSync();
uint localSlot;
if (threadLocalId.x == 0)
InterlockedAdd(countBuffer[chunkCountIndex], localChunkCount, globalSlot);
GroupMemoryBarrierWithGroupSync();
for(uint i = 0; i < chunkCount; i++) {
chunkBuffer[globalSlot + localSlot + i].chunkId = chunkOffset + i;
//instacne id需要一直传递后面有用
chunkBuffer[globalSlot + localSlot + i].instanceId = instanceId;
}
GroupMemoryBarrierWithGroupSync();
if (threadGlobalId.x == 0)
//设置下一步Indirect draw参数
indirectCommand.dispatchCommand.ThreadGroupCountX = countBuffer[chunkCountIndex];
indirectCommand.dispatchCommand.ThreadGroupCountX = 1;
indirectCommand.dispatchCommand.ThreadGroupCountX = 1;
//不传过去,就需要在下一个shader中进行统计
indirectCommand.clusterCout = indirectCommand.dispatchCommand.ThreadGroupCountX] * 64;
}
第六步将chunk拆分成cluster
这一步就是常规的拆分,一个线程处理一个chunk,每一个chunk拆分的cluster索引是连续存储的。
Input资源,存储chunk id的Buffer。
Output资源,存储cluster id的Buffer。
//C++端代码
//切换PSO,设置根参数等
computeCmdList->ExecuteIndirect(
commandSignature.Get(),
1,
indirectCommandBuffer.Get(),
0,
nullptr,
0);
//shader端代码
//每个线程处理一个chunk
[numthread(perGroupThreadCount,1,1)]
void main(uint3 threadGlobalId : SV_DispatchThreadID,
uint3 threadLocalId : SV_GroupThreadID)
{
uint chunkid = LoadChunkId(threadGlobalId.x);
uint clusterOffset = LoadClusterId(chunkid);
uint instanceId = LoadInstanceId(chunkid);
for(int i = 0; i < 64; i++) {
clusterIdBuffer[threadGlobalId * 64 + i].clusterId = clusterOffset + i;
clusterIdBuffer[threadGlobalId * 64 + i].instanceId = instanceId;
}
GroupMemoryBarrierWithGroupSync();
if (threadGlobalId.x == 0)
//设置下一步Indirect draw参数, clusterCount是通多indirect command buffer传过来的
dispatchCommand.ThreadGroupCountX = clusterCount;
dispatchCommand.ThreadGroupCountX = 1;
dispatchCommand.ThreadGroupCountX = 1;
}
第7步cluster剔除
cluster会经历normal cone剔除,视锥体剔除以及遮挡剔除
Input资源,存储cluster id的Buffer。
Output资源,存储幸存的cluster id的Buffer。
//C++端代码
//切换PSO,设置根参数等
computeCmdList->ExecuteIndirect(
commandSignature.Get(),
1,
indirectCommandBuffer.Get(),
0,
nullptr,
0);
//shader端代码
groupshared uint localClusterCount;
//每个线程处理一个cluster
[numthread(perGroupThreadCount,1,1)]
void main(uint3 threadGlobalId : SV_DispatchThreadID,
uint3 threadLocalId : SV_GroupThreadID)
{
if (threadLocalId.x == 0)
localClusterCount = 0;
GroupMemoryBarrierWithGroupSync();
ClusterIndexData clusterIdData = LoadClusterIndexData(threadGlobalId.x);
InstanceData instanceData = LoadInstanceData(clusterIdData.instanceId);
ClusterData clusterData = LoadClusterData(clusterIdData.clusterId);
bool isSurvived = true;
//进行各种剔除
GroupMemoryBarrierWithGroupSync();
uint localSlot;
if (isSurvived)
InterlockedAdd(localClusterCount, 1, localSlot);
GroupMemoryBarrierWithGroupSync();
uint globaleSlot;
if (threadLocalId.x == 0)
InterlockedAdd(countBuffer[clusterSurvivedCountIndex], localClusterCount, globalSlot);
GroupMemoryBarrierWithGroupSync();
clusterSurvivedBuffer[globalSlot + localSlot].clusterId = clusterIdData.clusterId;
clusterSurvivedBuffer[globalSlot + localSlot].instanceId= clusterIdData.instanceId;
GroupMemoryBarrierWithGroupSync();
if (threadGlobalId.x == 0)
//设置下一步Indirect draw参数
indirectCommand.dispatchCommand.ThreadGroupCountX = countBuffer[clusterSurvivedCountIndex] * preClusterTriCount;
indirectCommand.dispatchCommand.ThreadGroupCountX = 1;
indirectCommand.dispatchCommand.ThreadGroupCountX = 1;
}
第八步三角面剔除
一个线程处理一个三角面
一个线程组只处理一个cluster,如果不这样做一个线程组就需要处理多个instance的Drawargs。
三角面剔除是否需要保证三角形的顺序,这涉及到vertext fecth cache以及一些功能的需求。如果需要保证顺序需要使用GPU的高级指令,比如AMD的ds_ordered_count,这块不熟悉,记得有这么个事。
cluster buffer里面记录的是顶点索引的偏移地址(merge mesh index),而Instance data里面存储的是instance index buffer中的偏移地址(merge instance index)。
//C++端代码
//切换PSO,设置根参数等
computeCmdList->ExecuteIndirect(
commandSignature.Get(),
1,
indirectCommandBuffer.Get(),
0,
nullptr,
0);
//shader端代码
groupshared uint localTriangleCount;
//每个线程处理一个Triangle
[numthread(perGroupThreadCount,1,1)]
void main(uint3 threadGlobalId : SV_DispatchThreadID,
uint3 threadLocalId : SV_GroupThreadID,
uint3 groupId : SV_GroupID)
{
if (threadLocalId.x == 0)
localTriangleCount = 0;
GroupMemoryBarrierWithGroupSync();
uint clusterId = LoadSurvivedClusterData[groupId.x].clusterId;
uint instanceId = LoadSurvivedClusterData[groupId.x].instanceId;
InstanceData instanceData = LoadInstanceData(instanceId);
ClusterData clusterData = LoadClusterData(clusterId);
uint vertexId0 = clusterData.offset + threadLocalId.x * 3;
uint vertexId1 = vertexId0++;
uint vertexId2 = vertexId1++;
Vertex vertex1 = IndexBuffer[instanceData.vertexOffset + vertexId0];
Vertex vertex1 = IndexBuffer[instanceData.vertexOffset + vertexId1];
Vertex vertex1 = IndexBuffer[instanceData.vertexOffset + vertexId2];
bool isSurvived = true;
//进行各种裁剪
GroupMemoryBarrierWithGroupSync();
uint localSlot;
if (isSurvived)
InterlockedAdd(localTriangleCount, 3, localSlot);
GroupMemoryBarrierWithGroupSync();
uint globaleSlot;
if (threadLocalId.x == 0)
InterlockedAdd(countBuffer[instanceId], localTriangleCount, globalSlot);
GroupMemoryBarrierWithGroupSync();
uint flyIndex0 = instanceData.indexOffset + globalSlot + localSlot;
uint flyIndex1 = flyIndex0++;
uint flyIndex2 = flyIndex1++;
FlyIndexBuffer[flyIndex0] = vertexId0;
FlyIndexBuffer[flyIndex1] = vertexId1;
FlyIndexBuffer[flyIndex2] = vertexId2;
GroupMemoryBarrierWithGroupSync();
if (threadLocalId.x == 0)
//设置下一步Indirect draw参数
indirectCommandBuffer[instanceId].drawargs.IndexCountPerInstance = countBuffer[instanceId];
indirectCommandBuffer[instanceId].drawargs.InstanceCount = 1;
indirectCommandBuffer[instanceId].drawargs.StartIndexLocation = instanceData.indexOffset;
indirectCommandBuffer[instanceId].drawargs.BaseVertexLocation = instanceData.vertexOffset;
indirectCommandBuffer[instanceId].drawargs.StartInstanceLocation = 0;
}
第九步剔除空DrawCall
有些instance被剔除了,无需调用,这里的剔除主要是利用ExecuteIndirect后面两个参数的设置,drawCall调用的次数是min(MaxCommandCount, pCountBuffer.size());
//C++端代码
//切换PSO,设置根参数等
computeCmdList->ExecuteIndirect(
commandSignature.Get(),
1,
indirectCommandBuffer.Get(),
0,
nullptr,
0);
//shader端代码
groupshared uint localValidDrawCount;
//每个线程处理一个cluster
[numthread(perGroupThreadCount,1,1)]
void main(uint3 threadGlobalId : SV_DispatchThreadID,
uint3 threadLocalId : SV_GroupThreadID)
{
if (threadLocalId.x == 0)
localValidDrawCount = 0;
bool isSurvived = true;
IndirectCommand drawArg = LoadIndirectCommand[threadGlobalId.x];
if (drawArg.IndexCountPerInstance < 0)
isSurvived = false;
GroupMemoryBarrierWithGroupSync();
uint localSlot;
if (isSurvived)
InterlockedAdd(localValidDrawCount, 1, localSlot);
GroupMemoryBarrierWithGroupSync();
uint globaleSlot;
if (threadLocalId.x == 0)
InterlockedAdd(batchData[batchIndex].drawCount, localValidDrawCount, globalSlot);
GroupMemoryBarrierWithGroupSync();
if (isSurvived)
indirectCommandBuffer[globalSlot + localSlot] = drawArg;
}
第十步调用DrawCall
这一步就是调用ExecuteIndirect没什么好说的
前缀和优化
多线程编程,同步会严重影响线程的并发性,而且同步的操作也会消耗性能。上面我们有两个点需要同步,一个是localSlot的增加,这个是线程组内部的同步,另一个是globalSlot的同步,这个是跨线程组之间的同步。可以看到组内线程之间的通信可以使用共享内存,跨组的线程通信只能靠外部显存了。
前缀和定义:


前缀和可以做很多事情,这里我们使用前缀和进行压缩数据流
可以看到如果我们用一个数组来存储该元素是否被保留,然后进行前缀和操作,得到的前缀和数组就可以做为输出数组的下标索引,这样我们就可以剔除那些被删除的元素,然后将保留的元素连续存储在一个输出的数组中。
//scatter results
if (cullFlag[tID] == 1)
{
outputDatas[prefixSum[tID]] = InputDatas[tID];
}
前缀和的串行实现很简单,但是并行实现算法稍微复杂一点,我要保证并行实现的算法的效率接近串行实现,串行实现的效率为n-1次加法也就是O(n),接下来我介绍一个并行实现的算法,效率为2*(n-1)加法,加上n-1次交互也可以算是O(n),该算法你可以把数组想象成一颗平衡二叉树的叶子节点。
算法分三步:
自底向上两个叶子节点相加,将结果保存到父节点上,这样根节点就是所有节点的和。
将根节点置零。
接下来的每一层,将父节点放到左子节点上,并将左子节点和父节点的和存到右子节点上。
前缀和的算法介绍完毕,但是在实现上我们需要注意bank冲突。为了增加共享缓存的读取带宽,共享缓存被分为多个Bank,一般Bank的数量和wrap的数量是相等的。共享缓存中连续数据的存储就和影院的座位一样,列就代表bank Id,先坐满一行再坐下一行。假如我们的wrap是32,读取数据的步长是1的话,每一个线程就会读取一个bank中的数据,这样多个线程就不会出现冲突。
当同一个线程组中的多个线程读取同一个bank id中的不同地址的数据时,就会产生bank冲突,这些冲突的线程需要按顺序等待读取数据,这样就大大降低了共享缓存的吞吐量。如果多个线程读取的是同一个bank中的同一个数据,这不会产生冲突,这种技术叫广播机制。在高级的CUDA中还有多播机制,就是一部分线程读取同一个数据,另一部分线程读取另一个数据,这个时候可以使用多播技术。
前缀和算法中会产生bank冲突,因为我们读取数据的步长是1,2,4,8,16,32,这样在极端的情况下会产生32路Bank冲突。这个很好理解假如我们bank数量是32,步长为1的时候,32个线程读取的是32个bank中的数据,因此没有冲突。如果步长是2的话,32个线程就需要读取64个位置的数据,那么前16个位置读取的是0~31Bank的数据,后16个位置读取的也是0~31Bank位置的数据,且这64个数据的地址都不一致,因此会产生2路Bank冲突。如果步长是4,则产出4路Bank冲突,后面依此类推,如下图:
解决的办法也很简单就是变更数据存储的位置,算法是以Bank数量为单位,每一个单位中间间隔一个空位置,比如0~15的位置不变,然后添加一个空位,这样本来是16~31位置的数据就变成17~32,然后再添加一个空位,原本32~47的位置就变成了34~49,依次类推。可以看到使用这个算法会增加存储前缀和的空间,增加的空间大小为bank num - 1。
经过测试解决bank冲突性能确实会有提升。
Instance剔除
Instance剔除这一步骤是可选的,因为Cluster会做更细致的剔除,这一步做与不做完全取决于剔除的Instance所带来的性能提升能是否大于处理这一步骤的性能消耗。
遮挡剔除(Hierarchical-Z)

如上图Hi-Z遮挡就是将物体投影到屏幕空间,然后比较物体覆盖的每个像素的深度,如果每个像素的深度都大于深度图,那么这个物体就被遮挡了。如果物体占了16*16个像素我们就需要比对256个像素,这个采样性能是不能接受的,实际上这个过程会被简化:
生成遮挡贴图或者使用上一帧的深度图
降采样,生成mipmap贴图,这里的混合是选取四个像素中深度最大的值
将物体的包围盒顶点转换到屏幕空间,求出所有顶点的最小深度值
根据包围盒UV坐标及贴图的分辨率,求取深度图的mipmap层级
如果mipmap层级像素不足2*2个像素,则使用上一层mipmap。
采样4个像素,选取最大的深度值与包围盒最小深度值比较,如果最小深度值比采样的最大深度值都大,那么物体被剔除
可以看到这个剔除算法是比较粗略的剔除,但是性能会好很多。
视锥体剔除
将包围盒转换到齐次裁剪空间或者是屏幕空间进行剔除,这种剔除并不是最高效的剔除算法,但是因为遮挡剔除也需要坐标转换,所以两个算法合并性能还是比较好的。
到底使用AABB包围盒还是包围球,还是其他包裹体,这里就不详细介绍了
剔除算法很简单,看下图

Cluster剔除
依然需要遮挡剔除及视锥体剔除,这部分和Instance剔除一致,Cluster有一个单独的剔除是normal cone剔除。
normal cone剔除

这个剔除是针对背面剔除的一个粗剔除,是以Cluster为单位,原理是求出一个圆锥包裹所有面的法线,如果视线与这个圆锥法线的夹角 > 90° + 圆锥的夹角,那么这个cluster就被剔除。途中的剔除公式是dot(cone.Normal,-view) < -sin(cone.angele)。
三角面剔除

三角面剔除整个流程好长,一个一个说吧:
背面剔除,这个算法有多种,刺客信条的算法是预计算一个立方体贴图,然后使用视线方向进行采样,这个立方体贴图很小1个面1bit,也就是一个三角形6bit的内存消耗。
零面积剔除,三个点距离小于一定的误差就被剔除
深度剔除,它这里使用的是NDC空间,我之前说的是屏幕空间,NDC空间少一步坐标转换。
小图元剔除,这个稍后介绍
视锥体贴图,同上
Samll Primitive Culling

这个剔除主要是提高光栅化阶段的性能,如上图GCN显卡一个时钟周期就可以对一个三角形光栅化16个像素,三角形覆盖的像素越低,光栅化的性能越低,并行计算的时代,不用就是浪费,这个步骤其实很简单就是剔除那些一个像素都没覆盖的三角行。这个和上面的零面积三角形剔除还是不一样的,如果一个大三角形拉的很远看,可能1个像素都分不到,这个看图就很明了了。




De-Interleaved Vertex Buffers

上面的图描述的很清晰,以前是一个顶点Buffer包含各种元素,现在是一个元素一个Buffer,这么做的好处有:
不同的shader可能需要不同的顶点结构,甚至相同的shader也可能需要不同的顶点结构,比如有的shader需要两套uv,有的shader需要一套。为了解决这个问题,以前的做法是针对每一种元素的组合,设置一个顶点Buffer,但这样做在切换shader的时候就需要切换顶点buffer,从而导致性能下降。为了合并批次,有些不同顶点结构的物体可能需要合并到同一个shader中,这样就会照成顶点数据的浪费,因为某一种物体可能压根用不上某个元素的数据。而将顶点数据拆分到不同的Buffer中,上面的问题就可以解决了,极端情况下,所有的shader可以共用一组顶点Buffer绑定,这样切换shader的时候,就不会因为顶点结构的不同而切换顶点Buffer。但需要的代价是以前instance data中可能只需要一个vertextOffset,现在可能需要多个offet,比如PositionOffset,NormalOffset,UVOffset。
充分利用cahe line,GPU剔除的时候只需要位置信息,如果按照SOA布局的化,这样会提高缓存的命中率。但是SOA对于后续的渲染来说不一定高效,因为渲染的VS中不仅仅使用Postion,它还需要读取其他数据进行插值处理。但是GPU剔除处理三角形的数量要多于渲染的三角面片。
SOA布局在cpu端也是一种高效的处理方式,这也是ECS架构的核心之一。
参考资料:
https://frostbite-wp-prd.s3.amazonaws.com/wp-content/uploads/2016/03/29204330/GDC_2016_Compute.pdf
http://advances.realtimerendering.com/s2015/aaltonenhaar_siggraph2015_combined_final_footer_220dpi.pdf
https://developer.nvidia.com/gpugems/gpugems3/part-vi-gpu-computing/chapter-39-parallel-prefix-sum-scan-cuda
/
//

















 507
507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









