







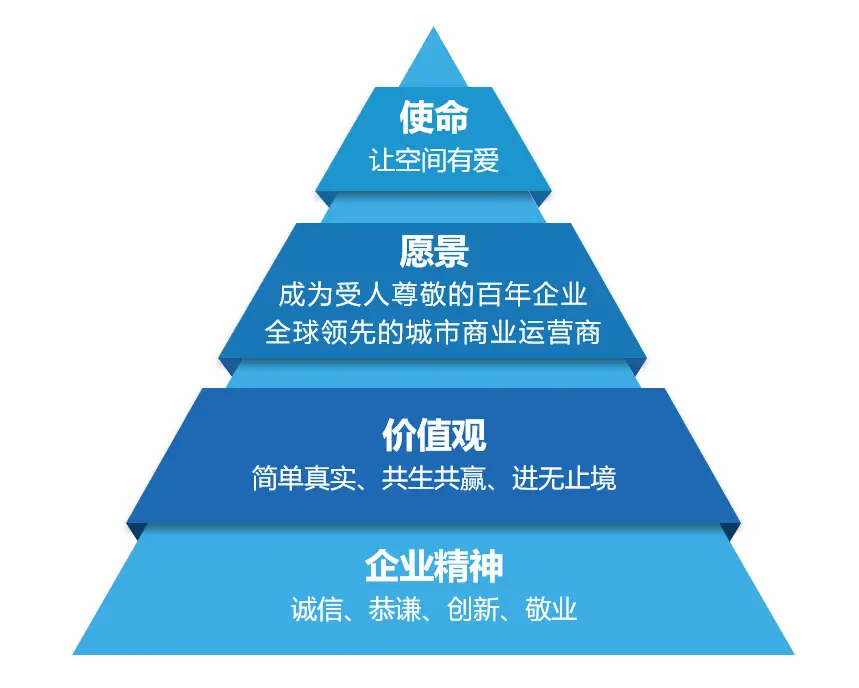
一、什么是使命、愿景、价值观
使命、愿景、价值观是组织或个人在发展过程中极为重要的三个核心要素,它们共同构成了组织或个人发展的精神支柱和行动指南,以下为你详细阐述:
使命(Mission)- 对别人、对社会的意义
- 定义:使命是组织或个人存在的根本目的和理由,回答了“我们为什么存在”的问题。它明确了组织或个人在更广泛的社会或行业背景中所承担的责任和义务,体现了其存在的核心价值。
- 特点
- 目的性:直接指向组织或个人存在的根本意图。
- 具体性:相对具体地描述了要达成的核心任务。
- 行动导向性:为日常活动提供了明确的方向指引。
- 示例
- 企业:阿里巴巴的使命是“让天下没有难做的生意”。这一使命清晰地阐述了阿里巴巴存在的意义,即通过提供各种商业服务和平台,降低商业运作的难度,帮助全球的商家和创业者更好地开展业务。
- 非营利组织:世界自然基金会的使命是“遏止地球自然环境的恶化,创造人类与自然和谐相处的美好未来”。这体现了该组织致力于保护自然环境、推动可持续发展的核心目标。
- 个人:一位医生的使命可能是“救死扶伤,守护人们的健康”,明确了其在医疗领域的核心职责和价值追求。
愿景(Vision)- 对自己成为的样子
- 定义:愿景是组织或个人对未来的期望和憧憬,描绘了“我们想要成为什么”的蓝图。它是一种远大的理想和目标,激励着组织或个人不断前进和发展。
- 特点
- 前瞻性:着眼于未来,具有前瞻性和战略性。
- 激励性:能够激发组织成员或个人的热情和动力,促使他们为实现愿景而努力奋斗。
- 理想性:通常具有一定的理想化色彩,是对未来美好状态的向往。
- 示例
- 企业:特斯拉的愿景是“加速世界向可持续能源的转变”。这一愿景展示了特斯拉希望在全球范围内推动能源转型,引领汽车行业和能源行业向更加可持续的方向发展的远大目标。
- 学校:一所知名大学的愿景可能是“成为世界一流的学术殿堂,培养具有全球视野和创新精神的领袖人才”。这体现了学校对自身未来发展的高远追求,以及在学术研究和人才培养方面的宏伟目标。
- 个人:一位运动员的愿景可能是“成为世界冠军,激励更多人热爱运动”,描绘了其在体育领域追求卓越、影响他人的理想状态。
价值观(Values)- 行为准则
- 定义:价值观是组织或个人在追求使命和实现愿景过程中所秉持的基本信念和行为准则,回答了“我们如何行事”的问题。它反映了组织或个人的道德观念、行为规范和价值取向,是组织文化和个人品格的重要组成部分。
- 特点
- 稳定性:一旦形成,具有相对的稳定性,不会轻易改变。
- 指导性:为组织成员或个人的决策和行为提供了基本的准则和依据。
- 凝聚性:有助于增强组织或个人的凝聚力和向心力,使成员在共同的价值观下团结协作。
- 示例
- 企业:谷歌的价值观包括“以用户为中心,其他一切水到渠成”“专心将一件事做到极致”“快比慢好”等。这些价值观体现了谷歌在产品设计、业务运营和团队合作等方面的基本原则和行为方式。
- 非营利组织:红十字会的价值观强调“人道、博爱、奉献”,这指导着其在救援行动、人道主义服务等方面的工作方式和行为准则。
- 个人:一个人的价值观可能是“诚实守信、勤奋努力、关爱他人”,这会影响其在日常生活和工作中的决策和行为。
三者关系
- 使命是基础:使命为愿景和价值观提供了存在的背景和理由,明确了组织或个人存在的根本目的。没有清晰的使命,愿景和价值观就缺乏根基,容易变得空洞和模糊。
- 愿景是方向:愿景在使命的基础上,为组织或个人描绘了未来的发展蓝图,是使命在时间维度上的延伸和具体化。它为组织或个人的发展提供了明确的方向和目标,引导着组织或个人不断前进。
- 价值观是保障:价值观是实现使命和愿景的保障,它规范了组织成员或个人的行为,确保在追求使命和实现愿景的过程中遵循正确的原则和准则。没有共同的价值观,组织或个人可能会出现内部矛盾和冲突,难以形成合力,从而影响使命的实现和愿景的达成。
二、如何通过使命、愿景、价值观看一家公司或创始人的是否值得加入?
通过使命、愿景、价值观来判断一家公司或创始人是否值得加入,需要从多个维度深入分析,以下为你详细阐述判断方法及要点:
使命维度
判断要点
- 是否清晰明确:清晰的使命能让你快速了解公司存在的意义和核心目标。若使命表述模糊、抽象,可能意味着公司自身定位不清晰,加入后你可能会在工作中感到迷茫,不清楚自己的工作对公司整体目标的贡献。
- 是否具有吸引力:使命应能激发你的热情和共鸣,让你觉得自己的工作是有价值和意义的。如果使命无法打动你,你可能很难在工作中保持积极的态度和动力。
- 是否与你的价值观契合:使命所体现的理念和追求应与你的个人价值观相符。例如,如果你重视环保,而公司的使命是推动绿色能源的发展,那么你们在价值观上就是契合的;反之,如果公司的使命与你的价值观相悖,加入后你可能会面临内心的冲突。
示例分析
- 值得加入的情况:一家医疗科技公司的使命是“利用先进技术,为全球患者提供更高效、更精准的医疗服务,拯救更多生命”。这个使命清晰明确,具有吸引力,且对于有医疗情怀、希望为人类健康事业做贡献的人来说,与个人价值观契合,值得考虑加入。
- 不值得加入的情况:一家公司的使命是“追求利润最大化,不考虑其他因素”。这样的使命过于功利,可能忽视了员工权益、社会责任等方面,与很多注重个人成长和社会价值的人的价值观不符,加入后可能会让你感到工作缺乏意义。
愿景维度
判断要点
- 是否具有前瞻性和挑战性:有前瞻性的愿景表明公司有远大的目标和抱负,愿意不断探索和创新。同时,具有挑战性的愿景也能激发你的潜力和创造力,让你在工作中不断成长和进步。
- 是否可实现:愿景虽然要有一定的前瞻性,但也必须是基于现实情况,有实现的可能性。如果愿景过于不切实际,可能会让你觉得公司是在空谈理想,缺乏实际行动和执行力。
- 是否能让你看到个人发展空间:一个好的愿景应该能让你看到自己在公司未来的发展前景和机会。如果愿景与你的职业规划和发展需求不匹配,加入后你可能会感到职业发展受限。
示例分析
- 值得加入的情况:一家互联网科技公司的愿景是“在未来五年内,成为全球领先的智能生活解决方案提供商,改变人们的生活方式”。这个愿景具有前瞻性和挑战性,同时也有一定的可实现性。对于有技术背景、希望在互联网行业有所作为的人来说,加入这样的公司有机会参与到具有影响力的项目中,实现个人价值。
- 不值得加入的情况:一家小型创业公司提出“在一年内成为全球最大的电商平台”。这样的愿景明显不切实际,缺乏对市场和自身实力的清醒认识。加入这样的公司,你可能会面临巨大的压力和风险,而且很难看到成功的希望。
价值观维度
判断要点
- 是否积极正面:公司的价值观应体现积极向上的精神,如诚信、创新、团队合作、客户至上等。这些价值观有助于营造良好的工作氛围,促进员工的成长和发展。
- 是否被真正践行:价值观不能仅仅停留在口号上,而应该在公司的日常运营和管理中得到真正体现。你可以通过了解公司的实际行为、员工反馈等方式来判断公司是否真正践行了其价值观。
- 是否与你的行为准则相符:公司的价值观应与你的个人行为准则相一致,这样你才能在工作中感到舒适和自在。如果公司的价值观与你的行为准则相冲突,你可能会在工作中面临道德困境。
示例分析
- 值得加入的情况:一家公司的价值观包括“诚信经营、鼓励创新、团队合作、关爱员工”。并且在日常工作中,公司确实注重产品质量,鼓励员工提出新想法,组织团队建设活动,关心员工的工作和生活。这样的公司价值观积极正面,且被真正践行,与很多人的行为准则相符,值得加入。
- 不值得加入的情况:一家公司声称重视团队合作,但在实际工作中,员工之间存在严重的内斗和竞争,缺乏有效的沟通和协作。这说明公司的价值观并没有得到真正落实,加入这样的公司可能会让你陷入复杂的人际关系中,影响工作效率和心情。
创始人维度
判断要点
- 创始人对使命、愿景、价值观的坚守程度:创始人是公司文化的塑造者和引领者,他们对使命、愿景、价值观的坚守程度直接影响着公司的发展方向和文化氛围。如果创始人能够始终如一地秉持这些理念,那么公司很可能会朝着正确的方向发展。
- 创始人的领导风格和能力:创始人的领导风格和能力决定了公司能否有效地实现使命和愿景。一个具有远见卓识、善于激励员工、能够带领团队克服困难的创始人,更有可能带领公司取得成功。
- 创始人的个人品质和口碑:创始人的个人品质和口碑也会对公司的形象和声誉产生影响。一个诚实守信、有社会责任感、受到员工和行业认可的创始人,更有可能打造出一个优秀的公司。
示例分析
- 值得加入的情况:某科技公司的创始人一直强调公司的使命是“用科技改善人们的生活”,并且始终将这一使命贯穿于公司的产品研发和市场推广中。他具有卓越的领导能力,善于发现和培养人才,带领团队取得了一系列的技术突破和市场成就。同时,他在行业内口碑良好,注重企业的社会责任。这样的创始人值得你跟随,加入这样的公司也更有发展前景。
- 不值得加入的情况:一家公司的创始人在公开场合宣扬公司的愿景是“成为行业的领军者”,但在实际经营中,却为了追求短期利益而忽视了产品质量和客户体验。他的领导风格专制,不善于倾听员工的意见,导致公司内部矛盾重重。这样的创始人难以带领公司实现长远发展,加入这样的公司风险较大。
通过以上对使命、愿景、价值观以及创始人的综合分析,你可以更全面、深入地了解一家公司或创始人是否值得加入。在做决策时,要结合自己的职业规划、价值观和个人需求,谨慎做出选择。



















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











