







一、GPU Gems3 Chapter 23:高速的离屏粒子
粒子特效一直是一个游戏开发中非常吃性能的点,特点就在于①数量不固定,在极端情况下同时存在的特效数量特别多,不且好合批;②其往往都为半透明物体,混合方式各有不同,同一个 pixel 可能会叠好几层特效。最后带来的结果就是:①大量的 DC,CPU 端优化不下去;②过多的 overdraw 也会带来 GPU 上的压力
而一种比较传统的优化方式就是离屏渲染:即将所有的粒子渲染到一张更低分辨率的 RT 上,并在后处理前把它混合回主渲染目标上,这可有效缓解②带来的性能问题
1.1 2007 年 GPU Gems3 中关于离屏粒子流程的简单介绍
这可以说是离屏粒子的起源,绝大多数的方案思路根源也都是这篇文章,尽管思路其实并不复杂,大致流程如下:
- 正常渲染场景中的不透明物体并开启深度写入
- 将当前深度缓存进行降采样到一张低分辨率的 RT 中
- 渲染粒子特效到一张离屏的 RT 中,其 RT 分辨率和前者深度 RT 一致
- 混合粒子的 RT 到主渲染目标,其中需要对粒子 RT 进行升采样
其中书中主要对如下的几个重点进行了详细介绍
- 一是粒子绘制到 RT 时使用的混合方式,以及最后与主渲染目标混合时,对应的混合公式(由于你粒子是离屏渲染的,渲染目标底色是黑色,因此在绘制粒子时,没有办法拿到当前 backbuffer 的颜色,无脑 alpha-blend 并不能得到正确的最终颜色,这里涉及了一些简单的数学公式,后面会有详细解释)
- 不同分辨率的 RT 混合可能会导致常规物体与粒子特效的交界处出现锯齿,需要探讨如何缓解这一部分的问题,书中的主要思路为边缘检测 + 修正
- 性能分析
1.2 现在离屏粒子应该怎么做
07年的渲染技术文章,放在现在来看确实有点“古文献”的感觉,特别是其中测试的显卡 GeForce8800 更是一个上古时代的老卡了,因此无脑造搬思路并不是一个好选择
考虑现在的硬件性能和主流的管线,我们或许可以少做一些事情……
1.2.1 深度信息考量
原文需要在绘制粒子之前,对当前的深度进行一次降采样拷贝
但是现在的主流管线中,无论是前向还是延迟,都可以在这个阶段直接拿到一张全分辨率的深度图,尽管这张图也不是白拿的也需要一个 blit 的成本,但是绝大多数情况下为了其它的效果,我们已经有了这张深度图了,就没必要降分辨率再拿一张,除非是另有用途
至少在绘制粒子的时候,可以不需要
1.2.2 是否可以接受的锯齿
文章中提供了一种边缘检测思路去解决低分辨率粒子升采样后出现的锯齿问题
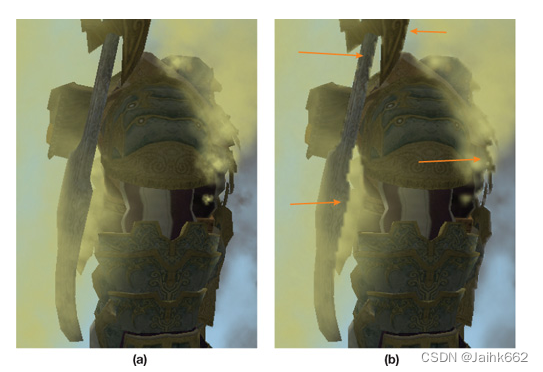
可以优化最终的效果但是会有额外成本,尽管在低分辨率下做这件事成本也不会太高,但是肯定能不做就不做,先测试下现在 PC 1920P 的分辨率下粒子边缘的锯齿情况:你甚至看不出来哪张是降了分辨率渲染的(其中一张图的分辨率长宽为另一张的 1/2)

移动平台由于屏幕不大,更不会出现什么问题,再考虑拿实际游戏中真实的场景(国战 20PVP,全部玩家同时放技能)进行测试、以及经过美术同学的评估,得出的最终结论是:完全可以接受的结果,相对于其它部分,没有必要做这一部分抗锯齿的优化
1.2.3 场景中的其它半透明物体,也需要离屏渲染嘛?
原文并没有考虑过场景中的其它半透明物体,可能是那时的设备,基本都会避免除粒子外的半透明物体的渲染,诸如酒瓶、玻璃这类的物品,都是通过 SSS 或全透明做的假半透效果
直接上一个结论:
- 如果场景中的半透明物体与特效之间发生穿插(特效 | 半透物件 | 特效),那么只对特效进行离屏渲染,得到的最终混合结果不可能完全正确,也做不到完全正确
- 如果场景中的半透明物体是最先被渲染的,即在所有的特效的后面(半透物件 | 特效 A | 特效 B),此时只对特效进行离屏渲染,可以得到正确的结果
- 如果场景中的半透明物体是最后被渲染的,即在所有的特效的最前面(特效 A | 特效 B | 半透物件),那么只对特效进行离屏渲染,需要保证渲染顺序为
不透明物体 -> 粒子离屏渲染 -> 粒子 RT 升采样并与主屏幕进行混合 -> 渲染半透明物体,才可得到正确的结果
整合而言就是:需要对所有的半透明物体都进行离屏渲染,才能保证最后混合结果完全正确,因此,与其说是粒子的离屏渲染,我们真正想做的是:所有常规半透明物体的离屏渲染,在这个方案下其中一个半透物体可以考虑在外,那就是水面,它可以被视为前面②中的情况
当然还有一个策略就是:只做离屏幕近的特效的离屏渲染,该策略有两个好处:
- 半透物体和特效物体混合问题发生概率大幅降低,只离屏绘制贴脸特效基本上只会出现上面②的情况
- 真正产生大量 overdraw,大量 frag 绘制的特效正是那种贴脸特效,其一个特效就占据了屏幕中的绝大部分面积,而许多离摄像机较远的特效其实是不会浪费太多 frag 绘制时间的,往往 drawcall 会先是瓶颈,离屏渲染优化这部分特效并没有什么收益
二、一个粒子离屏优化案例
写在最前面的注意事项:
- 本方案实现于 Unity URP,版本 2020+,需对 URP 源码做出略微修改,方式不唯一
- 所有离屏的粒子特效,只考虑 AlphaBlend 即 Addtive 两种主流混合方式
2.1 绘制特效的 RenderPass
创建一张低分辨率的粒子 RT,并且把需要绘制的物体筛选出来,非常简单的逻辑
筛选要绘制的物体有很多种方式,比如说指定 layer、或指定 Tag、按照渲染队列筛选也可以,案例中的策略是使用一个自己定义的 lightmode
public OffScreenParticlePass(OffScreenParticleSettings setting)
{
this.setting = setting;
particleLowResRT.Init("_ParticleLowResRT");
shaderTagIdList.Add(new ShaderTagId("OffScreenForward"));
filteringSettings = new FilteringSettings(RenderQueueRange.transparent, LayerMask.NameToLayer("Everything"));
}如果没有开启离屏渲染:修改原先半透物体渲染的 RenderPass,添加对应 ShaderTag,此时对应 Lightmode 的物件也会按照原先流程正常绘制
此操作需要修改 URP 源码:DrawObjectPass,也是唯一需要修改源码的地方,之所以改源码,而不是在原先的 shader 中多添加一个 subshader 或者 shaderpass,是为了避免变体数量增多,操作不当的话对应的 shader 会有原先两倍的变体
foreach (ShaderTagId sid in shaderTagIds)
m_ShaderTagIdList.Add(sid);
if (!UniversalRenderPipeline.assetRuntimeParams.offscreenRender)
m_ShaderTagIdList.Add(new ShaderTagId("OffScreenForward"));当然方案不唯一,这只是一个例子
2.1.1 两种粒子深度测试的方式
由于粒子是离屏渲染的,因此不能直接使用主摄像机的深度缓冲直接进行深度测试,下面提供两种离屏后深度测试的方案,先上个人结论:后者的方案应该更好一些,两者性能拉不开太大差距
第一个方案简单暴力:在绘制粒子的时候直接进行软深度测试
half partZ = i.vertex.w;
half sceneZ = LinearEyeDepth(SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, sampler_CameraDepthTexture, i.scrPos.xy / i.scrPos.w).r, _ZBufferParams);
float partZ = i.vertex.w;
float zalpha = saturate((sceneZ - partZ + 0.01) * 10000);
col.a *= zalpha;缺点很明显,尽管这应该是个主流方案:
- 美术要改 shader 的具体着色逻辑
- 每个 effect 每个 frag 都要进行深度测试,当 overdraw 过多时候有不少的额外性能开销,尽管这个开销应该远不及降分辨率渲染省下的性能开销,但还是能省则省
- 硬件 early-Z 在绘制粒子时完全失效
第二个方案:将主摄像机的当前深度缓冲数据写入离屏粒子 RT 的深度缓冲,之后再绘制粒子
需要多一次 Draw:绘制粒子的 RenderPass 需要在绘制所有粒子前先绘制一个全屏 Quad,在这次绘制时写好当前渲染目标的深度缓冲
CameraData cameraData = renderingData.cameraData;
CommandBuffer cmd = CommandBufferPool.Get(profilerTag);
using (new ProfilingScope(cmd, profilingSamplerr))
{
float flipSign = (cameraData.IsCameraProjectionMatrixFlipped()) ? -1.0f : 1.0f;
cmd.SetGlobalFloat("_ScaleBiasRt", flipSign);
cmd.DrawMesh(RenderingUtils.fullscreenMesh, Matrix4x4.identity, setting.copyDeptyMat, 0, 1);
context.ExecuteCommandBuffer(cmd);
cmd.Clear();
//接下来省略,逻辑为正常绘制特效
}Shader 部分多一个 pass,这个 pass 用于写深度:使用 SV_DEPTH 输出
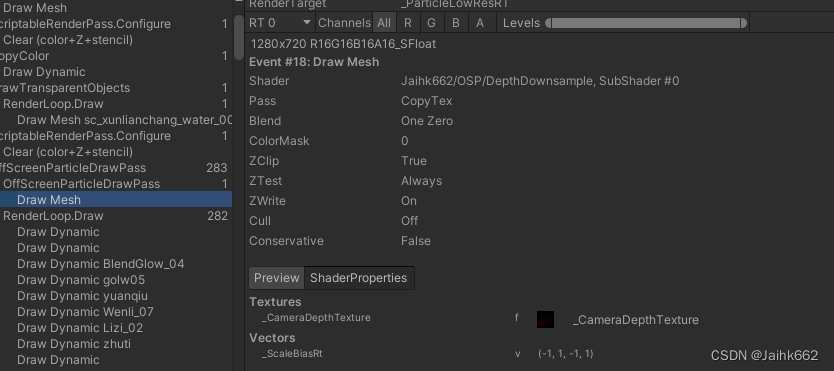
struct fragOut
{
float4 color : SV_target;
float depth : SV_DEPTH;
};
TEXTURE2D_FLOAT(_CameraDepthTexture); SAMPLER(sampler_CameraDepthTexture);
v2f vert(appdata v)
{
v2f o;
o.pos = float4(v.vertex.xyz, 1);
o.pos.y *= _ScaleBiasRt;
o.uv = v.texcoord;
return o;
}
fragOut frag(v2f i)
{
fragOut d;
d.depth = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, sampler_CameraDepthTexture, i.uv);
d.color = float4(i.uv, 0, 1);
return d;
}后面绘制特效的时候,正常进行 ZTest 即可,无需修改任何 frag 内容。性能相对于第一个方案开销恒定,为固定当前特效 RT 分辨率,不受粒子 overdraw 影响
2.2 离屏绘制混合方式
不考虑预乘,这里参考 GPU Gems3 中提供的方案,无需美术参与,通过简单修改混合模式解决
举一个例子:假设当前同一个 pixel 上有三个特效需要依次绘制,三个特效对应的 color 分别为 ,对应的 alpha 值为
,
为特效还没绘制任何特效时,当前颜色缓冲区的源颜色
2.2.1 仅考虑 alpha-blend 的混合
先只考虑 alpha-blend 的混合方式,对于正常绘制的情况,绘制第一个特效后,其 pixel 的颜色为
绘制完第二个特效后,其 pixel 的颜色为
绘制完最后一个(第三个)特效后,其 pixel 的最终颜色应为
那么离屏渲染粒子并最后混合回主屏幕的颜色,也应该是上面的 。不同于正常绘制,离屏渲染在绘制这些粒子时并不能拿到当前
的信息,也无法正常混合,只有在最后 merge 的时候,渲染目标才有
的信息,因此需要一些小小的操作,才能得到正确的结果
那么该如何操作呢?
绘制粒子时,由于没有 的信息,对上面的三个公式,把
作为未知参数,移项:
可以看到,要想最后能正确混合粒子 RT 及屏幕 RT:就需要在绘制粒子的时候,存储
正好,①只和 alpha 有关,可以存储在粒子 RT 的 alpha 中,②存储在粒子 RT 的 RGB 通道中
很明显,alpha 通道就是所有粒子的 alpha 值拿一减去后连续相乘,因此离屏绘制粒子时,其 alpha 通道需要设置单独的混合模式:即 Zero OneMinusSrcAlpha,而对于正常 RGB 混合模式,由于 项为零并不影响最终公式的结果,因此仍然为 SrcAlpha OneMinusSrcAlpha
Blend SrcAlpha OneMinusSrcAlpha, Zero OneMinusSrcAlpha正确设置了如上 blend mode 后,渲染完所有粒子,粒子 RT 的 RGB 通道存储值就为如上的 ,A 通道存储的值为如上的
,当然你还需要确保粒子 RT 在没有绘制任何物体前,其 buffer 要初始化为 (0, 0, 0, 1)(确保
项为零),即 Color.black
public override void Configure(CommandBuffer cmd, RenderTextureDescriptor cameraTextureDescriptor)
{
ConfigureTarget(new RenderTargetIdentifier(particleLowResRT.id));
ConfigureClear(ClearFlag.All, Color.black);
}2.2.2 同时考虑 alpha-blend 及 addtive 粒子的混搭混合
再考虑夹带 addtive 粒子的混合方式,原文中大致意思是 addtive 和 alpha-blend 要分开处理,但事实上,它们也只有 blendmode 的不同而已,完全可以混搭绘制到一张离屏 RT 中,不用独立处理,下面给出同时绘制 addtive 及 alpha-blend 粒子的混合方式及公式
一样假设当前同一个 pixel 上有三个特效需要依次绘制,三个特效对应的 color 分别为 ,对应的 alpha 值为
,
为特效还没绘制任何特效时,当前颜色缓冲区的源颜色,唯一的区别就是:第二个粒子的混合方式为 addtive
对于正常绘制的情况,绘制第一个特效后,其 pixel 的颜色为
绘制完第二个特效后,其 pixel 的颜色为
绘制完最后一个(第三个)特效后,其 pixel 的最终颜色应为
同样对 进行移项,得到
,可以看到,其本质就是
的一个特例
此时要想最后能正确混合粒子 RT 及屏幕 RT:就需要在绘制粒子的时候,存储
很明显,当前和前者只绘制 alpha-blend 物体不同的是:在绘制 addtive 物体时,并不需要对当前 alpha 通道做任何处理,其对应的 alpha blend-mode 就为 Zero One,同理 addtive 的 color blend mode 不变,仍然为 SrcAlpha One,除此之外原先 alpha-blend 的特效,和前者 2.2.1 混合方式一致
Blend SrcAlpha One, Zero One如果你的特效 shader 为 Ubershader,blend-mode 不写死通过参数控制,那么其最后离屏渲染修改后的特效 shader blend-mode 就应如下:
Blend [_Src] [_Dst], Zero [_Dst]2.3 离屏粒子 RT 混合回主渲染目标
这一步在后处理之前做,将粒子 RT 混合回主目标
也就在此时,渲染目标有前面的 信息,粒子 RT 存储的值为
,需要得到的最终混合结果
这个公式显而易见(如果不明白是怎么来的建议再看一次 2.2 的所有推导),这次 merge 的混合模式就也显而易见了,必然是 One SrcAlpha
Merge shader 也非常简单明了:
Blend One SrcAlpha
#pragma vertex vert
#pragma fragment frag
v2f vert(appdata v)
{
v2f o;
o.uv = v.texcoord;
}
float4 frag(v2f i) : SV_Target
{
float2 uv = i.uv;
#ifdef DEPTH_RESOLVE
//如果你需要做边缘抗锯齿,可以在这里处理升采样
#endif
float4 particleColor = SAMPLE_TEXTURE2D(_MainTex, sampler_MainTex, uv);
return particleColor;
}搞定!这只需要一次 cmd.blit 的操作与开销
2.4 特效与物体接壤处锯齿优化
不做,带来额外的性能负担且效果不明显,这边只丢几个参考文章:
2.5 实机性能分析
该方案仅能优化离屏物体带来的 GPU Frag 计算瓶颈
以下是一个 GPU 瓶颈优化案例:使用的设备为 Mi6(骁龙835),其中画面为游戏实机画面加上大量特效的结合,即除了主体大量的特效以外,还包含其它场景物件,包括但不限于 UI、水体、地形、大量人物角色等等,因此相对极端的测试案例可能优化有限
出于信息保密,画面内容及具体性能数据无法公开,只能贴下 profile,见谅
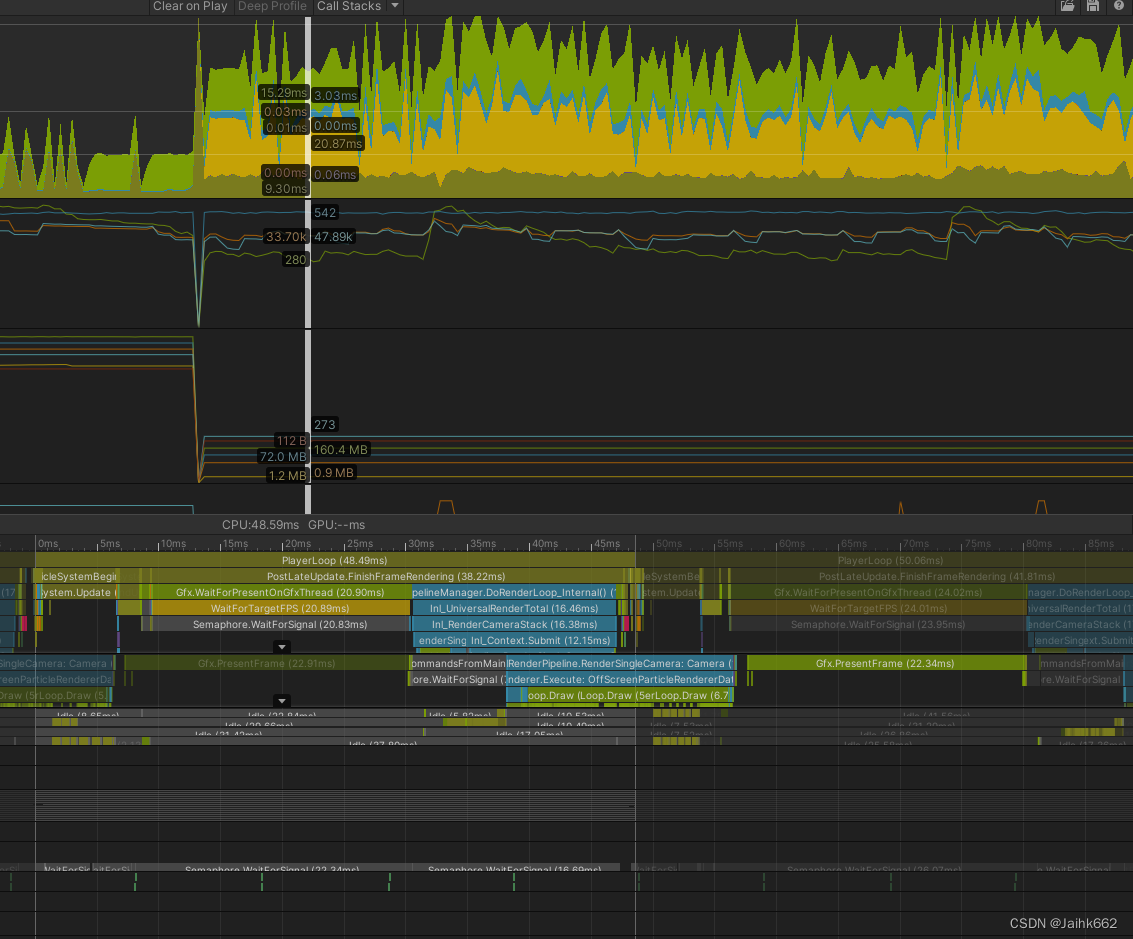
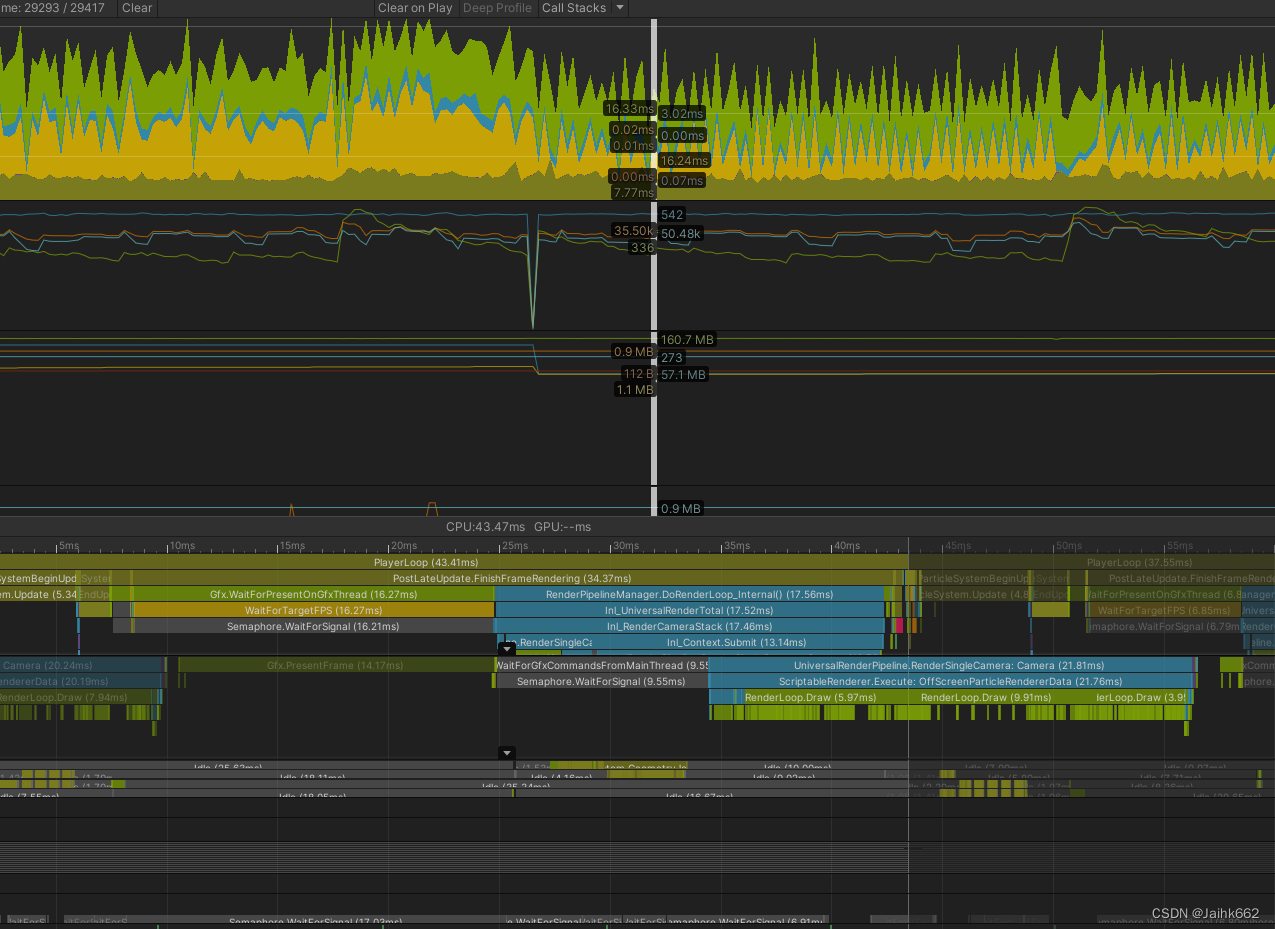
从上可见优化明显,CPU 等待 GPU 时间缩短
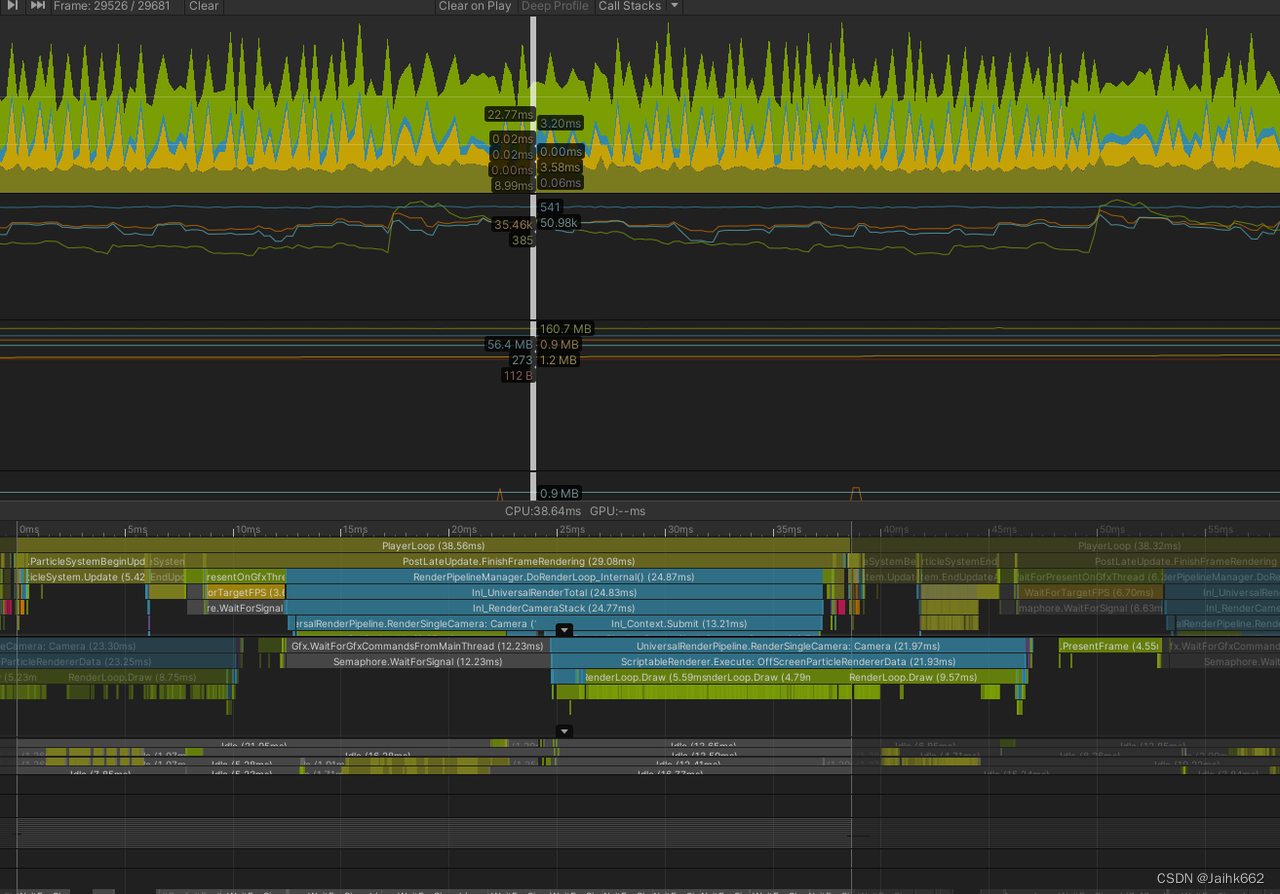
相对于前者,几乎就不再有优化了,因为此时已经是其它瓶颈了,再缩小分辨率并无收益
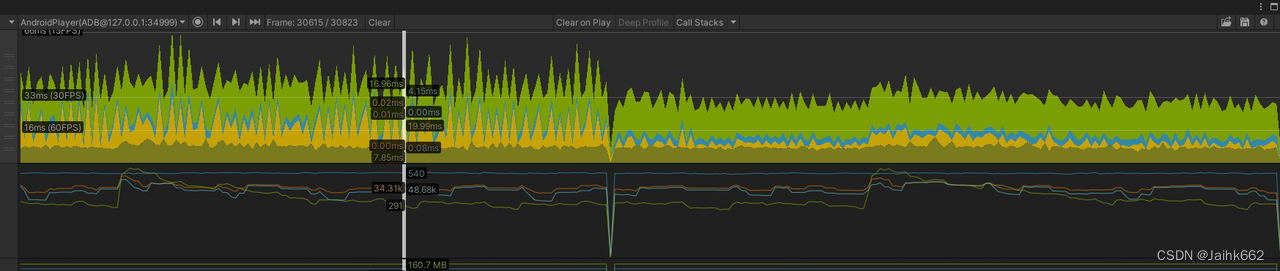
包括场景中的水在内,所有半透物体及特效全部离屏渲染结果,有明显的性能优化,但是游戏画质明显下降:原因是高频内容并不适合降分辨率渲染















 94
94

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









