










正定、超定、欠定矩阵
正定定义
方程个数等于未知量个数的方程组。
广义定义
设M是n阶方阵,如果对任何非零向量z,都有 z′Mz>0,其中z’ 表示z的转置,就称M正定矩阵。[1]
例如:B为n阶矩阵,E为单位矩阵,a为正实数。aE+B在a充分大时,aE+B为正定矩阵。(B必须为对称阵)。
狭义定义
一个n阶的实对称矩阵M是正定的当且仅当对于所有的非零实系数向量z,都有z′Mz>0。其中z’表示z的转置。
性质
正定矩阵在合同变换下可化为标准型, 即单位矩阵。
合同矩阵:两个实对称矩阵A和B,如存在可逆矩阵P,使得A=PTBP,就称矩阵A和B互为合同矩阵,并且称由A到B的变换叫合同变换。
所有特征值大于零的对称矩阵(或厄米矩阵)是正定矩阵。
判定定理1:对称阵A为正定的充分必要条件是:A的特征值全为正。
判定定理2:对称阵A为正定的充分必要条件是:A的各阶顺序主子式都为正。
判定定理3:任意阵A为正定的充分必要条件是:A合同于单位阵。
1.正定矩阵一定是非奇异的。非奇异矩阵的定义:若n阶矩阵A的行列式不为零,即|A|≠0。
2.正定矩阵的任一主子矩阵也是正定矩阵。
3.若A为n阶对称正定矩阵,则存在唯一的主对角线元素都是正数的下三角阵L,使得A=L∗L′,此分解式称为 正定矩阵的乔列斯基(Cholesky)分解。
4.若A为n阶正定矩阵,则A为n阶可逆矩阵。
矩阵的每一行代表一个方程,m行代表m个线性联立方程。 n列代表n个变量。如果m是独立方程数,根据m
超定方程组
方程个数大于未知量个数的方程组。
对于方程组 Ra=y,R为n×m矩阵,如果R列满秩,且n>m。
超定方程一般是不存在解的矛盾方程。
例如,如果给定的三点不在一条直线上,我们将无法得到这样一条直线,使得这条直线同时经过给定这三个点。 也就是说给定的条件(限制)过于严格, 导致解不存在。在实验数据处理和曲线拟合问题中,求解超定方程组非常普遍。比较常用的方法是最小二乘法。形象的说,就是在无法完全满足给定的这些条件的情况下,求一个最接近的解。
曲线拟合的最小二乘法要解决的问题,实际上就是求以上超定方程组的最小二乘解的问题。
欠定方程组
方程个数小于未知量个数的方程组。
对于方程组Ra=y,R为n×m 矩阵,且n<m。则方程组有无穷多组解,此时称方程组为欠定方程组。
内点法和梯度投影法是目前解欠定方程组的常用方法。
视觉标定中经常碰到这三种超定方程,简单总结下它们的一般解法。
线性非齐次方程组Ax=b,b~=0:最小二乘法 在matlab中 可以直接x=A\b,自己一般习惯x=(A’A)(Ab),两者在matlab中处理方法是一样的即 最小二乘法。
线性齐次方程组Ax=0:一般用svd分解,后者是求解特征后,得到最小的特征值对应的特征向量为方程组的解,解会有很多组,可以选取归一化的那组。当然方程组一般是超定的,应该应经过A’*A处理。
非线性方程组:levenlerg-marquaerdt,牛顿法等,前者用得比较多,在matlab中用lsqnonlin函数进行求救

转载https://www.cnblogs.com/pinard/p/6251584.html
奇异值分解(Singular Value Decomposition,以下简称SVD)是在机器学习领域广泛应用的算法,它不光可以用于降维算法中的特征分解,还可以用于推荐系统,以及自然语言处理等领域。是很多机器学习算法的基石。本文就对SVD的原理做一个总结,并讨论在在PCA降维算法中是如何运用运用SVD的。
1. 回顾特征值和特征向量
我们首先回顾下特征值和特征向量的定义如下:
Ax=λx 其中A是一个n×n的矩阵,x是一个n维向量,则我们说λ是矩阵A的一个特征值,而x是矩阵A的特征值λ所对应的特征向量。
求出特征值和特征向量有什么好处呢? 就是我们可以将矩阵A特征分解。如果我们求出了矩阵A的n个特征值λ1≤λ2≤...≤λn,以及这n个特征值所对应的特征向量{w1,w2,...wn},,如果这n个特征向量线性无关,那么矩阵A就可以用下式的特征分解表示:A=WΣW−1 其中W是这n个特征向量所张成的n×n维矩阵,而Σ为这n个特征值为主对角线的n×n维矩阵。
一般我们会把W的这n个特征向量标准化,即满足||wi||2=1, 或者说wTiwi=1,此时W的n个特征向量为标准正交基,满足WTW=I,即WT=W−1, 也就是说W为酉矩阵。 这样我们的特征分解表达式可以写成A=WΣWT
注意到要进行特征分解,矩阵A必须为方阵。那么如果A不是方阵,即行和列不相同时,我们还可以对矩阵进行分解吗?答案是可以,此时我们的SVD登场了。
2. SVD的定义
SVD也是对矩阵进行分解,但是和特征分解不同,SVD并不要求要分解的矩阵为方阵。假设我们的矩阵A是一个m×n
的矩阵,那么我们定义矩阵A的SVD为:A=UΣVT
其中U是一个m×m的矩阵,Σ是一个m×n的矩阵,除了主对角线上的元素以外全为0,主对角线上的每个元素都称为奇异值,V是一个n×n的矩阵。U和V都是酉矩阵,即满足UTU=I,VTV=I。下图可以很形象的看出上面SVD的定义:
那么我们如何求出SVD分解后的U,Σ,V这三个矩阵呢?
如果我们将A的转置和A做矩阵乘法,那么会得到n×n的一个方阵ATA。既然ATA是方阵,那么我们就可以进行特征分解,得到的特征值和特征向量满足下式:(ATA)vi=λivi
这样我们就可以得到矩阵ATA的n个特征值和对应的n个特征向量v了。将ATA的所有特征向量张成一个n×n的矩阵V,就是我们SVD公式里面的V矩阵了。一般我们将V中的每个特征向量叫做A的右奇异向量。
如果我们将A和A的转置做矩阵乘法,那么会得到m×m的一个方阵AAT。既然AAT是方阵,那么我们就可以进行特征分解,得到的特征值和特征向量满足下式:(AAT)ui=λiui
这样我们就可以得到矩阵AAT的m个特征值和对应的m个特征向量u了。将AAT的所有特征向量张成一个m×m
的矩阵U,就是我们SVD公式里面的U矩阵了。一般我们将U中的每个特征向量叫做A的左奇异向量。
U和V我们都求出来了,现在就剩下奇异值矩阵Σ没有求出了。由于Σ除了对角线上是奇异值其他位置都是0,那我们只需要求出每个奇异值σ就可以了。 我们注意到:A=UΣVT⇒AV=UΣVTV⇒AV=UΣ⇒Avi=σiui⇒σi=Avi/ui
这样我们可以求出我们的每个奇异值,进而求出奇异值矩阵Σ
上面还有一个问题没有讲,就是我们说ATA的特征向量组成的就是我们SVD中的V矩阵,而AAT的特征向量组成的就是我们SVD中的U矩阵,这有什么根据吗?这个其实很容易证明,我们以V矩阵的证明为例。
A=UΣVT⇒AT=VΣTUT⇒ATA=VΣTUTUΣVT=VΣ2VT
上式证明使用了:UTU=I,ΣTΣ=Σ2。
可以看出ATA的特征向量组成的的确就是我们SVD中的V矩阵。类似的方法可以得到AAT的特征向量组成的就是我们SVD中的U矩阵。 进一步我们还可以看出我们的特征值矩阵等于奇异值矩阵的平方,也就是说特征值和奇异值满足如下关系:
σi=λi‾‾√ 这样也就是说,我们可以不用σi=Avi/ui来计算奇异值,也可以通过求出ATA的特征值取平方根来求奇异值。
3. SVD计算举例

4. SVD的一些性质
上面几节我们对SVD的定义和计算做了详细的描述,似乎看不出我们费这么大的力气做SVD有什么好处。那么SVD有什么重要的性质值得我们注意呢?
对于奇异值,它跟我们特征分解中的特征值类似,在奇异值矩阵中也是按照从大到小排列,而且奇异值的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上的比例。也就是说,我们也可以用最大的k个的奇异值和对应的左右奇异向量来近似描述矩阵。也就是说:
Am×n=Um×mΣm×nVTn×n≈Um×kΣk×kVTk×n
其中k要比n小很多,也就是一个大的矩阵A可以用三个小的矩阵Um×k,Σk×k,VTk×n
来表示。如下图所示,现在我们的矩阵A只需要灰色的部分的三个小矩阵就可以近似描述了。
由于这个重要的性质,SVD可以用于PCA降维,来做数据压缩和去噪。也可以用于推荐算法,将用户和喜好对应的矩阵做特征分解,进而得到隐含的用户需求来做推荐。同时也可以用于NLP中的算法,比如潜在语义索引(LSI)。下面我们就对SVD用于PCA降维做一个介绍。
5. SVD用于PCA
在主成分分析(PCA)原理总结中,我们讲到要用PCA降维,需要找到样本协方差矩阵XTX
的最大的d个特征向量,然后用这最大的d个特征向量张成的矩阵来做低维投影降维。可以看出,在这个过程中需要先求出协方差矩阵XTX
,当样本数多样本特征数也多的时候,这个计算量是很大的。
注意到我们的SVD也可以得到协方差矩阵XTX最大的d个特征向量张成的矩阵,但是SVD有个好处,有一些SVD的实现算法可以不求先求出协方差矩阵XTX,也能求出我们的右奇异矩阵V
。也就是说,我们的PCA算法可以不用做特征分解,而是做SVD来完成。这个方法在样本量很大的时候很有效。实际上,scikit-learn的PCA算法的背后真正的实现就是用的SVD,而不是我们我们认为的暴力特征分解。
另一方面,注意到PCA仅仅使用了我们SVD的右奇异矩阵,没有使用左奇异矩阵,那么左奇异矩阵有什么用呢?
假设我们的样本是m×n的矩阵X,如果我们通过SVD找到了矩阵XXT最大的d个特征向量张成的m×d维矩阵U,则我们如果进行如下处理:X′d×n=UTd×mXm×n 可以得到一个d×n的矩阵X‘,这个矩阵和我们原来的m×n维样本矩阵X相比,行数从m减到了k,可见对行数进行了压缩。也就是说,左奇异矩阵可以用于行数的压缩。相对的,右奇异矩阵可以用于列数即特征维度的压缩,也就是我们的PCA降维。
6. SVD小结
SVD作为一个很基本的算法,在很多机器学习算法中都有它的身影,特别是在现在的大数据时代,由于SVD可以实现并行化,因此更是大展身手。SVD的原理不难,只要有基本的线性代数知识就可以理解,实现也很简单因此值得仔细的研究。当然,SVD的缺点是分解出的矩阵解释性往往不强,有点黑盒子的味道,不过这不影响它的使用.
来源:知乎 作者:赵文和 链接:https://www.zhihu.com/question/19666954/answer/54788626
首先,矩阵可以认为是一种线性变换,而且这种线性变换的作用效果与基的选择有关。
以Ax = b为例,x是m维向量,b是n维向量,m,n可以相等也可以不相等,表示矩阵可以将一个向量线性变换到另一个向量,这样一个线性变换的作用可以包含旋转、缩放和投影三种类型的效应。
奇异值分解正是对线性变换这三种效应的一个析构。
A=
2.SVD应用于推荐系统
数据集中行代表用户user,列代表物品item,其中的值代表用户对物品的打分。基于SVD的优势在于:用户的评分数据是稀疏矩阵,可以用SVD将原始数据映射到低维空间中,然后计算物品item之间的相似度,可以节省计算资源。
整体思路:先找到用户没有评分的物品,然后再经过SVD“压缩”后的低维空间中,计算未评分物品与其他物品的相似性,得到一个预测打分,再对这些物品的评分从高到低进行排序,返回前N个物品推荐给用户。
具体代码如下,主要分为5部分:
第1部分:加载测试数据集;
第2部分:定义三种计算相似度的方法;
第3部分:通过计算奇异值平方和的百分比来确定将数据降到多少维才合适,返回需要降到的维度;
第4部分:在已经降维的数据中,基于SVD对用户未打分的物品进行评分预测,返回未打分物品的预测评分值;
第5部分:产生前N个评分值高的物品,返回物品编号以及预测评分值。
优势在于:用户的评分数据是稀疏矩阵,可以用SVD将数据映射到低维空间,然后计算低维空间中的item之间的相似度,对用户未评分的item进行评分预测,最后将预测评分高的item推荐给用户。

#coding=utf-8
from numpy import *
from numpy import linalg as la
'''加载测试数据集'''
def loadExData():
return mat([[0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 5],
[0, 0, 0, 3, 0, 4, 0, 0, 0, 0, 3],
[0, 0, 0, 0, 4, 0, 0, 1, 0, 4, 0],
[3, 3, 4, 0, 0, 0, 0, 2, 2, 0, 0],
[5, 4, 5, 0, 0, 0, 0, 5, 5, 0, 0],
[0, 0, 0, 0, 5, 0, 1, 0, 0, 5, 0],
[4, 3, 4, 0, 0, 0, 0, 5, 5, 0, 1],
[0, 0, 0, 4, 0, 4, 0, 0, 0, 0, 4],
[0, 0, 0, 2, 0, 2, 5, 0, 0, 1, 2],
[0, 0, 0, 0, 5, 0, 0, 0, 0, 4, 0],
[1, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0]])
'''以下是三种计算相似度的算法,分别是欧式距离、皮尔逊相关系数和余弦相似度,
注意三种计算方式的参数inA和inB都是列向量'''
def ecludSim(inA,inB):
return 1.0/(1.0+la.norm(inA-inB)) #范数的计算方法linalg.norm(),这里的1/(1+距离)表示将相似度的范围放在0与1之间
def pearsSim(inA,inB):
if len(inA)<3: return 1.0
return 0.5+0.5*corrcoef(inA,inB,rowvar=0)[0][1] #皮尔逊相关系数的计算方法corrcoef(),参数rowvar=0表示对列求相似度,这里的0.5+0.5*corrcoef()是为了将范围归一化放到0和1之间
def cosSim(inA,inB):
num=float(inA.T*inB)
denom=la.norm(inA)*la.norm(inB)
return 0.5+0.5*(num/denom) #将相似度归一到0与1之间
'''按照前k个奇异值的平方和占总奇异值的平方和的百分比percentage来确定k的值,
后续计算SVD时需要将原始矩阵转换到k维空间'''
def sigmaPct(sigma,percentage):
sigma2=sigma**2 #对sigma求平方
sumsgm2=sum(sigma2) #求所有奇异值sigma的平方和
sumsgm3=0 #sumsgm3是前k个奇异值的平方和
k=0
for i in sigma:
sumsgm3+=i**2
k+=1
if sumsgm3>=sumsgm2*percentage:
return k
'''函数svdEst()的参数包含:数据矩阵、用户编号、物品编号和奇异值占比的阈值,
数据矩阵的行对应用户,列对应物品,函数的作用是基于item的相似性对用户未评过分的物品进行预测评分'''
def svdEst(dataMat,user,simMeas,item,percentage):
n=shape(dataMat)[1]
simTotal=0.0;ratSimTotal=0.0
u,sigma,vt=la.svd(dataMat)
k=sigmaPct(sigma,percentage) #确定了k的值
sigmaK=mat(eye(k)*sigma[:k]) #构建对角矩阵
xformedItems=dataMat.T*u[:,:k]*sigmaK.I #根据k的值将原始数据转换到k维空间(低维),xformedItems表示物品(item)在k维空间转换后的值
for j in range(n):
userRating=dataMat[user,j]
if userRating==0 or j==item:continue
similarity=simMeas(xformedItems[item,:].T,xformedItems[j,:].T) #计算物品item与物品j之间的相似度
simTotal+=similarity #对所有相似度求和
ratSimTotal+=similarity*userRating #用"物品item和物品j的相似度"乘以"用户对物品j的评分",并求和
if simTotal==0:return 0
else:return ratSimTotal/simTotal #得到对物品item的预测评分
'''函数recommend()产生预测评分最高的N个推荐结果,默认返回5个;
参数包括:数据矩阵、用户编号、相似度衡量的方法、预测评分的方法、以及奇异值占比的阈值;
数据矩阵的行对应用户,列对应物品,函数的作用是基于item的相似性对用户未评过分的物品进行预测评分;
相似度衡量的方法默认用余弦相似度'''
def recommend(dataMat,user,N=5,simMeas=cosSim,estMethod=svdEst,percentage=0.9):
unratedItems=nonzero(dataMat[user,:].A==0)[1] #建立一个用户未评分item的列表
if len(unratedItems)==0:return 'you rated everything' #如果都已经评过分,则退出
itemScores=[]
for item in unratedItems: #对于每个未评分的item,都计算其预测评分
estimatedScore=estMethod(dataMat,user,simMeas,item,percentage)
itemScores.append((item,estimatedScore))
itemScores=sorted(itemScores,key=lambda x:x[1],reverse=True)#按照item的得分进行从大到小排序
return itemScores[:N] #返回前N大评分值的item名,及其预测评分值将文件命名为svd2.py,在python提示符下输入:>>>import svd2
>>>testdata=svd2.loadExData()
>>>svd2.recommend(testdata,1,N=3,percentage=0.8)#对编号为1的用户推荐评分较高的3件商品Reference:
1.Peter Harrington,《机器学习实战》,人民邮电出版社,2013
2.http://www.ams.org/samplings/feature-column/fcarc-svd (讲解SVD非常好的一篇文章,对于理解SVD非常有帮助,本文中SVD的几何意义就是参考这篇)
3. http://blog.csdn.net/xiahouzuoxin/article/details/41118351 (讲解SVD与特征值分解区别的一篇文章)
一、奇异值与特征值基础知识:
特征值分解和奇异值分解在机器学习领域都是属于满地可见的方法。两者有着很紧密的关系,我在接下来会谈到,特征值分解和奇异值分解的目的都是一样,就是提取出一个矩阵最重要的特征。先谈谈特征值分解吧:
1)特征值:
如果说一个向量v是方阵A的特征向量,将一定可以表示成下面的形式:

这时候λ就被称为特征向量v对应的特征值,一个矩阵的一组特征向量是一组正交向量。特征值分解是将一个矩阵分解成下面的形式:

其中Q是这个矩阵A的特征向量组成的矩阵,Σ是一个对角阵,每一个对角线上的元素就是一个特征值。我这里引用了一些参考文献中的内容来说明一下。首先,要明确的是,一个矩阵其实就是一个线性变换,因为一个矩阵乘以一个向量后得到的向量,其实就相当于将这个向量进行了线性变换。比如说下面的一个矩阵:

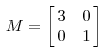

 转存失败重新上传取消
转存失败重新上传取消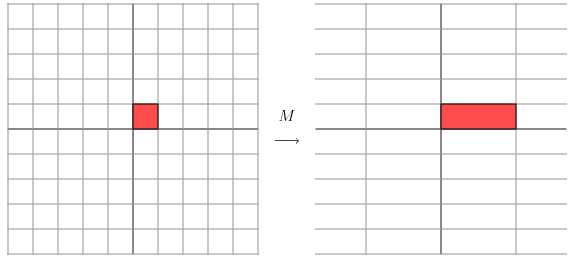 因为这个矩阵M乘以一个向量(x,y)的结果是:
因为这个矩阵M乘以一个向量(x,y)的结果是:
 转存失败重新上传取消
转存失败重新上传取消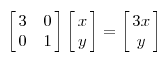 上面的矩阵是对称的,所以这个变换是一个对x,y轴的方向一个拉伸变换(每一个对角线上的元素将会对一个维度进行拉伸变换,当值>1时,是拉长,当值<1时时缩短),当矩阵不是对称的时候,假如说矩阵是下面的样子:
上面的矩阵是对称的,所以这个变换是一个对x,y轴的方向一个拉伸变换(每一个对角线上的元素将会对一个维度进行拉伸变换,当值>1时,是拉长,当值<1时时缩短),当矩阵不是对称的时候,假如说矩阵是下面的样子:


它所描述的变换是下面的样子:


这其实是在平面上对一个轴进行的拉伸变换(如蓝色的箭头所示),在图中,蓝色的箭头是一个最主要的变化方向(变化方向可能有不止一个),如果我们想要描述好一个变换,那我们就描述好这个变换主要的变化方向就好了。反过头来看看之前特征值分解的式子,分解得到的Σ矩阵是一个对角阵,里面的特征值是由大到小排列的,这些特征值所对应的特征向量就是描述这个矩阵变化方向(从主要的变化到次要的变化排列)
当矩阵是高维的情况下,那么这个矩阵就是高维空间下的一个线性变换,这个线性变化可能没法通过图片来表示,但是可以想象,这个变换也同样有很多的变换方向,我们通过特征值分解得到的前N个特征向量,那么就对应了这个矩阵最主要的N个变化方向。我们利用这前N个变化方向,就可以近似这个矩阵(变换)。也就是之前说的:提取这个矩阵最重要的特征。总结一下,特征值分解可以得到特征值与特征向量,特征值表示的是这个特征到底有多重要,而特征向量表示这个特征是什么,可以将每一个特征向量理解为一个线性的子空间,我们可以利用这些线性的子空间干很多的事情。不过,特征值分解也有很多的局限,比如说变换的矩阵必须是方阵。
(说了这么多特征值变换,不知道有没有说清楚,请各位多提提意见。)
2)奇异值:
下面谈谈奇异值分解。特征值分解是一个提取矩阵特征很不错的方法,但是它只是对方阵而言的,在现实的世界中,我们看到的大部分矩阵都不是方阵,比如说有N个学生,每个学生有M科成绩,这样形成的一个N * M的矩阵就不可能是方阵,我们怎样才能描述这样普通的矩阵呢的重要特征呢?奇异值分解可以用来干这个事情,奇异值分解是一个能适用于任意的矩阵的一种分解的方法:
 转存失败重新上传取消
转存失败重新上传取消![]() 假设A是一个N * M的矩阵,那么得到的U是一个N * N的方阵(里面的向量是正交的,U里面的向量称为左奇异向量),Σ是一个N * M的矩阵(除了对角线的元素都是0,对角线上的元素称为奇异值),V’(V的转置)是一个N * N的矩阵,里面的向量也是正交的,V里面的向量称为右奇异向量),从图片来反映几个相乘的矩阵的大小可得下面的图片
假设A是一个N * M的矩阵,那么得到的U是一个N * N的方阵(里面的向量是正交的,U里面的向量称为左奇异向量),Σ是一个N * M的矩阵(除了对角线的元素都是0,对角线上的元素称为奇异值),V’(V的转置)是一个N * N的矩阵,里面的向量也是正交的,V里面的向量称为右奇异向量),从图片来反映几个相乘的矩阵的大小可得下面的图片


那么奇异值和特征值是怎么对应起来的呢?首先,我们将一个矩阵A的转置 * A,将会得到一个方阵,我们用这个方阵求特征值可以得到: 转存失败重新上传取消
转存失败重新上传取消![]() 这里得到的v,就是我们上面的右奇异向量。此外我们还可以得到:
这里得到的v,就是我们上面的右奇异向量。此外我们还可以得到:
 转存失败重新上传取消
转存失败重新上传取消 这里的σ就是上面说的奇异值,u就是上面说的左奇异向量。奇异值σ跟特征值类似,在矩阵Σ中也是从大到小排列,而且σ的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了。也就是说,我们也可以用前r大的奇异值来近似描述矩阵,这里定义一下部分奇异值分解:
这里的σ就是上面说的奇异值,u就是上面说的左奇异向量。奇异值σ跟特征值类似,在矩阵Σ中也是从大到小排列,而且σ的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了。也就是说,我们也可以用前r大的奇异值来近似描述矩阵,这里定义一下部分奇异值分解:

r是一个远小于m、n的数,这样矩阵的乘法看起来像是下面的样子:

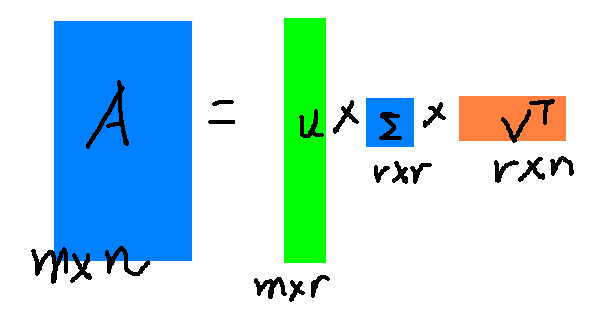
右边的三个矩阵相乘的结果将会是一个接近于A的矩阵,在这儿,r越接近于n,则相乘的结果越接近于A。而这三个矩阵的面积之和(在存储观点来说,矩阵面积越小,存储量就越小)要远远小于原始的矩阵A,我们如果想要压缩空间来表示原矩阵A,我们存下这里的三个矩阵:U、Σ、V就好了。
二、奇异值的计算:
奇异值的计算是一个难题,是一个O(N^3)的算法。在单机的情况下当然是没问题的,matlab在一秒钟内就可以算出1000 * 1000的矩阵的所有奇异值,但是当矩阵的规模增长的时候,计算的复杂度呈3次方增长,就需要并行计算参与了。Google的吴军老师在数学之美系列谈到SVD的时候,说起Google实现了SVD的并行化算法,说这是对人类的一个贡献,但是也没有给出具体的计算规模,也没有给出太多有价值的信息。
其实SVD还是可以用并行的方式去实现的,在解大规模的矩阵的时候,一般使用迭代的方法,当矩阵的规模很大(比如说上亿)的时候,迭代的次数也可能会上亿次,如果使用Map-Reduce框架去解,则每次Map-Reduce完成的时候,都会涉及到写文件、读文件的操作。个人猜测Google云计算体系中除了Map-Reduce以外应该还有类似于MPI的计算模型,也就是节点之间是保持通信,数据是常驻在内存中的,这种计算模型比Map-Reduce在解决迭代次数非常多的时候,要快了很多倍。
Lanczos迭代就是一种解对称方阵部分特征值的方法(之前谈到了,解A’* A得到的对称方阵的特征值就是解A的右奇异向量),是将一个对称的方程化为一个三对角矩阵再进行求解。按网上的一些文献来看,Google应该是用这种方法去做的奇异值分解的。请见Wikipedia上面的一些引用的论文,如果理解了那些论文,也“几乎”可以做出一个SVD了。
由于奇异值的计算是一个很枯燥,纯数学的过程,而且前人的研究成果(论文中)几乎已经把整个程序的流程图给出来了。更多的关于奇异值计算的部分,将在后面的参考文献中给出,这里不再深入,我还是focus在奇异值的应用中去。
三、奇异值与主成分分析(PCA):
主成分分析在上一节里面也讲了一些,这里主要谈谈如何用SVD去解PCA的问题。PCA的问题其实是一个基的变换,使得变换后的数据有着最大的方差。方差的大小描述的是一个变量的信息量,我们在讲一个东西的稳定性的时候,往往说要减小方差,如果一个模型的方差很大,那就说明模型不稳定了。但是对于我们用于机器学习的数据(主要是训练数据),方差大才有意义,不然输入的数据都是同一个点,那方差就为0了,这样输入的多个数据就等同于一个数据了。以下面这张图为例子:
 转存失败重新上传取消
转存失败重新上传取消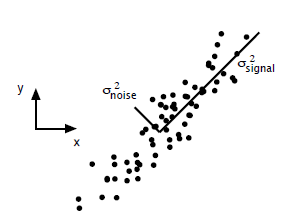 这个假设是一个摄像机采集一个物体运动得到的图片,上面的点表示物体运动的位置,假如我们想要用一条直线去拟合这些点,那我们会选择什么方向的线呢?当然是图上标有signal的那条线。如果我们把这些点单纯的投影到x轴或者y轴上,最后在x轴与y轴上得到的方差是相似的(因为这些点的趋势是在45度左右的方向,所以投影到x轴或者y轴上都是类似的),如果我们使用原来的xy坐标系去看这些点,容易看不出来这些点真正的方向是什么。但是如果我们进行坐标系的变化,横轴变成了signal的方向,纵轴变成了noise的方向,则就很容易发现什么方向的方差大,什么方向的方差小了。
这个假设是一个摄像机采集一个物体运动得到的图片,上面的点表示物体运动的位置,假如我们想要用一条直线去拟合这些点,那我们会选择什么方向的线呢?当然是图上标有signal的那条线。如果我们把这些点单纯的投影到x轴或者y轴上,最后在x轴与y轴上得到的方差是相似的(因为这些点的趋势是在45度左右的方向,所以投影到x轴或者y轴上都是类似的),如果我们使用原来的xy坐标系去看这些点,容易看不出来这些点真正的方向是什么。但是如果我们进行坐标系的变化,横轴变成了signal的方向,纵轴变成了noise的方向,则就很容易发现什么方向的方差大,什么方向的方差小了。
一般来说,方差大的方向是信号的方向,方差小的方向是噪声的方向,我们在数据挖掘中或者数字信号处理中,往往要提高信号与噪声的比例,也就是信噪比。对上图来说,如果我们只保留signal方向的数据,也可以对原数据进行不错的近似了。
PCA的全部工作简单点说,就是对原始的空间中顺序地找一组相互正交的坐标轴,第一个轴是使得方差最大的,第二个轴是在与第一个轴正交的平面中使得方差最大的,第三个轴是在与第1、2个轴正交的平面中方差最大的,这样假设在N维空间中,我们可以找到N个这样的坐标轴,我们取前r个去近似这个空间,这样就从一个N维的空间压缩到r维的空间了,但是我们选择的r个坐标轴能够使得空间的压缩使得数据的损失最小。
还是假设我们矩阵每一行表示一个样本,每一列表示一个feature,用矩阵的语言来表示,将一个m * n的矩阵A的进行坐标轴的变化,P就是一个变换的矩阵从一个N维的空间变换到另一个N维的空间,在空间中就会进行一些类似于旋转、拉伸的变化。

而将一个m * n的矩阵A变换成一个m * r的矩阵,这样就会使得本来有n个feature的,变成了有r个feature了(r < n),这r个其实就是对n个feature的一种提炼,我们就把这个称为feature的压缩。用数学语言表示就是:
 转存失败重新上传取消
转存失败重新上传取消![]() 但是这个怎么和SVD扯上关系呢?之前谈到,SVD得出的奇异向量也是从奇异值由大到小排列的,按PCA的观点来看,就是方差最大的坐标轴就是第一个奇异向量,方差次大的坐标轴就是第二个奇异向量…我们回忆一下之前得到的SVD式子:
但是这个怎么和SVD扯上关系呢?之前谈到,SVD得出的奇异向量也是从奇异值由大到小排列的,按PCA的观点来看,就是方差最大的坐标轴就是第一个奇异向量,方差次大的坐标轴就是第二个奇异向量…我们回忆一下之前得到的SVD式子:
 转存失败重新上传取消
转存失败重新上传取消![]() 在矩阵的两边同时乘上一个矩阵V,由于V是一个正交的矩阵,所以V转置乘以V得到单位阵I,所以可以化成后面的式子
在矩阵的两边同时乘上一个矩阵V,由于V是一个正交的矩阵,所以V转置乘以V得到单位阵I,所以可以化成后面的式子
 转存失败重新上传取消
转存失败重新上传取消 将后面的式子与A * P那个m * n的矩阵变换为m * r的矩阵的式子对照看看,在这里,其实V就是P,也就是一个变化的向量。这里是将一个m * n 的矩阵压缩到一个m * r的矩阵,也就是对列进行压缩,如果我们想对行进行压缩(在PCA的观点下,对行进行压缩可以理解为,将一些相似的sample合并在一起,或者将一些没有太大价值的sample去掉)怎么办呢?同样我们写出一个通用的行压缩例子:
将后面的式子与A * P那个m * n的矩阵变换为m * r的矩阵的式子对照看看,在这里,其实V就是P,也就是一个变化的向量。这里是将一个m * n 的矩阵压缩到一个m * r的矩阵,也就是对列进行压缩,如果我们想对行进行压缩(在PCA的观点下,对行进行压缩可以理解为,将一些相似的sample合并在一起,或者将一些没有太大价值的sample去掉)怎么办呢?同样我们写出一个通用的行压缩例子:
 转存失败重新上传取消
转存失败重新上传取消![]() 这样就从一个m行的矩阵压缩到一个r行的矩阵了,对SVD来说也是一样的,我们对SVD分解的式子两边乘以U的转置U'
这样就从一个m行的矩阵压缩到一个r行的矩阵了,对SVD来说也是一样的,我们对SVD分解的式子两边乘以U的转置U'
 转存失败重新上传取消
转存失败重新上传取消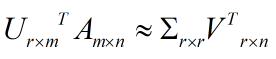 这样我们就得到了对行进行压缩的式子。可以看出,其实PCA几乎可以说是对SVD的一个包装,如果我们实现了SVD,那也就实现了PCA了,而且更好的地方是,有了SVD,我们就可以得到两个方向的PCA,如果我们对A’A进行特征值的分解,只能得到一个方向的PCA。
这样我们就得到了对行进行压缩的式子。可以看出,其实PCA几乎可以说是对SVD的一个包装,如果我们实现了SVD,那也就实现了PCA了,而且更好的地方是,有了SVD,我们就可以得到两个方向的PCA,如果我们对A’A进行特征值的分解,只能得到一个方向的PCA。















 708
708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









