







 该论文提出了一种共同的多尺度卷积架构,用于预测深度、表面法线和语义标签。通过三个阶段的网络,解决了2014年论文中未输出像素级深度预测的问题。Scale 1使用VGG或AlexNet提取特征,Scale 2进行预测,Scale 3提高分辨率,以获得更清晰的输出。深度和法向量的损失函数改进,增加了平滑度,避免了额外的处理步骤。
该论文提出了一种共同的多尺度卷积架构,用于预测深度、表面法线和语义标签。通过三个阶段的网络,解决了2014年论文中未输出像素级深度预测的问题。Scale 1使用VGG或AlexNet提取特征,Scale 2进行预测,Scale 3提高分辨率,以获得更清晰的输出。深度和法向量的损失函数改进,增加了平滑度,避免了额外的处理步骤。
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture
这篇文章是eigen 2015年的新文章,基于同样的模型,同样的初始化和大概相同的参数,可以用来得到深度,表面法向量或语义标签。
1.网络介绍
它的Pipeline如图:
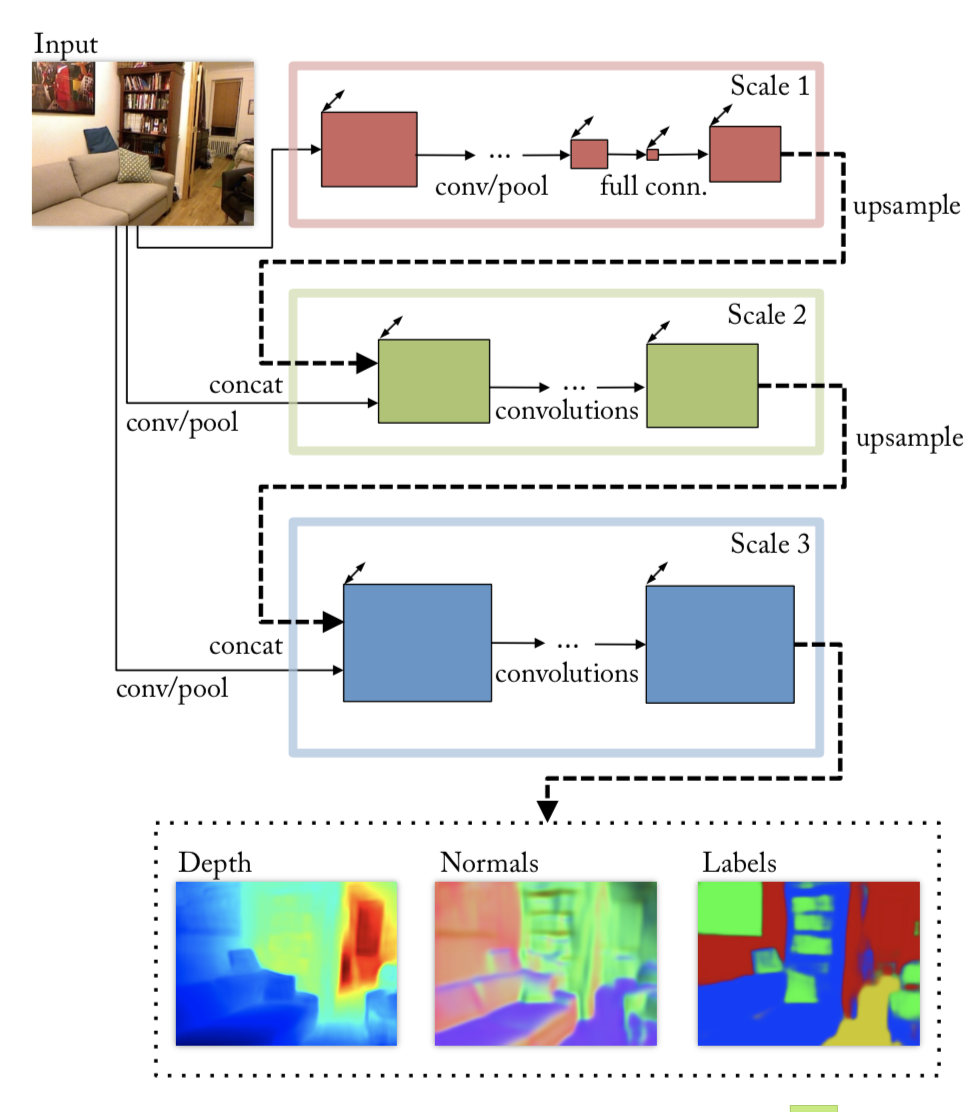
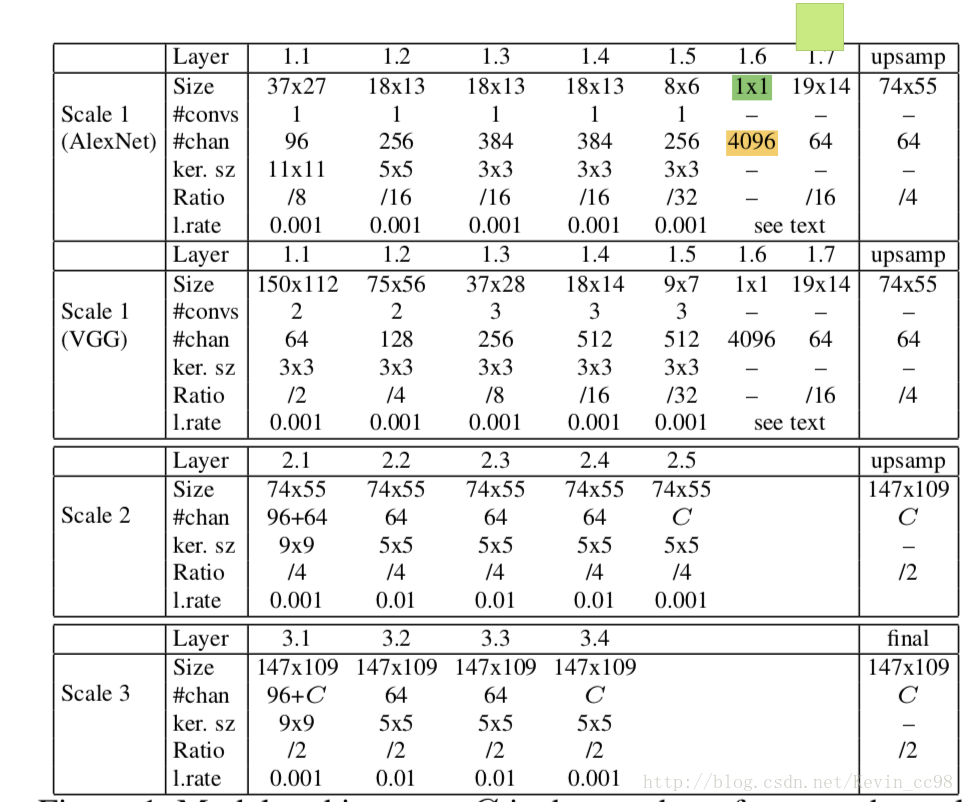
三个stage的网络,scale1的输入与池化后的原图片concatenate,scale2的输入与池化后的原图片进行concatenate。相对于2014年的论文Depth Map Prediction from a Single Image using a Multi-Scale Deep Network中没有输出像素级深度预测的问题,新增了scale3用来unsample。
2.Scale 1-Full-Image:
先对它进行一个VGG或AlexNet的网络来提取feature ma
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1573
1573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









