







predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture
大体思想
这篇论文是上一篇论文的改进。使用单个多尺度卷积网络架构处理三种不同的计算机视觉任务:深度预测、表面法线估计和语义标记。网络结构一共包含三个stage的网络,scale1的输入与池化后的原图片concatenate,scale2的输入与池化后的原图片进行concatenate。相对于2014年的论文Depth Map Prediction from a Single Image using a Multi-Scale Deep Network中没有输出像素级深度预测的问题,新增了scale3用来unsample。


Combining Depth and Normals: We combine both depths and normals networks together to share computation, creating a network using a single scale 1 stack, but separate scale 2 and 3 stacks. Thus we predict both depth and normals at the same time, given an RGB image.
1.scale解释
①Scale1-Full-Image:
scale1输出的是整个图像区域的粗特征预测,得到feature map。(它总共有两种,一种AlexNet,一种是VGG)到layer1.6为止。然后用1x1的卷积核来降维,减少计算数量。
②Scale2-Predication:
得到预测图。语义系统的输入是ground truth的depth和normal vector,作者曾尝试使用预测得到depth和normal,但联合训练scale1和scale2得到结果几乎无提升,但depth等用来单独训练语义scale2则有效。作者认为这是因为基于语义的系统也能学习到depth和normal vector的相关性。
③Scale3-Higher Resolution
使得预测图片的分辨率变高同时将结果进一步的精细化,得到更高清的输出。相当于up-sample过程
2.loss function
①Depth loss:
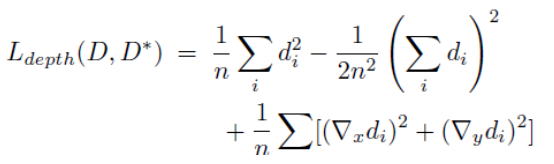
D是预测,D是ground-truth。d=D-D
可见相比eigen2014年的文章,损失函数增加了一个水平和竖直方向上梯度的抑制。这样使得得到的结果更加平滑,因此本文的深度估计,语义分割,都不必对结果进行超像素处理或平滑处理。
②Surface Normals loss:
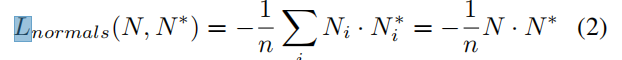
N:the predicted vector maps
N*:ground truth normal vector mapsthe sums again run over valid pixels
判断法向的预测值和真实值的差别,使用的是法向量内积:
③Semantic Labels loss:
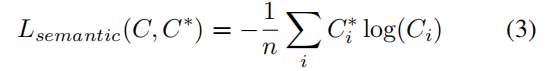
where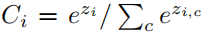 is the class prediction at pixel i given the output z of the final convolutional linear layer
is the class prediction at pixel i given the output z of the final convolutional linear layer















 357
357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









