







论文链接
Cooperative Perception for 3D Object Detection in Driving Scenarios using Infrastructure Sensors
0. 摘要
各种 3D 对象检测方法依赖于不同传感器模态融合来克服个体传感器的限制。协同感知将分布于不同传感器的信息进行合作来作为一种缓解限制的方法。
本文提出了两种基于单模态传感器的协同三维目标检测方案:
- 早期融合:在检测前结合多个空间不同的感知点的点云
- 后期融合:融合来自多个空间不同传感器的独立检测的边界盒(bounding box)
同时,考虑了两种场景:t 形路口和环形路口
1. Intro
准确表征驾驶环境是自动驾驶感知的核心功能,三维物体检测是感知系统的核心功能。
- 利用相机提供纹理信息,对于对象分类十分重要。LiDAR和深度相机产生深度信息可用于估计姿态。
- 多模态传感器数据融合容易受到主要传感器的影响。主要的限制来源于遮挡,视场受限以及远离区域的低点密度
本文的主要内容:
- 提出了两种新型的协同三维目标检测方案,每种方案都采用一种独特的融合机制,基于定制神经网络的检测方法和定制的训练过程
- 提出一个新的数据集用于协同感知
- 从系统运行所需的检测性能和通信成本两方面对融合方式进行评估
- 分析了传感器和系统配置的影响
2. 相关工作
2.1 三维对象检测模型
模型可以按输入的数据类型分为三类
- 单目相机的彩色图像
- LiDAR/深度相机的点云信息
- 上述两者的结合
利用点云信息的模型通常会将点云信息投射到鸟瞰图(BEV)或柱坐标中得到结构化且固定大小的表示,该表示可用于卷积网络的目标检测。对于两种投影技术而言,都可能因为空间量化和表示方式的选择而导致信息丢失。
本文重点关注协作对象检测。由于其泛化能力和检测性能,我们特别使用 Voxelnet 对象检测模型。由于该模型专门在点云上运行,因此它使我们能够减少从传感器节点到融合系统的数据传输所需的带宽,并避免彩色图像出现的潜在隐私问题。
2.2 协同三维对象检测方法
本文工作的不同之处
- 提出了融合来自多种传感器数据的中央系统,允许共享资源来分摊传感器和处理成本
- 选择遮挡情况最严重的 T 型路口和环形路口场景
- 解决传感器配置的实际评估。如其数量,姿态,视场重叠等
2.3 数据融合方案
数据融合的方式分为三大类:数据关联,状态估计,决策函数。
早期融合和后期融合可以互补。传感器独占视场时视为冗余,传感器重叠视场也视为冗余。
点云融合也可以分为三种类型:点云级别,体素级别,特征级别
本文工作采用的早期融合方式属于点云级别融合,但后期融合不属于任何类别融合,因为在本文的工作中融合的是检测到的边界盒。
3. 系统模型和融合方法
3.1 系统模型
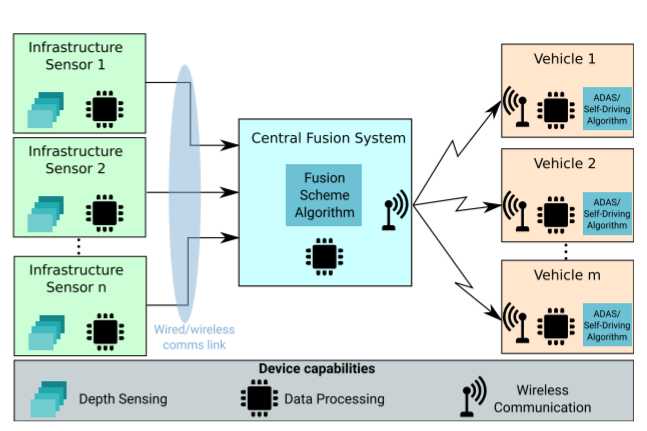
- 多个路边设施将传感器感知信息传输到中央融合系统
- 中央融合系统将多个路边设施感知的信息进行融合,并产生目标检测结果,然后与附近所有车辆共享
- 每个车辆根据自车传感器信息和由中央融合系统广播的信息来感知交通环境,并做出适当的决策
中央融合系统负责融合各个路边设施传感器的数据和定期向附近的车辆广播协同感知信息,其作用只是协助自动驾驶车辆或司机做出适当的控制决策,以安全驾驶。但本文未考虑网络延迟和通信损耗。
3.2 数据预处理
每个传感器都提供相对于自身坐标的点,在处理需要映射到全局坐标系。
- 每个LiDAR传感器都基于自身的位姿信息通过旋转平移,将点云从自身传感器坐标系映射到全局坐标系中。
- 将在给定的全局检测区域之外的点和高于4米的点删除,因为这些点不携带相关有用的信息
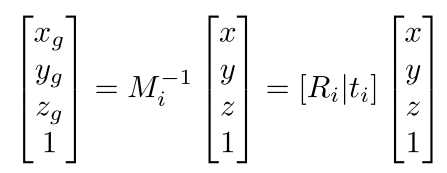
其中 M,R,t 需要不断校准。移动节点会导致融合点云时的对准错误,可能导致假阳性和漏检的问题。故在本文的工作中,将传感器固定于路边。
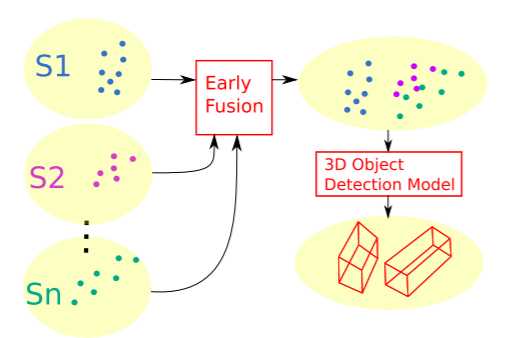
3.3 早期融合方法
允许通过不同观测来聚集来自检测区域中对象的不同互补信息,特别对于被遮挡或能见度低的对象。该方案的处理流程包含在每个传感器上进行的预处理阶段,从而在全局坐标系中产生 n 个点云。每个点云都会传输到中央融合系统,在那里它们被连接成单个点云,然后馈送到 3D 对象检测模型。中央融合系统中的对象检测模型的结果由一系列对象组成,即 3D 边界框,然后将其传播到附近的车辆
3.4 后期融合方法
对每个点云进行预处理,并将其输入到每个传感器上的检测模型中,该模型会生成由 3D 边界框表示的对象列表。然后,从 n 个传感器检测到的物体列表被传输到中央融合系统,在那里它们被融合成一个列表
每个路边设施将自身的目标检测结果传输到中央融合系统进行融合。采用非最大抑制(NMS)算法来消除重叠的边界框,通过交叉联合(IOU)指标来衡量边界框的重叠情况,如果多个边界框之间的重合度超过了指定的阈值,那么就删除置信度低的边界框。
检测结果融合和后处理完成之后,最终的检测结果就会广播给附近的所有车辆,以协助车辆做出更安全的控制决策

3.5 混合融合方法
与后期融合相比,早期融合方案可以增加检测物体的可能性,因为在检测阶段之前聚合了信息,但需要原始传感器数据共享,这增加了通信成本。
混合融合方案使用先前的两种方案来增加检测的可能性,而不会大幅增加通信成本。关键概念是在传感器具有高可见性的情况下共享高级信息(后期融合),在可见性较差的情况下共享低级信息(早期融合)。
- 在每个传感器节点中采用后期融合方案,并将检测到的物体边界框共享给中央融合系统。
- 每个传感器节点选取其点云中附近区域之外的点与中央融合系统共享。
- 中央融合系统对接收到的点云使用早期融合,并将检测到的边界框与来自每个路边设施传感器的后期融合结果融合
3.6 三维对象检测模型
所有的对象检测模型都是基于 VoxelNet,其由三个主要部分组成:
- 特征学习网络
- 多卷积中间层
- 区域建议网络
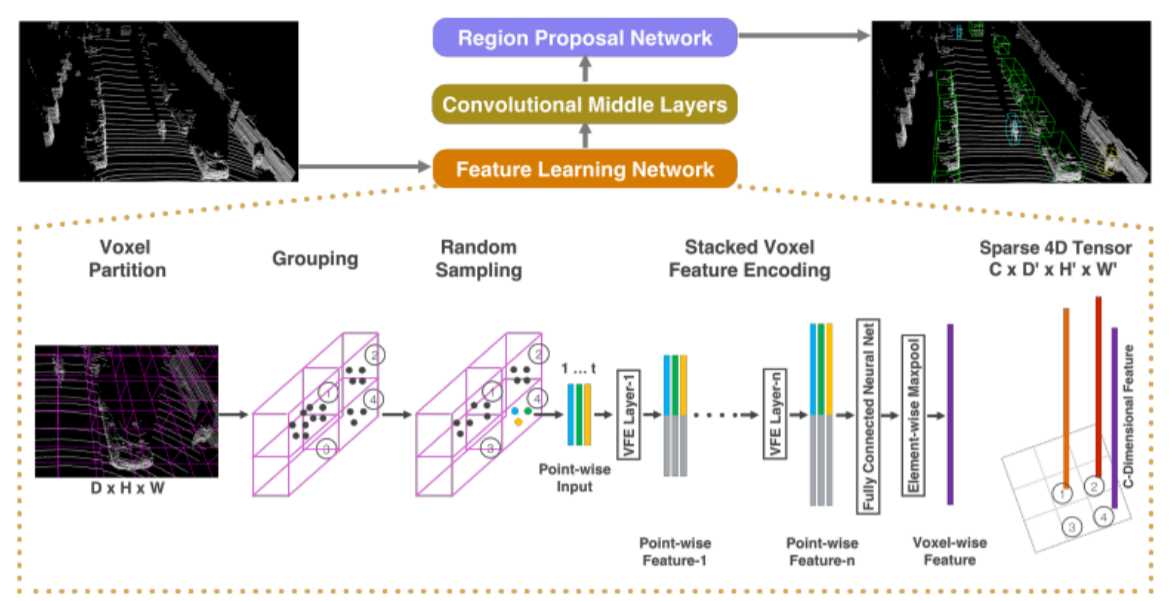
特征学习网络的任务是将点云数据转化为可由卷积层处理的固定尺寸表示;多卷积中间层将三个阶段 3D 卷积应用于 4D 体素张量,结合相邻体素的信息,将空间上下文信息添加到特征图;区域建议网络的利用中间层的输出张量创建特征图,再使用该特征图生成两个输出分支:1)指示对象存在概率的置信度得分,2)指示边界框相对于锚点的相对大小、位置和方向的回归图。
使用锚点是因为与锚点相关的检测盒的回归比没有任何先验信息的回归给出的结果更加准确。
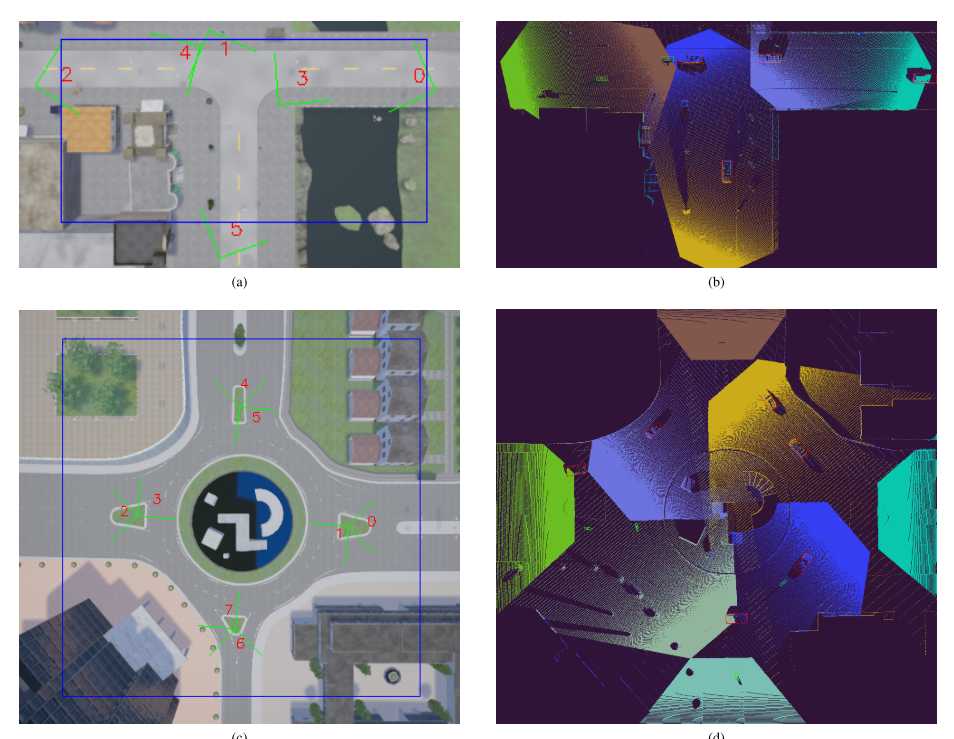
4. 数据集
本文使用多个基础设施传感器为驾驶场景生成一个新颖的协作数据集。本文的数据集是使用 CARLA 模拟工具创建的。
使用固定路边摄像头在丁字路口和环岛场景中生成的,这些摄像头提供分辨率为 400 x 300 像素、水平视野为 90 度的 RGB 和深度图像。
T 字路口场景使用安装在 5.2m 高的柱子上的六个基础设施摄像机。其中三个摄像头指向传入道路,其余三个指向路口的相反方向。
环岛场景使用八个摄像头,安装在交叉口的 8m 安装柱上,其中四个面向环岛迎面而来的车道,另外四个面向环岛外。
四个子数据集:两个用于T型路口,分别包含4000个训练帧和1000个测试帧,两个用于环岛,具有相同数量的训练和测试帧。一个帧被定义为来自所有摄像机的深度和RGB图像的集合,每帧还包含一个检测物体列表,其包含了场景中所有物体的真实位置、方向、大小和类别。检测物体类别包含车辆、骑车人/摩托车人或行人。
在本文的方法中仅使用深度图像,也称为深度图。深度图像中的每个像素指定从相机到表面点的矢量投影(到相机的 Z 轴)的距离。每个深度图像用于重建点云,其中每个像素使用针孔相机模型转换为相机坐标系中的 3D 点,描述如下:
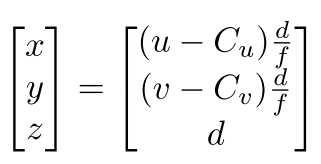
其中(x,y,z)是深度图像中像素坐标(u,v)对应的3D点的坐标, C u , C v C_u,C_v Cu,Cv ,f 是相机焦点中心和长度(由固有相机矩阵给出), d为坐标为(u,v)的像素各自的深度值
5. 训练过程
模型使用随机梯度下降 (SGD) 优化进行 30 个时期的训练,学习率为 1 0 − 3 10^{−3} 10−3 ,动量为 0.9。选择的超参数:尺寸为 (3.9,1.6,1.56)m 的单个锚点,具有两个方向(0 度和 90 度),每个体素的最大点数 T = 35。
T 形路口场景模型沿 X 和 Y 维度的体素大小 ( v x , v y , v z ) (v_x, v_y, v_z) (vx,vy,vz) 和锚定步幅设置为 (0.2, 0.2, 0.4)
在环岛模型中使用这些相同的超参数是不可行的,因为环岛场景的面积大约是 T 形路口场景的三倍,这将导致特征图不适合 GPU 内存。因此,我们通过为环岛模型采用 (0.4, 0.4, 0.4)m 的体素大小和 0.8m 的锚步距,将 X 和 Y 轴的空间分辨率降低一半。
还考虑旋转整个点云,以避免模型过度拟合交汇点周围的建筑物和固定物体,但是此操作并没有带来显着的性能提升。
6. 性能评估
评估标准
利用 IOU,精度,召回率以及平均精度作为评估标准。
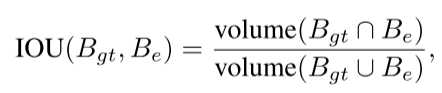
融合方案对比评价
本实验的目的是比较早期、后期和混合融合方案在检测性能、通信成本和计算时间方面的性能。
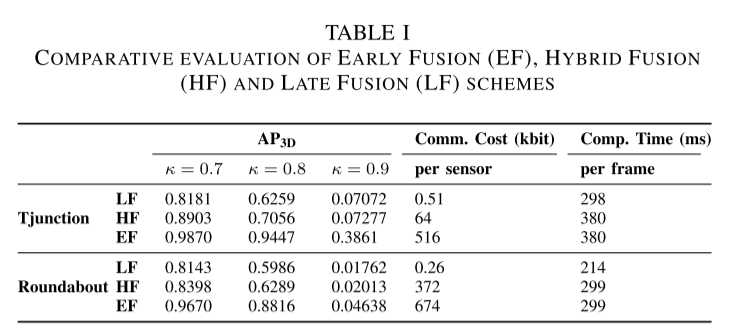
结果表明早期融合方案优于混合融合,而混合融合又优于晚期融合。早期融合方案的检测性能的优越性是以较高的通信成本为代价的。这是因为与后期融合中估计对象从传感器传输到中央系统相比,早期融合中传输原始点云所需的数据量更大。此外,混合融合的性能优于后期融合,其通信成本显着低于早期融合,但由于遗漏点的丢失,其性能低于早期融合。应该注意的是,从传感器节点到中央融合系统的实际所需链路容量将取决于处理帧速率。
同时,网络延迟可能会对于融合系统构成重大问题,因为其会丢失帧而导致检测失败。
传感器的姿态和数量对检测性能的影响
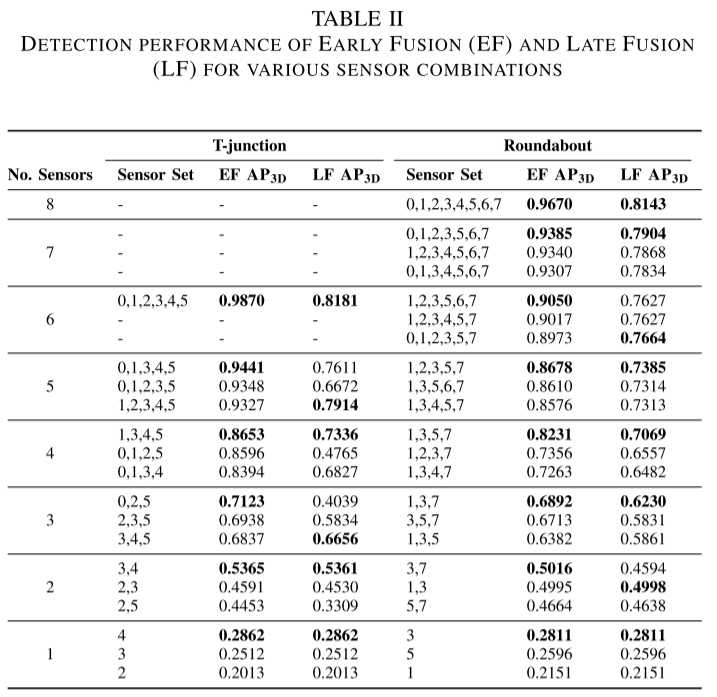
结果表明,检测性能随着参与传感器数量的增加而提高。然而,随着传感器数量的增加,性能增益会饱和。可以看出,随着检测面积的增加,需要更多的传感器来维持检测性能。
此外,早期融合方案在检测性能方面始终优于后期融合。随着传感器数量的增加,它们的差异变得更加显着,因为与后期融合相比,早期融合方案可以在检测时利用更多信息。
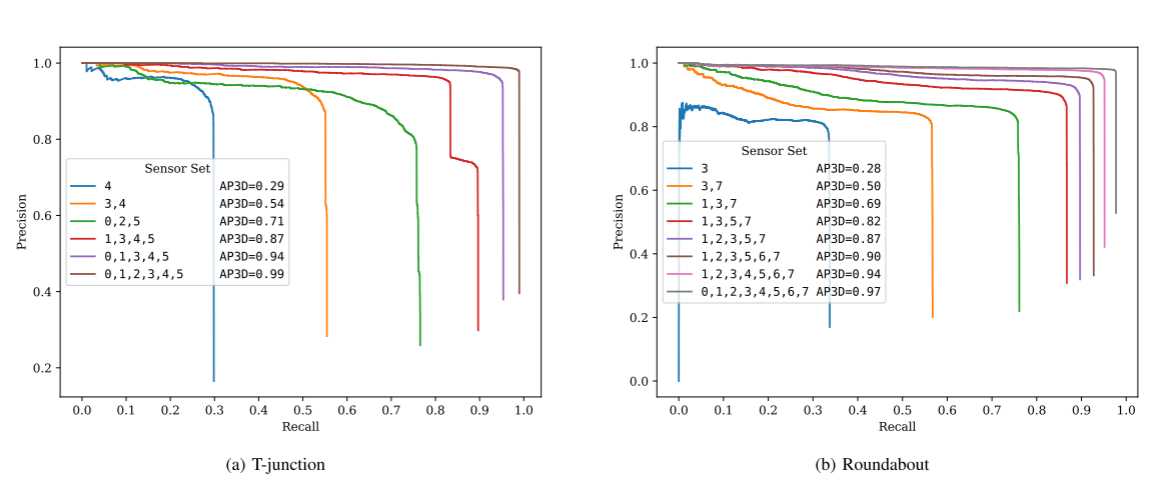
合作感知的空间多样性增益
协作感知检测性能的增强可能与两个因素有关:1)视野增加; 2)空间多样性增益,它体现在被多个传感器覆盖的区域中点密度较高的点云中。
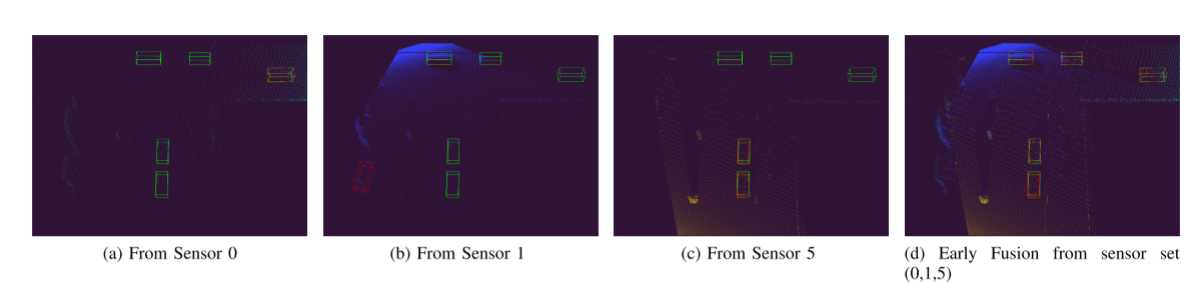
空间多样性对早期融合方案检测性能的影响如图所示。当使用单个传感器时,大多数物体无法检测到或检测精度较差(即不正确的尺寸或偏航角)。然而,通过将多个点云与早期融合相结合来增加点密度,可以减少误报的数量并提高估计边界框的质量。
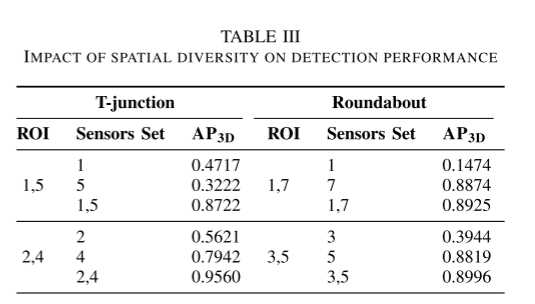
表 III 中总结的该实验结果表明,在 T 形路口场景中,仅使用两个传感器的早期融合方案的性能比最好的单个传感器高 20% 和 85%。然而,在环岛中使用两个传感器时,检测性能的增益是微乎其微的。这是因为在这个特定的环岛场景中,所使用的特定传感器组的视场具有最小的重叠。结果表明,早期融合可以: a) 减少由遮挡和低点密度引起的假阴性数量; b) 当传感器具有显着的重叠覆盖范围时,提高估计框的质量。
点密度对估计边界框精度的影响
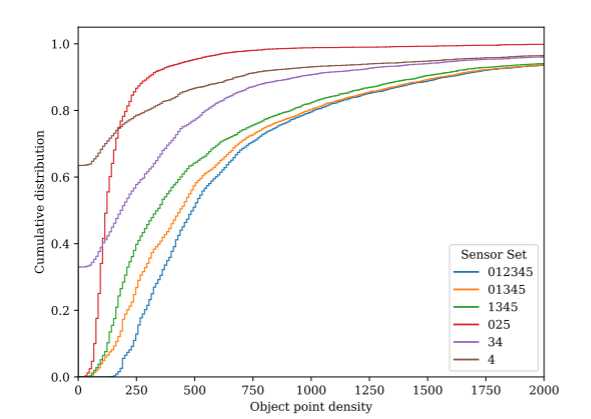
当使用的传感器数量增加时,点密度在 [250, 1000] 点范围内的对象数量显着增加,但点密度高于 1750 点时会饱和。
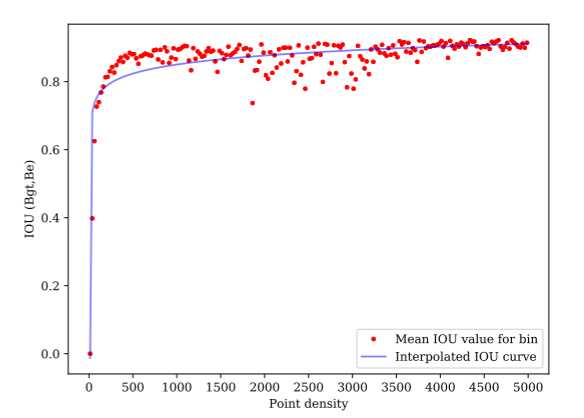
点密度低于70点的物体精度较差,但当点密度超过100点时,精度显着提高。在 [1800, 3400] 范围内观察到的异常值是由靠近传感器的物体引起的,因此大量点集中在一个小表面上,但在其他地方很少有点,导致边界框估计不佳。
总之,对象的点密度可以为估计边界框的准确性提供有用的预测。因此,给定估计边界框的精度要求,可以找到特定场景所需的最小点密度和传感器数量。
与现有基准的比较
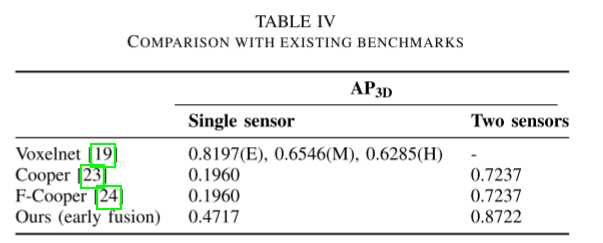
当考虑多个传感器参与时,会显示出客观的性能增益。
7. 总结
- 相比于V2V共享车载信息并在本地融合数据,所提出的协同感知系统采用了一个中央系统,融合来自多个路边设施传感器的感知信息,可以通过共享资源来减少传感器本地处理成本。
- 通过选取远处的点云原始数据(稀疏)进行传输来减少传输数据量从而减少早期融合方式的通信带宽,附近区域采用后期融合方式,这种混合融合方案可以实现感知精度与通信成本之间的平衡。
局限:
- 没有考虑网络延迟和通信损失。
- 融合方案只涉及各个路边设施传感器数据的融合,基于路边设施传感器获得的结果具体是怎么协助车辆,自车传感器信息和由中央融合系统广播的信息是怎么融合的














 3082
3082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









