







关于<Street Scene: A new dataset and evaluation protocol for video anomaly detection>论文学习
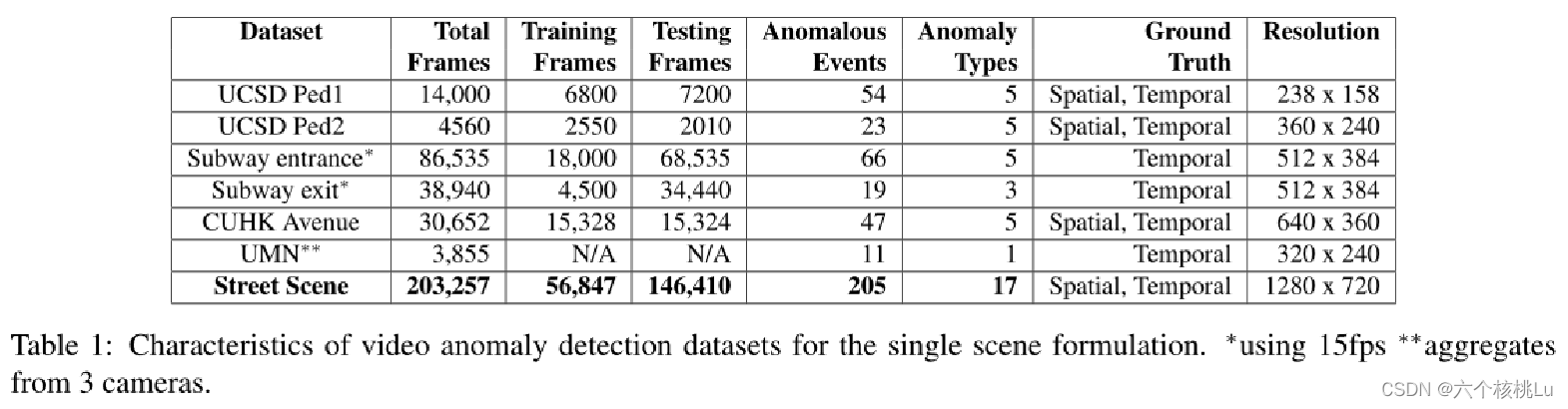
Street Scene数据集
是一个较新的数据集,包含46个训练片段和35个测试片段,分辨率为1280×720,是采集自包含自行车道和人行道的双行道场景.
数据集很有挑战性,因为发生了各种各样的活动,例如汽车驾驶、转弯、停车、步行、慢跑和推婴儿车的行人,还有骑自行车的人.此外,视频还包括变化的阴影、移动的背景,如旗帜和在风中飘扬的树木以及树木和大型车辆造成的遮挡.异常包括横穿马路和非法掉头以及在训练集中不会发生的事情,例如遛宠物和1名交警给1辆汽车开罚单.
下载街景数据集:http://www.merl.com/demos/video-anomaly-detection

现有挑战:数据集小、评估标准有缺陷
作者提出:Street Scence数据集,它大型、多样、高分辨率
一、现有评估标准
①.帧级(frame-level)
检测到的帧指定为得分大于给定异常分数阈值的帧中至少有一个像素的帧.
如果检测到的帧根据 ground truth 判别为异常,则视为真阳性,反之视为假阳性.
阳性和阴性的总数由帧级标注决定,并用于计算真阳性和假阳性率.
帧级标准不能评估是否已经实现了足够的空间定位,只是对某一时段提供了是否有异常.
②.像素级(pixel-level)
仍是计算真和假阳性帧,而不是真和假阳性异常区域。
如果检测到的地面真实异常像素至少占到地面真实异常像素的40%,则视为true postive。
其他被检测到的与地面真实值不重叠的异常像素被忽略。
即使检测到一个像素为异常,任何没有地面真值异常的帧都被视为false postive。
若进行简单的后处理,就可使像素级标准和帧级别标准一样。后处理为:对于检测到至少一个异常像素的任意帧,将该帧中的每个像素标记为异常像素。
二、新的评估标准
作者提出了2个新的标准,基于区域的和基于轨迹的,以取代以前的标准.新的标准为算法在实践中的表现提供了更为现实的情形.他们提出观点,评估方案应该设计成这样一种方式,以考虑到任何异常检测数据集中可能出现的歧义、偏差和不一致.为了修复旧标准的问题,他们基本上采取了2个步骤.
1)通过提出一种松散目标检测风格的IOU 标准来判断空间定位,解释了异常事件标注和检测中固有的模糊性.另外,基于轨迹的准则只要求在异常轨迹中检测到固定百分比帧的异常.
2)把原子检测的真阳性和假阳性计算在内,而不是按照原子来计算帧.这意味着在他们的标准下,一帧可以有不止一个真阳性或假阳性结果,这符合基本直觉.
2.1 Track-Based 检测标准(基于轨迹)
基于轨迹的检测准则衡量:
基于轨迹的检测率(TBDR,成功检测到标注的异常轨迹的比例)与每帧假阳性区域的数量。如果轨道中至少有一部分α的地面实况区域被检测到,则认为该轨道被检测到。
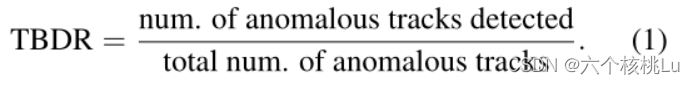
如果ground truth区域和被检测区域的union的IOU大于或等于β,就认为在一个帧中检测到一个ground truth区域。
如果一帧中的一个检测区域与该帧中每个ground truth区域之间的IOU小于β,就认为它是false positive。

式中,FPR为每帧的假阳性率(false positive)
单个检测区域可以覆盖两个或多个不同的ground truth区域,以便检测每个ground truth区域(尽管这种情况很少见)。
实验中,作者使用的是 α = 0.1和 β = 0.1。
2.2 Region-Based 检测标准(基于区域)
基于区域的检测准则衡量:
测试集中所有帧的基于区域的检测率(RBDR)与每帧假阳性区域的数量。与基于轨迹的检测准则一样,如果一帧中的真实区域与被检测区域之间的IOU (ground truth region)的交点大于或等于β,则认为检测到了该区域。

每一帧的假阳性数的计算方法与基于轨迹的检测标准相同。与任何检测标准一样,检测率(真阳性率)和假阳性率之间存在权衡,可以通过改变异常得分的阈值来计算ROC曲线,确定哪些区域被检测为异常。当需要一个单一的数字时,作者建议用0~1的假阳性率的平均检测率来总结性能,即假阳性率小于或等于1的ROC曲线下的面积。
三、Baseline Algorithms
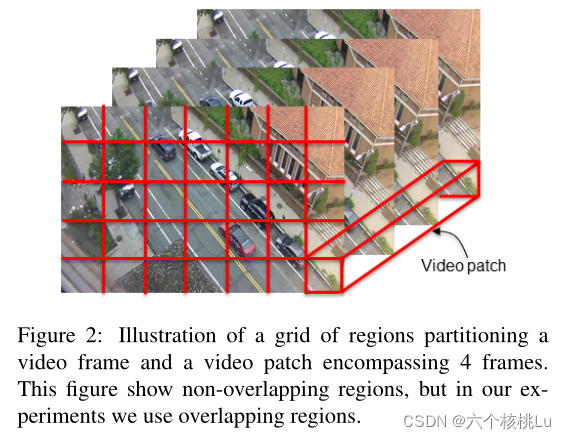
新算法把视频分割为时空区域(称为video patches),存储一组样本来表示发生在每个区域中的各种video patches,然后将测试video patches到最近邻居样本的距离用作异常评分。
首先,将每个视频分割为空间步长s、时间步长1帧、大小为H * W * T像素的时空区域网格。在实验中,作者选择H=40像素,W=40像素,T=4或7帧,s = 20像素。如图2所示。
基线算法分为两个阶段:
1.训练或模型构建阶段
2.测试或异常检测阶段
在模型构建阶段,用训练(正常)视频来为每个空间区域找到一组video patches(由后面描述的特征向量表示),这些video patches代表该空间区域的各种活动变化。把这些代表性video patches称为exemplars。
在异常检测阶段,将测试视频分割成与训练相同的区域,对于每个测试视频patch,从其空间区域中找到最接近的样本。到最近范例的距离就是异常分数。
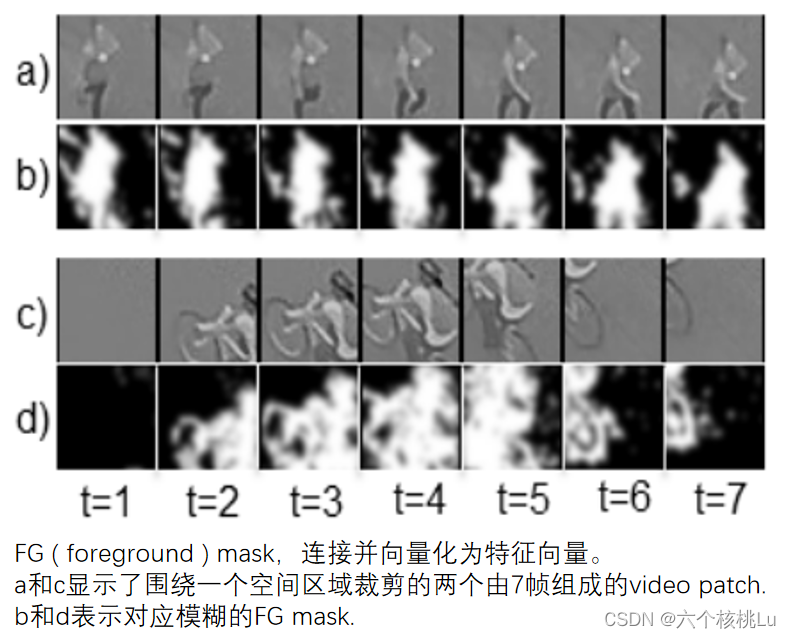
在video patch中的每一帧,前景(foreground,FG)mask变化使用模糊的FG masks。FG masks使用背景(background,BG)模型计算,该模型在视频处理时更新。实验中使用的BG模型是一个非常简单的每个像素的平均颜色值,尽管可以很容易地用一个更复杂的模型来替代。
然后使用高斯核模糊 FG mask,使 FG mask 之间的L2距离更稳健。将video patch中所有帧的模糊FG mask拼接起来,然后进行矢量化,形成FG mask特征向量(见下图)。
基于flow-based variation使用连续帧之间计算的光流场来代替FG masks。每个视频补丁帧区域内的流场被连接起来,然后被矢量化,产生一个特征向量,其长度是FG masks基线特征向量的两倍(由于流场的dx和dy成分)。
在作者的实验中,他们使用Kroeger等人[17]的光流算法来计算流场。
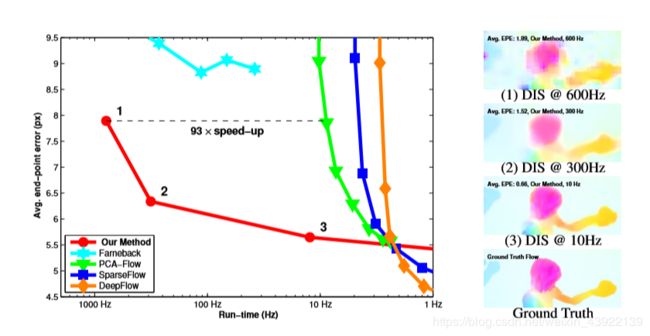
DIS 光流算法是Dense Inverse Search-basedmethod的简称,于2016年由Till Kroeger等人提出的一种在光流质量和计算时间中取得平衡的算法。
主要包含3个方面:
(1)基于块对应关系的逆搜索
(2)沿着多尺度做图像块的聚合从而获得稠密的光流场
(3)精细化搜索。精细化搜索。DIS算法最大的优点在于运算速度的提升,在单核cpu上,1024*436分辨率可以达到300Hz-600Hz运行速率;包含图像预处理,例如平滑,缩放,梯度计算等运行速度能达到42/46 Hz,完全满足实时的需求。
运行时间及效果对比图如下:
具体详细信息,请查看《Fast Optical Flow Using Dense Inverse Search》原论文。
在模型建立阶段,他们选择了一组不同的 exemplars 来代表每个空间区域的正常活动。他们的 exemplar 选择方法是直接的。对于一个特定的空间区域,exemplars 被初始化为空集。他们沿着每个训练视频的时间维度滑动一个空间-时间窗口(步长等于一帧),得到一系列的video patches,我们用基于 FG masks 的特征向量或基于流量的特征向量来表示,这取决于上述算法的变化。对于每个video patch,他们将其与当前的exemplars进行比较。如果与最近的exemplar的距离小于阈值,那么就丢弃该video patch。否则,将其添加到exemplars中。
用特征向量来比较两个样本的距离; 对于模糊的 FG masks 特征向量,使用L2距离; 对于流场特征向量,使用归一化L1距离:
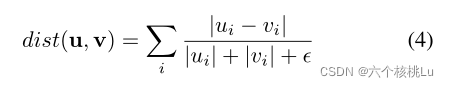
其中u和v是两个基于 flow-based 的特征向量,是一个小的正常数,用于避免被零除。
曼哈顿距离(L1距离):我们可以定义曼哈顿距离的正式意义为L1距离或城市区块距离,也就是在欧几里得空间的固定直角坐标系上两点所形成的线段对轴产生的投射的距离总和。
通俗来讲,想想你在曼哈顿要从一个十字路口开车到另一个十字路口,驾驶距离是两点间的直线距离吗?显然不不是,除非你能穿越大楼。而实际驾驶距离就是这个“曼哈顿距离”,此即曼哈顿距离名称的来源,同时,曼哈顿距离也称为城市街区距离。
欧氏距离(L2距离):最常见的两点之间或多点之间的距离表示法,又称之为欧几里得度量,它定义于欧几里得空间中:



给定一个由不同的视频空间区域样本组成的普通视频模型,异常检测只是一系列最近邻查找。对于测试视频的T帧序列中的每个空间区域,计算表示视频patch的特征向量,然后在该区域的范例集中找到最近的邻居。距离最近的样本的距离是视频补丁的异常分数。
这将产生一个异常分数每个重叠的视频补丁。这些用于为每一帧创建逐像素异常分数矩阵。视频补丁的异常分数存储在该T帧集的中间帧中。测试视频的前T /2−1帧和后T /2 + 1帧不分配任何视频补丁的异常分数,因此都是0。被两个或多个视频补丁覆盖的像素将从包含该像素的所有视频补丁中获得平均分数。
不论是根据 基于轨迹 还是 基于区域 的标准计算ROC曲线时,对于给定的阈值,所有异常分数高于阈值的像素都被标记为异常。然后通过计算异常像素的连通分量,找到异常区域。
根据上述标准之一,将这些异常区域与地面真实区域进行比较。
四、实验
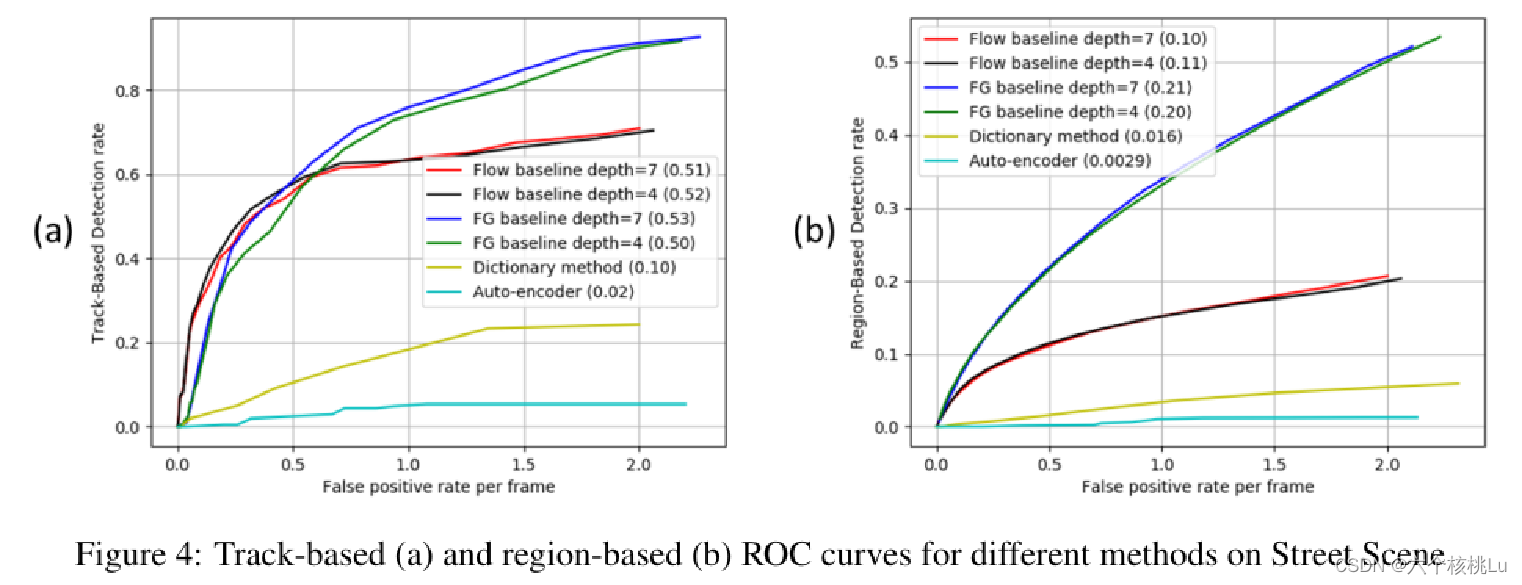 图4(a)和(b)显示了作者的基线方法以及字典和自动编码器方法在使用新提出的基于轨道和的标准在Street Scene数据集中的ROC曲线。图例中括号内的数字是假阳性率为0到1的曲线下的面积。很明显,字典和自动编码器方法在街道场景中的表现很差。作者的基线方法要好得多,尽管仍有很大的改进余地。
图4(a)和(b)显示了作者的基线方法以及字典和自动编码器方法在使用新提出的基于轨道和的标准在Street Scene数据集中的ROC曲线。图例中括号内的数字是假阳性率为0到1的曲线下的面积。很明显,字典和自动编码器方法在街道场景中的表现很差。作者的基线方法要好得多,尽管仍有很大的改进余地。
虽然字典方法在其他较小的数据集上工作得很好,但稀疏字典模型似乎不足以表达在更大、更多样化的街景上重建许多正常测试视频补丁。
自动编码器的方法试图一次建立整个帧的模型,而不是为不同的空间区域创建更小的模型。虽然这似乎可以在以前的数据集上运行,但它似乎无法处理街景中呈现的大量正常变化。
作者的基线算法在街景中表现得相当不错。在有很多活动的区域(如街道、人行道和自行车道区域)存储大量的范例(通常在1000到3000个范例之间)。在其他区域,如建筑墙壁或屋顶,只存储一个单一的范例。对于使用基于轨迹的标准的两个基线变化,基于流的方法对低假阳性率(可以说是ROC曲线中最重要的部分)做得最好。对于大多数异常,流场提供了比FG mask更有用的信息(主要的例外是下面讨论的徘徊异常)。采用基于区域的判据,基于FG的方法取得了较好的效果。视频补丁中使用的帧数(4或7)对这两种变化都没有很大的影响。
基线算法在检测异常行为方面做得最好,比如乱穿马路、违规掉头、自行车手或汽车超出车道,因为这些异常行为与发生区域的典型运动相比有独特的运动。
对于基线方法来说,游荡异常(以及其他大量静态异常,如非法停车)是最困难的,因为它们不包含任何运动,除了在开始时,一个行走的人过渡到闲逛。对于基于流量的方法,游荡异常现象是完全不可见的。对于基于FG的方法,游荡异常的开始是可见的,因为BG模型需要几帧来吸收没有运动的人。这是基于流量的方法比基于FG的方法检测率更差的主要原因。基于FG的方法可以检测到一些闲逛的异常情况,而基于流量的方法则不能。类似的效果解释了基于区域的结果,其中基于FG的方法比基于流量的方法做得更好。闲逛和其他 "静态 "异常现象在全部异常区域中占了不成比例的部分,因为它们中的许多都发生在许多帧中。基于FG的方法检测到了其中的一些区域,而基于流量的方法基本上错过了所有这些区域。因此,尽管基于流量的方法检测到了所有异常轨道中更大的一部分(在低误报率下),但它检测到了所有异常区域中的一小部分。

flow-based method (使用T=4)的检测结果的一些可视化显示如图6和7所示。在图中,红色的像素是异常检测,蓝色的框显示地面真相标注。图6显示了对行驶在人行道上的摩托车的正确检测。图7显示了一个被检测到的乱穿马路的行人以及一个假阳性区域。
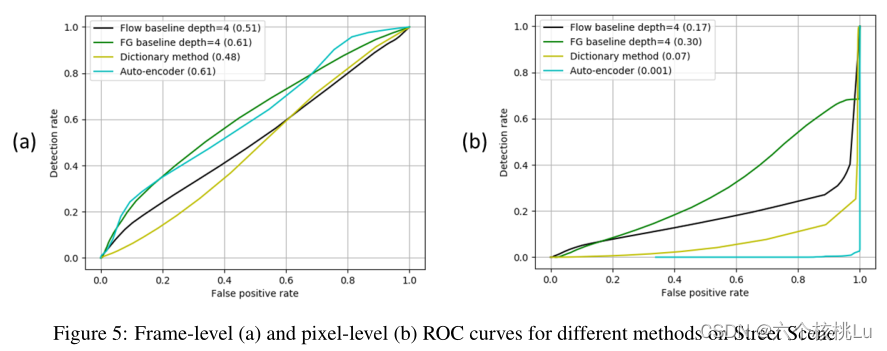
作者还在图5(a)和(b)中展示了两种基线算法以及使用传统的帧级和像素级标准的字典和自动编码器方法的结果。他们展示这些结果的目的是为了说明这些标准的不足之处,但不是为了与未来的工作进行比较。我们认为这些标准不应该被用于未来的街道场景。帧级的结果(不考虑空间定位)表明,自动编码器方法与前景基线的表现差不多,字典方法几乎与流量基线一样好。然而,当我们看一下自动编码器和字典方法实际检测到的每一帧的哪些区域是异常的,准确率就相当低了。这可以从基于轨迹的、基于区域的和像素级的ROC曲线中看出,也可以通过视觉检查看出。

图8显示了在左上角包含 "person opening trunk "异常现象的帧的流动基线的输出。帧级标准将这一帧算作正确的检测,尽管检测到的像素远没有接近地面真相的异常点,但实际上是一个假阳性。
图5(b)中的像素级ROC曲线更合理,与基于轨迹和区域的ROC曲线更一致,但如前面所说,这个标准有一个严重的缺陷,即对异常得分进行非常简单的后处理就可以提高这些曲线,使它们与帧级ROC曲线完全相同。图7显示了一个乱穿马路的异常现象的例子,它的像素被检测到的比例不到40%,因此根据像素级标准,它是一个漏检。这个标准也忽略了汽车下面的一个假阳性区域。基于区域和轨迹的标准将把它算作一个正确的检测和一个假阳性。作者认为,这更符合人类对这一帧应该如何计算的直觉。



















 721
721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











