









论文题目:PIXOR: Real-time 3D Object Detection from Point Clouds
论文年份:2018年
论文来源:
PIXOR: Real-time 3D Object Detection from Point Clouds
论文代码:
下面是pytorch版本:
philip-huang/PIXOR
论文提出:作者考虑了对点云数据直接进行处理,对点云数据体素化,对点云数据直接进行3D卷积后,认为这些操作需要更多的是对原始数据的预处理,并且3D卷积带来的计算量也是非常的大,并且由于点云数据的稀疏特点,并不是太适合直接使用。但是,经过考虑后,对于将点云数据映射到BEV(Bird`s Eye View)鸟瞰图上,对于数据的信息损失不多,而且还保留的目标的高度信息,综上考虑作者还是决定使用BEV图进行3D目标检测,并且给出检测目标的边界框(bounding-box)。
相关的3D目标检测综述:
基于卷积神经网络的目标检测
1、Imagenet classifica- tion with deep convolutional neural networks
2、Faster r-cnn: Towards real- time object detection with region
proposal networks
单级目标检测(single-stage object detection) 1、You only look once: Unified,real-time object detection.
2、Ssd:Single shot multibox detector
3、Densebox: Unifying land- mark localization with end to end object detection
4、Focal loss for dense object detection
基于点云数据的目标检测
1、Voting for voting in online point cloud objectdetection
2、Learning spatiotemporal features with 3d convolutional networks.
3、PointNet: Deep learning on point sets for 3D classification and segmentation
如果对PointnNet感兴趣,可以看我的另一个文章
你可skr小机灵鬼:PointNet论文及代码(一)4、Multi-view 3d object de- tection network for autonomous
driving.
PIXOR网络结构
1、为什么叫做PIXOR
ORiented 3D object de- tection from PIXel-wise neural network predictions,这是论文中作者对该网络的简称,全称是:基于像素级神经网络预测的三维目标识别。
2、网络输入(Input Representation)
作者对网络的输入,做过一些考虑,比如,voxel处理以及直接对raw point cloud使用3D卷积,前者在3D目标检测中经常的使用,对于后者,作者认为,一方面,3维坐标系维度要比2D的图片数据更高,而且相比较而言计算量会更大,这对网络的计算、速度以及准确度都会产生影响,因此作者决定使用BEV进行目标检测。
3、Network Architecture
PIXOR网络是全卷积的网络,并且该网络没有使用Faster RCNN中提出的region proposal network,Faster r-cnn: Towards real- time object detection with region proposal networks(Faster RCNN论文链接),PIXOR网络的输出则是:网络在单个阶段输出像素级的预测,每个预测对应一个3D对象估计。
Anchors的发明让很多网络模型对于目标的检测精度得到很大的提升,但是,在这个网络模型中并没有使用到目标的多个Anchors的定义,反而则是,直接编码而不使用预定义的对象锚,并且也有很好的效果和计算速度。网络模型的整体结果如下
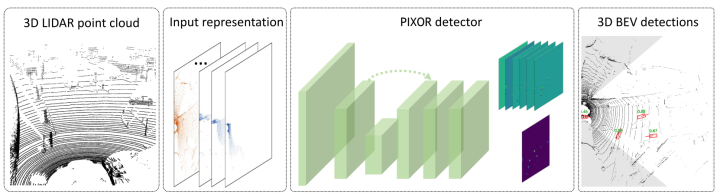
PIXOR网络模型结构
4、网络的两个子网络(backbone+header)
1、backbone主干网络(下图中橙色背景部分)(特征提取)
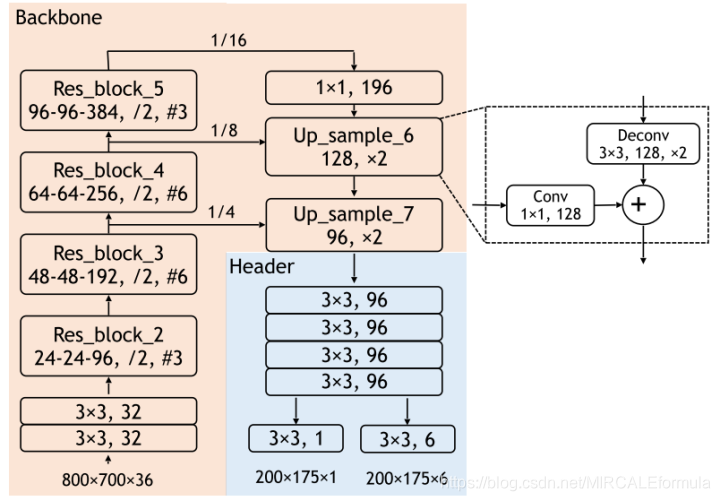
正如卷积网络计算一样,该部分的主要作用就是用来对输入的数据进行卷积计算,然后产生相应的特征矩阵,Faster RCNN网络的设计会对产生的feature输入到RPN网络进行计算,最终得到相关的分类和预测结果等信息,但是,该网络的对于目标的检测任务交给的是header自网络,而不是RPN网络。
2、header网络(目标预测)
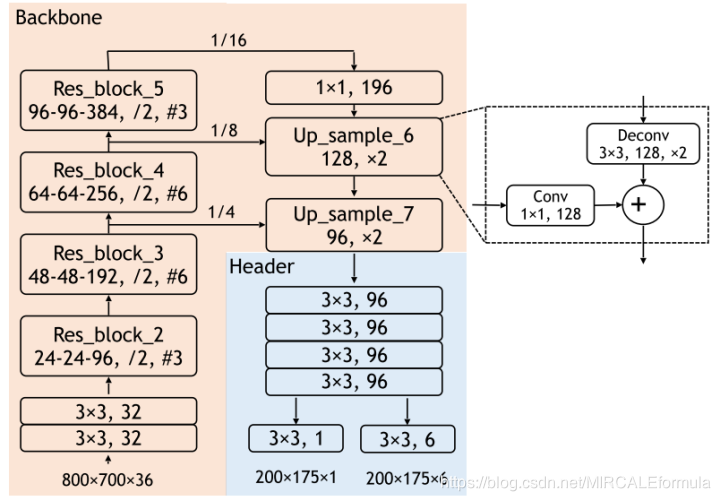
5、网络细节
5.1 Backbone子网络
首先考虑的问题就是,卷积的计算会让物体变得更加“模糊”,卷积网络更加使用到图像中,这是由于图像的一个个的像素组成,但是当卷积遇到了点云数据,就会出现一个问题,由于点云中的物体很小,当使用0.1m的离散化后,一个典型的车辆的大小会占有18*40个像素,并且文中提到,当经过16轮的down-sampling后,仅仅就只有覆盖到了3个像素,在这个过程中丢失了大量的信息。
文中提到的方法,第一种是考虑使用更少的池化层,但是这样会导致最终得到的特征图的每个像素的接受域减少,从而限制了表达能力。另一种方法就是考虑,扩大卷积,但是这样会出现像论文(Deconvolution and checker- board artifacts)中提到的重叠区域出现的问题。
PIXOR网络的解决办法则是:网络依然采用的是16轮的向下采样,但是做了两个改变
1、在较低的层次上添加更多的通道数较少的层,以提取更多的细节信息。
2、采用了一个类似于Feature Pyramid Networks for Object Detection
(特征金字塔)的自顶向下的分支,它将高分辨率的feature map与低分辨率的feature map结合起来,从而对最终的feature representation进行上采样。
正如backbone网络结构图中所展示的,骨干网络一共有5个部分
第一个:包括两个卷积层,参数为:channle-32,stride-1
第二个到第五个都是由残差层组成。
残差层的网络具体参数:
为了对特征图进行向下采样,每个残差块的第一次卷积的步长为2。总的来说,下采样系数是16。为了向上采样特征图,添加了一个自顶向下的路径,该路径每次向上采样2个特征图。然后通过像素求和将其与相应分辨率的自底向上的特征映射相结合。使用了两个上采样层,得到了最终的特征图,其中包含了相对于输入的4个下采样因子。
5.2 Header子网络
header子网络担任的任务则是,对目标进行识别和对目标进行定位。因此,header子网络设计的简单,并且高效。
header子网络左下方的输出,是一个1 channel的输出分支,用来进行分类,使用的激活函数是sigmod激活函数。
header子网络右下方的输出,是一个6 通道的特征图,用来进行回归任务。
对于方向bounding box的定义
作者将每个对象作为一个参数化的边界框b{θ,xc、yc、w、l},与每个元素对应的航向角(范围内(−π,π)),对象的中心位置,和对象的大小。其中xc和yc是目标相对在2D图片上的中心位置(目标的中心位置,通过中心位置就可以判断为题的准确大小:这是因为目标的宽(w)和长(l)给出了,因此知道目标的中心位置就可以对目标进行定位和检测)。目标的检测的bounding-box给出的示例图,如下
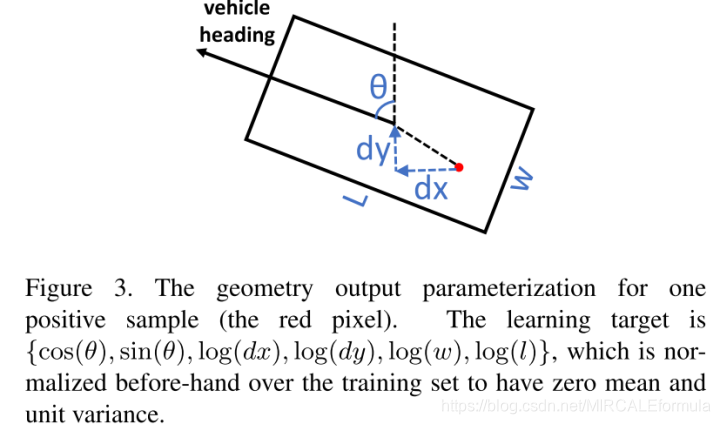
oriented bounding box相关参数定义
参数解释:
图中红色的点:代表的是一个正样本的位置,并且,我们可以很简单的看到这个正样本距离目标的真正的中心位置还是有一定的差距,因此作者定义的学习目标为:**{cos(θ),sin(θ), log(dx), log(dy), log(w), log(l)}
θ:需要进行解码使用,解码为:atan2(sin(θ),cos(θ))
坐标(dx,dy):表示的是正样本的点距离真正的目标的中心位置的偏差(offset)
(w,l):代表目标物体的size大小
6、网络训练等
- 损失函数:使用的是多任务损失(参考faster rcnn中的多任务损失),进行计算。
分类任务使用的是 sofrmax多元分类。回归任务使用 smooth损失,相比较L1损失smooth更加的平滑,并且减小梯度消失。PIXOR对于所有的位置都使用到了分类损失,但是针对于正样本的正位置使用回归损失。
- 损失函数定义:
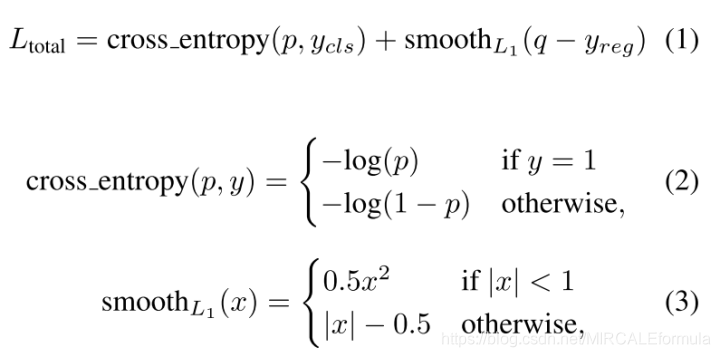
- 从损失函数中可以看到,分类任务使用的是交叉熵损失,用来判断两者之间的差距,从而进行优化;回归任务使用的是smooth L1损失,从该损失函数就可以看出,该损失函数要比L1损失函数更加平滑,并且从下图中的对比也可以看出
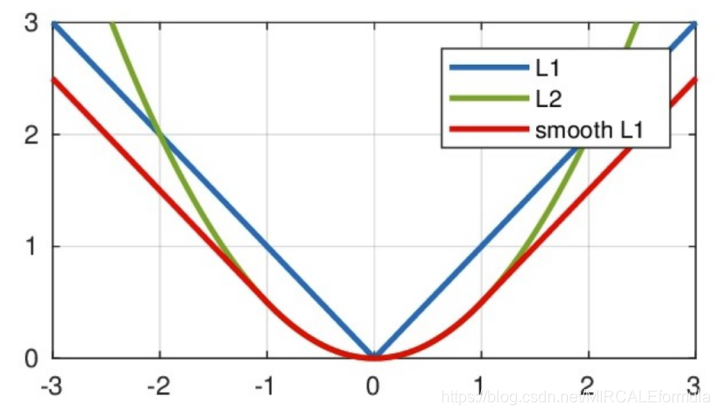
- 使用Focal Loss稳定训练过程
7、实验部分
1、benchmark:KITTI官方数据集
2、PIXOR也进行了消融实验(ablation):这里介绍一下消融实验:简单的理解为,将网络中的部分去掉再次进行训练,查看结果如何(更加具体可以询问度娘)。本文在三个方面进行了消融实验:优化,网络架构,速度,这三个方面。
3、将PIXOR应用到一个新的大规模自动驾驶车辆检测数据集中,验证了其泛化能力。 实验细节部分如下图:
网络性能评价指标:
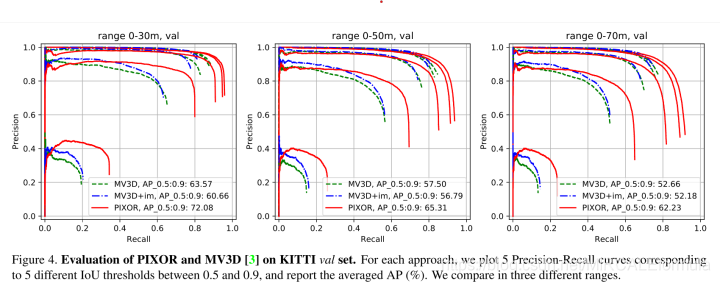
AP(Average Precision)平均精度:使用0.7的IoU(Intersection-Over-Union)作为评价指标。
指标的变化曲线图,反映在,(论文引用:The Pascal Visual Object Classes (VOC) Challenge),召回率的变化曲线图中,下图所示

8、消融实验部分
消融实验的设置:
val集合:其他网络训练的方法的性能存放集合。
val-dev集合:数据不和train以及val数据集数据重复的部分。该集合主要 存放的是消融实验的实验结果。
评价指标:0.7 IoU以及0.5-0.95的IoU
消融实验涉及的部分主要有一下几点:
- Optimization(优化)
- 分类损失
可以看到,在分类损失使用的是focal的损失时,网络的平均精度普遍高于分类损失使用的是交叉熵损失。

- 回归损失
- 分类损失
在回归损失中,默认的选择是使用smooth L1损失,但是,文中提出了一种新的损失–decoding
loss,输出目标首先被解码成有方向的盒,然后根据四个盒角的(x, y)坐标直接根据ground-
truth计算平滑的L1损耗。更改为decoding loss后模型的性能,参考上图。
- 取样策略&数据增强
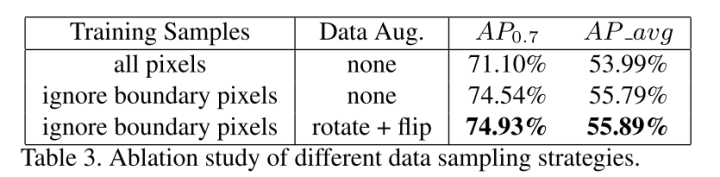
当对稠密的目标进行训练的时候,一个问题出现了,那就是如何对正样本和负样本进行定义。考虑到之前得一些方法,是基于IoU以及proposal得,但是PIXOR是proposal-free的方法。因此,作者提出了一个更加直接的方法,来对方法中的正样本和负样本进行定义,即,ground-truth内部的点是正样本,外部的全部认为是负样本。这确实够直接的,但是这样做的优点也是存在,提升计算速度,并且准确度也是比较合适的。一个问题的解决,随之出现另一个问题,该方法虽然方便直接,但是,对于靠近目标边界的点就会产生很大的回归目标方差,这个好解决,直接忽略这些点就可以了。
再具体一点,文中的取样策略,对ground-truth boxes进行缩放,文中分别选择0.3和1.2进行缩放,并且选择性忽略位于这两个缩放范围内的点。性能图,如下,可以看到处理后的结果还是有提升的,但是提升并不是很大。
- Network Architecture(网络结构)
- Backbone部分
该部分就是对PIXOR中的骨干网络的模型进行更换,然后对比不同的实验性能。更换的模型有:vgg16-half、resnet-50、pvanet 以及resnet-lidar,对比实验结果如下图。
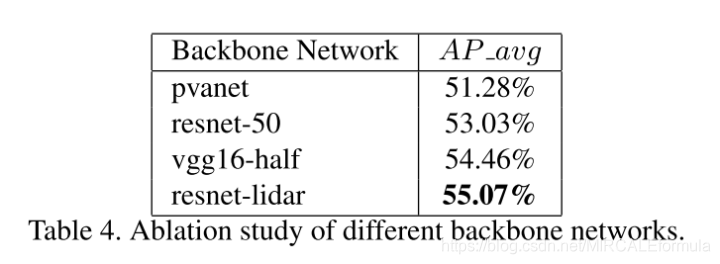
- Header部分
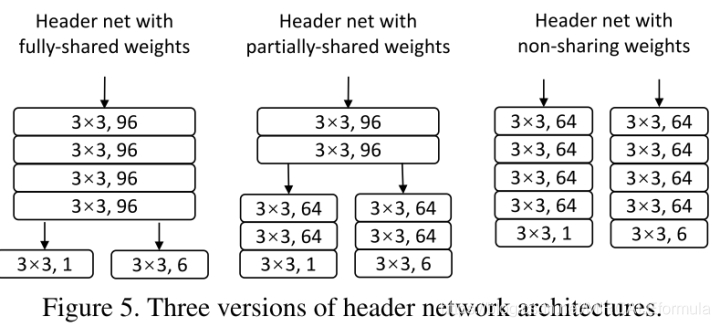
header部分对网络的更改在于权重共享部分,分为三类:完全共享权重、部分共享以及不共享,如下图
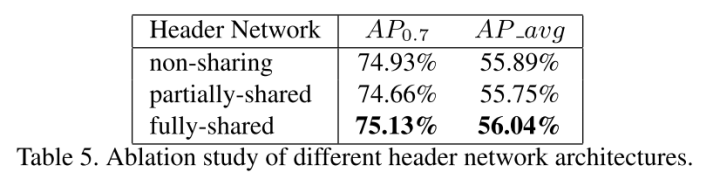
更换后网络模型的性能指标如下:
- Speed(速度)
pass - Failure Mode
在下图中展示了PIXOR的一些检测结果,并发现了一些故障模式。一般来说,如果没有观测到激光雷达点,PIXOR就会失败。在更长的范围内,我们几乎没有对象的证据,因此对象定位变得不准确,导致在更高的借据阈值下出现错误的借据。(来自原文的翻译)

9、大规模场景下的实验
直接总结,文中提到在ATG4D,下可以运行10fps的速度。
- Backbone部分














 436
436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









