









接着上回好久的PointNet论文(一)
PointNet论文阅读
接着上次大家对论文的创新点和基本的知识的了解,我们正式开始讲解代码部分。上次的文章中用到的是tensorfloe1.x版本的。但是,在这里最近写代码,做实验用到的是pytorch所以对pytorch比较熟悉,所以选择用pytorch讲解
。当然,本质来说,无论是keras还是tf还是torch还是其他的计算框架,只是一个工具而已,当然,自己可以实现numpy的神经网络的前向传播,后向传播等等,但是也是没有必要的,别人给你提供好了,方便的,高性能的计算框架,你学习api调用就可以了,但是,对于底层的基本实现还是需要有自己的了解和认识。
该部分的代码的介绍以PointNet分类网络为主进行介绍!
如果不想看第一部分网络是如何跑起来的可以直接从第二部分开始看PointNet代码部分。
1、网络是如何跑起来的?
这一部分,可以百度找一些更加详细的说法,这里就简单说一下自己的理解。如果有不正确的地方请指正,谢谢。
1.1. Model(网络模型)
该部分只是在计算机视觉,更具体的说是在这篇文章的研究方向领域内的介。
模型就是大家说的神经网络中的一部分组成,无论是处理图像、处理3D点云数据还是处理视频还是自然语言,输入到网路模型中参与计算的一定是数字,而不是文字,而不是图片(当然图片就是像素数据),也不是视频(视频是一帧一帧图片组成)。
从最基本的单个神经元开始说起,假设神经元 A \mathbb{A } A 有两个输入, x 1 \mathbb{x_{1}} x1和 x 2 \mathbb{x_{2}} x2 ,经过神经元 A \mathbb{A} A的计算为简单的两个数求和加法计算,最后输出神经元计算结果的 y \mathbb{y} y。
用数学表达是表示就是 y = x 1 + x 2 \mathbb{y}=\mathbb{x_{1}+\mathbb{x_{2}}} y=x1+x2 。
但是,这样的一个神经元是没有办法优化的,因为,输入数据是常数,输出结果也是常数在梯度计算时,会得到梯度为0,就没有办法优化,因为,我们需要修改神经元的操作。给输入数据×一个权重(weights),+一个偏置(bias)。最终,我们得到的计算为 y = [ x 1 x 2 ] [ w 1 w 2 ] T + b i a s \mathbb{y}=[x_{1} \space \space x_{2}][w_{1} \space \space w_{2}]^{T}+bias y=[x1 x2][w1 w2]T+bias 得到上面的式子,这一个神经元就可以完成优化了。当然最终得到的结果就不是原本的 y \mathbb{y} y了。但是,在这个神经元的梯度优化的过程中,最终 y \mathbb{y} y 的值会接近到原本的 y \mathbb{y} y的值。
1.2. Loss(损失函数)
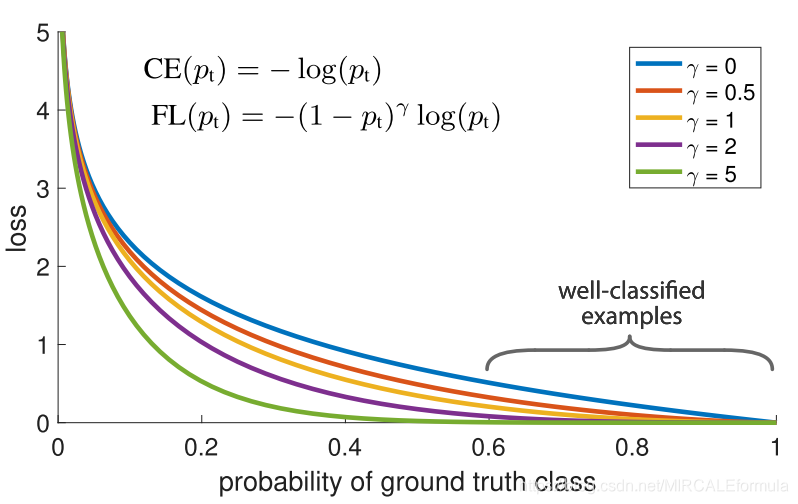
损失函数这一部分,如果说Model是用来计算网络的参数,那么Loss的作用就是用来评价网络参数的优化的好坏。对于,损失函数的设计,不同的网络有不同的损失函数的设计。并且,不同的损失对于同一个网络的性能的改变也是不同的。对于下面这篇Focal Loss损失函数的设计。作者,在基本的交叉熵损失函数的基础上添加一个 ( 1 − p t ) γ (1-p_{t})^{\gamma} (1−pt)γ参数,并且对于不同的 γ \gamma γ 的取值,网络的损失的变化也是不同。见下图1.
1.3. 数据预处理
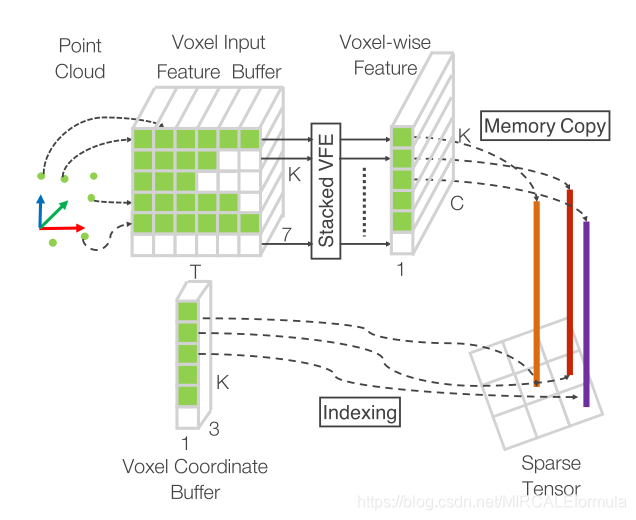
最后,再讲这一部分的原因是,这一部分可以说是网络的重点,当然,数据的处理,不简简单单是在将数据输入到网络之前对数据进行的处理,并且还包括,数据在网络运行时的一些处理。例如,下面这个VoxelNet设计的Sparse 4D Tensor。用于点云特征提取的设计。
Efficient Implementation
Sparse 4D Tensor设计图如图2所示。
最后,对于网络是如何跑起来的这个问题还是简单的总结一下。
首先,对于输入到网络的数据,可以进行数据预处理,当然,也可以使用之前文献资料中别人的方法,进行特征提取等等方法。其次,就是对于数据的理解和掌握一定要清楚,比如,如果你选择做3D点云目标检测方向,你需要了解一些基本的数学知识、几何知识,当然还需要了解线性代数。
第二,损失函数的设计,一般来说,我认为的损失函数的设计,会几何人工标注的信息进行设计,一方面是为了让网络的参数更加好,另一方面是可以体现人工智能(有人工才有智能,小样本学习,零样本学习的崛起一定会向着智能方向发展,而不是大量人工标注的数据的基础上进行网络的训练和优化)。
第三,网络跑起来还需要一个最最重要的东西,如果说你自己可以用求导的方式得到一个函数的极大值、极小值、最大值、最小值、拐点、驻点等等各种点。但是,网络他不会啊,网络输入的数据是数据,而不是未知量,所以,论文的另一个创新点就出现了,我们可以设计一个好的梯度下降算法,当然,这一个创新点是非常非常难的。
第四,网络模型的设计。在模型设计这一方面,从最初的AlexNet到GoogleNet、VGG在到ResNet、Yolo、U-Net等等这些无敌的网络的设计
网络是如何跑起来的组成的部分,就讲到这里,下面开始正题PointNet
2. PointNet
首先PointNet有两个,一个论文的名字叫做:《PointNet: A 3D Convolutional Neural Network for Real-Time Object Class Recognition》论文在下面,感兴趣的可以自己查看、阅读。
然而,另一个才是我们要讲解的PointNet,论文名字叫做:《PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation》
2.1. Modeld(网络模型部分)
再贴一下模型的整体设计,如图3所示

2.1.1. Classification Network
根据网络的整体结构也可以看到。输入的点云数据,经过第一个transform后将输出给了下一个mlp(64,64),然后输入的数据从 3 channels 变成了 64 channels ,之后给了第二个transform后,又接一个mlp(64,128,1024),经过这一层多层 感知机的计算后,最初的输入数据从 3 channels ——> 64 channels ——> 1024 channels , 最后,接一个max pool 在这里按照论文中的意思是说,最大值池化的作用就是:最大池化层作为一个对称函数来聚合所有点的信息。
2.1.1.1. 首先,分类网络的整体设计如下:
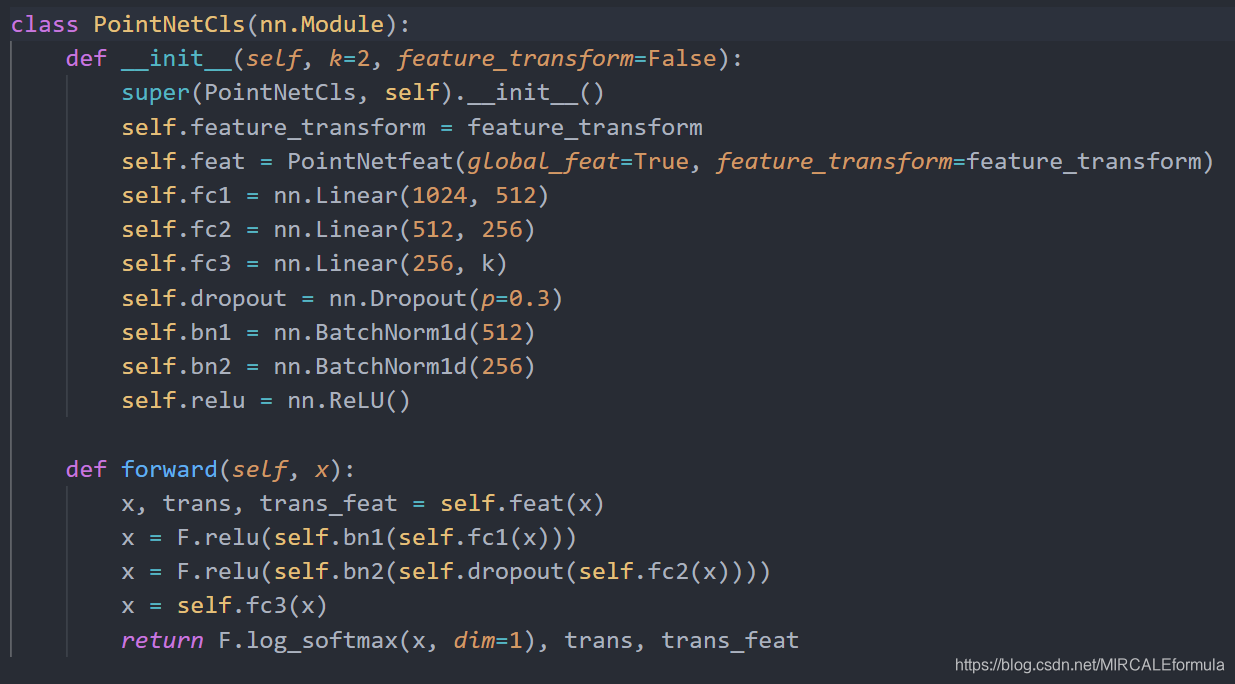
从分类网络的代码中可以看到,这段代码的关键部分是这个叫做PointNetfeat的类。所以,我们看一下PointNetfeat这个类的定义,就是用来提取点云特征的类。我们叫他为特征编码层Encoder
2.1.1.2. 下图为PointNetfeat的代码构造:
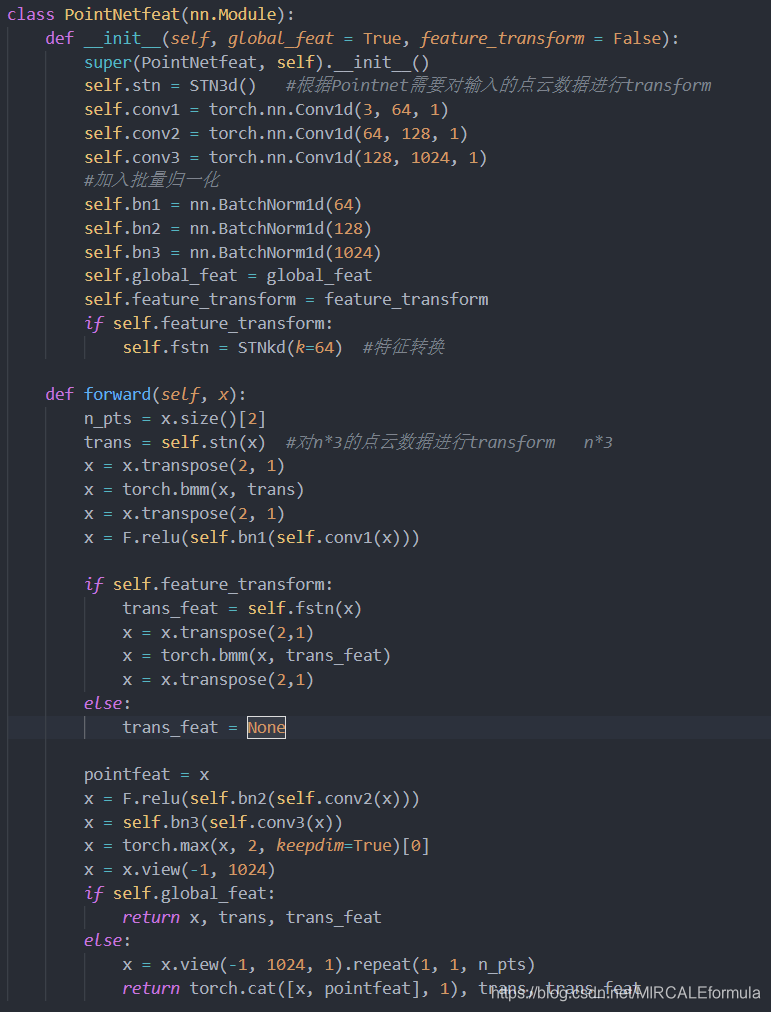
先不看网络的前向传导部分的逻辑设计,我们可以清楚的认识到,关键是这个叫做STDN3d的类。然后,还有一个STDNkd的类。这两个类就是在网络整体设计中的那两个Transform
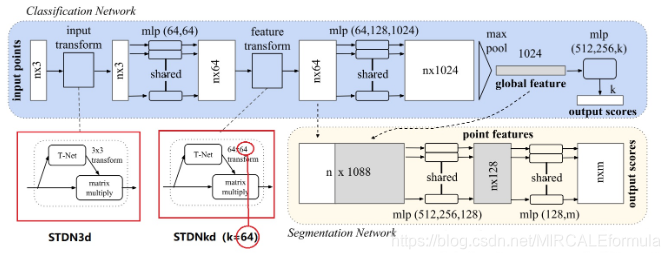
2.1.1.3. STDN3d网络模型代码部分:
在将网络之前,要先从源代码中明白STDN3d的作用是一个变换矩阵,最终将输入的点云数据转换为根据变换矩阵相乘的形式的shape
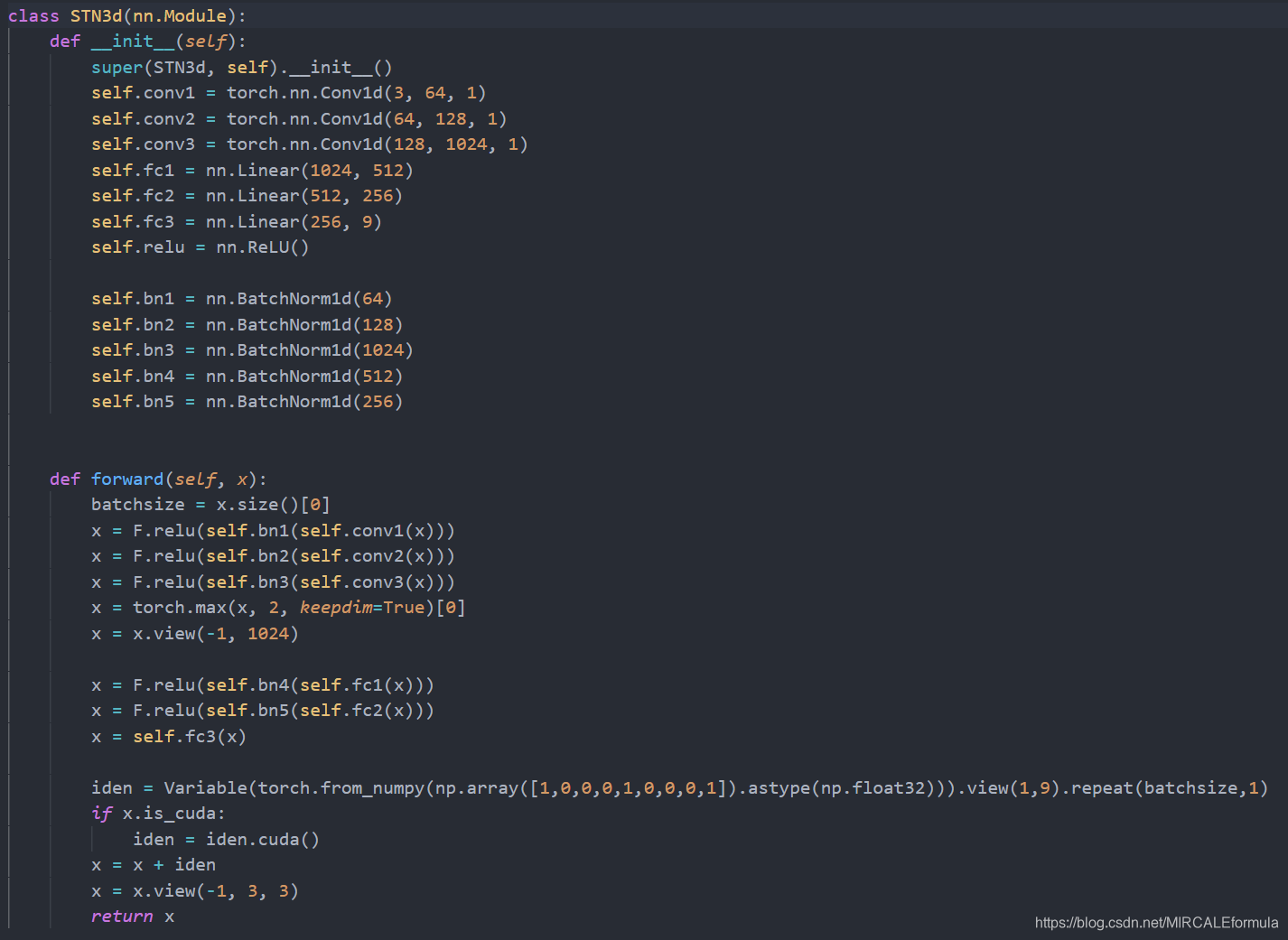
为了更加直观的看一下网络的结构,下面使用visio简单画了一下STDN3d网络的结构图:如果出现有问题的,画的不对的地方请指正,谢谢。

最终,经过 x . v i e w ( − 1 , 3 , 3 ) x.view(-1,3,3) x.view(−1,3,3) 矩阵的数据shape变化,转换成一个(N(批次大小),3,3)shape的变换矩阵,这个矩阵就是STDN3d最终生成的矩阵
如果,不懂 view()中指定的-1是什么意思:下面给出解释
指定 -1 参数的意思就是,在矩阵shape变换时,不指定这个位置的shape,而是直接交给pytroch进行计算。例如,A=(2,3,3)类型也就是整体是 2 ∗ 3 ∗ 3 2*3*3 2∗3∗3 =18,所以我们可以变换为 A.view(-1,2,3),此时-1就会交给view函数自己计算,结果就是18/(2*3)=3,但是,如果你指定为这样A.view(-1,2,2)就会报错,因为无法转换,这样计算和原矩阵的类型无法匹配。
变换矩阵的作用就是,参与网络结构图中的 [公式] 的变换时使用的。并且,至于为什么这样就可以达到效果,可以看原论文中作者关于这部分的数学推理。
2.1.1.4. STDNkd网络
说完了STDN3d,再接着说一下STDNkd没错,如果你直接使用STDNkd将k参数指定为3,就变成了STDN3d。但是,为了更加让网络清楚,就不对网络代码进行重构了。
STDNkd整体的网络结构如下图
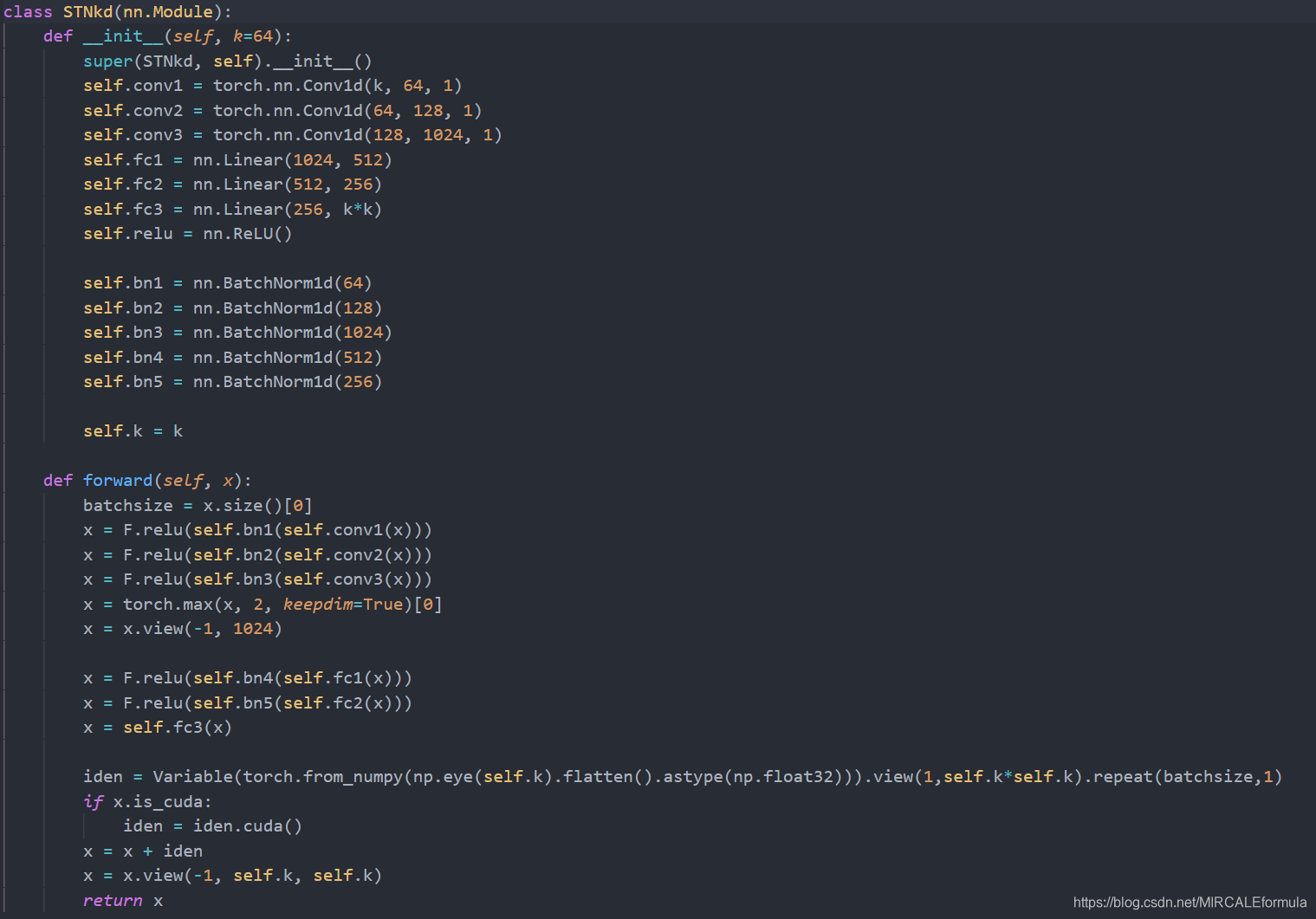
鉴于STDNkd的网络结构和STDN3d的十分相似,大家可以自己理解。
2.1.1.5. 特征提取网络的逻辑定义
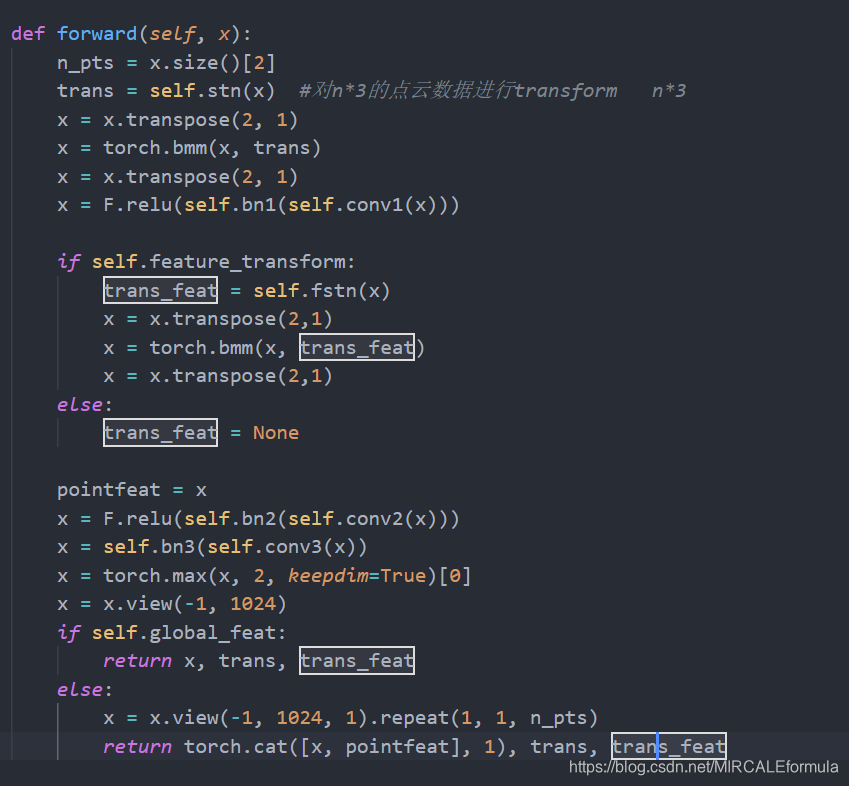
这部分的网络设计和网络设计的总览图中一模一样,对照的看就可以,但是,需要记住的是STDN3d和STDNkd的作用是干什么的。
2.1.1.6. 分类网络最后
最后,分类网络的各个Sub-Net看完了,需要知道网络的输出到底是什么。
1、网络的输入是点云数据,shape=(N,n,3)
N是批次数量
n是点云包含多少点(这个数据在KITTI官方的数据集的文件里面都会有)
3是x,y,z坐标
2、网络的输出
不管网络的黑匣子的设计,只看输入和输出,对于网络的输入数据清晰明了,就是输入的点云数据,当然不同的网络设计还会有不同的输入,比如有基于多模态、或者多视角的方法,会选择将图片也作为网络的输入,结合点云一块完成点云目标检测任务。比如,Frustum PointNets方法,将2D图片提出的RP区域,和点云做一个映射,由于这个映射的形状和锥台(Frustum)相似,故成网络为F-PointNets(Frustum PointNets方法)。
回到正题,PointNetCls分类网络的输出是什么?
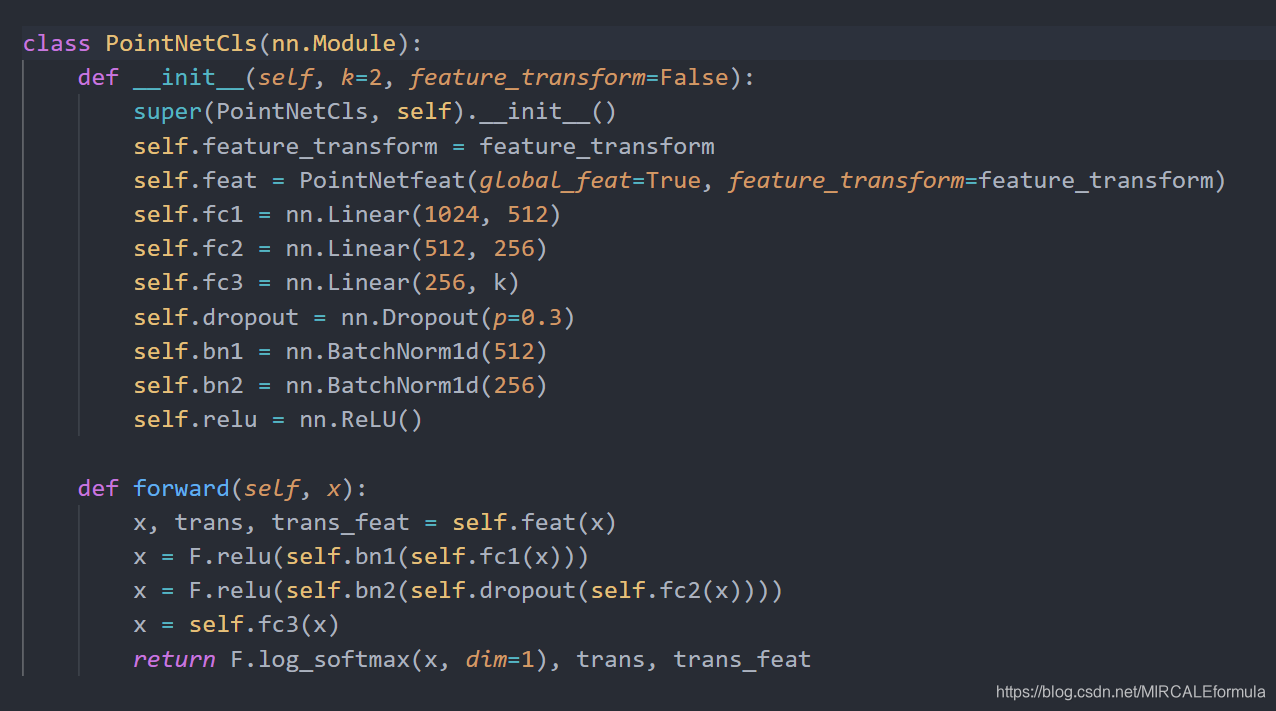
从网络的前向传播可以看到,网络的最后的设计返回是:
①:softmax多元分类器生成的分类,就根据这个图中的k=2的定义。经过最后一个全连接层(fc3())计算后,网络参数的维度从256->k(k=2)。从而,参数矩阵变成了(N(批次大小),2)在后面的定义中,k值得设定为num_classes(点云数据中的样本类别数),目的就是根据多元分类器对这个目标的不同类别给出一定的分数,然而,我们只认为数值最大的是分类的类别。更加值观的理解就是:比如,log_softmax计算后得到一个1*3的tensor数值为(-1.199(苹果),2.111(香蕉),0.888(西瓜))。好的,那么我们认为这个检测类别是个香蕉,注意在这一步我们就认为是“香蕉”,不去判断它是不是真的是香蕉,对于判断它是不是真的是香蕉,就需要我们的标签和人工标注的数据,完成损失函数的设计,从而提升网络的分类准确度!
②:第二个输出是一个trans,trans的来源是feat(PointNetfeat这个子网络的输出),这一部就是作者设计的对点云特征的提取的结果,但是,trans是一个转换矩阵。(还记得网络整体图中的 3 3 transform 和 64 * 64 transform 吗?)
③:第三个输出是tran_feat,好的这个就是转换后的特征!特征编码!
2.2. Loss损失函数

①:使用到的损失函数是NLLLoss,英文的全名叫做:Negative Log Likelihood Loss,翻译过来的意思就是:Log似然代价函数。这个损失函数的具体讲解可以去看一下吴恩达的视频。在pytorch中对于这个损失函数的具体讲解在torch.nn.NLLLoss(),官方提供了两种定义方式第一种是:
ℓ ( x , y ) = L = { l 1 , … , l N } ⊤ , l n = − w y n x n , y n , w c = weight [ c ] ⋅ 1 { c ≠ ignore_index } \ell(x, y) = L = \{l_1,\dots,l_N\}^\top, \quad l_n = - w_{y_n} x_{n,y_n}, \quad w_{c} = \text{weight}[c] \cdot \mathbb{1}\{c \not= \text{ignore\_index}\} ℓ(x,y)=L={l1,…,lN}⊤,ln=−wynxn,yn,wc=weight[c]⋅1{c=ignore_index}
第二种是:(根据官方提供的api的意思是,下面这个可以用到更高维度的数据,也可以用在2D图片上,如果你用在了2D图片上,那么计算得到的损失就是每个像素的NLL损失)
ℓ ( x , y ) = { ∑ n = 1 N 1 ∑ n = 1 N w y n l n , if reduction = ’mean’; ∑ n = 1 N l n , if reduction = ’sum’. \ell(x, y) = \begin{cases} \sum_{n=1}^N \frac{1}{\sum_{n=1}^N w_{y_n}} l_n, & \text{if reduction} = \text{'mean';}\\ \sum_{n=1}^N l_n, & \text{if reduction} = \text{'sum'.} \end{cases} ℓ(x,y)={∑n=1N∑n=1Nwyn1ln,∑n=1Nln,if reduction=’mean’;if reduction=’sum’.
②:如果参数使用到了特征转换,那么这部分的损失也需要加到最终设计的损失函数中。转换的损失的设计如下图
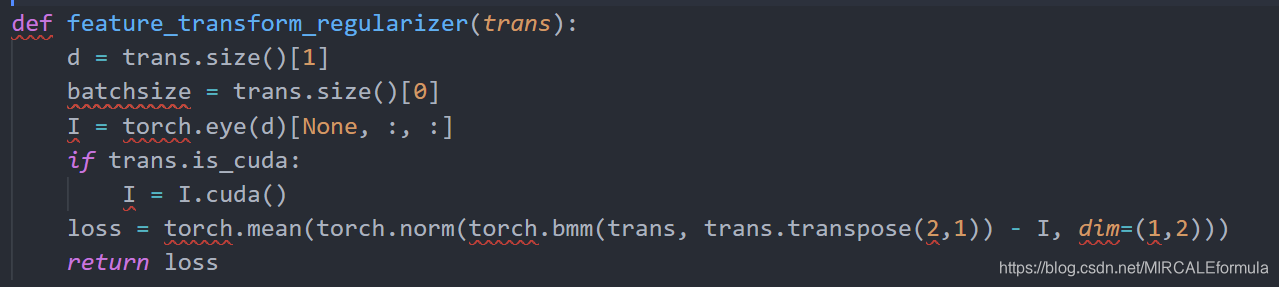
用公式把这个地方的损失表示出来就是
m
e
a
n
(
∑
N
o
r
m
a
l
i
z
a
t
i
o
n
(
t
r
a
n
s
∗
t
r
a
n
s
T
−
I
(
单
位
阵
)
)
)
mean(\sum Normalization(trans * trans^{T}-I(单位阵)))
mean(∑Normalization(trans∗transT−I(单位阵)))
t r a n s T trans^{T } transT是不太准确的,因为数据还有批次,所以简化写成这样。按照dim=(1,2)的维度轴进行计算。
2.3. 梯度下降算法

使用Adam梯度下降方法,想更加深入了解这个梯度下降算法的可以自行了解。
3. 万事具备,只欠训练这个东风
其实,上面的顺序不是我看代码的顺序,我喜欢先看别人写的 training代码,然后根据训练去看逻辑,这就像是一个思维导图。导图的主题是 训练,然后延申有 Model、Loss、Gradient、DataAugment以及DataPreprocessing。
由于训练的代码有点长,所以我把关键部分放在下面。
optimizer = optim.Adam(classifier.parameters(), lr=0.001, betas=(0.9, 0.999))
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.5)
classifier.cuda()
num_batch = len(dataset) / opt.batchSize
for epoch in range(opt.nepoch):
scheduler.step()
for i, data in enumerate(dataloader, 0):
points, target = data
target = target[:, 0]
points = points.transpose(2, 1)
points, target = points.cuda(), target.cuda()
optimizer.zero_grad() #清除梯度
classifier = classifier.train()
pred, trans, trans_feat = classifier(points)
loss = F.nll_loss(pred, target)
if opt.feature_transform:
loss += feature_transform_regularizer(trans_feat) * 0.001
loss.backward()
optimizer.step()
pred_choice = pred.data.max(1)[1]
correct = pred_choice.eq(target.data).cpu().sum()
print('[%d: %d/%d] train loss: %f accuracy: %f' % (epoch, i, num_batch, loss.item(), correct.item() / float(opt.batchSize)))
if i % 10 == 0:
j, data = next(enumerate(testdataloader, 0))
points, target = data
target = target[:, 0]
points = points.transpose(2, 1)
points, target = points.cuda(), target.cuda()
classifier = classifier.eval()
pred, _, _ = classifier(points)
loss = F.nll_loss(pred, target)
pred_choice = pred.data.max(1)[1]
correct = pred_choice.eq(target.data).cpu().sum()
print('[%d: %d/%d] %s loss: %f accuracy: %f' % (epoch, i, num_batch, blue('test'), loss.item(), correct.item()/float(opt.batchSize)))
torch.save(classifier.state_dict(), '%s/cls_model_%d.pth' % (opt.outf, epoch))
total_correct = 0
total_testset = 0
for i,data in tqdm(enumerate(testdataloader, 0)):
points, target = data
target = target[:, 0]
points = points.transpose(2, 1)
points, target = points.cuda(), target.cuda()
classifier = classifier.eval()
pred, _, _ = classifier(points)
pred_choice = pred.data.max(1)[1]
correct = pred_choice.eq(target.data).cpu().sum()
total_correct += correct.item()
total_testset += points.size()[0]
print("final accuracy {}".format(total_correct / float(total_testset)))
对于pytroch,训练时的数据肯定不能自己读取,自己shuffle自己来完成,当然是选择官方给我们提供的方便的API那就是DataLoader。在使用DataLoader时,还可以对自己的数据集进行定义,关键操作就是继承负类Dataset(torch.utils.data.Dataset)。然后,重写负类的_getitem__方法就可以遍历数据了。在这个过程,你就可以完成对数据集的预处理和增强处理了!
4. 最后再啰嗦一下
我喜欢看别人的代码先从 training开始,将重点放在他们对数据预处理和数据增强上面,网络的设计,以及每一层网络,为什么使用Up-Sampling以及Down-Sampling都需要大家自己慢慢积累,不过你可以看一下Google Brain推出的超级网络:EfficientNet
,里面有相关的信息介绍,当然还有最近很火的YoLo v4里面关于网络设计的思想。都是需要大家慢慢积累的!
再补充一句,同一个作者(Mingxing Tan)写的另一篇网络:
EfficientDet: Scalable and Efficient Object Detection,也是很值得看一下的

















 2217
2217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









