







前言
1. 为什么要做这个研究?
- 将点云体素化做3D卷积计算量大,而且由于点云的稀疏性,很多计算都是不必要的。
- 将点云投影到一个平面上做2D卷积,会丢失部分信息。
- 作者考虑可以输入的是3D体素,但是做的是2D卷积。
2. 实验方法是什么样的?
- 输入是36个通道的3D体素数据,包括35个通道的3D体素特征,每个体素网格通过1和0表示该网格内是否有点云中的点,还有1个通道代表体素网格的反射率。
- 在鸟瞰图下做2D卷积预测目标框,不预测z值和框的高度(建立在自动驾驶所有物体大都处于同一个平面的情况),包括中心点坐标、航向角以及框的长宽。
- 不使用anchor,以缩小GT框内的像素点为正例点,放大框以外的像素点为负例点,中间部分的点不参与计算损失。
3. 得到了什么结果?
- PIXOR作为one-stage、proposal-free的3D目标检测网络,没有预测z值,对于输入的36个通道的3D体素表征采用2D CNN处理,结果和MV3D的结果差不太多。另外,在正负例样本的选择上比较有新意。
摘要
作者解决了自动驾驶环境下直接从点云进行实时3D目标检测的问题。通过鸟瞰图(BEV)表示场景,可以更加有效地利用3D数据,并提出了PIXOR,一种无候选框的one-stage检测器。PIXOR能够在高精度和实时效率(10 FPS)之间取得平衡。
1. 介绍
3D目标检测使用的数据源包括RGB-D传感器得到的带有深度信息的图像和激光雷达得到的点云数据。雷达会以点云的形式生成非结构化数据,360°扫描包含大约 1 0 5 10^5 105个3D点,计算量大。
现有的点云表现形式主要分为两种:3D体素网格和2D投影。3D体素网格将点云转为规则间隔的3D网格,可用于实现3D卷积,但由于点云的稀疏性,因此体素网格非常稀疏,很大一部分的计算是多余的。另一种方法是将点云投影到一个平面上,然后将其离散化为基于2D图像的表示形式,并应用2D卷积,但这样会丢失信息。
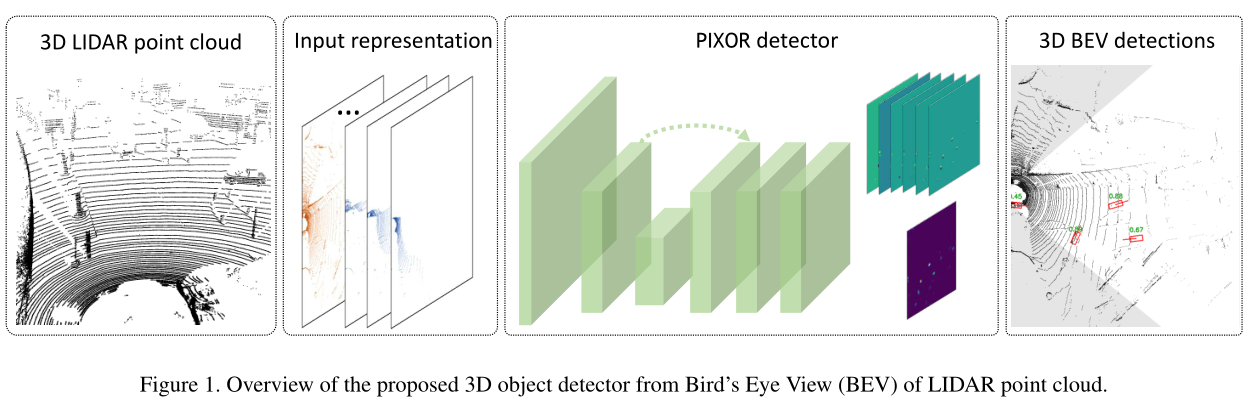
PIXOR是one-stage, proposal-free的密集目标检测器,可有效利用2D鸟瞰图(BEV)。作者使用BEV表示是因为与3D体素网格相比,其在计算上更友好,并且保留了度量空间,使得模型能够探索有关物体类别的大小和形状的先验知识。PIXOR可以在鸟瞰范围内输出真实尺寸、精确定向的边界框,在两个公开的数据集测试中保持了领先的精度和运行速度。
2.相关工作
2.1 基于CNN的目标检测
目前的目标检测方法很多都引入了目标候选框,如Region-CNN(RCNN)、Faster-RCNN等。基于候选框的检测器在准确度上表现出色,但是Two-Stage算法不适合实时应用。
One-Stage 直接回归物体的类别概率和位置坐标值(无region proposal),准确度低,但速度相较two-stage快,目前常用的典型One-Stage目标检测网络包括YOLO系列、SSD等。
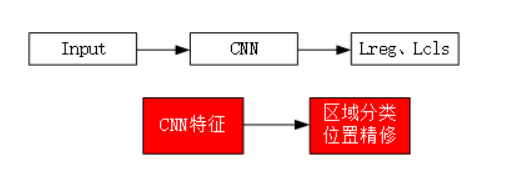
Two-Stage 先由算法生成一系列作为样本的候选框,再通过CNN进行样本分类。在训练网络时,先训练RPN网络,再训练目标区域检测的网络,网络准确度高,速度较One-Stage慢,典型代表包括RCNN、Faster R-CNN。
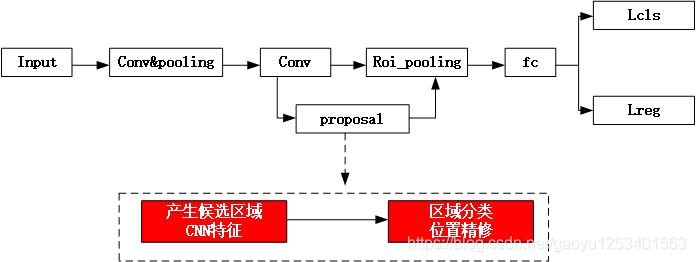
作者提出的检测器遵循One-Stage密集目标检测器的思想,通过重新设计输入表示、网络体系结构和输出参数将其扩展到实时3D目标检测,并且重新定义目标定位函数,去掉了预定义目标锚点的超参数,得到更简单的检测框架。
2.2 基于点云的3D目标检测
之前的3D目标检测器有的通过在3D体素网格上使用3D-CNN检测目标,有的将3D点云投影到2D视图上应用2D-CNN检测目标。作者提出的检测器仅将鸟瞰图表示用于自动驾驶环境下的实时3D目标检测,这里假设所有目标都位于同一地面。
3. PIXOR 检测器
作者提出的PIXOR检测器可以通过LIDAR点云产生非常准确的边界框,包括3D空间中的位置和航向角。检测器利用了LIDAR点云的2D表示,与3D体素网格相比更紧凑。接下来将介绍检测器的输入表示、网络体系结构,定向边界框编码以及有关检测器的学习和推断的详细信息。
3.1 输入表示
由于点云的稀疏性和不均匀分布,将点云转成3D体素网格再进行三维卷积会造成很多不必要的计算。因此,作者单独采用鸟瞰图来表示场景,将维度降为2,并且在颜色通道中保留高度信息,这样就可以在BEV表示中应用二维卷积。在自动驾驶中,物体一般都处于同一地面,因此这种降维是合理的,并且由于是从鸟瞰图检测目标,因此不会遇到物体之间遮挡的问题。
体素化LIDAR表示的常用特征是占有率、强度(反射率)、密度和高度特征。在PIXOR中,作者只使用占有率和强度作为特征。作者定义要检测的场景的3D物理尺寸为 L × W × H L×W×H L×W×H,然后以每单元 d L × d W × d H d_L×d_W×d_H dL×dW×dH离散3D矩形空间中的3D点。每个单元格的值均被编码为占有率(如果该单元格存在点,则为1,否则为0)。离散化后得到占有率特征为 L d L × W d W × H d H \frac{L}{d_L}×\frac{W}{d_W}×\frac{H}{d_H} d
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1166
1166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









