







论文介绍
题目
EMCAD:Efficient Multi-scale Convolutional Attention Decoding for Medical Image Segmentation
论文地址
https://arxiv.org/pdf/2405.06880
创新点
- 多尺度卷积解码器:提出了一种高效的多尺度卷积注意力解码器(EMCAD),专门设计用于医学图像分割任务,通过多尺度深度卷积块增强特征表示,有助于在有限的计算资源下提高分割性能。
- 多尺度卷积注意力模块:引入MSCAM模块,通过多尺度的深度卷积抑制无关区域并增强特征图,从而捕捉多尺度显著特征,降低了计算成本。
- 大核分组注意力门:在解码器中加入了一种大核分组注意力门,通过更大局部上下文捕捉显著特征,提升了模型对重要区域的关注度。
- 更低的计算成本与参数量:与现有的最先进方法相比,EMCAD在保持或提升分割精度的同时,显著减少了模型参数和浮点运算次数(FLOPs),在多个医学图像分割基准上达到了最优性能。
- 广泛适配性:EMCAD可用于不同的编码器结构,在多个医学图像分割任务中表现出优越的性能和适应性,适合在计算资源受限的实际应用场景中应用。
方法
整体结构
该模型由一个分层编码器和高效多尺度卷积注意力解码器(EMCAD)组成,通过编码器提取不同尺度的特征图,然后利用EMCAD中的多尺度卷积注意力模块、分组注意力门和上采样模块逐步融合和增强这些特征,实现精确的医学图像分割。最终,通过分割头输出高分辨率的分割结果,模型在保持高精度的同时显著降低了计算成本。
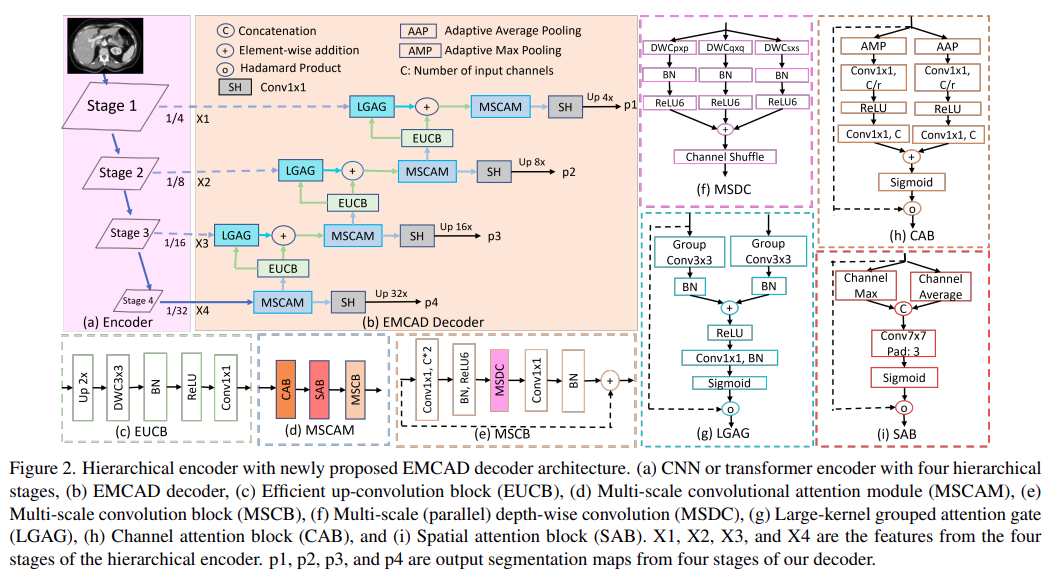
- 分层编码器:模型使用了层次化的编码器来提取不同尺度的特征图,这些特征图被分为多个阶段。编码器可以是PVTv2-B0或PVTv2-B2等预训练模型,用于捕捉输入图像的多尺度信息。分层编码器输出四个特征图(即X1, X2, X3, X4),用于后续解码处理。
- EMCAD解码器:这是论文的核心创新部分,包含多个模块:
- 多尺度卷积注意力模块(MSCAM):通过深度卷积在不同尺度上对特征图进行处理,增强特征表示并抑制无关区域。
- 大核分组注意力门(LGAG):通过分组卷积结合大核,进一步融合编码器和解码器之间的特征,以捕捉更大的上下文信息。
- 高效上采样卷积块(EUCB):该模块用于逐步上采样特征图,将特征的空间分辨率提升到目标输出的分辨率。
- 分割头(SH):每个阶段的特征图都通过一个1×1卷积输出一个分割图,最终整合多个分割图生成最终的分割结果。
- 多阶段损失和输出整合:解码器每个阶段生成的分割图会参与损失计算,采用多种组合方式计算损失,以强化各阶段输出的精度。最终分割图使用Sigmoid或Softmax函数生成二分类或多分类的分割结果。
即插即用模块作用
EUCB 作为一个即插即用模块,主要适用于:
- 医学图像分割:如CT、MRI等医学影像的像素级分割任务。
- 语义分割:广泛应用于需要精细分割的任务中,包括遥感图像分析、自动驾驶中的路面分割等。
- 资源受限场景:在计算资源有限的设备(如边缘设备、移动端)上实现高效图像分割。
消融实验结果
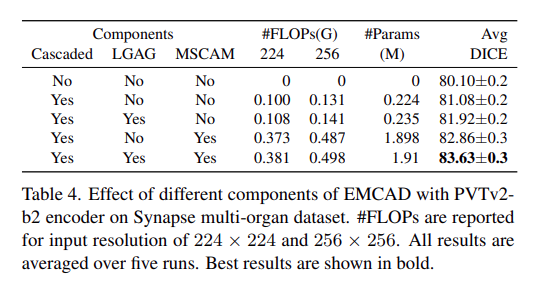
- 展示了不同组件对模型性能的影响,评估了解码器的级联结构、大核分组注意力门(LGAG)和多尺度卷积注意力模块(MSCAM)的贡献。实验结果显示,逐步添加这些模块能显著提升模型的DICE分数,其中MSCAM的效果尤为显著,当同时使用LGAG和MSCAM时,模型达到了最佳性能。这表明这两个模块在捕捉多尺度特征和增强局部上下文信息方面发挥了关键作用。

- 探讨了多尺度卷积内不同卷积核的选择对性能的影响。实验结果表明,使用1x1、3x3和5x5卷积核组合能够带来最佳性能,这一组合在捕捉多尺度特征方面具有优势。而进一步添加更大的卷积核(如7x7或9x9)反而降低了性能,说明适当的卷积核大小组合有助于模型在保持计算效率的同时提升分割效果。
即插即用模块
import torch.nn as nn
import torch
# 论文:EMCAD: Efficient Multi-scale Convolutional Attention Decoding for Medical Image Segmentation, CVPR2024
# 论文地址:https://arxiv.org/pdf/2405.06880
def channel_shuffle(x, groups):
batchsize, num_channels, height, width = x.data.size()
channels_per_group = num_channels // groups
# reshape
x = x.view(batchsize, groups,
channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batchsize, -1, height, width)
return x
def act_layer(act, inplace=False, neg_slope=0.2, n_prelu=1):
# activation layer
act = act.lower()
if act == 'relu':
layer = nn.ReLU(inplace)
elif act == 'relu6':
layer = nn.ReLU6(inplace)
elif act == 'leakyrelu':
layer = nn.LeakyReLU(neg_slope, inplace)
elif act == 'prelu':
layer = nn.PReLU(num_parameters=n_prelu, init=neg_slope)
elif act == 'gelu':
layer = nn.GELU()
elif act == 'hswish':
layer = nn.Hardswish(inplace)
else:
raise NotImplementedError('activation layer [%s] is not found' % act)
return layer
# Efficient up-convolution block (EUCB)
class EUCB(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, activation='relu'):
super(EUCB, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.up_dwc = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.Conv2d(self.in_channels, self.in_channels, kernel_size=kernel_size, stride=stride,
padding=kernel_size // 2, groups=self.in_channels, bias=False),
nn.BatchNorm2d(self.in_channels),
act_layer(activation, inplace=True)
)
self.pwc = nn.Sequential(
nn.Conv2d(self.in_channels, self.out_channels, kernel_size=1, stride=1, padding=0, bias=True)
)
def forward(self, x):
x = self.up_dwc(x)
x = channel_shuffle(x, self.in_channels)
x = self.pwc(x)
return x
if __name__ == '__main__':
input = torch.randn(1, 32, 64, 64) #B C H W
block = EUCB(in_channels=32, out_channels=64)
print(input.size())
output = block(input) print(output.size())


















 3916
3916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









