






✅作者简介:热爱科研的Matlab仿真开发者,擅长数据处理、建模仿真、程序设计、期刊写作与指导,代码获取、论文复现及科研仿真合作可私信或扫描文章底部二维码。
🍎个人主页:Matlab科研工作室
🍊个人信条:格物致知。
更多Matlab完整代码及仿真定制内容点击👇
🔥 内容介绍
随着国民经济发展和社会进步,基于电力电子技术的电能变换(电能变换是指将电能从一种形式转变成另一种形式,如直流电转换为不同电压的直流电,直流电转换为不同频率和大小的交流电等)得到迅速发展,尤其是新能源和信息通讯领域。电能变换技术在通讯电源、算力电源、数据中心电源、新能源功率变换、轨道交通、电动汽车、电气传动、智能电网、绿色照明等各个方面都有广泛应用。随着第三代功率半导体技术的发展,高频、高功率密度和高可靠性成为功率变换器产品的发展方向。磁性元件(变压器、电感等)作为功率变换器中必不可少的器件,担负着磁能的传递、存储、滤波等功能,对功率变换器的体积、重量、损耗、成本等都具有重要的影响。为了获得高效率和高功率密度的设计,除了满足磁性元件电气参数的可行性设计外,还要求其损耗小。因此,必须详细研究和分析磁性元件的损耗特性,磁性元件的损耗包括绕组损耗和磁芯损耗。铜导体的绕组损耗可以通过电磁场有限元仿真技术准确获得,但磁芯损耗是磁性材料在高频交变磁通作用下产生的功率损耗(本题中损耗都是指功率损耗),由于高频磁性材料(如铁氧体、合金磁粉芯、非晶/纳米晶等)本身的微观结构复杂,且其损耗与工作频率、磁通密度、励磁波形、工作温度、磁芯材料等诸多因素有关,并呈现复杂的非线性和相互关联性。现有的磁芯材料损耗模型与实际应用的需求有较大差异。
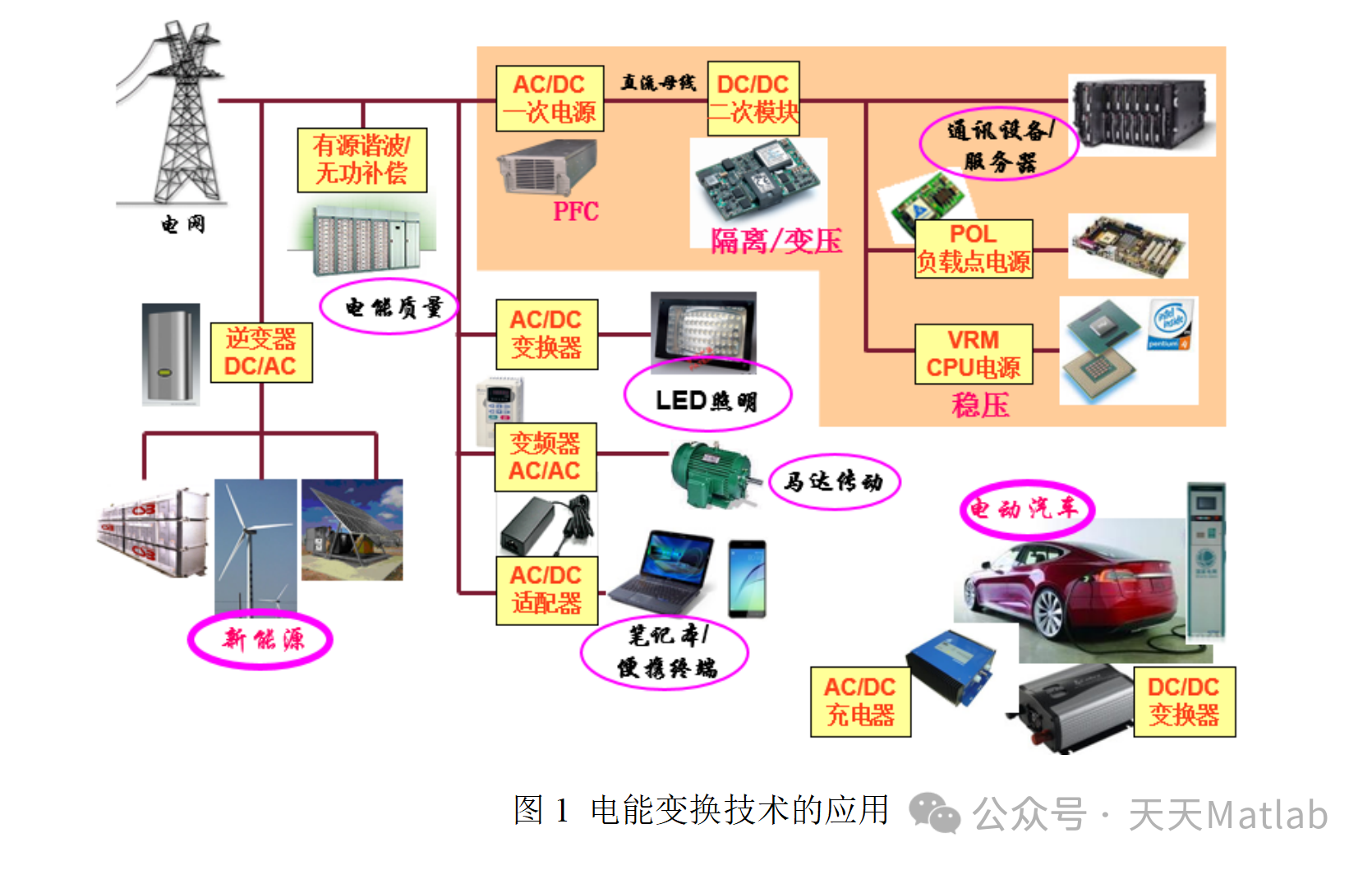

📣 赛题分析
磁芯损耗是磁性元件的重要性能指标,直接影响其效率和可靠性。传统的磁芯损耗模型往往依赖于经验公式和理论推导,缺乏数据驱动的特性,难以准确预测复杂场景下的损耗情况。近年来,随着数据科学和机器学习的快速发展,数据驱动建模方法为磁芯损耗预测提供了新的思路。本文将探讨数据驱动下的磁芯损耗建模思路,并结合实际案例,给出相应的代码实现。
一、 问题背景与挑战
磁芯损耗是指磁性材料在交变磁场作用下产生的能量损耗,主要包括涡流损耗、磁滞损耗和剩余损耗。准确预测磁芯损耗对于优化磁性元件设计、提升器件性能至关重要。然而,传统的磁芯损耗模型往往存在以下不足:
-
依赖经验公式: 传统的模型通常基于经验公式,难以适应复杂的工作条件和材料特性。
-
理论推导局限: 理论推导模型往往需要简化假设,无法完全反映实际情况。
-
缺乏数据驱动: 传统的模型缺乏对大量数据的学习和挖掘,难以捕捉实际损耗情况的复杂规律。
为了克服上述问题,数据驱动方法应运而生,其优势在于:
-
基于大数据: 可以利用大量的实验数据和仿真数据,更全面地反映实际情况。
-
模型学习: 可以通过机器学习算法,自动学习数据特征和规律,建立更准确的模型。
-
自适应性强: 能够根据不同的工作条件和材料特性,动态调整模型参数,提高预测精度。
二、 数据驱动磁芯损耗建模思路
数据驱动下的磁芯损耗建模主要包括以下步骤:
1. 数据采集与预处理:
-
采集不同工作条件下的磁芯损耗数据,包括磁场强度、频率、温度、损耗功率等。
-
对数据进行清洗、去噪、归一化等预处理,确保数据的完整性和一致性。
2. 特征工程:
-
根据物理机理和数据特点,提取与磁芯损耗相关的特征,例如磁场强度、频率、材料特性等。
-
可以采用特征筛选、降维等方法,选择最有效的特征,提高模型效率和精度。
3. 模型选择与训练:
-
选择合适的机器学习模型,例如支持向量机、神经网络、随机森林等。
-
利用训练数据对模型进行训练,使模型能够学习数据中的复杂规律。
4. 模型评估与优化:
-
使用验证数据评估模型的性能,例如准确率、误差率等。
-
根据评估结果,对模型进行优化,例如调整模型参数、选择更合适的特征等。
5. 模型部署与应用:
-
将训练好的模型部署到实际应用场景,用于预测磁芯损耗。
-
可以根据新的数据,不断更新模型,保证模型的准确性和可靠性。
三、 实例代码
以下代码示例展示了使用神经网络模型进行磁芯损耗预测的流程,并以 Python 语言和 Keras 库为例:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.callbacks import EarlyStopping
# 加载数据
data = pd.read_csv('core_loss_data.csv')
# 特征提取
X = data[['magnetic_field', 'frequency', 'temperature']]
y = data['core_loss']
# 数据分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 建立神经网络模型
model = Sequential()
model.add(Dense(64, activation='relu', input_shape=(X_train.shape[1],)))
model.add(Dense(32, activation='relu'))
model.add(Dense(1))
# 模型编译
model.compile(optimizer='adam', loss='mse')
# 早停机制
early_stopping = EarlyStopping(monitor='val_loss', patience=10)
# 模型训练
model.fit(X_train, y_train, epochs=100, batch_size=32, validation_split=0.2,
callbacks=[early_stopping])
# 模型评估
loss = model.evaluate(X_test, y_test)
print('模型损失:', loss)
# 模型预测
y_pred = model.predict(X_test)
# 结果可视化
# ...
四、 总结与展望
数据驱动下的磁芯损耗建模方法能够利用大量数据,克服传统模型的局限性,提高磁芯损耗预测的准确性。未来,随着数据采集技术的进步和机器学习算法的优化,数据驱动方法将在磁性元件设计、制造和应用方面发挥越来越重要的作用。















 1204
1204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









