






在上海交大举办的校源行线下活动中,来自国家地方共建人形机器人创新中心(以下简称“国地中心”)的运动控制专家 Darren老师带来了关于人形机器人运动控制框架的精彩分享。本文将围绕该框架的设计背景、核心模块、控制算法与仿真系统展开介绍,深入浅出地剖析了人形机器人运动控制框架的关键要素,让我们对这一前沿科技领域的认知更加清晰。

为什么需要运动控制框架?
Darren老师开篇指出,在人形机器人研发中,“运动控制框架”并不是可有可无的附属品,而是保证高效开发与系统稳定运行的基础设施。主要原因包括:
实时性:机器人需在毫秒级内完成传感器数据处理与控制指令下发;
稳定性:运行中常会遇到下使能、宕机等问题,系统必须具备容错能力;
开发效率低下:重复造轮子、模块耦合高、调试周期长;
硬件损耗高:频繁实机测试加速机械损伤;
AI 算法集成困难:强化学习、模仿学习等算法与低层控制难以融合;
人才培养瓶颈:缺少系统化工具链,学习曲线陡峭。
因此,为了应对实时性、稳定性、高耦合等挑战,一个模块化、可重用、支持 AI 集成的运动控制框架,是现代人形机器人开发的关键支撑。
框架结构设计:分层、模块化、易扩展
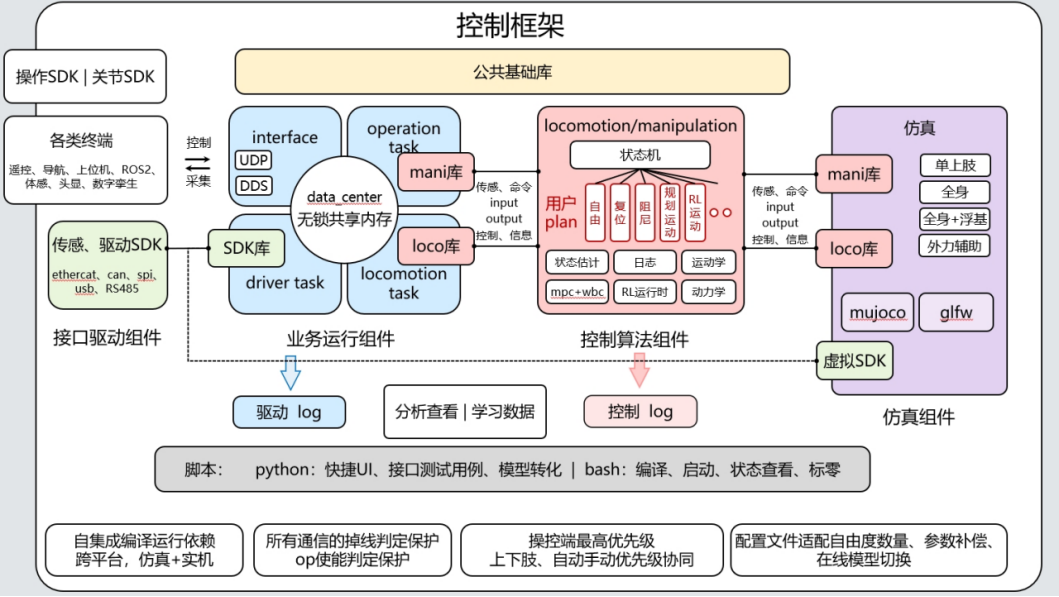
该运动控制框架以模块独立、层级清晰、接口规范、仿实共通为核心设计理念,整体架构划分为以下四大组件:
① 接口驱动组件(Interface Layer)
该层负责连接机器人与外部世界,包括传感器、伺服驱动、控制面板等设备,支持与上层系统间的智能交互通信。
同时也支持虚拟SDK切换:在仿真模式下,传感与驱动接口会被自动替换为虚拟模块,实现代码级别的一致性。该组件还集成了操作工具、关节SDK等,支持实机与仿真下的交互操作。
② 业务运行组件(Business Runtime Layer)
核心控制逻辑由四个独立的运行模块构成,每个模块都被独立编译为可执行程序,并通过无锁共享内存(data_center)实现高效实时数据交换:
driver_task:读取传感器数据、下发控制指令;
interface_task:实现基于 UDP 与 DDS 的通信交互;
locomotion_task:管理机器人动态平衡与运动控制;
operation_task:处理机器人高层操作行为(如抓取、搬运等)。
这种结构支持高并发、低延迟的控制执行,也方便开发者按需独立调试每个任务模块。
③ 控制算法组件(Control Algorithm Layer)
该组件作为整个系统的核心决策与计算层,采用动态链接库(.so/.dll)形式部署,并可被仿真与实机系统无缝复用,无需代码修改。
控制算法组件分开为两个独立库开发,机器人平衡与运动控制的 locomotion 库、以及操作作业的operation 库,独立开发完毕后作为动态链接库接入业务控制系统。
④ 仿真组件(Simulation Layer)
为控制算法验证和系统开发提供高保真、可视化的物理仿真环境。该组件支持:
- 机器人单上肢,全身,全身+浮基,外力辅助等运动场景模拟;
- 用户指令注入、调试参数更新;
- 可视化与日志记录支持分析与优化控制策略。
仿真与实机系统使用同一套控制逻辑,保证验证结果高度一致,降低实机调试风险。
统一优势与工程特性总结
自集成打包
所有依赖一键封装,解压即用,无需复杂环境配置;
接口通用性强
标准化数据结构,适配多类机器人平台;
仿实代码一致
实机与仿真共享一套控制逻辑;
全链路开源透明
不仅开放算法层,同时开放底层框架系统,区别于行业常见的“算法开源/框架闭源”做法。
这一分层结构充分体现了现代机器人控制系统在功能分离、模块自治、仿实一致、可测试性强等方面的工程实践价值,是构建高可靠性人形机器人平台的重要基石。
核心模块设计
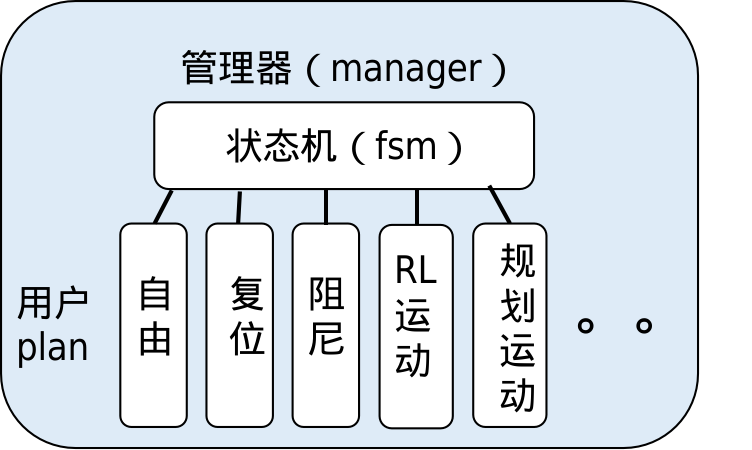
状态机与状态管理模块
状态机(FSM)是控制框架中的最核心的部分,它的主要功能为添加规划以及运行。在添加规划时,状态机会依次添加初始规划,空闲规划以及普通规划这三种规划,并且通过运行,用户规划会在程序中被实时循环调用。也就是说状态机会根据当前状态和用户输入键值,决定下一个状态和要执行的规划。
在状态机之上还有一层状态管理器(Manager),它的任务是负责在初始化时向状态机添加并检查用户规划。它要检查用户规划的绑定名、切换键值和优先级等信息,确保状态机能够正确地管理和切换不同的状态。
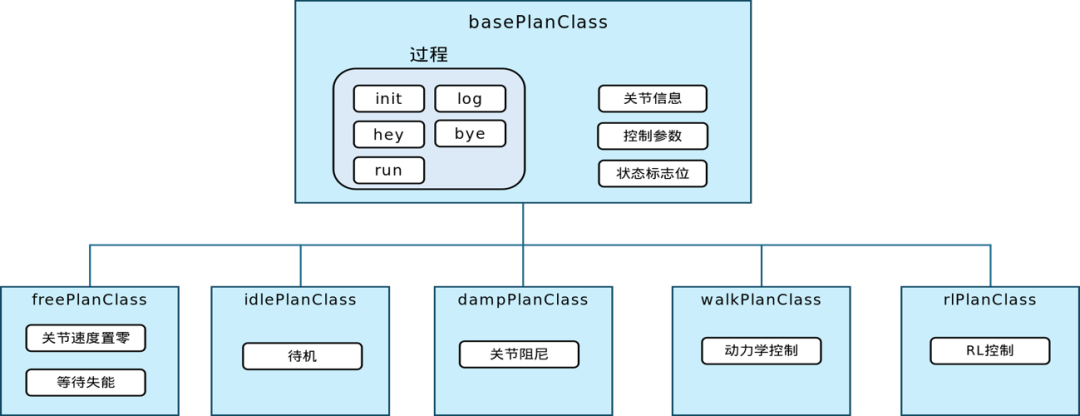
用户规划器
用户规划器(Plan)的设计也很巧妙。它采用了继承关系,基类 basePlanClass 集成了各子类共用的调用过程接口,以及各个用户规划必须的关节信息、控制参数、状态信息等。常用的规划类型包括下电(free plan)、空闲(idle plan)、阻尼(damp plan)、行走(walk plan)和强化学习(rl plan)等。这些规划就像是机器人的“动作库”,可以根据不同的应用场景和需求,灵活选择和组合。
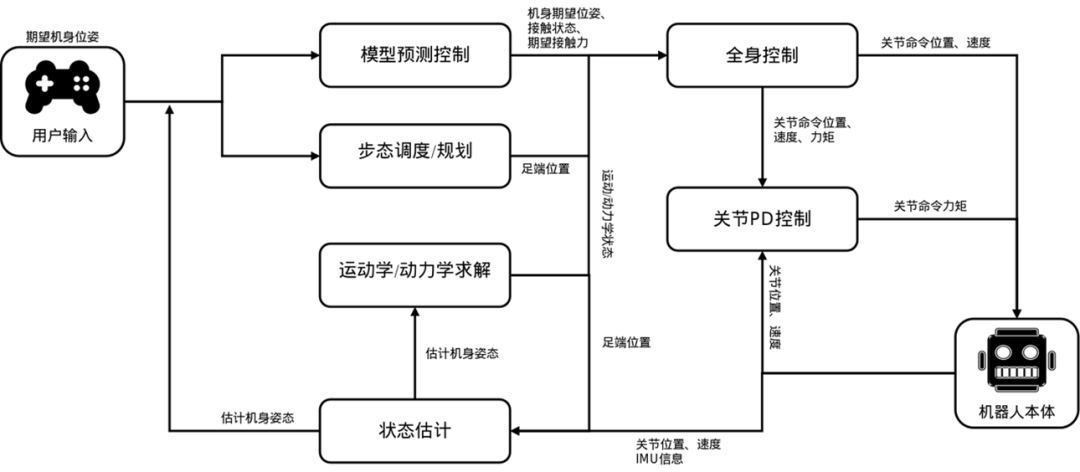
动力学平衡控制
动力学平衡控制是人形机器人运动控制的核心技术之一。它采用了模型预测控制(MPC)和全身动力学控制(WBC)相结合的方法。MPC是一种基于模型的控制方法,它通过预测未来一段时间内的系统状态和控制输入,来优化当前时刻的控制输出。这种方法能够生成平滑、稳定的运动轨迹,使机器人在行走、跳跃、爬行等复杂动作中保持平衡。而WBC则考虑了机器人的整体动力学特性,通过优化各个关节的运动来实现整体的平衡和稳定。两者结合使用,可以显著提高机器人的运动性能和控制精度。
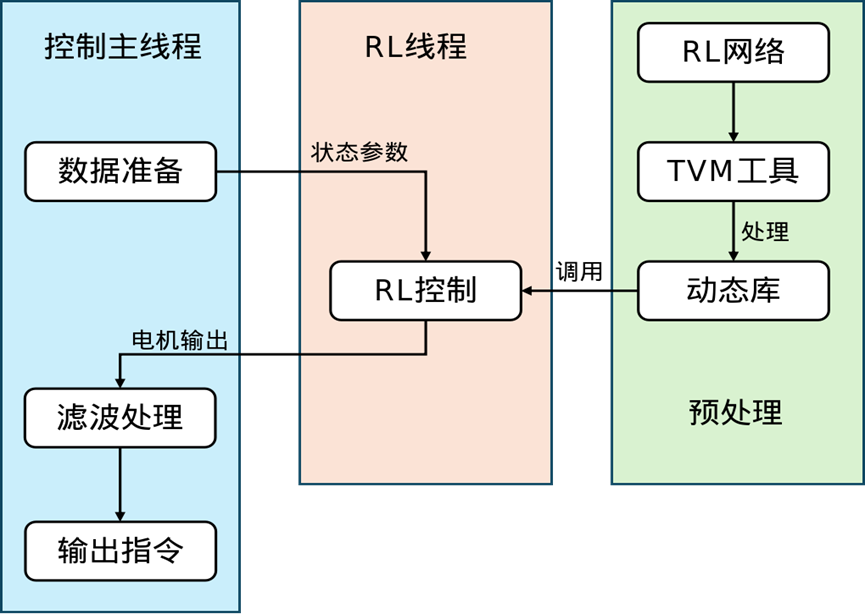
强化学习运行时
强化学习在人形机器人的运动控制中也发挥着重要作用。强化学习控制逻辑的设计很有意思。在运行强化学习算法时,会基于TVM(Tensor Virtual Machine)进行封装,采用嵌套类封装的方式,既保持了代码的模块化,又实现了接口与实现的分离。运行逻辑方面,可以创建副线程用于网络模型推理,主线程则将推理结果进行滤波处理后输出。这种设计使得强化学习算法能够高效地应用于人形机器人的运动控制,就像是给机器人配备了一个“学习大脑”,让它能够通过不断学习和优化,更好地适应各种复杂的任务和环境。
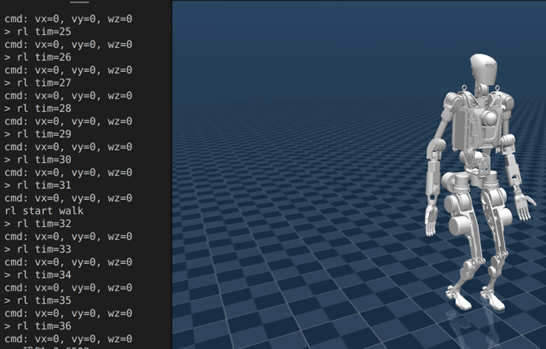
全链仿真SDK演示:一体化 SDK 支持
一般的 sim2sim 的问题在于它是单线程的,一旦网络或者仿真step被阻塞,那么整个线程就会停止。但这种 sim2sim 不符合物理实际,因为实际上网络step和仿真step是并行化的。
因此,全链仿真 sim2sim-real 应运而生。在全链仿真中,所有的网络step、SDK step、仿真step以及物理step都是并行处理,网络和仿真/物理step之间通过sdk连接,SDK内集成了物理准备和安全保护过程,确保了仿真与真机之间的无缝对接。
操作流程简述
1. 启动多个窗口脚本,包括仿真、驱动、通信、控制器、UI 等;
2. 上使能 [en] → 复位 [rc] → 站立 [nb];
3. 调节高度、解除辅助力(按键 f),准备实机控制;
4. 启动 joint SDK → 点击 UI 控制面板完成控制;
5. 紧急停机(dis)进入 free 状态后可重新上使能。
SDK 提供稳定的仿真接口和安全机制,便于在物理真机运行前进行全面验证。在仿真运行过程中,通过一系列的操作命令,如机器人上使能、复位、调整高度、站立、去除辅助力等,可以实现对机器人运动的精准控制。
开源资源:欢迎参与社区共建
Darren 还介绍了 OpenLoong 开源社区正在推进的多个相关项目,涵盖运动控制、仿真、AI 强化学习平台等,欢迎关注与参与:
- 学习资料
- 动力学控制库
从底层动力学到高层 AI 策略,从框架设计到仿真实战,Darren老师为我们系统讲解了一个面向未来的人形机器人运动控制体系。无论是高性能的分层控制架构,还是仿真与实机统一的工程实践,都为开发者提供了可复用、可拓展、可验证的技术路径。
更重要的是,这一控制体系不仅解决了实际工程中的复杂性与实时性难题,还通过模块化设计降低了上手门槛,让更多开发者可以在通用的技术基础上开展个性化创新。
随着开源生态的持续扩展,工具链、算法库和硬件标准的不断完善,属于每一个开发者的机器人时代正在加速到来。未来,不再只是“大厂”的游戏,每一位有热情、有想法的技术人都可以真正“参与创造”,从实验室走向现实,从代码走向形体。

我们期待有更多的工程实践者,持续分享经验,推动人形机器人领域从工程落地走向更广阔的智能世界。OpenLoong 开源社区提供了一个开放交流的平台,在这里,大家可以共同探讨机器人仿真的难点与创新点。本次技术稿件也将在开源社区进行共享,欢迎大家点击跳转下载稿件PDF,一起进行交流。

















 880
880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









