







实验
1. 实验环境及步骤
实验环境配置
| 硬件配置 | 软件配置 |
|---|---|
| 显卡:NVIDIA RTX A6000 | 系统:Ubuntu 18.04(64位) |
| 硬盘:SSD NVMe 86GB | Python版本:3.8.0 |
| 内存:48GB RAM | 框架:Pytorch 1.10+cudnn8.0.5 |
| 处理器:Intel Xeon Platinum 8260C CPU | CUDA:CUDA11.3 |
实验步骤
- 数据集增强
对收集的数据进行增强处理以提高模型泛化能力。 - 评价指标确定
通过定义评价指标分析实验数据。 - 模型训练及参数设置
- 设置训练参数
- 将数据集输入模型进行训练
- 选择最优模型权重,通过检测脚本对道路障碍物图片进行分类预测
模型结构
- YOLOv8 模型结构
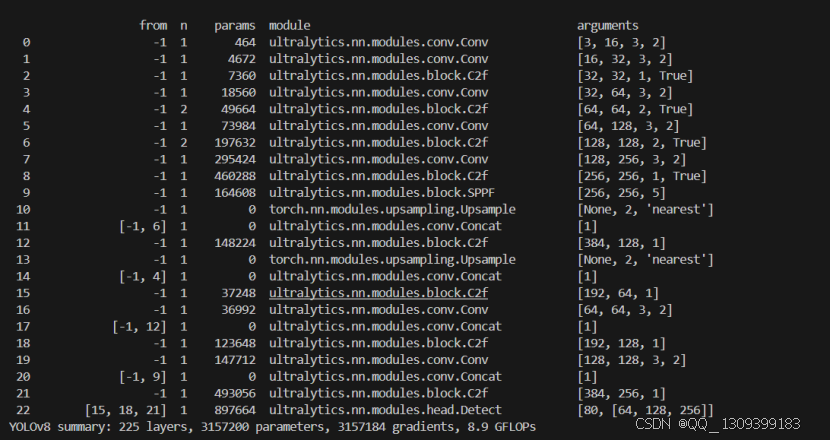
改进的YOLO11结构图
2. 数据集采集
- 数据来源:通过 Roboflow 下载
- 数据集规模:8000+ 张图像,包含 8 类目标
- 数据示例
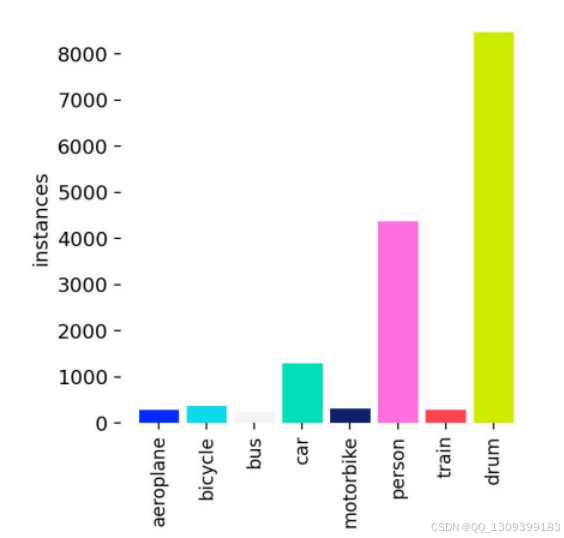
类别分布
| 类别 | 数量 |
|---|---|
| 类别1 | 1000 |
| 类别2 | 1200 |
| … | … |
3. 数据集预处理
采用 Mosaic 数据增强 技术,将四张图像拼接为新图像以提升模型鲁棒性。
4. 评价指标
4.1 计算公式
- 精确率(Precision)
P = T P T P + F P P = \frac{TP}{TP + FP} P=TP+FPTP - 召回率(Recall)
R = T P T P + F N R = \frac{TP}{TP + FN} R=TP+FNTP - 平均精度(AP)
A P = ∫ 0 1 P ( R ) d R AP = \int_{0}^{1} P(R) \, dR AP=∫01P(R)dR - 均值平均精度(mAP)
m A P = 1 N ∑ i = 1 N A P i mAP = \frac{1}{N} \sum_{i=1}^{N} AP_i mAP=N1i=1∑NAPi
4.2 评价标准
- IoU 阈值设为 0.5(即 AP@0.5)
- mAP@0.5 反映模型整体性能
5. 结果对比
5.1 算法性能对比
| 算法 | 输入尺寸 | 模型大小(M) | mAP@0.5 | 训练速度(s/张) | FPS |
|---|---|---|---|---|---|
| YOLOv8 | 640×640 | 5.36 | 83.4 | 0.098 | 56 |
| YOLO11 | 640×640 | 5.96 | 82.6 | 0.110 | 52 |
| 改进的YOLO11 | 640×640 | 5.21 | 83.7 | 0.119 | 58 |
结论:改进的YOLO11在模型大小(5.21M)、mAP(83.7%)和FPS(58)上均表现最优。
5.2 训练曲线对比
-
YOLOv8 训练曲线
) -
YOLO11 训练曲线
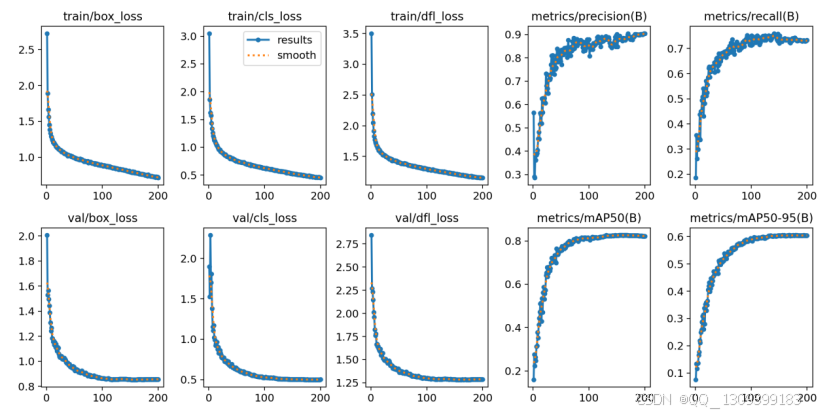
-
改进的YOLO11 训练曲线
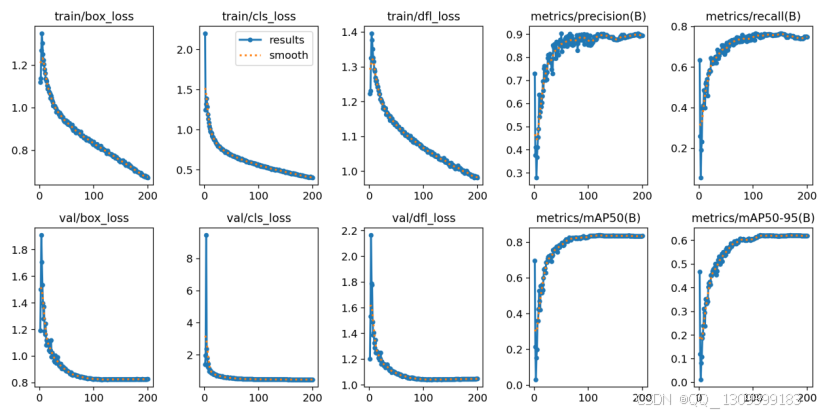
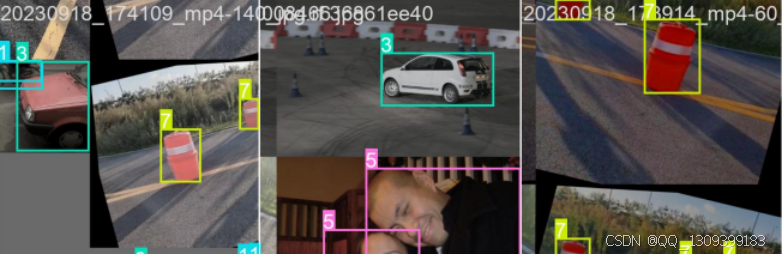
6. 障碍物识别检测系统
检测效果对比
-
YOLOv8 检测结果
-
YOLO11 检测结果
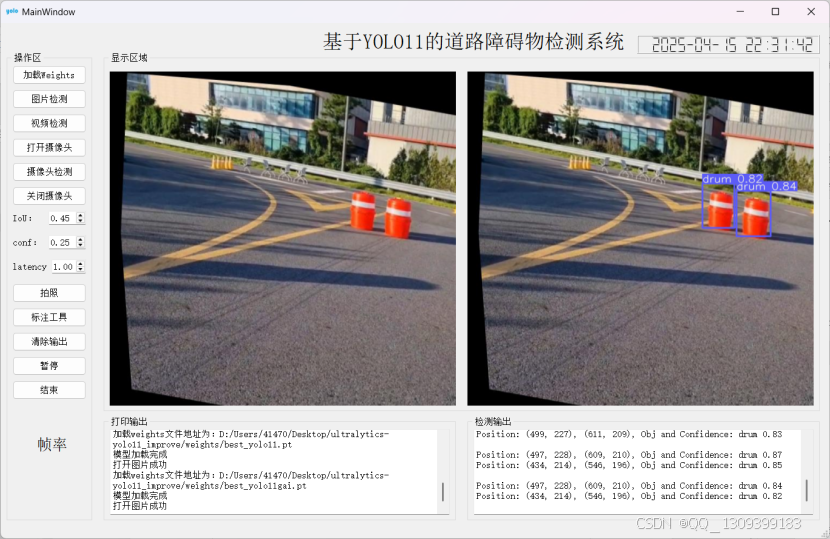
-
改进的YOLO11 检测结果
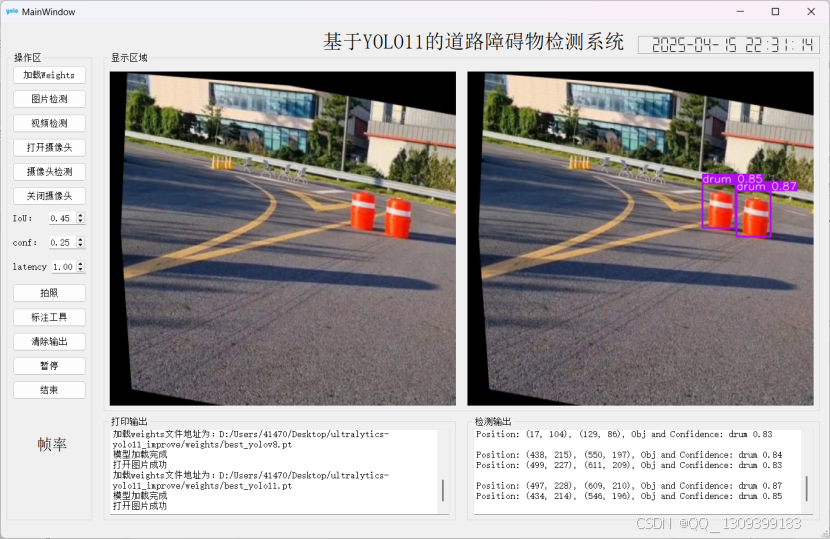
结论:改进模型对障碍物的置信度显著提高,验证了 Efficient 注意力机制和 CARAFE 算子的有效性。


















 1984
1984

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









