







基于YOLOv8n和BDD100K数据集的自动驾驶目标检测技术
一、技术概述

自动驾驶目标检测是计算机视觉领域的重要研究方向,也是实现自动驾驶系统的核心技术之一。YOLOv8n(You Only Look Once version 8 nano)是Ultralytics公司推出的最新一代轻量级目标检测模型,结合BDD100K(Berkeley DeepDrive 100K)大规模自动驾驶数据集,为自动驾驶车辆提供了高效、准确的环境感知能力。
这一技术组合具有以下显著特点:
- 实时性能优异:YOLOv8n作为轻量级模型,在保持较高检测精度的同时,能够实现快速的推理速度
- 场景覆盖全面:BDD100K数据集包含多样化的驾驶场景,使模型具备良好的泛化能力
- 硬件兼容性强:模型轻量化设计适合部署在车载边缘计算设备上
- 多类别检测:支持车辆、行人、交通标志等多种道路相关目标的识别
二、BDD100K数据集详解
BDD100K是由加州大学伯克利分校DeepDrive项目发布的大规模自动驾驶数据集,是目前最全面的驾驶场景数据集之一。
数据集组成
- 图像数量:包含100,000段高清视频(每段约40秒),从中抽取了约120万张标注图像
- 地理分布:覆盖纽约、旧金山湾区等不同地区,包含城市、乡村和高速公路场景
- 天气条件:晴天、雨天、雾天、雪天等多种天气状况
- 时间变化:白天、黄昏、夜晚不同光照条件下的数据
标注信息
- 对象类别:共8大类(公交车、红绿灯、交通标志、人、自行车、卡车、摩托车、汽车)和10小类
- 标注格式:边界框(Bounding Box)标注,包含对象类别和位置信息
- 附加信息:部分数据包含道路区域、可行驶区域和车道线标注
数据划分
- 训练集:70,000张图像
- 验证集:10,000张图像
- 测试集:20,000张图像
三、YOLOv8n模型架构
YOLOv8n是YOLOv8系列中最轻量级的版本,专为边缘设备部署优化,其架构设计体现了效率与精度的平衡。
模型特点
- 骨干网络(Backbone):采用CSPDarknet的轻量变体,减少计算量同时保持特征提取能力
- 颈部设计(Neck):使用PAN-FPN(Path Aggregation Network-Feature Pyramid Network)结构,增强多尺度特征融合
- 检测头(Head):解耦式检测头设计,分类和回归任务分离,提升检测精度
- Anchor-free机制:摒弃传统YOLO的Anchor机制,直接预测目标中心点和尺寸
- 损失函数:采用TaskAlignedAssigner和Distribution Focal Loss,优化正负样本分配和分类任务
性能参数
- 参数量:约3.2M
- FLOPs:约8.7G(输入尺寸640×640)
- 推理速度:在NVIDIA Tesla T4上约0.5ms每帧
- 精度表现:在BDD100K验证集上mAP50可达约45-50%(取决于训练配置)
四、技术实现流程
1. 数据准备与预处理
- 数据下载:从BDD100K官网获取数据集
- 格式转换:将原始JSON标注转换为YOLO格式的txt文件
- 数据增强:
- 几何变换:随机缩放、裁剪、旋转
- 色彩调整:亮度、对比度、饱和度变化
- 特殊增强:模拟雨滴、雾化等天气效果
2. 模型训练
- 环境配置:PyTorch框架,CUDA加速
- 超参数设置:
- 初始学习率:0.01
- 批量大小:16-64(根据GPU显存调整)
- 训练周期:100-300epochs
- 训练技巧:
- 迁移学习:使用COCO预训练权重初始化
- 学习率调度:Cosine衰减策略
- 早停机制:监控验证集mAP变化
3. 模型评估
- 评估指标:
- mAP(mean Average Precision)@0.5:0.95
- 召回率(Recall)
- 精确率(Precision)
- 推理速度(FPS)
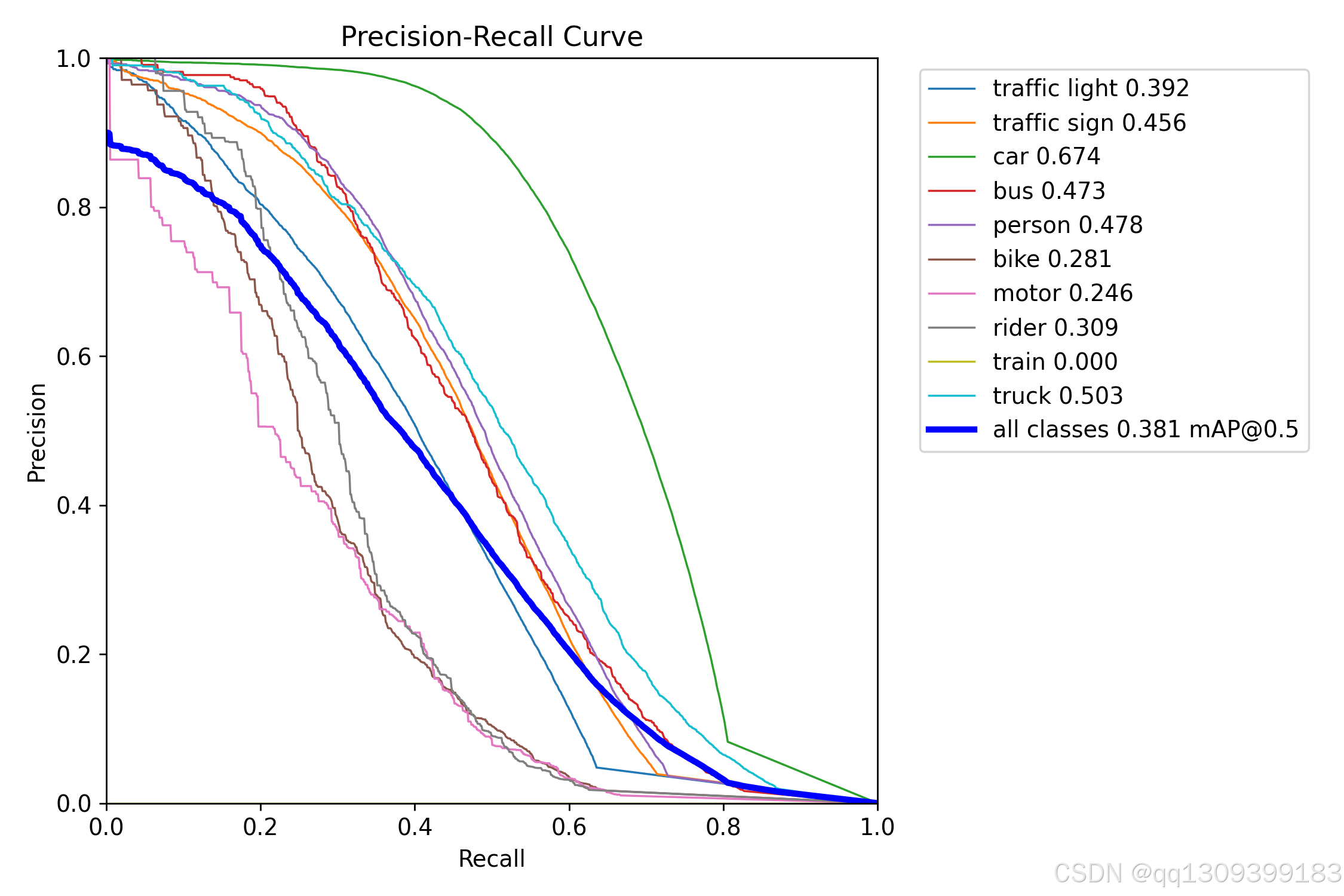
- 可视化分析:绘制PR曲线、混淆矩阵
4. 模型优化
- 量化压缩:FP16/INT8量化减少模型大小
- 剪枝策略:移除冗余通道和层
- 知识蒸馏:使用更大YOLOv8模型作为教师模型
五、实际应用与部署
车载系统集成
- 硬件平台:NVIDIA Jetson系列、地平线征程芯片等边缘计算设备
- 软件框架:
- 推理引擎:TensorRT加速
- 中间件:ROS(Robot Operating System)
- 系统架构:
- 感知模块:目标检测为核心
- 跟踪模块:SORT/DeepSORT多目标跟踪
- 融合模块:多传感器数据融合(摄像头、雷达、激光雷达)
性能优化策略
- 输入分辨率调整:平衡精度和速度(如从640×640降至512×512)
- 模型裁剪:针对特定场景精简检测类别
- 流水线优化:与其他感知任务(如语义分割)共享特征提取

实际应用场景
- 前方碰撞预警:检测前方车辆和行人,计算碰撞时间(TTC)
- 交通标志识别:识别限速、禁止通行等标志
- 盲区监测:检测侧后方来车和行人
- 自动紧急制动:危险目标检测触发制动系统
六、技术优势与挑战
显著优势
- 实时性:在边缘设备上可达30-60FPS,满足自动驾驶实时需求
- 轻量化:模型大小仅约6MB,适合资源受限环境


















 695
695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









