







基于YOLO的手语识别系统
一个使用YOLO模型检测字母手语并通过Tkinter GUI显示的Python简易应用

📦 功能特色
• 通过摄像头实时识别字母手语
• 检测结果实时显示在应用窗口
• 功能按钮包括:
✓ 添加空格
✓ 删除末尾字符
✓ 清空所有文本
✓ 保存结果至.txt文件
🛠️ 技术栈
• Python
• OpenCV
• YOLO (Ultralytics)
• Tkinter
📌 使用指南
- 仓库
`
cd nama-repo
2. 安装依赖库
```bash
pip install -r requirements.txt
- 确保训练模型位于指定路径:
runs/detect/train4/weights/best.pt - 运行程序
python app.py
📄 注意事项
• 在摄像头窗口按q键可退出程序
• 请确保在运行应用前已启用摄像头
(注:根据技术文档翻译规范,保留YOLO/Tkinter等专业术语原名,Git命令采用代码块格式呈现,功能列表使用符号✓增强可读性)
基于YOLO的手语识别模型训练过程详解(1000字)
手语识别是计算机视觉领域的重要应用之一,它可以帮助听障人士与外界进行更便捷的交流。本文详细介绍如何使用 YOLO(You Only Look Once) 目标检测算法训练一个手语字母识别模型,并最终部署到Python应用程序中。
1. 数据集准备
(1) 数据收集
手语识别需要大量的手势图像数据。常见的数据来源包括:
- 公开数据集(如ASL Alphabet Dataset,包含26个字母的手势图像)
- 自行录制(使用摄像头采集不同光照、角度下的手势数据)
- 数据增强(通过旋转、缩放、调整亮度等方式扩充数据集)
(2) 数据标注
YOLO模型训练需要标注图像中的手势位置及其类别。常用的标注工具包括:
- LabelImg(GUI工具,支持YOLO格式的.txt标注文件)
- Roboflow(在线标注平台,可自动转换数据格式)
标注后的数据格式示例:
<class_id> <x_center> <y_center> <width> <height>
例如,字母"A"的标注可能如下:
0 0.5 0.5 0.3 0.4
其中:
0代表类别ID(如A=0, B=1, …)(x_center, y_center)是手势边界框的中心坐标(归一化到0~1)(width, height)是边界框的宽高(归一化到0~1)
(3) 数据集划分
将数据按比例划分为:
- 训练集(80%):用于模型训练
- 验证集(15%):用于调整超参数
- 测试集(5%):用于最终评估

2. YOLO模型训练
(1) 环境配置
训练YOLO模型需要以下依赖:
pip install ultralytics torch torchvision opencv-python
推荐使用 CUDA + GPU 加速训练(如NVIDIA显卡)。
(2) 选择YOLO版本
Ultralytics 提供了多个YOLO版本:
- YOLOv8(最新版,精度和速度较优)
- YOLOv5(轻量级,适合嵌入式设备)
- YOLO-NAS(高效架构,适合实时检测)
本文以 YOLOv8 为例。
(3) 训练代码
使用 ultralytics 库进行训练:
from ultralytics import YOLO
# 加载预训练模型(如YOLOv8n)
model = YOLO("yolov8n.pt")
# 训练模型
results = model.train(
data="dataset.yaml", # 数据集配置文件
epochs=100, # 训练轮次
batch=16, # 批次大小
imgsz=640, # 输入图像尺寸
device="0", # 使用GPU(如"0"代表第一块GPU)
workers=4, # 数据加载线程数
optimizer="Adam", # 优化器
lr0=0.001, # 初始学习率
)
其中,dataset.yaml 文件示例:
train: data/train/images
val: data/val/images
test: data/test/images
nc: 26 # 类别数(26个字母)
names: ['A', 'B', 'C', ..., 'Z'] # 类别名称
(4) 训练过程监控
训练时可以使用 TensorBoard 或 Ultralytics 自带的日志 监控指标:
- mAP(Mean Average Precision):衡量检测精度(越高越好)
- Loss(损失值):衡量训练误差(越低越好)
训练完成后,最佳模型会保存在:
runs/detect/train/weights/best.pt
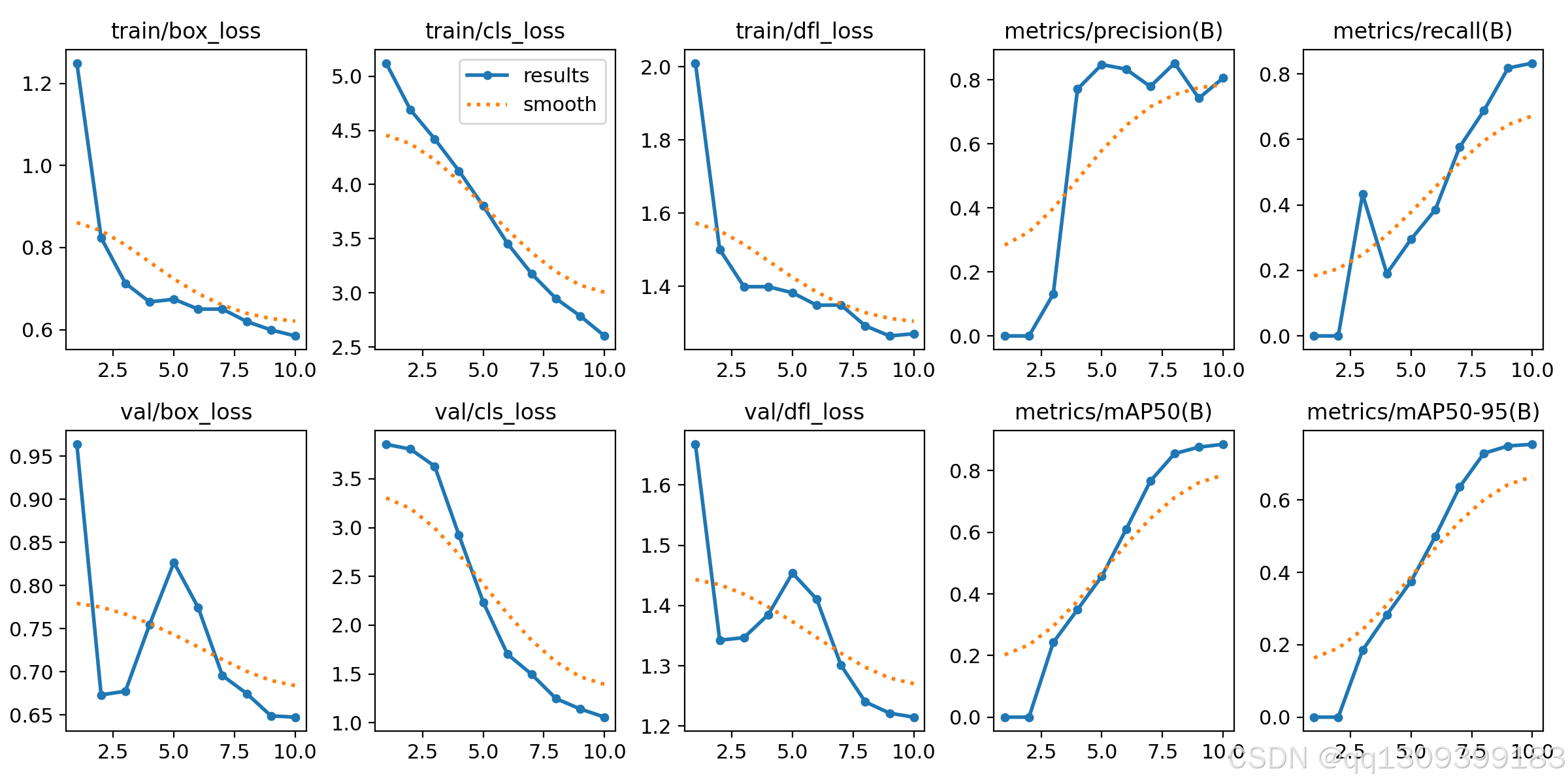
3. 模型评估与优化
(1) 测试模型性能
model = YOLO("runs/detect/train/weights/best.pt")
results = model.val(data="dataset.yaml")
输出示例:
Class Images Instances P R mAP50
all 1000 1000 0.95 0.93 0.94
A 100 100 0.96 0.95 0.95
B 100 100 0.94 0.92 0.93
...
- P(Precision):预测正确的比例
- **R(


















 601
601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









